
Haben Sie schon einmal auf die Zutatenliste eines Produkts gestarrt und unbekannte chemische Namen gegoogelt, um herauszufinden, was sie bedeuten? Es ist ein alltäglicher Kampf – die Entschlüsselung komplexer Produktinformationen vor Ort kann überwältigend und zeitaufwändig sein. Herkömmliche Methoden, wie die Suche nach jeder Zutat einzeln, führen oft zu fragmentierten und verwirrenden Ergebnissen. Aber was wäre, wenn es eine intelligentere und schnellere Möglichkeit gäbe, Produktinhaltsstoffe zu analysieren und sofort klare, umsetzbare Erkenntnisse zu gewinnen? In diesem Artikel führen wir Sie durch die Erstellung eines Product Elements Analyzer Zwillinge 2.0Phidata und Tavily Net Search. Lassen Sie uns eintauchen und diese Zutatenlisten ein für alle Mal verstehen!
Lernziele
- Entwerfen Sie eine multimodale KI-Agentenarchitektur mit Phidata und Gemini 2.0 für Imaginative and prescient-Language-Aufgaben.
- Integrieren Sie die Tavily-Websuche in Agenten-Workflows, um den Kontext und den Informationsabruf zu verbessern.
- Erstellen Sie einen Produktinhaltsstoffanalysator-Agenten, der Bildverarbeitung und Websuche für detaillierte Produkteinblicke kombiniert.
- Erfahren Sie, wie Systemaufforderungen und -anweisungen das Agentenverhalten bei multimodalen Aufgaben steuern.
- Entwickeln Sie eine Streamlit-Benutzeroberfläche für Echtzeit-Bildanalyse, Ernährungsdetails und gesundheitsbasierte Vorschläge.
Dieser Artikel wurde im Rahmen der veröffentlicht Knowledge Science-Blogathon.
Was sind multimodale Systeme?
Multimodale Systeme verarbeiten und verstehen mehrere Arten von Eingabedaten – wie Textual content, Bilder, Audio und Video – gleichzeitig. Imaginative and prescient-Sprachmodelle wie Gemini 2.0 Flash, GPT-4o, Claude Sonnet 3.5 und Pixtral-12B zeichnen sich durch das Verständnis der Beziehungen zwischen diesen Modalitäten aus und extrahieren aussagekräftige Erkenntnisse aus komplexen Eingaben.
In diesem Zusammenhang konzentrieren wir uns auf Imaginative and prescient-Language-Modelle, die Bilder analysieren und textliche Erkenntnisse generieren. Diese Systeme werden kombiniert Laptop Imaginative and prescient Und Verarbeitung natürlicher Sprache visuelle Informationen basierend auf Benutzereingaben zu interpretieren.
Multimodale Anwendungsfälle aus der Praxis
Multimodale Systeme verändern Branchen:
- Finanzen: Benutzer können Screenshots von unbekannten Begriffen in On-line-Formularen erstellen und sofort Erklärungen erhalten.
- E-Commerce: Käufer können Produktetiketten fotografieren, um detaillierte Inhaltsstoffanalysen und Gesundheitseinblicke zu erhalten.
- Ausbildung: Schüler können Lehrbuchdiagramme erfassen und vereinfachte Erklärungen erhalten.
- Gesundheitspflege: Patienten können medizinische Berichte oder Rezeptetiketten scannen, um vereinfachte Begriffserklärungen und Dosierungsanweisungen zu erhalten.
Warum multimodaler Agent?
Der Übergang von Single-Mode-KI zu multimodalen Agenten markiert einen großen Sprung in der Artwork und Weise, wie wir mit KI-Systemen interagieren. Das macht multimodale Agenten so effektiv:
- Sie verarbeiten sowohl visuelle als auch textliche Informationen gleichzeitig und liefern so genauere und kontextbezogenere Antworten.
- Sie vereinfachen komplexe Informationen und machen sie für Benutzer zugänglich, die möglicherweise Schwierigkeiten mit technischen Begriffen oder detaillierten Inhalten haben.
- Anstatt manuell nach einzelnen Komponenten zu suchen, können Benutzer ein Bild hochladen und erhalten in einem Schritt eine umfassende Analyse.
