Eine sanfte Einführung in das neueste multimodale Transfusionsmodell
Kürzlich veröffentlichten Meta und Waymo ihr neuestes Papier —Transfusion: Vorhersage des nächsten Tokens und diffuser Bilder mit einem multimodalen Modell, das das beliebte Transformer-Modell mit dem Diffusionsmodell für multimodale Trainings- und Vorhersagezwecke integriert.
Wie Meta’s vorherige ArbeitenDas Transfusionsmodell basiert auf der Lama-Architektur mit früher Fusion, die sowohl die Texttoken-Sequenz als auch die Bildtoken-Sequenz verwendet und ein einzelnes Transformatormodell zur Generierung der Vorhersage verwendet. Anders als beim bisherigen Stand der Technik behandelt das Transfusionsmodell die Bildtoken jedoch anders:
- Die Bild-Token-Sequenz wird von einem vortrainierten Variational Auto-Encoder-Teil generiert.
- Die Transformator-Aufmerksamkeit für die Bildsequenz ist bidirektional und nicht kausal.
Lassen Sie uns Folgendes im Element besprechen. Wir werden zuerst die Grundlagen wie autoregressive und Diffusionsmodelle durchgehen und uns dann mit der Transfusionsarchitektur befassen.
Autoregressive Modelle
Heutzutage basieren große Sprachmodelle (LLMs) hauptsächlich auf Transformer-Architekturen, die in den Aufmerksamkeit ist alles, was Sie brauchen Papier im Jahr 2017. Die Transformatorarchitektur besteht aus zwei Teilen: dem Encoder und dem Decoder.
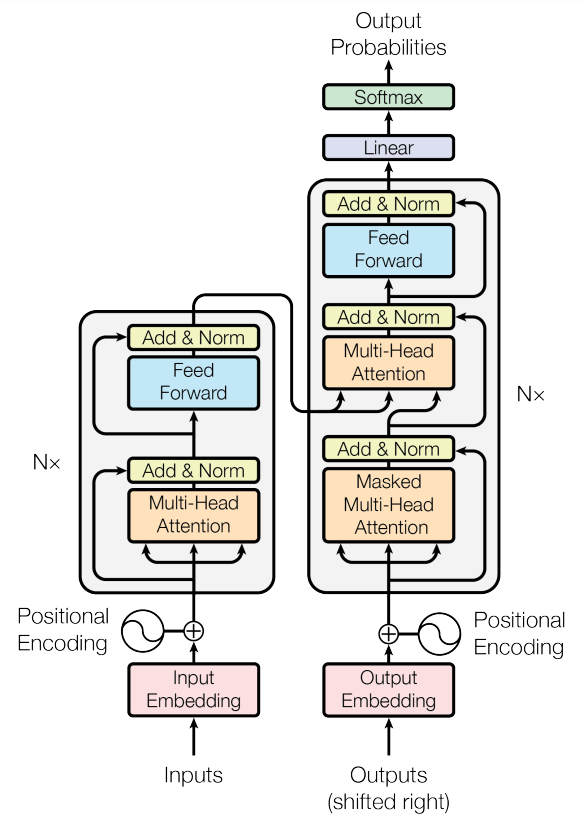
Maskierte Sprachmodelle wie BERT verwenden den Encoder-Teil, der mit zufällig bidirektionalen maskierten Token-Vorhersageaufgaben (und der Vorhersage des nächsten Satzes) vortrainiert wurde. Bei autoregressiven Modellen wie den neuesten LLMs wird der Decoder-Teil normalerweise mit der nächsten Token-Vorhersageaufgabe trainiert, bei der der LM-Verlust minimiert wird:
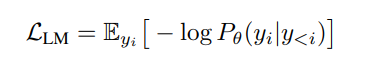
In der obigen Gleichung ist theta der Modellparametersatz und y_i das Token am Index i in einer Sequenz der Länge n. y
Diffusionsmodelle
Was ist das Diffusionsmodell? Es handelt sich um eine Reihe von Deep-Studying-Modellen, die häufig in der Computervision (insbesondere für die medizinische Bildanalyse) zur Bildgenerierung/Rauschunterdrückung und anderen Zwecken verwendet werden. Eines der bekanntesten Diffusionsmodelle ist das DDPM, das aus dem Rauschunterdrückung bei probabilistischen Diffusionsmodellen Artikel veröffentlicht im Jahr 2020. Das Modell ist eine parametrisierte Markow-Kette, die einen Rückwärts- und Vorwärtsübergang enthält, wie unten gezeigt.

