Bei der Ausführung von LLMs im großen Maßstab liegt die eigentliche Einschränkung eher im GPU-Speicher als in der Rechenleistung, hauptsächlich weil für jede Anfrage ein KV-Cache zum Speichern von Daten auf Token-Ebene erforderlich ist. In herkömmlichen Setups wird professional Anfrage ein großer fester Speicherblock basierend auf der maximalen Sequenzlänge reserviert, was zu erheblich ungenutztem Speicherplatz führt und die Parallelität einschränkt. Paged Consideration verbessert dies, indem der KV-Cache in kleinere, versatile Blöcke aufgeteilt wird, die nur bei Bedarf zugewiesen werden, ähnlich wie der virtuelle Speicher funktioniert. Es ermöglicht auch mehreren Anfragen mit derselben Startaufforderung, den Speicher gemeinsam zu nutzen und ihn nur zu duplizieren, wenn ihre Ausgaben beginnen, sich zu unterscheiden. Dieser Ansatz verbessert die Speichereffizienz erheblich und ermöglicht einen deutlich höheren Durchsatz bei sehr geringem Overhead.
In diesem Artikel simulieren wir den naiven KV-Cache-Allokator, erstellen eine funktionierende Paged Consideration-Implementierung mit einer Blocktabelle und Copy-on-Write-Präfixfreigabe und messen die Auslastungslücke über Stapelgrößen von 10 bis 200 gleichzeitigen Anforderungen.

import math
import random
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from collections import defaultdict
random.seed(42)
np.random.seed(42)Bevor wir etwas simulieren, müssen wir wissen, wie viel GPU-Speicher ein einzelner Token tatsächlich kostet. Dies hängt vollständig von der Architektur des Modells ab. Wir verwenden eine Konfiguration im GPT-Stil – 32 Ebenen, 32 Aufmerksamkeitsköpfe, 128 Dimensionen professional Kopf, gespeichert in fp16. Der Faktor 2 vorne berücksichtigt sowohl die Schlüssel- als auch die Wertprojektion (es gibt keinen Q-Cache – Abfragen werden bei jedem Schritt neu berechnet). Wenn wir diese multiplizieren, erhalten wir 524.288 Bytes oder 512 KB professional Token. Dies ist die grundlegende Einheit, auf der alles andere aufbaut – Vorbelegungsgrößen, Seitenanzahlen und verschwendeter Speicher skalieren alle direkt von dieser Zahl.
NUM_LAYERS = 32
NUM_HEADS = 32
HEAD_DIM = 128
BYTES_FP16 = 2
PAGE_SIZE = 16 # tokens per web page (vLLM default)
MAX_SEQ_LEN = 2048
KV_BYTES_PER_TOKEN = 2 * NUM_LAYERS * NUM_HEADS * HEAD_DIM * BYTES_FP16
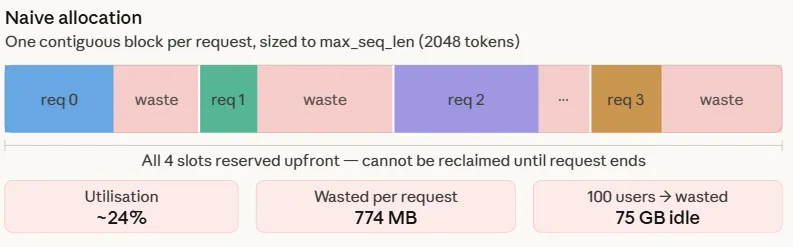
KV_MB_PER_TOKEN = KV_BYTES_PER_TOKEN / 1024 / 1024Der naive Ansatz ist einfach: Wenn eine Anfrage eintrifft, wird ein zusammenhängender Block GPU-Speicher mit der Größe der maximalen Sequenzlänge zugewiesen – in diesem Fall 2048 Token. Dies liegt daran, dass die Antwortlänge im Voraus unbekannt ist und daher der schlimmste Fall vorbehalten bleibt.
AVG_RESPONSE ist auf 500 eingestellt, was ein realistischer Durchschnitt für einen Produktions-Chatbot ist. Die Multiplikation mit KV_MB_PER_TOKEN ergibt, was tatsächlich geschrieben wurde und was gesperrt battle. Die Lücke ist die Verschwendung.
