
Einführung
Vektor-Streaming wird in EmbedAnything eingeführt, eine Funktion, die das Einbetten von Dokumenten in großem Maßstab optimieren soll. Das Aktivieren von asynchronem Chunking und Einbetten mithilfe der Parallelität von Rust reduziert den Speicherverbrauch und beschleunigt den Prozess. Heute zeige ich, wie man es in die Weaviate-Vektordatenbank integriert, um Bilder nahtlos einzubetten und zu suchen.
In meinem vorherigen Artikel Optimieren Sie Ihre Embeddings-Pipeline mit EmbedAnythingIch habe die Idee hinter EmbedAnything erläutert und wie es das Erstellen von Einbettungen aus mehreren Modalitäten vereinfacht. In diesem Artikel möchte ich eine neue Funktion von EmbedAnything namens Vektor-Streaming vorstellen und zeigen, wie sie mit der Weaviate-Vektordatenbank funktioniert.

Überblick
- Vektor-Streaming in EmbedAnything optimiert das Einbetten großer Dokumente durch asynchrones Chunking mit der Parallelität von Rust.
- Es löst Speicher- und Effizienzprobleme bei herkömmlichen Einbettungsmethoden durch die parallele Verarbeitung von Blöcken.
- Die Integration mit Weaviate ermöglicht die nahtlose Einbettung und Suche in einer Vektordatenbank.
- Die Implementierung von Vektor-Streaming umfasst das Erstellen eines Datenbankadapters, das Initiieren eines Einbettungsmodells und das Einbetten von Daten.
- Dieser Ansatz bietet eine effizientere, skalierbarere und flexiblere Lösung für die Einbettung umfangreicher Dokumente.
Was ist das Downside?
Untersuchen wir zunächst das aktuelle Downside bei der Erstellung von Einbettungen, insbesondere in umfangreichen Dokumenten. Die aktuelle Einbettungsframeworks arbeiten in einem zweistufigen Prozess: Chunking und Embedding. Zuerst wird der Textual content aus allen Dateien extrahiert und Chunks/Knoten werden erstellt. Dann werden diese Chunks einem Embedding-Modell mit einer bestimmten Batch-Größe zugeführt, um die Embeddings zu verarbeiten. Während dies geschieht, verbleiben die Chunks und die Embeddings im Systemspeicher.
Dies ist kein Downside, wenn die Dateien und Einbettungsdimensionen klein sind. Es wird jedoch zu einem Downside, wenn viele Dateien vorhanden sind und Sie mit großen Modellen und, noch schlimmer, mit Multi-Vektor-Einbettungen arbeiten. Um damit arbeiten zu können, ist additionally viel RAM erforderlich, um die Einbettungen zu verarbeiten. Wenn dies synchron erfolgt, geht außerdem viel Zeit verloren, während die Chunks erstellt werden, da das Chunking kein rechenintensiver Vorgang ist. Während die Chunks erstellt werden, wäre es effizient, sie an das Einbettungsmodell zu übergeben.
Unsere Lösung des Issues
Die Lösung besteht darin, eine asynchrone Chunking- und Embedding-Aufgabe zu erstellen. Wir können Threads effektiv erstellen, um diese Aufgabe mithilfe der Parallelitätsmuster und Threadsicherheit von Rust zu bewältigen. Dies geschieht mithilfe von Rusts MPSC-Modul (Multi-producer Single Shopper), das Nachrichten zwischen Threads überträgt. Dadurch wird ein Datenstrom von Chunks erstellt, der mit einem Puffer an den Einbettungsthread übergeben wird. Sobald der Puffer vollständig ist, bettet er die Chunks ein und sendet die Einbettungen zurück an den Hauptthread, der sie dann an die Vektordatenbank sendet. Dadurch wird sichergestellt, dass keine Zeit für einen einzelnen Vorgang verschwendet wird und keine Engpässe auftreten. Darüber hinaus speichert das System nur die Chunks und Einbettungen im Puffer und löscht sie aus dem Speicher, sobald sie in die Vektordatenbank verschoben werden.