Was ist eine Markow-Kette? Es handelt sich um einen statistischen Prozess, bei dem der aktuelle Schritt nur auf dem vorherigen Schritt basiert und umgekehrt. Unter der Annahme eines Markow-Prozesses kann das Modell mit einem sauberen Bild beginnen, indem es im Vorwärtsprozess iterativ Gaußsches Rauschen hinzufügt (rechts -> hyperlinks in der Abbildung oben) und das Rauschen iterativ „lernt“, indem es im Rückwärtsprozess eine Unet-basierte Architektur verwendet (hyperlinks -> rechts in der Abbildung oben). Deshalb können wir das Diffusionsmodell manchmal als generatives Modell (bei Verwendung von hyperlinks nach rechts) und manchmal als Rauschunterdrückungsmodell (bei Verwendung von rechts nach hyperlinks) betrachten. Der DDPM-Verlust ist unten angegeben, wobei Theta der Modellparametersatz, epsilon das bekannte Rauschen und epsilon_theta das von einem Deep-Studying-Modell (normalerweise ein UNet) geschätzte Rauschen ist:
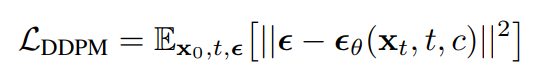
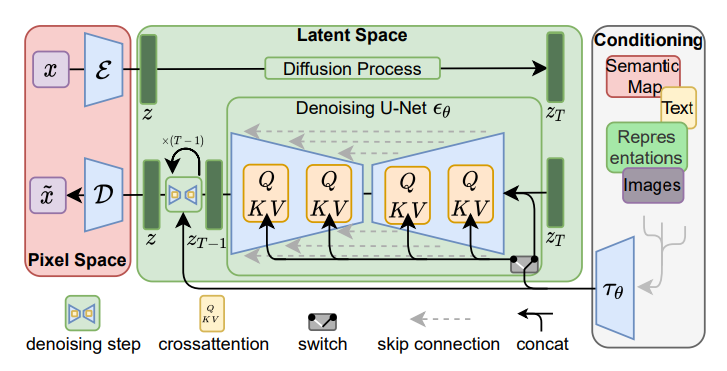
Diffusionsmodell im latenten Raum
Die Idee der Diffusion wurde weiter ausgedehnt auf den latenten Raum in der CVPR‘22-Papierbei dem die Bilder zunächst mithilfe des Encoder-Teils eines vorab trainierten Variationaler Auto-Encoder (VAE). Anschließend werden die Diffusions- und Umkehrprozesse im latenten Raum durchgeführt und mithilfe des Decoderteils des VAE wieder in den Pixelraum abgebildet. Dies könnte die Lerngeschwindigkeit und -effizienz erheblich verbessern, da die meisten Berechnungen in einem Raum mit niedrigerer Dimension durchgeführt werden.
VAE-basierte Bildtransfusion
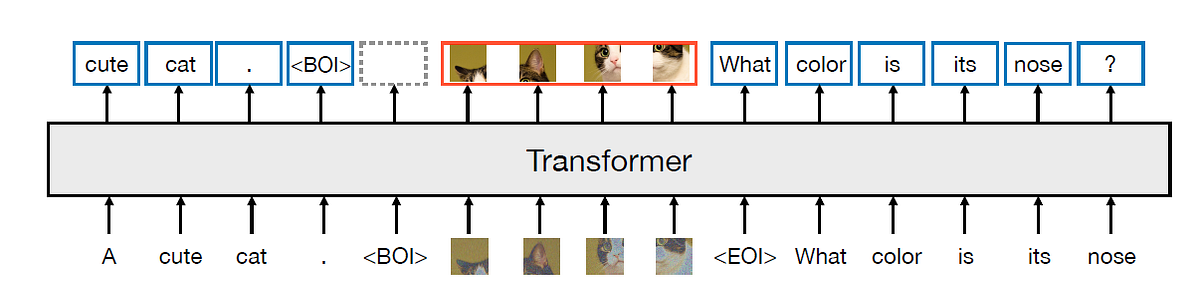
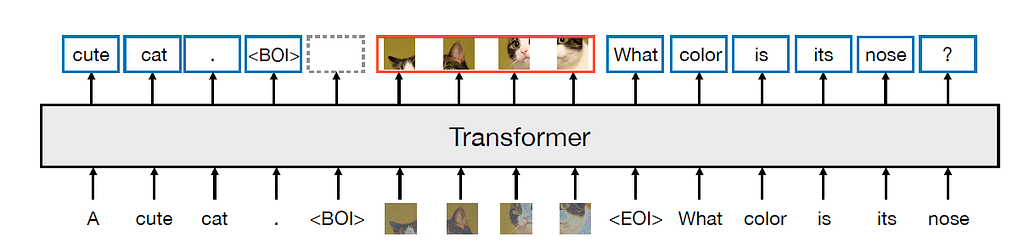
Der Kern des Transfusionsmodells ist die Fusion zwischen der Diffusion und dem Transformator für Eingabebilder. Zunächst wird ein Bild in eine Folge von 8 x 8 Patches aufgeteilt; jeder Patch wird an einen vorab trainierten VAE-Encoder übergeben, um ihn in eine latente Vektordarstellung mit 8 Elementen zu „komprimieren“. Dann wird der latenten Darstellung Rauschen hinzugefügt und von einem linearen Layer/U-Web-Encoder weiter verarbeitet, um das „verrauschte“ x_t zu erzeugen. Drittens verarbeitet das Transformatormodell die Folge verrauschter latenter Darstellungen. Zuletzt werden die Ausgaben von einem weiteren linearen/U-Web-Decoder umgekehrt verarbeitet, bevor ein VAE-Decoder verwendet wird, um das „echte“ x_0-Bild zu erzeugen.
