
Das Panorama von künstliche Intelligenzinsbesondere in der Verarbeitung natürlicher Sprache (NLP) durchläuft mit der Einführung des einen transformativen Wandel Byte Latent Transformer (BLT) und Metas neueste Forschungsarbeit Ich verschütte etwas über das Gleiche. Diese modern Architektur wurde von Forschern bei Meta entwickelt KIstellt die traditionelle Abhängigkeit von der Tokenisierung in großen Sprachmodellen (LLMs) in Frage und ebnet den Weg für eine effizientere und robustere Sprachverarbeitung. In diesem Überblick werden die wichtigsten Merkmale, Vorteile und Auswirkungen des BLT auf die Zukunft untersucht NLPals Grundvoraussetzung für die Morgendämmerung, in der Token wahrscheinlich endgültig ersetzt werden können.
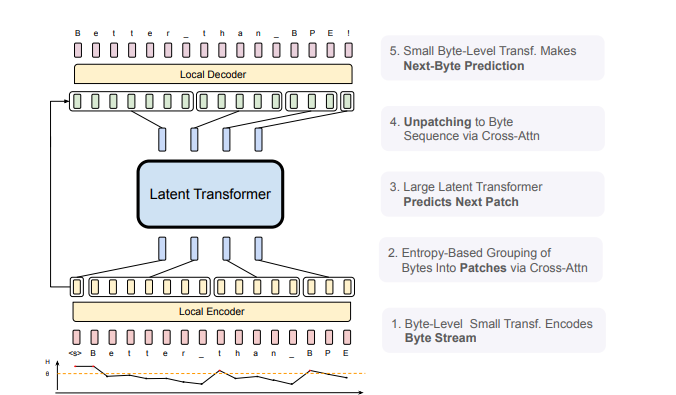
Abbildung 1: BLT-Architektur: Bestehend aus drei Modulen: einem leichten lokalen Encoder, der Eingabebytes in Patch-Darstellungen kodiert, einem rechenintensiven Latent Transformer über Patch-Darstellungen und einem leichten lokalen Decoder zum Dekodieren des nächsten Byte-Patches.
Das Tokenisierungsproblem
Die Tokenisierung warfare ein Eckpfeiler bei der Texterstellung Daten für das Sprachmodelltraining, Konvertieren von Rohtext in einen festen Satz von Token. Diese Methode weist jedoch mehrere Einschränkungen auf:
- Sprachverzerrung: Die Tokenisierung kann zu Ungleichheiten zwischen verschiedenen Sprachen führen und begünstigt häufig diejenigen mit robusteren Tokensätzen.
- Geräuschempfindlichkeit: Behobene Token haben Schwierigkeiten, verrauschte oder abweichende Eingaben genau darzustellen, was die Modellleistung beeinträchtigen kann.
- Eingeschränktes orthographisches Verständnis: Bei der herkömmlichen Tokenisierung werden häufig nuancierte sprachliche Particulars übersehen, die für eine umfassende Darstellung von entscheidender Bedeutung sind Sprachverständnis.
Vorstellung des Byte Latent Transformer
Der BLT begegnet diesen Herausforderungen, indem er Sprache direkt auf Byte-Ebene verarbeitet und so die Notwendigkeit eines festen Vokabulars überflüssig macht. Anstelle vordefinierter Token verwendet es a dynamischer Patch-Mechanismus das Bytes basierend auf ihrer Komplexität und Vorhersagbarkeit gruppiert, gemessen an Entropie. Dadurch kann das Modell Rechenressourcen effektiver zuweisen und sich auf Bereiche konzentrieren, in denen ein tieferes Verständnis erforderlich ist.
Wichtige technische Innovationen
- Dynamisches Byte-Patching: Der BLT segmentiert Byte dynamisch Daten in Patches, die auf ihre Informationskomplexität zugeschnitten sind, wodurch die Recheneffizienz erhöht wird.
- Dreistufige Architektur:
- Leichter lokaler Encoder: Konvertiert Byteströme in Patch-Darstellungen.
- Großer globaler latenter Transformator: Verarbeitet diese Darstellungen auf Patch-Ebene.
- Leichter lokaler Decoder: Übersetzt Patch-Darstellungen zurück in Bytesequenzen.
Hauptvorteile des BLT
- Verbesserte Effizienz: Die BLT-Architektur reduziert die Rechenkosten sowohl beim Coaching als auch bei der Inferenz durch die dynamische Anpassung der Patchgrößen erheblich, was zu einer Reduzierung der Gleitkommaoperationen (FLOPs) um bis zu 50 % im Vergleich zu herkömmlichen Modellen wie Llama 3 führt.