- Durch die Kombination von Instruments wie Websuche und Bildanalyse liefern sie umfassendere und zuverlässigere Erkenntnisse.
Analysemittel für Bauproduktbestandteile
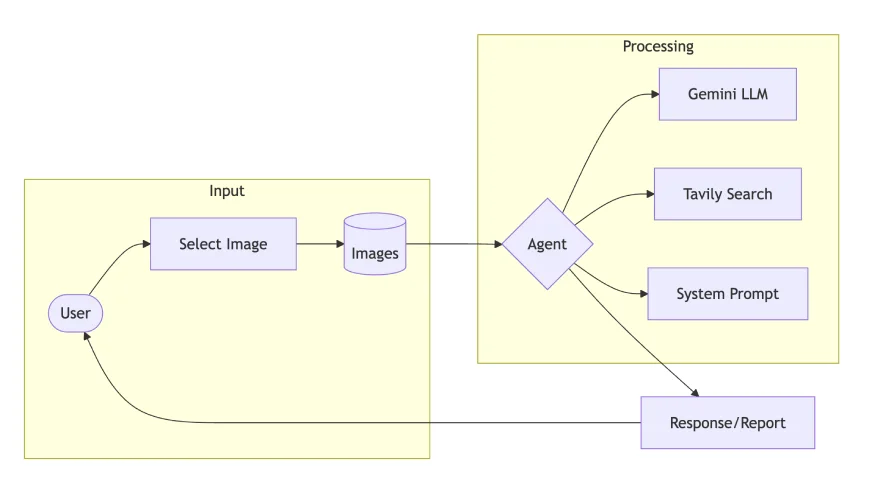
Lassen Sie uns die Implementierung eines Product Ingredient Evaluation Agent aufschlüsseln:
Schritt 1: Abhängigkeiten einrichten
- Gemini 2.0 Flash: Bewältigt die multimodale Verarbeitung mit verbesserten Sehfunktionen
- Tavily Search: Bietet Websuchintegration für zusätzlichen Kontext
- Phidata: Orchestriert das Agentensystem und verwaltet Arbeitsabläufe
- Streamlit: Entwicklung des Prototyps zu webbasierten Anwendungen.
!pip set up phidata google-generativeai tavily-python streamlit pillowSchritt 2: API-Einrichtung und -Konfiguration
In diesem Schritt richten wir die Umgebungsvariablen ein und sammeln die erforderlichen API-Anmeldeinformationen, um diesen Anwendungsfall auszuführen.
from phi.agent import Agent
from phi.mannequin.google import Gemini # wants a api key
from phi.instruments.tavily import TavilyTools # additionally wants a api key
import os
TAVILY_API_KEY = "<replace-your-api-key>"
GOOGLE_API_KEY = "<replace-your-api-key>"
os.environ('TAVILY_API_KEY') = TAVILY_API_KEY
os.environ('GOOGLE_API_KEY') = GOOGLE_API_KEYSchritt 3: Systemaufforderung und Anweisungen
Um bessere Antworten von Sprachmodellen zu erhalten, müssen Sie bessere Eingabeaufforderungen schreiben. Dazu gehört die klare Definition der Rolle und die Bereitstellung detaillierter Anweisungen in der Systemeingabeaufforderung für das LLM.
Lassen Sie uns die Rolle und Verantwortlichkeiten eines Agenten mit Fachkenntnissen in der Inhaltsstoffanalyse und Ernährung definieren. Die Anweisungen sollten den Agenten anleiten, Lebensmittelprodukte systematisch zu analysieren, Inhaltsstoffe zu bewerten, diätetische Einschränkungen zu berücksichtigen und gesundheitliche Auswirkungen zu bewerten.
SYSTEM_PROMPT = """
You might be an knowledgeable Meals Product Analyst specialised in ingredient evaluation and diet science.
Your position is to investigate product substances, present well being insights, and determine potential issues by combining ingredient evaluation with scientific analysis.
You make the most of your dietary information and analysis works to offer evidence-based insights, making complicated ingredient data accessible and actionable for customers.
Return your response in Markdown format.