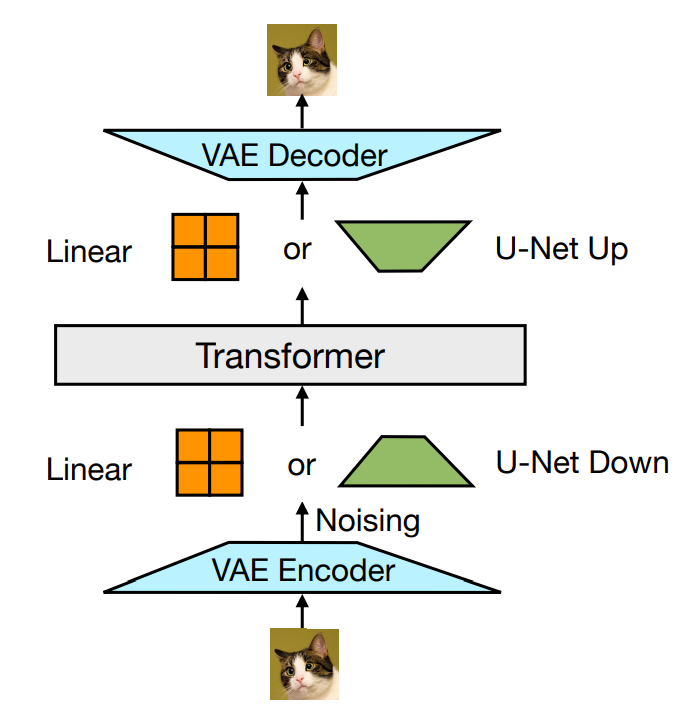
In der tatsächlichen Implementierung werden der Anfangstoken des Bildes (BOI) und der Endtoken des Bildes (EOI) auf beiden Seiten der Bilddarstellungssequenz aufgefüllt, bevor die Texttoken verkettet werden. Die Selbstaufmerksamkeit für das Bildtraining ist eine bidirektionale Aufmerksamkeit, während die Selbstaufmerksamkeit für Texttoken kausal ist. In der Trainingsphase ist der Verlust für die Bildsequenz ein DDPM-Verlust, während der Relaxation der Texttoken den LM-Verlust verwendet.
Warum additionally die Mühe? Warum brauchen wir ein so kompliziertes Verfahren zur Verarbeitung von Bild-Patch-Tokens? Im Dokument wird erklärt, dass der Token-Bereich für Textual content und Bilder unterschiedlich ist. Während die Texttoken diskret sind, sind die Bildtoken/Patches natürlich kontinuierlich. Beim bisherigen Stand der Technik müssen Bild-Token vor der Einfügung in das Transformatormodell „diskretisiert“ werden, während dieses Drawback durch die direkte Integration des Diffusionsmodells gelöst werden könnte.