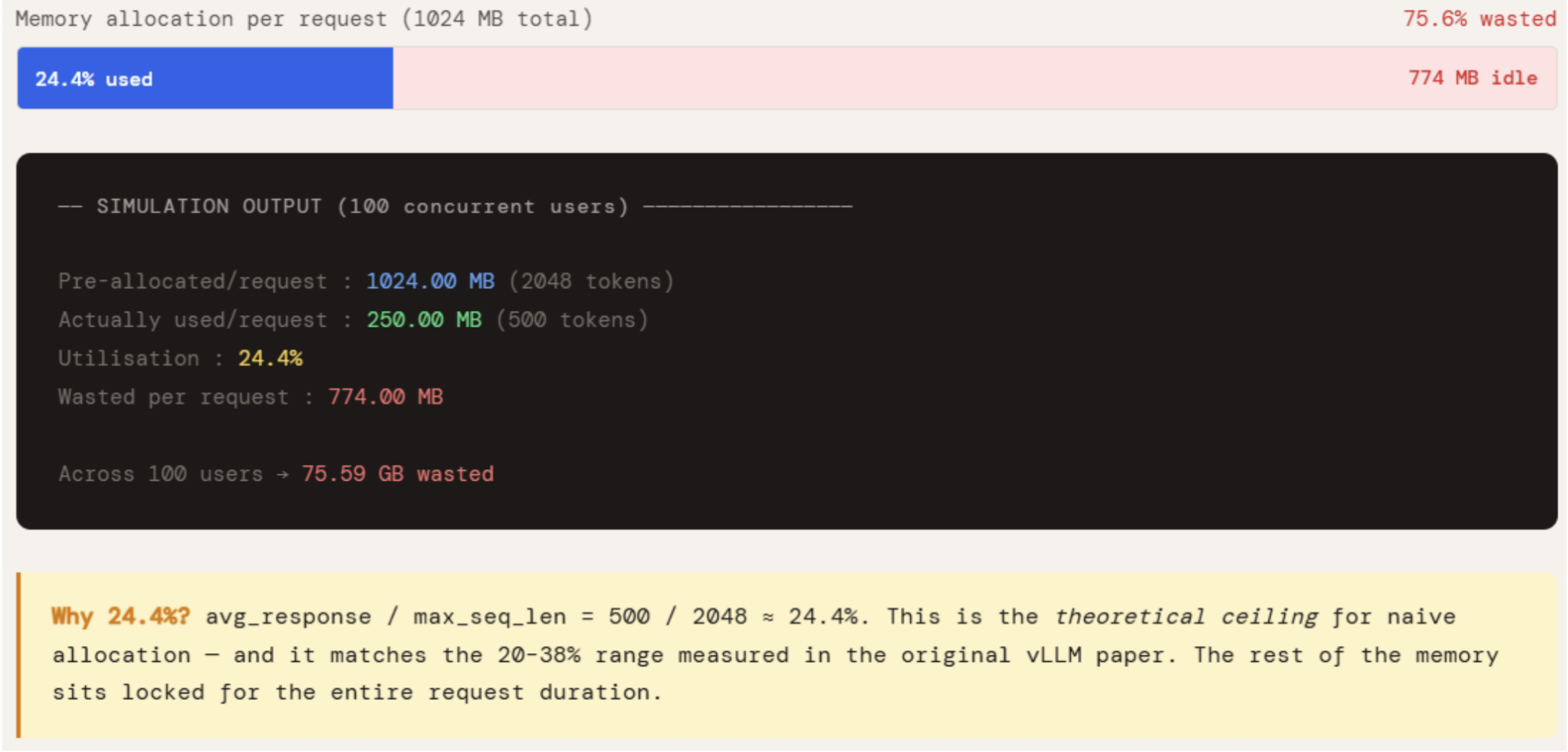
Die Zahlen machen das Downside konkret. Jede Anfrage weist 1024 MB vorab zu, nutzt aber nur 250 MB – 24,4 % Auslastung. Die restlichen 774 MB bleiben für die gesamte Dauer der Anfrage reserviert und stehen keiner anderen Anfrage zur Verfügung. Bei 100 gleichzeitigen Benutzern bedeutet das, dass 75 GB GPU-Speicher nichts bewirken. Dies ist kein Randfall – es ist das Standardverhalten jedes Programs, das keine Seitenzuweisung implementiert, und genau das ist der Grund, warum naive Bereitstellungssysteme lange bevor die GPU rechentechnisch ausgelastet ist, an eine OOM-Wand stoßen.
