
In der Welt des maschinellen Lernens besessen wir über Modellarchitekturen, Trainingspipelines und Hyper-Parameter-Tuning und übersehen jedoch oft einen grundlegenden Aspekt: Wie unsere Merkmale während ihres gesamten Lebenszyklus leben und atmen. Von In-Reminiscence-Berechnungen, die nach jeder Vorhersage bis zur Herausforderung der Reproduktion der genauen Merkmalswerte Monate später verschwinden, kann die Artwork und Weise, wie wir mit Merkmalen umgehen, die Zuverlässigkeit und Skalierbarkeit unserer ML-Systeme erstellen oder brechen.
Wer sollte das lesen
- ML -Ingenieure, die ihren Function -Administration -Ansatz bewerten
- Datenwissenschaftler, die schäbige Probleme haben, die bei der Schulung auftraten
- Technische Leads Planen zur Skalierung ihrer ML -Operationen
- Groups überlegen Function Retailer Durchführung
Ausgangspunkt: Der unsichtbare Ansatz
Viele ML -Groups, insbesondere diejenigen in ihren frühen Stadien oder ohne dedizierte ML -Ingenieure, beginnen mit dem, was ich als „unsichtbarer Ansatz“ bezeichne, um Engineering zu erzielen. Es ist täuschend einfach: Rohdaten abrufen, sie in Reminiscence transformieren und im laufenden Fliegen Funktionen erstellen. Der resultierende Datensatz ist zwar funktional, aber im Wesentlichen eine schwarze Schachtel mit kurzlebigen Berechnungen-Merkmale, die nur für einen Second existieren, bevor nach jeder Vorhersage oder jeder Trainingsanlage verschwindet.
Obwohl dieser Ansatz die Arbeit erledigt scheint, basiert er auf wackeligem Boden. Da Groups ihre ML -Operationen skalieren, verhalten sich Modelle, die sich hervorragend im Testen entwickelten, plötzlich unvorhersehbar in der Produktion. Merkmale, die beim Coaching perfekt funktionierten, erzeugen auf mysteriöse Weise unterschiedliche Werte in Stay -Inferenz. Wenn die Stakeholder fragen, warum im letzten Monat eine bestimmte Vorhersage getroffen wurde, können Groups nicht in der Lage sind, die genauen Merkmalswerte zu rekonstruieren, die zu dieser Entscheidung geführt haben.
Kernherausforderungen in der Function Engineering
Diese Schmerzpunkte sind nicht nur für ein einzelnes Crew einzigartig. Sie stellen grundlegende Herausforderungen dar, denen sich jedes wachsende ML -Crew schließlich gegenübersieht.
- Beobachtbarkeit
Ohne materialisierte Merkmale wird das Debuggen zu einer Detektivmission. Stellen Sie sich vor zu verstehen, warum ein Modell vor Monaten eine bestimmte Vorhersage gemacht hat, nur um festzustellen, dass die Merkmale hinter dieser Entscheidung längst verschwunden sind. Die Beobachtbarkeit von Merkmalen ermöglicht auch eine kontinuierliche Überwachung, sodass Groups Verschlechterung oder in Bezug auf Tendencies in ihren Function -Verteilungen im Laufe der Zeit erkennen können. - Zeitkorrektheit
Wenn Funktionen, die im Coaching verwendet werden, nicht mit denen übereinstimmen, die während der Inferenz generiert wurden, was zum berüchtigten Trainingsersatz geführt wird. Hier geht es nicht nur um Datengenauigkeit, sondern darum, dass Ihr Modell wie während des Trainings auf die gleichen Funktionen in der Produktion trifft. - Wiederverwendbarkeit
Das wiederholte Berechnen der gleichen Merkmale über verschiedene Modelle hinweg wird zunehmend verschwenderisch. Wenn Function -Berechnungen starke Rechenressourcen beinhalten, ist diese Ineffizienz nicht nur eine Unannehmlichkeit, sondern eine erhebliche Abfluss für Ressourcen.
Entwicklung von Lösungen
Ansatz 1: On-Demand-Function-Generierung
Die einfachste Lösung beginnt, wenn viele ML -Groups beginnen: Erstellen von Funktionen bei Bedarf nach sofortiger Verwendung bei der Vorhersage. Die Rohdaten fließen durch Transformationen, um Funktionen zu generieren, die für Inferenz verwendet werden. Erst dann werden diese Funktionen in der Regel in Parquetendateien gespeichert. Diese Methode ist zwar unkompliziert, da Groups häufig Parquetendateien auswählen, da sie einfach aus In-Reminiscence-Daten erstellen können, enthält sie Einschränkungen. Der Ansatz löst die Beobachtbarkeit teilweise, da Merkmale gespeichert werden. Die Analyse dieser Funktionen wird jedoch später eine Herausforderung. Das Abfragen von Daten in mehreren Parquetendateien erfordert bestimmte Instruments und eine sorgfältige Organisation Ihrer gespeicherten Dateien.

