In diesem Artikel erfahren Sie, was rekursive Sprachmodelle sind, warum sie für die Argumentation mit langen Eingaben wichtig sind und wie sie sich von standardmäßigen Eingabeaufforderungs-, Abfrage- und Agentensystemen für lange Kontexte unterscheiden.
Zu den Themen, die wir behandeln werden, gehören:
- Warum ein langer Kontext allein die Argumentation über sehr große Eingaben nicht löst
- Wie rekursive Sprachmodelle eine externe Laufzeit und rekursive Unteraufrufe verwenden, um Informationen zu verarbeiten
- Die wichtigsten Kompromisse, Einschränkungen und praktischen Anwendungsfälle dieses Ansatzes
Kommen wir gleich zur Sache.
Alles, was Sie über rekursive Sprachmodelle wissen müssen
Bild vom Herausgeber
Einführung
Wenn Sie hier sind, haben Sie wahrscheinlich von neueren Arbeiten zu rekursiven Sprachmodellen gehört. Die Idee battle auf LinkedIn und Ich denke, wir sind uns alle einig, dass sich große Sprachmodelle (LLMs) in den letzten Jahren rasant verbessert haben, insbesondere hinsichtlich ihrer Fähigkeit, große Eingaben zu verarbeiten. Dieser Fortschritt hat viele Menschen zu der Annahme veranlasst, dass der lange Kontext ein weitgehend gelöstes Downside sei, aber das ist nicht der Fall. Wenn Sie versucht haben, Modellen sehr lange Eingaben nahe oder gleich ihrem Kontextfenster zu geben, ist Ihnen möglicherweise aufgefallen, dass sie weniger zuverlässig werden. Sie übersehen häufig Particulars in den bereitgestellten Informationen, widersprechen früheren Aussagen oder geben oberflächliche Antworten, anstatt sorgfältig zu argumentieren. Dieses Downside wird oft als bezeichnet „Kontextfäule“was ein recht interessanter Title ist.
Eine Antwort auf dieses Downside sind rekursive Sprachmodelle (RLMs). Anstatt immer mehr Textual content in einen einzigen Vorwärtsdurchlauf eines Sprachmodells zu schieben, ändern RLMs zunächst einmal die Artwork und Weise, wie das Modell mit langen Eingaben interagiert. In diesem Artikel werden wir uns damit befassen, was sie sind, wie sie funktionieren und welche Artwork von Problemen sie lösen sollen.
Warum ein langer Kontext nicht ausreicht
Sie können diesen Abschnitt überspringen, wenn Sie die Motivation aus der Einleitung bereits verstanden haben. Aber wenn Sie neugierig sind oder die Idee beim ersten Mal nicht ganz überzeugen konnte, lassen Sie mich sie weiter aufschlüsseln.
Die Funktionsweise dieser LLMs ist ziemlich einfach. Alles, was das Modell berücksichtigen soll, wird ihm als einzelne Eingabeaufforderung übermittelt, und basierend auf diesen Informationen generiert das Modell die Ausgabe Token für Token. Dies funktioniert intestine, wenn die Eingabeaufforderung kurz ist. Wenn es jedoch sehr lang wird, beginnt die Leistung nachzulassen. Dies ist nicht unbedingt auf Speicherbeschränkungen zurückzuführen. Selbst wenn das Modell die vollständige Eingabeaufforderung sehen kann, kann es diese häufig nicht effektiv nutzen. Hier sind einige Gründe, die zu diesem Verhalten beitragen können:
- Bei diesen LLMs handelt es sich hauptsächlich um transformatorbasierte Modelle mit einem Aufmerksamkeitsmechanismus. Je länger die Aufforderung wird, desto diffuser wird die Aufmerksamkeit. Dem Modell fällt es schwer, sich klar auf das Wesentliche zu konzentrieren, wenn es Zehntausende oder Hunderttausende von Token verwalten muss.
- Ein weiterer Grund ist das Vorhandensein heterogener Informationen wie Protokolle, Dokumente, Code, Chat-Verlauf und Zwischenausgaben.
- Schließlich geht es bei vielen Aufgaben nicht nur darum, einen relevanten Ausschnitt aus einer riesigen Menge an Inhalten abzurufen oder zu finden. Dabei werden häufig Informationen über die gesamte Eingabe hinweg aggregiert.