print("=" * 60)
print("SECTION 1 -- Naive KV Cache: The Waste Downside")
print("=" * 60)
AVG_RESPONSE = 500 # reasonable common tokens generated
pre_allocated_mb = MAX_SEQ_LEN * KV_MB_PER_TOKEN
actually_used_mb = AVG_RESPONSE * KV_MB_PER_TOKEN
print(f"nKV cache per token : {KV_BYTES_PER_TOKEN:,} bytes")
print(f"Pre-allocated/request : {pre_allocated_mb:.2f} MB ({MAX_SEQ_LEN} tokens)")
print(f"Really used/request : {actually_used_mb:.2f} MB ({AVG_RESPONSE} tokens)")
print(f"Utilisation : {actually_used_mb / pre_allocated_mb * 100:.1f}%")
print(f"Wasted per request : {pre_allocated_mb - actually_used_mb:.2f} MB")
NUM_USERS = 100
wasted_gb = (pre_allocated_mb - actually_used_mb) * NUM_USERS / 1024
print(f"nAcross {NUM_USERS} concurrent customers → {wasted_gb:.2f} GB wasted")
print("n→ Naive programs utilise solely 20-38% of allotted KV cache reminiscence")
print(" (supply: unique Paged Consideration / vLLM paper)")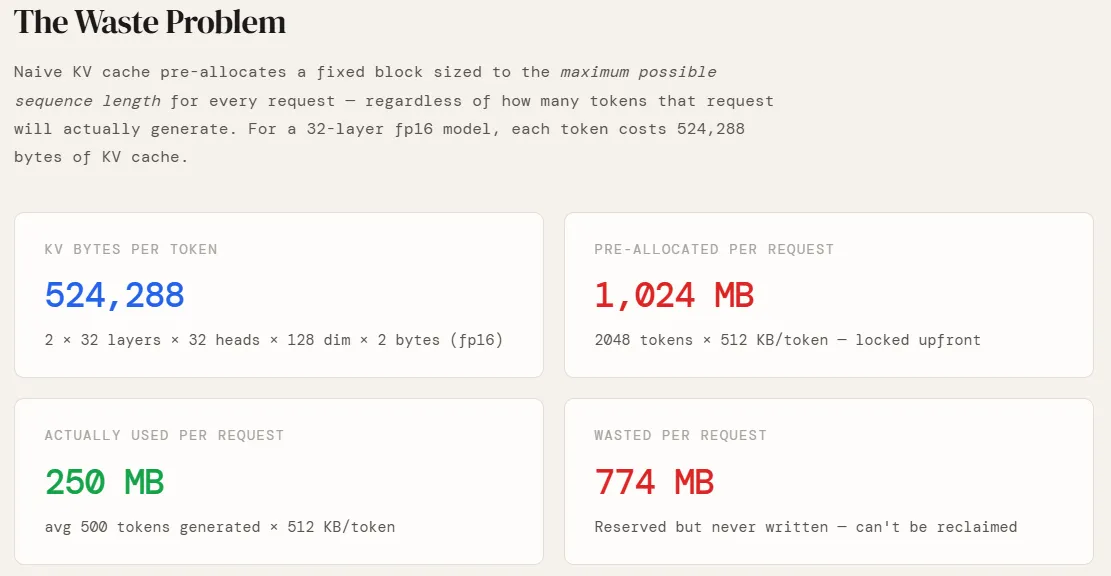
Hier werden zwei Klassen vorgestellt, um zu simulieren, wie Paged Consideration tatsächlich auf der Speicherverwaltungsebene funktioniert.
PagePool stellt den physischen GPU-Speicherpool dar – ein flaches Array gleich großer Seiten, die jeweils 16 Token enthalten. Es verwaltet eine kostenlose Liste und eine Referenzanzahl professional Seite. Wenn die Ref-Anzahl einer Seite auf Null sinkt, wird sie sofort wieder in die Liste der freien Seiten aufgenommen und steht für jede neue Anfrage zur Verfügung. Dies ist der Hauptunterschied zur naiven Zuweisung – es gibt keine reservierten Lücken, keine Fragmentierung und keinen an eine abgeschlossene Anfrage gebundenen Speicher.
PagedRequest stellt eine einzelne Inferenzanforderung dar. Es enthält eine block_table – eine Liste, die logische Seitenindizes physischen Seiten-IDs im Pool zuordnet. Jedes Mal, wenn „generate_token()“ aufgerufen wird und der Token-Zähler eine Seitengrenze überschreitet, wird eine neue physische Seite aus dem Pool beansprucht. Keine Erinnerung wird berührt, bevor sie benötigt wird.