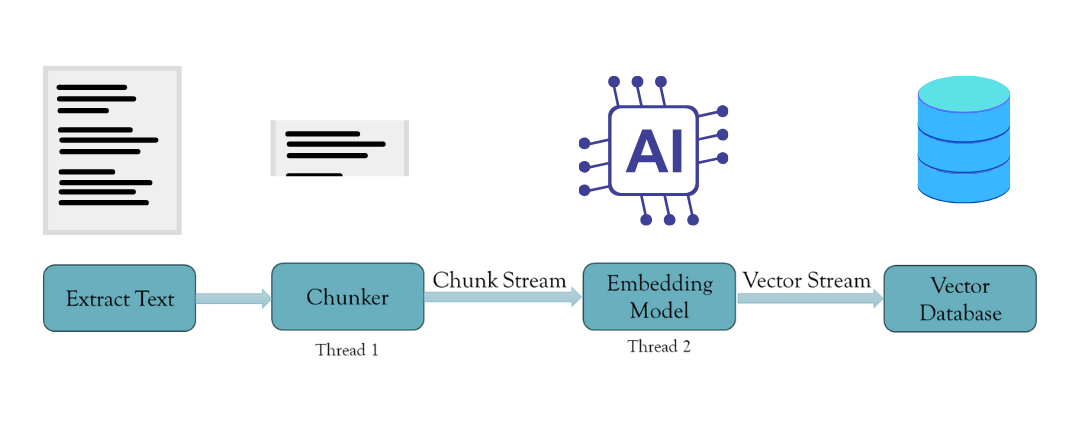
Beispiel-Anwendungsfall mit EmbedAnything
Sehen wir uns diese Funktion nun in Aktion an:
Mit EmbedAnything können Sie die Vektoren aus einem Verzeichnis mit Dateien in das Vektordatenbank ist ein einfacher dreistufiger Prozess.
- Erstellen Sie einen Adapter für Ihre Vektordatenbank: Dies ist ein Wrapper um die Funktionen der Datenbank, der es Ihnen ermöglicht, einen Index zu erstellen, Metadaten vom EmbedAnything-Format in das von der Datenbank benötigte Format zu konvertieren und die Funktion zum Einfügen der Einbettungen in den Index bereitzustellen. Adapter für die wichtigsten Datenbanken wurden bereits erstellt und sind vorhanden. Hier.
- Initiieren Sie ein Einbettungsmodell Ihrer Wahl: Sie können zwischen verschiedenen lokalen Modellen oder sogar Cloud-Modellen wählen. Die Konfiguration kann auch durch Festlegen der Blockgröße und der Puffergröße bestimmt werden, je nachdem, wie viele Einbettungen gleichzeitig gestreamt werden müssen. Idealerweise sollte dies so hoch wie möglich sein, aber der System-RAM begrenzt dies.
- Rufen Sie die Einbettungsfunktion von EmbedAnything auf: Übergeben Sie einfach den einzubettenden Verzeichnispfad, das Einbettungsmodell, den Adapter und die Konfiguration.
In diesem Beispiel betten wir ein Verzeichnis mit Bildern ein und senden es an die Vektordatenbanken.
Schritt 1: Erstellen des Adapters
In EmbedAnything werden die Adapter außerhalb erstellt, um die Bibliothek nicht zu schwer zu machen, und Sie können auswählen, mit welcher Datenbank Sie arbeiten möchten. Hier ist ein einfacher Adapter für Weaviate:
from embed_anything import EmbedData
from embed_anything.vectordb import Adapter
class WeaviateAdapter(Adapter):
def __init__(self, api_key, url):
tremendous().__init__(api_key)
self.shopper = weaviate.connect_to_weaviate_cloud(
cluster_url=url, auth_credentials=wvc.init.Auth.api_key(api_key)
)
if self.shopper.is_ready():
print("Weaviate is prepared")
def create_index(self, index_name: str):
self.index_name = index_name
self.assortment = self.shopper.collections.create(
index_name, vectorizer_config=wvc.config.Configure.Vectorizer.none()
)
return self.assortment
def convert(self, embeddings: Record(EmbedData)):
information = ()
for embedding in embeddings:
property = embedding.metadata
property("textual content") = embedding.textual content
information.append(
wvc.information.DataObject(properties=property, vector=embedding.embedding)
)
return information
def upsert(self, embeddings):
information = self.convert(embeddings)
self.shopper.collections.get(self.index_name).information.insert_many(information)
def delete_index(self, index_name: str):
self.shopper.collections.delete(index_name)
### Begin the shopper and index
URL = "your-weaviate-url"
API_KEY = "your-weaviate-api-key"
weaviate_adapter = WeaviateAdapter(API_KEY, URL)
index_name = "Test_index"
if index_name in weaviate_adapter.shopper.collections.list_all():