Ansatz 2: Merkmalstabelle Materialisierung
Während sich die Groups weiterentwickeln, wechseln viele zu dem, was allgemein on-line als Various zu vollwertigen Function-Shops: Function-Desk-Materialisierung diskutiert wird. Dieser Ansatz nutzt die vorhandene Knowledge Warehouse -Infrastruktur, um Funktionen zu transformieren und zu speichern, bevor sie benötigt werden. Stellen Sie sich es als ein zentrales Repository vor, in dem Merkmale konsistent durch etablierte ETL -Pipelines berechnet und dann sowohl für das Coaching als auch für die Inferenz verwendet werden. Diese Lösung befasst sich elegant auf die Korrektheit und Beobachtbarkeit der Punkte in der Zeit-Ihre Funktionen stehen immer zur Inspektion zur Verfügung und werden konsequent generiert. Es zeigt jedoch seine Einschränkungen im Umgang mit der Merkmalentwicklung. Wenn Ihr Modell -Ökosystem wächst, wird das Hinzufügen neuer Funktionen, das Ändern vorhandener oder die Verwaltung verschiedener Versionen immer komplexer – insbesondere aufgrund von Einschränkungen, die durch die Entwicklung des Datenbankschemas auferlegt werden.
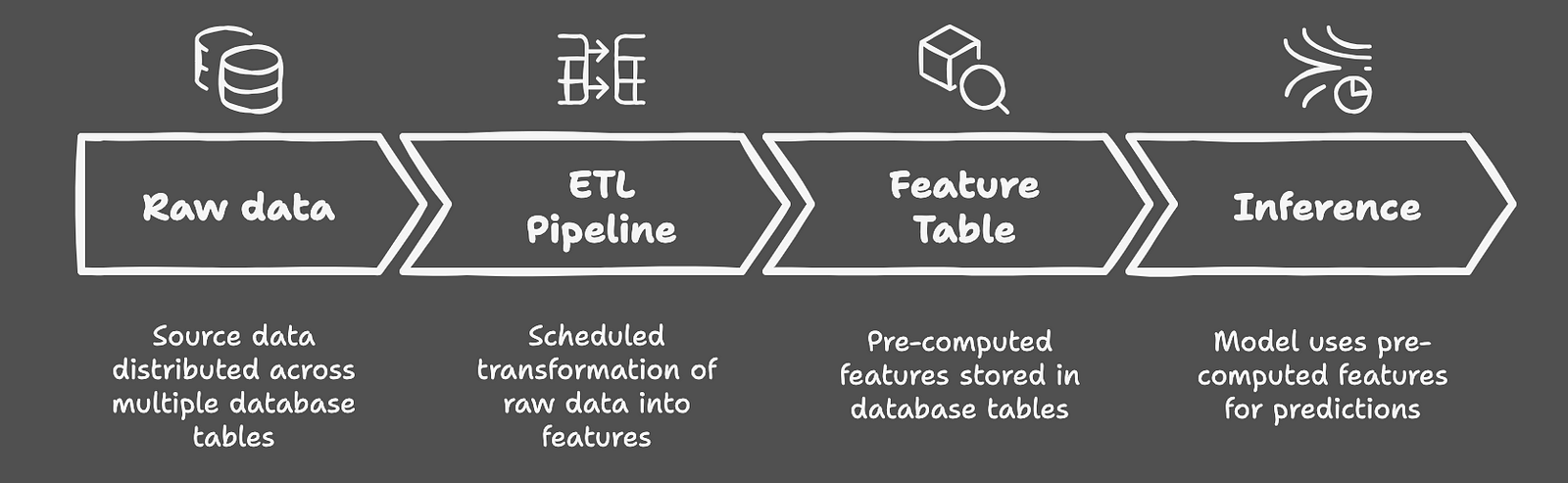
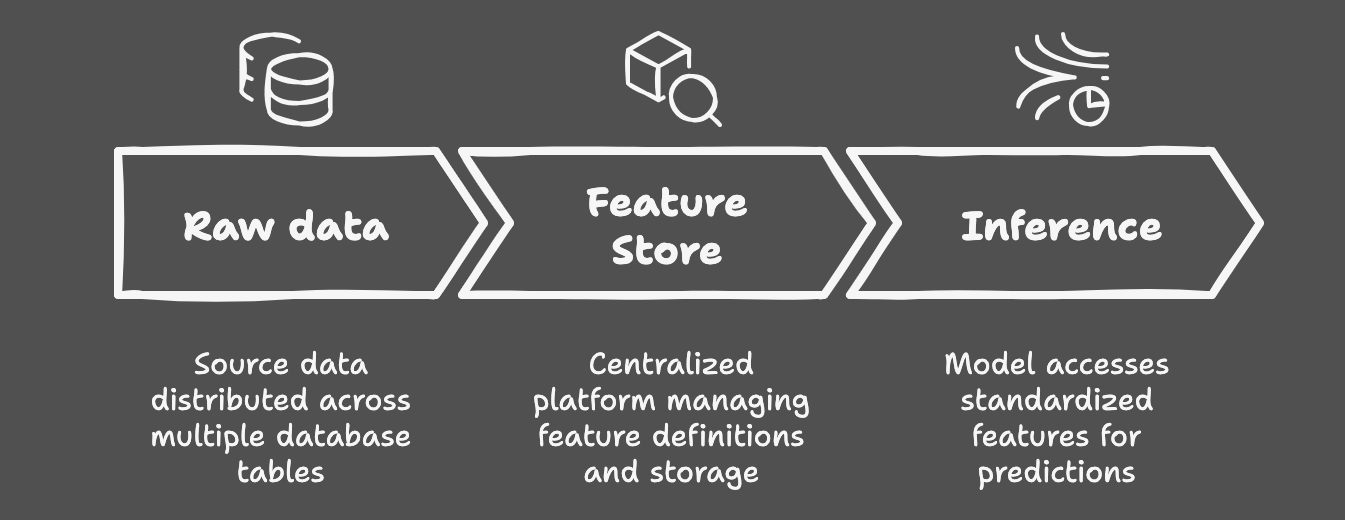
Ansatz 3: Function Retailer
Am anderen Ende des Spektrums liegt der Function Retailer – in der Regel Teil einer umfassenden ML -Plattform. Diese Lösungen bieten das vollständige Paket: Function -Versioning, effizientes On-line/Offline -Servieren und nahtlose Integration in breitere ML -Workflows. Sie sind das Äquivalent einer intestine geölten Maschine und lösen unsere Kernherausforderungen umfassend. Merkmale sind versionsgesteuert, leicht beobachtbar und von Natur aus wiederverwendbar. Diese Macht hat jedoch erhebliche Kosten: technologische Komplexität, Ressourcenanforderungen und die Notwendigkeit von engagiertem ML Engineering Sachverstand.