- Robustheit gegenüber Lärm: Durch direktes Arbeiten mit Byte-Ebene DatenDer BLT weist eine verbesserte Widerstandsfähigkeit gegenüber Eingangsrauschen auf und gewährleistet so eine zuverlässige Leistung bei verschiedenen Aufgaben.
- Besseres Verständnis von Unterwortstrukturen: Der Ansatz auf Byte-Ebene ermöglicht die Erfassung komplexer Sprachdetails, die tokenbasierten Modellen möglicherweise entgehen, was besonders nützlich für Aufgaben ist, die ein tiefes phonologisches und orthografisches Verständnis erfordern.
- Skalierbarkeit: Die Architektur ist so konzipiert, dass sie effektiv skaliert werden kann und größere Modelle und Datensätze ohne Leistungseinbußen aufnehmen kann.
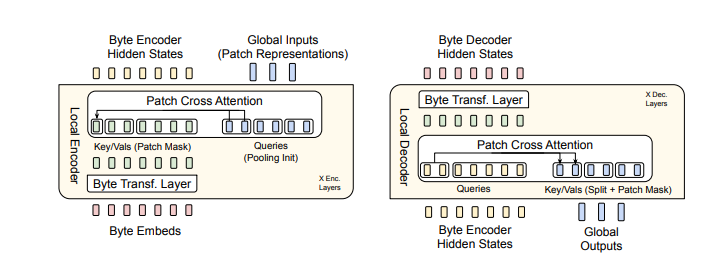
Abbildung 2: BLT nutzt Byte-n-Gram-Einbettungen zusammen mit einem Cross-Consideration-Mechanismus, um den Informationsfluss zwischen dem Latent Transformer und den Modulen auf Byte-Ebene zu verbessern (siehe Abbildung 5). Im Gegensatz zur Tokenisierung mit festem Vokabular organisiert BLT Bytes dynamisch in Patches und behält so den Zugriff auf Informationen auf Byte-Ebene bei.
Experimentelle Ergebnisse
Umfangreiche Experimente haben gezeigt, dass BLT die Leistung etablierter, auf Tokenisierung basierender Modelle erreicht oder übertrifft und gleichzeitig weniger Ressourcen verbraucht. Zum Beispiel:
- Auf dem HellaSwag laut Daten Im Benchmark erreichte Llama 3 eine Genauigkeit von 56,9 %, während der BLT eine Genauigkeit von 64,3 % erreichte.
- Bei Verständnisaufgaben auf Zeichenebene wie Rechtschreibung und semantischen Ähnlichkeitsbenchmarks wurden nahezu perfekte Genauigkeitsraten erreicht.
Diese Ergebnisse unterstreichen das Potenzial des BLT als überzeugende Different NLP Anwendungen.
Auswirkungen auf die reale Welt
Die Einführung des BLT eröffnet spannende Möglichkeiten für:
- Effizienter KI Trainings- und Inferenzprozesse.
- Verbesserter Umgang mit morphologisch reichen Sprachen.
- Verbesserte Leistung bei verrauschten oder abweichenden Eingaben.
- Größere Gerechtigkeit bei der mehrsprachigen Sprachverarbeitung.
Einschränkungen und zukünftige Arbeit
Trotz seines bahnbrechenden Charakters erkennen Forscher mehrere Bereiche für zukünftige Erforschung an:
- Entwicklung von durchgängig erlernten Patching-Modellen.
- Weitere Optimierung der Verarbeitungstechniken auf Byte-Ebene.
- Untersuchung der Skalierungsgesetze speziell für Byte-Degree-Transformatoren.
Abschluss
Der Byte Latent Transformer stellt einen bedeutenden Fortschritt in der Sprachmodellierung dar, indem er über herkömmliche Tokenisierungsmethoden hinausgeht. Seine modern Architektur steigert nicht nur die Effizienz und Robustheit, sondern definiert auch neu, wie KI kann menschliche Sprache verstehen und erzeugen. Während Forscher weiterhin seine Fähigkeiten erforschen, erwarten wir spannende Fortschritte NLP Das wird zu mehr Intelligenz und Anpassungsfähigkeit führen KI Systeme. Zusammenfassend stellt der BLT eine dar Paradigmenwechsel in der Sprachverarbeitung – eine, die die Fähigkeiten der KI zum effektiven Verstehen und Generieren menschlicher Sprache neu definieren könnte.
Der Beitrag Revolutionierung von Sprachmodellen: Der Byte Latent Transformer (BLT) erschien zuerst auf Datenfloq.