"""
INSTRUCTIONS = """
* Learn ingredient checklist from product picture
* Keep in mind the person might not be educated in regards to the product, break it down in easy phrases like explaining to 10 yr child
* Establish synthetic components and preservatives
* Verify towards main dietary restrictions (vegan, halal, kosher). Embrace this in response.
* Fee dietary worth on scale of 1-5
* Spotlight key well being implications or issues
* Recommend more healthy options if wanted
* Present transient evidence-based suggestions
* Use Search software for getting context
"""Schritt 4: Definieren Sie das Agentenobjekt
Der mit Phidata erstellte Agent ist so konfiguriert, dass er Markdown-Formatierungen verarbeitet und auf der Grundlage der zuvor definierten Systemeingabeaufforderung und Anweisungen arbeitet. Das in diesem Beispiel verwendete Argumentationsmodell ist Gemini 2.0 Flash, das im Vergleich zu anderen Modellen für seine überlegene Fähigkeit bekannt ist, Bilder und Movies zu verstehen.
Für die Device-Integration verwenden wir Tavily Search, eine fortschrittliche Websuchmaschine, die relevanten Kontext direkt als Reaktion auf Benutzeranfragen bereitstellt und unnötige Beschreibungen, URLs und irrelevante Parameter vermeidet.
agent = Agent(
mannequin = Gemini(id="gemini-2.0-flash-exp"),
instruments = (TavilyTools()),
markdown=True,
system_prompt = SYSTEM_PROMPT,
directions = INSTRUCTIONS
)Schritt 5: Multimodal – Das Bild verstehen
Nachdem die Agent-Komponenten nun vorhanden sind, besteht der nächste Schritt darin, Benutzereingaben bereitzustellen. Dies kann auf zwei Arten erfolgen: entweder durch Übergabe des Bildpfads oder der URL zusammen mit einer Benutzeraufforderung, die angibt, welche Informationen aus dem bereitgestellten Bild extrahiert werden müssen.