Die richtige Wahl treffen
Im Gegensatz zu dem, was Pattern ML -Weblog -Beiträge vorschlagen mögen, benötigt nicht jedes Crew einen Function -Retailer. Nach meiner Erfahrung bietet Function -Tischmaterialisierung häufig den Candy Spot – insbesondere wenn Ihre Organisation bereits eine robuste ETL -Infrastruktur hat. Der Schlüssel besteht darin, Ihre spezifischen Anforderungen zu verstehen: Wenn Sie mehrere Modelle verwalten, die die Funktionen teilen und häufig ändern, ist ein Function -Retailer möglicherweise die Investition wert. Für Groups mit begrenzter Modell gegen die gegenseitige Abhängigkeit oder für diejenigen, die ihre ML -Praktiken immer noch festlegen, bieten einfachere Lösungen häufig eine bessere Kapitalrendite. Sicher, du könnte Bleiben Sie bei der Generierung von On-Demand-Function-Wenn das Debuggen der Rennbedingungen um 2 Uhr morgens Ihre Vorstellung von einer guten Zeit ist.
Die Entscheidung ist letztendlich auf die Reife, die Verfügbarkeit der Ressourcen und die spezifischen Anwendungsfälle Ihres Groups zurückzuführen. Function -Shops sind leistungsstarke Instruments, aber wie jede ausgefeilte Lösung erfordern sie erhebliche Investitionen sowohl in Humankapital als auch in die Infrastruktur. Manchmal bietet der pragmatische Pfad der Merkmalstabellenmaterialisierung trotz seiner Einschränkungen das beste Gleichgewicht zwischen Fähigkeit und Komplexität.
Denken Sie daran: Erfolg im ML -Function -Administration geht es nicht darum, die anspruchsvollste Lösung zu wählen, sondern die richtige Passform für die Bedürfnisse und Fähigkeiten Ihres Groups zu finden. Der Schlüssel besteht darin, Ihre Bedürfnisse ehrlich zu bewerten, Ihre Einschränkungen zu verstehen und einen Pfad zu wählen, der es Ihrem Crew ermöglicht, zuverlässige, beobachtbare und wartbare ML -Systeme aufzubauen.