weaviate_adapter.delete_index(index_name)
weaviate_adapter.create_index("Test_index")Schritt 2: Erstellen des Einbettungsmodells
Da wir hier Bilder einbetten, können wir das Clip-Modell verwenden
import embed_anything import WhichModel
mannequin = embed_anything.EmbeddingModel.from_pretrained_cloud(
embed_anything.WhichModel.Clip,
model_id="openai/clip-vit-base-patch16")Schritt 3: Verzeichnis einbetten
information = embed_anything.embed_image_directory(
"image_directory",
embeder=mannequin,
adapter=weaviate_adapter,
config=embed_anything.ImageEmbedConfig(buffer_size=100),
)Schritt 4: Abfrage der Vektordatenbank
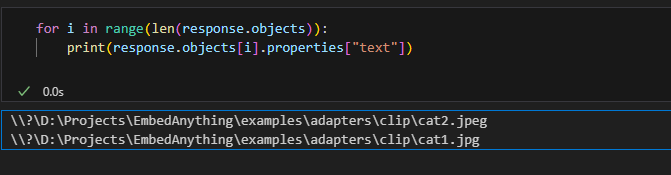
query_vector = embed_anything.embed_query(("picture of a cat"), embeder=mannequin)(0).embeddingSchritt 5: Abfrage der Vektordatenbank
response = weaviate_adapter.assortment.question.near_vector(
near_vector=query_vector,
restrict=2,
return_metadata=wvc.question.MetadataQuery(certainty=True),
)
Test the response;Ausgabe
Mithilfe des Clip-Modells haben wir das gesamte Verzeichnis mit Bildern von Katzen, Hunden und Affen vektorisiert. Mit der einfachen Abfrage „Bilder von Katzen“ konnten wir alle Dateien nach Bildern von Katzen durchsuchen.
Den Code finden Sie im Notizbuch hier auf Zusammenarbeit.
Abschluss
Ich denke, dass Vektor-Streaming eine der Funktionen ist, die viele Ingenieure dazu befähigen wird, sich für eine optimiertere Lösung ohne technische Schulden zu entscheiden. Anstatt sperrige Frameworks in der Cloud zu verwenden, können Sie eine leichte Streaming-Choice nutzen.
Schauen Sie sich das GitHub-Repository hier an: EmbedAnything-Repository.
Häufig gestellte Fragen
Antwort: Vektor-Streaming ist eine Funktion, die das Einbetten von Dokumenten in großem Maßstab optimiert, indem sie die Parallelität von Rust für asynchrones Chunking und Einbetten nutzt, wodurch der Speicherverbrauch reduziert und der Prozess beschleunigt wird.
Antwort: Es behebt den hohen Speicherverbrauch und die Ineffizienz herkömmlicher Einbettungsmethoden, indem es Blöcke asynchron verarbeitet, Engpässe reduziert und die Ressourcennutzung optimiert.
Antwort: Es verwendet einen Adapter, um EmbedAnything mit der Weaviate-Vektordatenbank zu verbinden, was ein nahtloses Einbetten und Abfragen von Daten ermöglicht.
Antwort: Hier sind die Schritte:
1. Erstellen Sie einen Datenbankadapter.
2. Initiieren Sie ein Einbettungsmodell.
3. Betten Sie das Verzeichnis ein.
4. Abfrage der Vektordatenbank.
Antwort: Es bietet im Vergleich zu herkömmlichen Einbettungsmethoden eine bessere Effizienz, einen geringeren Speicherverbrauch, Skalierbarkeit und Flexibilität.
KI-Entwickler @ Serpentine AI || TU Eindhoven Entwicklung von Starlight – semantische Suchmaschine für Home windows in Rust 🦀. Entwicklung von EmbedAnything – eine minimale Einbettungspipeline, die auf Candle basiert. Ich liebe es, beim Coaching großer KI-Modelle zuzusehen.