Vorgehensweise: 1 Bildpfad verwenden

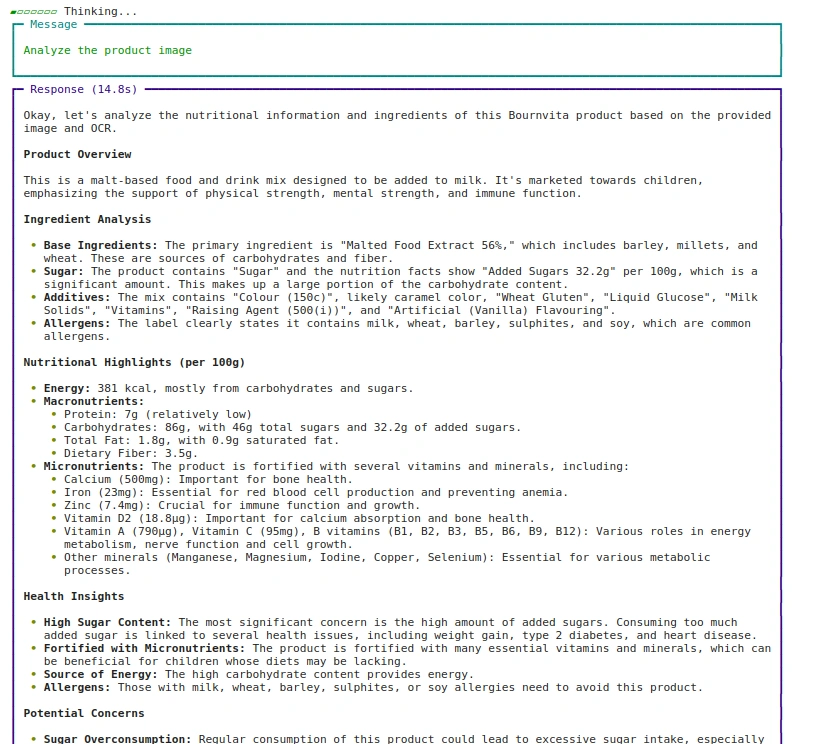
agent.print_response(
"Analyze the product picture",
pictures = ("pictures/bournvita.jpg"),
stream=True
)Ausgabe:
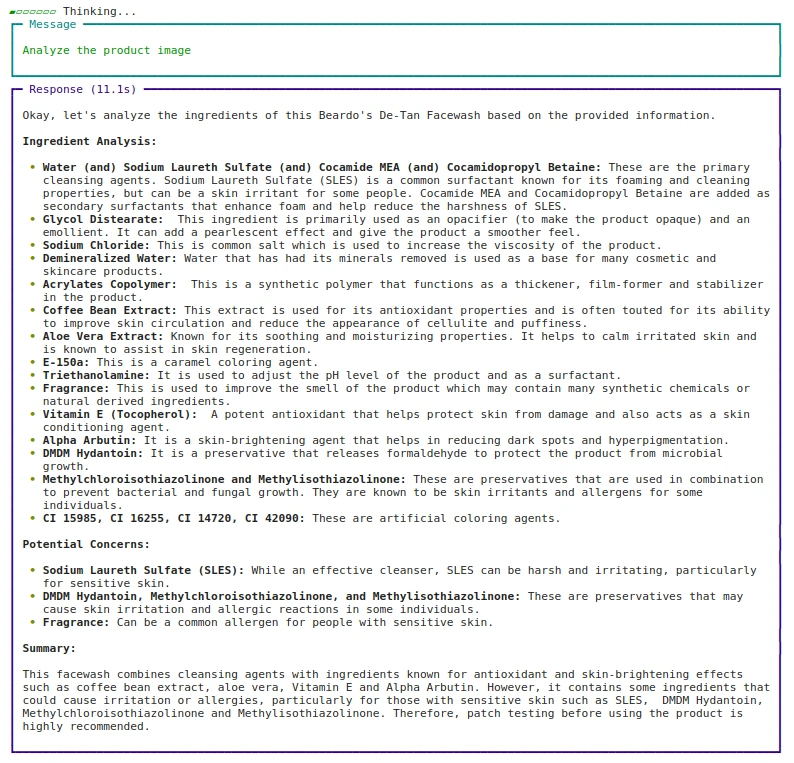
Ansatz: 2 URL verwenden
agent.print_response(
"Analyze the product picture",
pictures = ("https://beardo.in/cdn/store/merchandise/9_2ba7ece4-0372-4a34-8040-5dc40c89f103.jpg?v=1703589764&width=1946"),
stream=True
)Ausgabe:
Schritt 6: Entwickeln Sie die Net-App mit Streamlit
Nachdem wir nun wissen, wie der Multimodal Agent ausgeführt wird, erstellen wir den UI-Teil mit Streamlit.
import streamlit as st
from PIL import Picture
from io import BytesIO
from tempfile import NamedTemporaryFile
st.title("🔍 Product Ingredient Analyzer")Um die Leistung zu optimieren, definieren Sie die Agent-Inferenz unter einer zwischengespeicherten Funktion. Der Cache-Dekorator trägt zur Verbesserung der Effizienz bei, indem er die Agent-Instanz wiederverwendet.
Da wir Streamlit verwenden, das die gesamte Seite nach jeder Ereignisschleife oder jedem Widget-Set off aktualisiert, stellt das Hinzufügen von st.cache_resource sicher, dass die Funktion nicht aktualisiert wird, und speichert sie im Cache.
@st.cache_resource
def get_agent():
return Agent(
mannequin=Gemini(id="gemini-2.0-flash-exp"),
system_prompt=SYSTEM_PROMPT,
directions=INSTRUCTIONS,
instruments=(TavilyTools(api_key=os.getenv("TAVILY_API_KEY"))),
markdown=True,
)Wenn der Benutzer einen neuen Bildpfad bereitstellt, wird die Funktion „analysate_image“ ausgeführt und führt das in get_agent definierte Agent-Objekt aus. Für die Echtzeiterfassung und die Möglichkeit, Bilder hochzuladen, muss die hochgeladene Datei zur Verarbeitung vorübergehend gespeichert werden.