Aufgrund der oben diskutierten Probleme wurden Ideen wie Zusammenfassung und Abruf vorgeschlagen. Diese Ansätze helfen zwar in manchen Fällen, sind aber keine universellen Lösungen. Zusammenfassungen sind von Natur aus verlustbehaftet und der Abruf geht davon aus, dass die Relevanz zuverlässig identifiziert werden kann, bevor mit der Argumentation begonnen wird. Viele Aufgaben in der realen Welt verstoßen gegen diese Annahmen. Aus diesem Grund schlagen RLMs einen anderen Ansatz vor. Anstatt das Modell zu zwingen, die gesamte Eingabeaufforderung auf einmal zu absorbieren, lassen sie das Modell die Eingabeaufforderung aktiv erkunden und verarbeiten. Nachdem wir nun den grundlegenden Hintergrund kennen, schauen wir uns genauer an, wie das funktioniert.
Wie ein rekursives Sprachmodell in der Praxis funktioniert
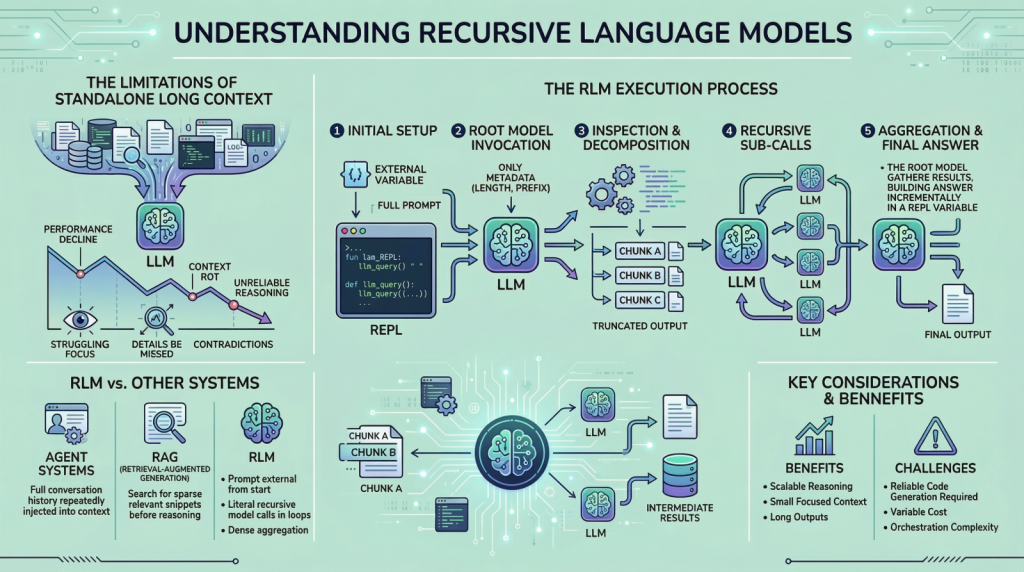
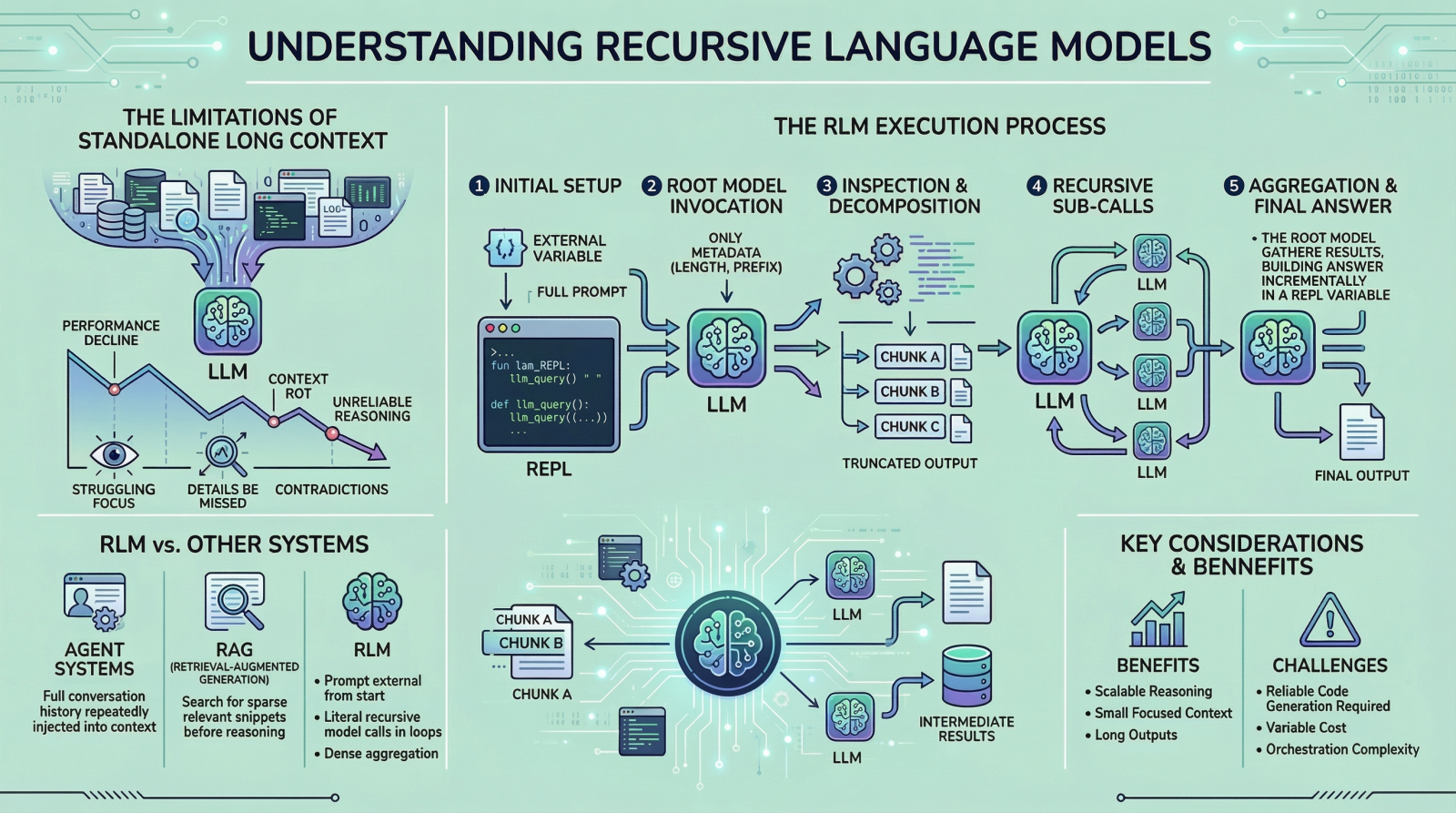
In einem RLM-Setup wird die Eingabeaufforderung als Teil der externen Umgebung behandelt. Dies bedeutet, dass das Modell nicht die gesamte Eingabe direkt liest. Stattdessen befindet sich die Eingabe außerhalb des Modells, oft als Variable, und das Modell erhält nur Metadaten über die Eingabeaufforderung sowie Anweisungen zum Zugriff darauf. Wenn das Modell Informationen benötigt, gibt es Befehle aus, um bestimmte Teile der Eingabeaufforderung zu untersuchen. Durch dieses einfache Design bleibt der interne Kontext des Modells klein und fokussiert, selbst wenn die zugrunde liegende Eingabe extrem groß ist. Um RLMs konkreter zu verstehen, gehen wir Schritt für Schritt eine typische Ausführung durch.
Schritt 1: Initialisieren einer persistenten REPL-Umgebung
Zu Beginn eines RLM-Laufs initialisiert das System eine Laufzeitumgebung, typischerweise eine Python REPL. Diese Umgebung enthält:
- Eine Variable, die die vollständige Benutzeraufforderung enthält und beliebig groß sein kann
- Eine Funktion (zum Beispiel
llm_query(...)odersub_RLM(...)), die es dem System ermöglicht, zusätzliche Sprachmodellaufrufe für ausgewählte Textteile aufzurufen
Aus der Sicht des Benutzers bleibt die Schnittstelle einfach, mit einer Texteingabe und einer Ausgabe, aber intern fungiert die REPL als Gerüst, das skalierbares Denken ermöglicht.
Schritt 2: Aufrufen des Root-Modells nur mit Immediate-Metadaten
Anschließend wird das Root-Sprachmodell aufgerufen, es erhält jedoch nicht die vollständige Eingabeaufforderung. Stattdessen heißt es:
- Metadaten mit konstanter Größe über die Eingabeaufforderung, z. B. ihre Länge oder ein kurzes Präfix
- Anweisungen, die die Aufgabe beschreiben
- Greifen Sie über die REPL-Umgebung auf Anweisungen zur Interaktion mit der Eingabeaufforderung zu
Durch das Zurückhalten der vollständigen Eingabeaufforderung zwingt das System das Modell dazu, absichtlich mit der Eingabe zu interagieren, anstatt sie passiv in das Kontextfenster aufzunehmen. Ab diesem Zeitpunkt interagiert das Modell indirekt mit der Eingabeaufforderung.
Schritt 3: Überprüfen und Zerlegen der Eingabeaufforderung durch Codeausführung
Das Modell könnte mit der Überprüfung der Struktur der Eingabe beginnen. Es kann beispielsweise die ersten paar Zeilen drucken, nach Überschriften suchen oder den Textual content anhand von Trennzeichen in Abschnitte aufteilen. Diese Vorgänge werden durch die Generierung von Code ausgeführt, der dann in der Umgebung ausgeführt wird. Die Ausgaben dieser Vorgänge werden gekürzt, bevor sie dem Modell angezeigt werden, um sicherzustellen, dass das Kontextfenster nicht überlastet wird.