Vergleich mit dem neuesten Stand der Technik
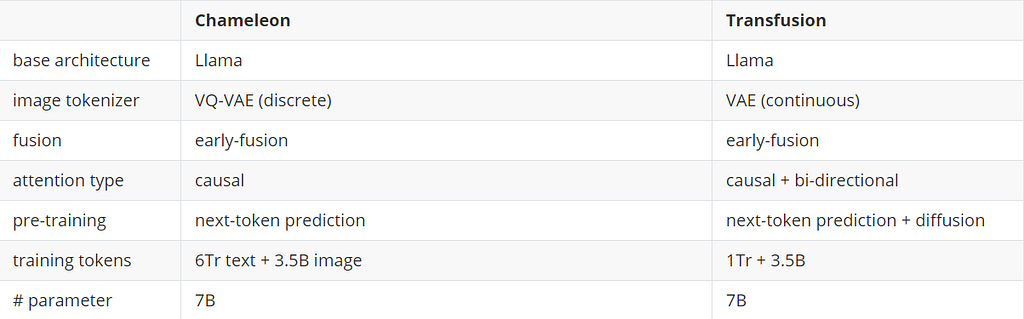
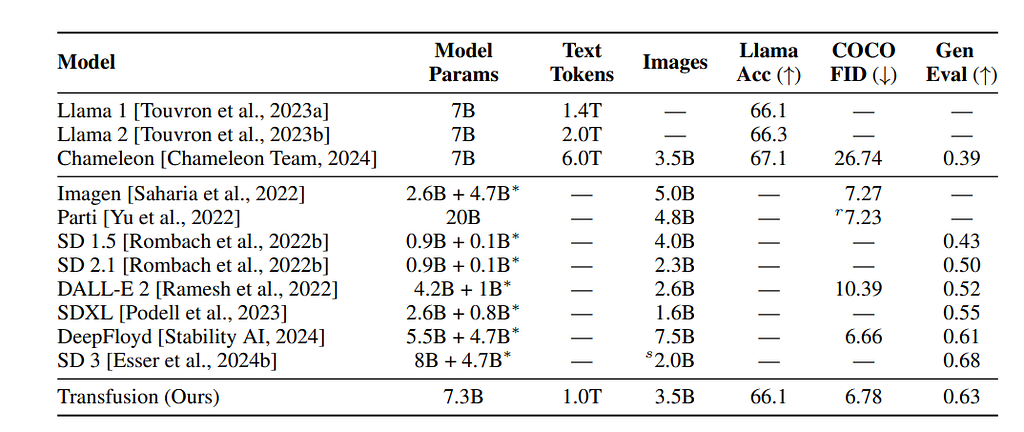
Das primäre multimodale Modell, mit dem das Papier vergleicht, ist das Chamäleon-Modelldas Meta Anfang des Jahres vorgeschlagen hat. Hier vergleichen wir den Unterschied zwischen Architektur und Trainingssatzgröße zwischen Chameleon-7B und Transfusion-7B.
Das Dokument listet den Leistungsvergleich über die Genauigkeit der Llama2-Pre-Coaching-Suite, die COCO Zero-Shot Frechet Inception Distance (FID) und den GenEval-Benchmark auf. Wir können sehen, dass Transfusion bei den bildbezogenen Benchmarks (COCO und Gen) viel besser abschneidet als Chameleon, während es im Vergleich zu Chameleon bei gleicher Anzahl von Parametern nur sehr wenig verliert.
Weitere Kommentare.
Obwohl die Idee des Papiers tremendous interessant ist, ist der „Diffusion“-Teil der Transfusion kaum eine tatsächliche Diffusion, da es im Markov-Prozess nur zwei Zeitstempel gibt. Außerdem macht das vorab trainierte VAE das Modell nicht mehr streng durchgängig. Außerdem sieht das Design VAE + Linear/UNet + Transformer Encoder + Linear/UNet + VAE so kompliziert aus, dass sich das Publikum fragen muss, ob es eine elegantere Möglichkeit gibt, diese Idee umzusetzen. Außerdem habe ich zuvor über die neueste Veröffentlichung von Apple zu den Generalisierungsvorteilen der Verwendung autoregressiver Modellierung auf Bilder, daher könnte es interessant sein, noch einmal über den Ansatz „MIM + autoregressive Modellierung“ nachzudenken.
Wenn du diesen Beitrag interessant findest und darüber diskutieren möchtest, kannst du gerne einen Kommentar hinterlassen und ich freue mich, die Diskussion dort weiterzuführen 🙂
Verweise
- Zhou et al., Transfusion: Vorhersage des nächsten Tokens und diffuser Bilder mit einem multimodalen Modell. arXiv 2024.
- Workforce C. Chameleon: Gemischtmodale Early-Fusion-Grundlagenmodelle. arXiv-Preprint 2024.
- Touvron et al., Llama: Offene und effiziente grundlegende Sprachmodelle. arXiv 2023.
- Rombach et al., Hochauflösende Bildsynthese mit latenten Diffusionsmodellen. CVPR 2022.
- Ho et al., Rauschunterdrückung bei probabilistischen Diffusionsmodellen. NeurIPS 2020.
- Vaswani, Aufmerksamkeit ist alles, was Sie brauchen. NeurIPS 2017.
- Kingma, Automatische Kodierung von Variational Bayes. ArXiv-Vorabdruck 2013.
Transformator? Diffusion? Transfusion! wurde ursprünglich veröffentlicht in Auf dem Weg zur Datenwissenschaft auf Medium, wo die Leute die Unterhaltung fortsetzen, indem sie diese Geschichte hervorheben und darauf reagieren.