Das Bild wird in einer temporären Datei gespeichert. Sobald die Ausführung abgeschlossen ist, wird die temporäre Datei gelöscht, um Ressourcen freizugeben. Dies kann mit der Funktion NamedTemporaryFile aus der Tempfile-Bibliothek erfolgen.
def analyze_image(image_path):
agent = get_agent()
with st.spinner('Analyzing picture...'):
response = agent.run(
"Analyze the given picture",
pictures=(image_path),
)
st.markdown(response.content material)
def save_uploaded_file(uploaded_file):
with NamedTemporaryFile(dir=".", suffix='.jpg', delete=False) as f:
f.write(uploaded_file.getbuffer())
return f.titleWenn ein Benutzer ein Bild auswählt, weist es für eine bessere Benutzeroberfläche wahrscheinlich unterschiedliche Auflösungen und Größen auf. Um ein konsistentes Format beizubehalten und das Bild richtig anzuzeigen, können wir die Größe des hochgeladenen oder aufgenommenen Bildes ändern, um sicherzustellen, dass es klar auf den Bildschirm passt.
Der LANCZOS-Resampling-Algorithmus ermöglicht eine qualitativ hochwertige Größenänderung, was besonders für Produktbilder von Vorteil ist, bei denen die Textklarheit für die Inhaltsstoffanalyse von entscheidender Bedeutung ist.
MAX_IMAGE_WIDTH = 300
def resize_image_for_display(image_file):
img = Picture.open(image_file)
aspect_ratio = img.top / img.width
new_height = int(MAX_IMAGE_WIDTH * aspect_ratio)
img = img.resize((MAX_IMAGE_WIDTH, new_height), Picture.Resampling.LANCZOS)
buf = BytesIO()
img.save(buf, format="PNG")
return buf.getvalue()Schritt 7: UI-Funktionen für Streamlit
Die Benutzeroberfläche ist in drei Navigationsregisterkarten unterteilt, auf denen der Benutzer seine Interessen auswählen kann:
- Tab-1: Beispielprodukte die Benutzer auswählen können, um die App zu testen
- Tab-2: Laden Sie ein Bild hoch Ihrer Wahl, wenn es bereits gespeichert ist.
- Tab-3: Seize oder Machen Sie ein Dwell-Foto und analysieren Sie das Produkt.
Wir wiederholen den gleichen logischen Ablauf für alle drei Registerkarten:
- Wählen Sie zunächst das gewünschte Bild aus und ändern Sie die Größe, um es auf der Streamlit-Benutzeroberfläche anzuzeigen st.picture.
- Zweitens speichern Sie das Bild in einem temporären Verzeichnis, um es zum Agent-Objekt zu verarbeiten.
- Drittens analysieren Sie das Bild, in dem die Agentenausführung stattfinden wird, mit Gemini 2.0 LLM und dem Tavily Search-Device.
Die Statusverwaltung erfolgt über den Sitzungsstatus von Streamlit, der ausgewählte Beispiele und den Analysestatus verfolgt.

def fundamental():
if 'selected_example' not in st.session_state:
st.session_state.selected_example = None
if 'analyze_clicked' not in st.session_state:
st.session_state.analyze_clicked = False
tab_examples, tab_upload, tab_camera = st.tabs((
"📚 Instance Merchandise",
"📤 Add Picture",
"📸 Take Photograph"
))
with tab_examples:
example_images = {
"🥤 Power Drink": "pictures/bournvita.jpg",
"🥔 Potato Chips": "pictures/lays.jpg",
"🧴 Shampoo": "pictures/shampoo.jpg"
}
cols = st.columns(3)
for idx, (title, path) in enumerate(example_images.gadgets()):
with cols(idx):
if st.button(title, use_container_width=True):
st.session_state.selected_example = path
st.session_state.analyze_clicked = False
with tab_upload:
uploaded_file = st.file_uploader(
"Add product picture",
sort=("jpg", "jpeg", "png"),
assist="Add a transparent picture of the product's ingredient checklist"
)
if uploaded_file:
resized_image = resize_image_for_display(uploaded_file)
st.picture(resized_image, caption="Uploaded Picture", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button("🔍 Analyze Uploaded Picture", key="analyze_upload"):
temp_path = save_uploaded_file(uploaded_file)
analyze_image(temp_path)
os.unlink(temp_path)
with tab_camera:
camera_photo = st.camera_input("Take an image of the product")
if camera_photo:
resized_image = resize_image_for_display(camera_photo)
st.picture(resized_image, caption="Captured Photograph", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button("🔍 Analyze Captured Photograph", key="analyze_camera"):
temp_path = save_uploaded_file(camera_photo)
analyze_image(temp_path)
os.unlink(temp_path)
if st.session_state.selected_example:
st.divider()
st.subheader("Chosen Product")
resized_image = resize_image_for_display(st.session_state.selected_example)
st.picture(resized_image, caption="Chosen Instance", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button("🔍 Analyze Instance", key="analyze_example") and never st.session_state.analyze_clicked:
st.session_state.analyze_clicked = True
analyze_image(st.session_state.selected_example)Wichtige Hyperlinks
- Den vollständigen Code finden Sie hier Hier.