Schritt 4: Rekursive Unteraufrufe für ausgewählte Slices ausgeben
Sobald das Modell die Struktur der Eingabeaufforderung versteht, kann es entscheiden, wie es vorgehen soll. Wenn die Aufgabe ein semantisches Verständnis bestimmter Abschnitte erfordert, kann das Modell Unterabfragen ausgeben. Jede Unterabfrage ist ein separater Sprachmodellaufruf für einen kleineren Teil der Eingabeaufforderung. Hier kommt eigentlich der „rekursive“ Teil ins Spiel. Das Modell zerlegt das Downside immer wieder, verarbeitet Teile der Eingabe und speichert Zwischenergebnisse. Diese Ergebnisse leben in der Umgebung, nicht im Kontext des Modells.
Schritt 5: Zusammenstellen und Zurücksenden der endgültigen Antwort
Nachdem genügend Informationen gesammelt und verarbeitet wurden, erstellt das Modell schließlich die endgültige Antwort. Wenn die Ausgabe lang ist:
- Das Modell baut es inkrementell innerhalb einer REPL-Variablen auf, z
Ultimate - Einmal
Ultimategesetzt ist, endet die RLM-Schleife - Der Wert von
Ultimatewird als Antwort zurückgegeben
Dieser Mechanismus ermöglicht es dem RLM, Ausgaben zu erzeugen, die die Token-Grenzwerte eines einzelnen Sprachmodellaufrufs überschreiten. Während dieses Prozesses muss kein einziger Sprachmodellaufruf jemals die vollständige Eingabeaufforderung sehen.
Was unterscheidet RLMs von Agenten und Abrufsystemen?
Wenn Sie Zeit im LLM-Bereich verbringen, verwechseln Sie diesen Ansatz möglicherweise mit Agenten-Frameworks oder Retrieval-Augmented Technology (RAG). Dies sind jedoch unterschiedliche Ideen, auch wenn die Unterschiede subtil erscheinen können.
In vielen Agentensystemen wird der gesamte Gesprächsverlauf oder Arbeitsspeicher wiederholt in den Kontext des Modells eingefügt. Wenn der Kontext zu groß wird, werden ältere Informationen zusammengefasst oder gelöscht. RLMs vermeiden dieses Muster vollständig, indem sie die Eingabeaufforderung von Anfang an extern halten. Im Gegensatz dazu verlassen sich Retrieval-Systeme darauf, eine kleine Menge relevanter Teile zu identifizieren, bevor mit der Argumentation begonnen wird. Dies funktioniert intestine, wenn die Relevanz gering ist. RLMs sind für Umgebungen konzipiert, in denen die Relevanz dicht und verteilt ist und eine Aggregation über viele Teile der Eingabe erforderlich ist. Ein weiterer wichtiger Unterschied ist die Rekursion. In RLMs ist Rekursion nicht metaphorisch. Das Modell ruft buchstäblich Sprachmodelle innerhalb von als Code generierten Schleifen auf, sodass die Arbeit auf kontrollierte Weise mit der Eingabegröße skaliert werden kann.
Kosten, Kompromisse und Einschränkungen
Es lohnt sich auch, einige Nachteile dieser Methode hervorzuheben. RLMs eliminieren keine Rechenkosten. Sie verschieben es. Anstatt für einen einzelnen, sehr großen Modellaufruf zu zahlen, zahlen Sie für viele kleinere, zusammen mit dem Mehraufwand für die Codeausführung und Orchestrierung. In vielen Fällen sind die Gesamtkosten vergleichbar mit einem Commonplace-Langkontextanruf, die Abweichung kann jedoch höher sein. Es gibt auch praktische Herausforderungen. Das Modell muss in der Lage sein, zuverlässigen Code zu schreiben. Schlecht eingeschränkte Modelle generieren möglicherweise zu viele Unteraufrufe oder werden nicht sauber beendet. Ausgabeprotokolle müssen sorgfältig entworfen werden, um Zwischenschritte von endgültigen Antworten zu unterscheiden. Dies sind technische Probleme, keine konzeptionellen Mängel, aber sie sind dennoch wichtig.
Fazit und Referenzen
Eine nützliche Faustregel lautet: Wenn Ihre Aufgabe allein deshalb schwieriger wird, weil die Eingabe länger ist, und wenn beim Zusammenfassen oder Abrufen wichtige Informationen verloren gehen, ist ein RLM wahrscheinlich eine Überlegung wert. Wenn die Eingabe kurz und die Aufgabe einfach ist, ist ein Aufruf eines Standardsprachenmodells normalerweise schneller und kostengünstiger. Wenn Sie sich eingehender mit rekursiven Sprachmodellen befassen möchten, sind die folgenden Ressourcen nützliche Ausgangspunkte: