Beiträge dieser Arbeit
Dieses Papier bietet sowohl eine aufschlussreiche Analyse der Trainingsdynamik auf Token-Ebene als auch eine neue Technik namens SLM:
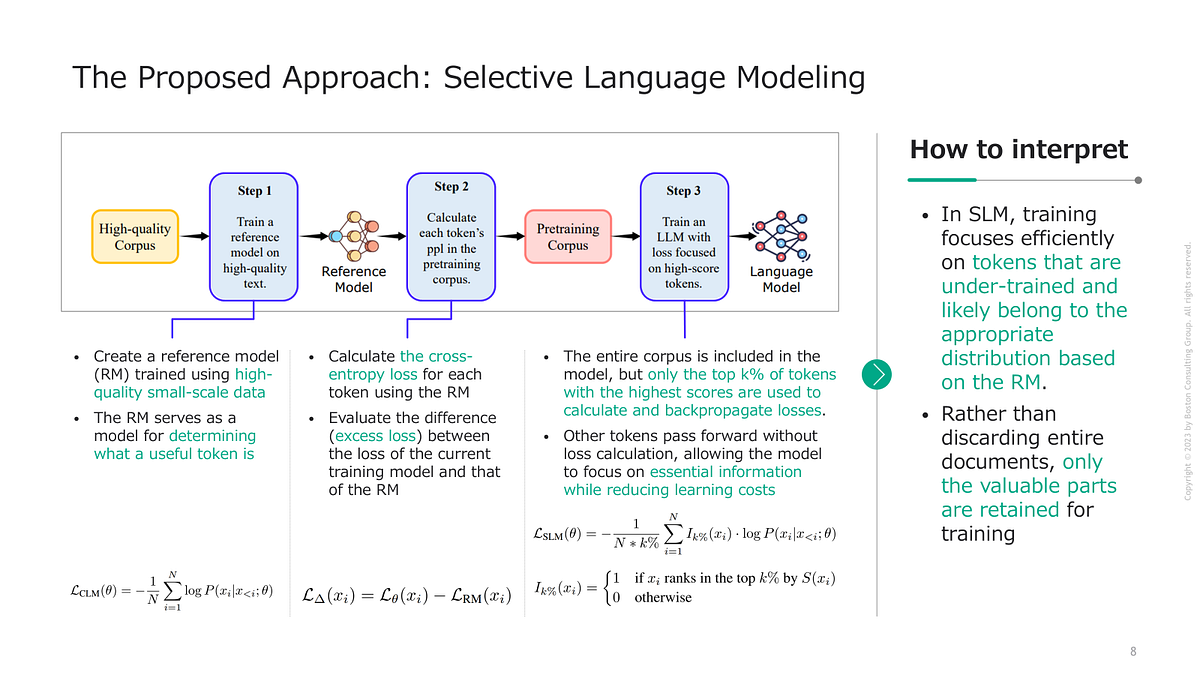
Token -Verlustanalyse:
Sie zeigen, dass ein Großteil der Token nur wenig über die anfängliche Trainingsphase hinausgeht, während eine kleine Untergruppe anhaltend hoher Verlust bleibt.
SLM für fokussiertes Lernen:
Durch die Nutzung eines Referenzmodells, um festzustellen, wie „nützlich“ jedes Token ist Trainingstoken drastisch reduzieren Ohne die Qualität zu beeinträchtigen – in vielen Fällen sogar die nachgelagerte Leistung steigern.
Breite Demonstration der Wirksamkeit:
SLM arbeitet nicht nur auf mathematische Aufgaben, sondern auch in allgemeineren Bereichen mit einem akribisch kuratierten Referenzdatensatz oder einem Referenzmodell aus demselben großen Korpus.
Wohin könnte das als nächstes gehen?
SLM umfasst verschiedene potenzielle Richtungen für zukünftige Forschung. Zum Beispiel:
Weiter aufbauen:
Obwohl sich das Papier hauptsächlich auf Modelle von 1B bis 7B -Parametern konzentriert, bleibt die offene Frage, wie SLM auf der Skala 30B, 70B oder 100B+ funktioniert. Wenn sich der Ansatz auf Token-Ebene intestine verallgemeinert, könnten die Kosteneinsparungen für wirklich huge LLMs enorm sein.
Referenzmodelle über API:
Wenn Sie kuratierte Daten nicht sammeln können, können Sie möglicherweise ein API-basierter Sprachmodell als Referenz verwenden. Dies könnte SLM für kleinere Forschungsteams, denen die Ressourcen für selektives Referenztraining fehlen, praktischer machen.
Verstärkungslernenverlängerungen:
Stellen Sie sich vor, Sie haben SLM mit Verstärkungslernen. Das Referenzmodell könnte als „Belohnungsmodell“ fungieren, und die Token -Auswahl könnte dann durch etwas optimiert werden, das mit politischen Gradienten ähnelt.
Mehrere Referenzmodelle:
Anstelle eines einzelnen RM können Sie trainieren oder versammeln mehrerejeweils konzentriert sich auf eine andere Domäne oder einen anderen Stil. Kombinieren Sie dann ihre Token-Scores, um ein robusteres Multi-Domänen-Filtersystem zu erzeugen.
Ausrichtung und Sicherheit:
Es gibt einen wachsenden Development zur Berücksichtigung der Ausrichtung oder Wahrhaftigkeit. Man könnte ein Referenzmodell trainieren, um intestine unterstützte Aussagen und Null-Out-Token, die sachlich inkorrekt oder schädlich aussehen, höhere Punktzahlen zu verleihen.