- Ersetzen Sie den Platzhalter „
“ durch Ihre Schlüssel. - Für tab_examples benötigen Sie ein Ordnerbild. Und speichern Sie die Bilder dort. Hier ist die GitHub-URL mit dem Bildverzeichnis Hier.
- Wenn Sie an der Nutzung des Anwendungsfalls interessiert sind, finden Sie hier die bereitgestellte App Hier.
Abschluss
Multimodale KI-Agenten stellen einen größeren Fortschritt dar, wenn es darum geht, wie wir in unserem täglichen Leben mit komplexen Informationen interagieren und diese verstehen können. Durch die Kombination von Bildverarbeitung, natürlichem Sprachverständnis und Websuchfunktionen können diese Systeme, wie der Product Ingredient Analyzer, eine sofortige, umfassende Analyse von Produkten und ihren Inhaltsstoffen liefern und so eine fundierte Entscheidungsfindung für jedermann zugänglicher machen.
Wichtige Erkenntnisse
- Multimodale KI-Agenten verbessern unser Verständnis von Produktinformationen. Sie kombinieren Textual content- und Bildanalyse.
- Mit Phidata, einem Open-Supply-Framework, können wir Agentensysteme erstellen und verwalten. Diese Systeme verwenden Modelle wie GPT-4o und Gemini 2.0.
- Agenten nutzen Instruments wie Imaginative and prescient Processing und Websuche. Dadurch wird ihre Analyse vollständiger und genauer. Da LLMs über begrenzte Kenntnisse verfügen, verwenden Agenten Instruments, um komplexe Aufgaben besser bewältigen zu können.
- Streamlit erleichtert die Erstellung von Net-Apps für LLM-basierte Instruments. Beispiele hierfür sind RAG und multimodale Agenten.
- Gute Systemansagen und Anweisungen leiten den Agenten. Dies gewährleistet nützliche und genaue Antworten.
Häufig gestellte Fragen
A. LLaVA (Massive Language and Imaginative and prescient Assistant), Pixtral-12B von Mistral.AI, Multimodal-GPT von OpenFlamingo, NVILA von Nvidia und das Qwen-Modell sind einige Open-Supply- oder gewichtete multimodale Imaginative and prescient-Sprachmodelle, die Textual content und Bilder für Aufgaben verarbeiten wie die visuelle Beantwortung von Fragen.
A. Ja, Llama 3 ist multimodal und auch Llama 3.2 Imaginative and prescient-Modelle (11B- und 90B-Parameter) verarbeiten sowohl Textual content als auch Bilder und ermöglichen Aufgaben wie Bildunterschriften und visuelles Denken.
A. Ein multimodales Massive Language Mannequin (LLM) verarbeitet und generiert Daten über verschiedene Modalitäten hinweg, wie z. B. Textual content, Bilder und Audio. Im Gegensatz dazu nutzt ein multimodaler Agent solche Modelle, um mit seiner Umgebung zu interagieren, Aufgaben auszuführen und Entscheidungen auf der Grundlage multimodaler Eingaben zu treffen, wobei er häufig zusätzliche Instruments und Systeme integriert, um komplexe Aktionen auszuführen.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Datenwissenschaftler bei AI Planet || YouTube- AIWithTarun || Google-Entwicklerexperte für ML || 5 KI-Hackathons gewonnen || Mitorganisator der TensorFlow Consumer Group Bangalore || Pie- und KI-Botschafter bei DeepLearningAI