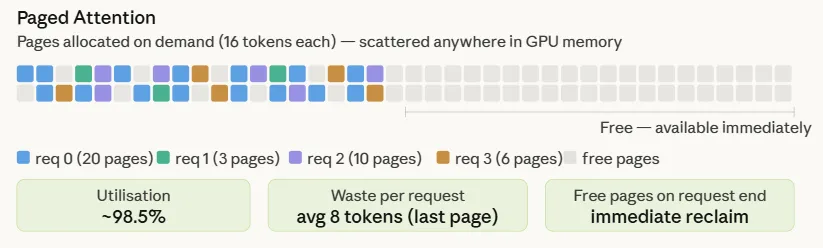
Es werden fünf Anfragen mit einer Tokenanzahl von 320, 48, 160, 96 und 272 ausgeführt. Die Ausgabe zeigt die Seiten an, die proportional zur tatsächlichen Nutzung zugewiesen sind – req-1 mit 48 Token erhält 3 Seiten, req-0 mit 320 Token erhält 20. Wenn req-1 freigegeben wird, gehen seine 3 Seiten direkt zurück in den Pool und sind sofort wiederverwendbar. Die Poolauslastung von 10,9 % scheint nur deshalb niedrig zu sein, weil 512 Seiten für 5 kleine Anfragen bereitgestellt wurden – in einem voll ausgelasteten Produktionspool würde sie in der Nähe des in Abschnitt 4 gezeigten Bereichs von 98 % liegen. Die „0 verschwendeten Token“ in der Spalte „Letzte Seite“ sind ein Startartefakt – alle fünf Token-Zählungen sind zufällig exakte Vielfache von 16. In der Praxis beträgt die durchschnittliche Verschwendung der letzten Seite PAGE_SIZE / 2 = 8 Token professional Anfrage.

print("n" + "=" * 60)
print("SECTION 2 -- Paged Consideration: Pages + Block Desk")
print("=" * 60)
"""
As a substitute of 1 giant contiguous block per request:
- KV cache is cut up into fixed-size pages (PAGE_SIZE tokens every)
- Pages are allotted on demand, can dwell wherever in GPU reminiscence
- Every request retains a block_table: logical index → bodily web page id
"""
class PagePool:
def __init__(self, total_pages):
self.free = listing(vary(total_pages))
self.complete = total_pages
self.ref_count = defaultdict(int)
def allocate(self):
if not self.free:
elevate MemoryError("OOM -- no free pages")
pid = self.free.pop(0)
self.ref_count(pid) = 1
return pid
def launch(self, pid):
self.ref_count(pid) -= 1
if self.ref_count(pid) <= 0:
self.free.append(pid)
del self.ref_count(pid)
def share(self, pid):
"""Increment ref rely -- one other request is sharing this web page."""
self.ref_count(pid) += 1
def cow_copy(self, pid):
"""CoW: allocate a brand new web page, decrement ref on the previous one."""
new_pid = self.allocate()
self.launch(pid)
return new_pid
@property
def utilisation(self):
return (self.complete - len(self.free)) / self.complete * 100
class PagedRequest:
def __init__(self, req_id, pool: PagePool):
self.id = req_id
self.pool = pool
self.block_table = () # logical index → bodily web page id
self.tokens = 0
def generate_token(self):
if self.tokens % PAGE_SIZE == 0: # web page boundary → allocate new web page
self.block_table.append(self.pool.allocate())
self.tokens += 1
def free(self):
for pid in self.block_table:
self.pool.launch(pid)
self.block_table.clear()
pool = PagePool(total_pages=512)
requests = (PagedRequest(f"req-{i}", pool) for i in vary(5))
token_counts = (320, 48, 160, 96, 272)
for req, n in zip(requests, token_counts):
for _ in vary(n):
req.generate_token()
print("nRequest state after technology:")
print(f" {'ID':<10} {'Tokens':>8} {'Pages':>7} {'Final-page waste':>16}")
for req in requests:
waste = req.tokens % PAGE_SIZE
waste = PAGE_SIZE - waste if waste else 0
print(f" {req.id:<10} {req.tokens:>8} {len(req.block_table):>7} {waste:>16} tokens")
print(f"nPool utilisation : {pool.utilisation:.1f}%")
requests(1).free()
print(f"After releasing req-1 → utilisation: {pool.utilisation:.1f}% (pages instantly reusable)")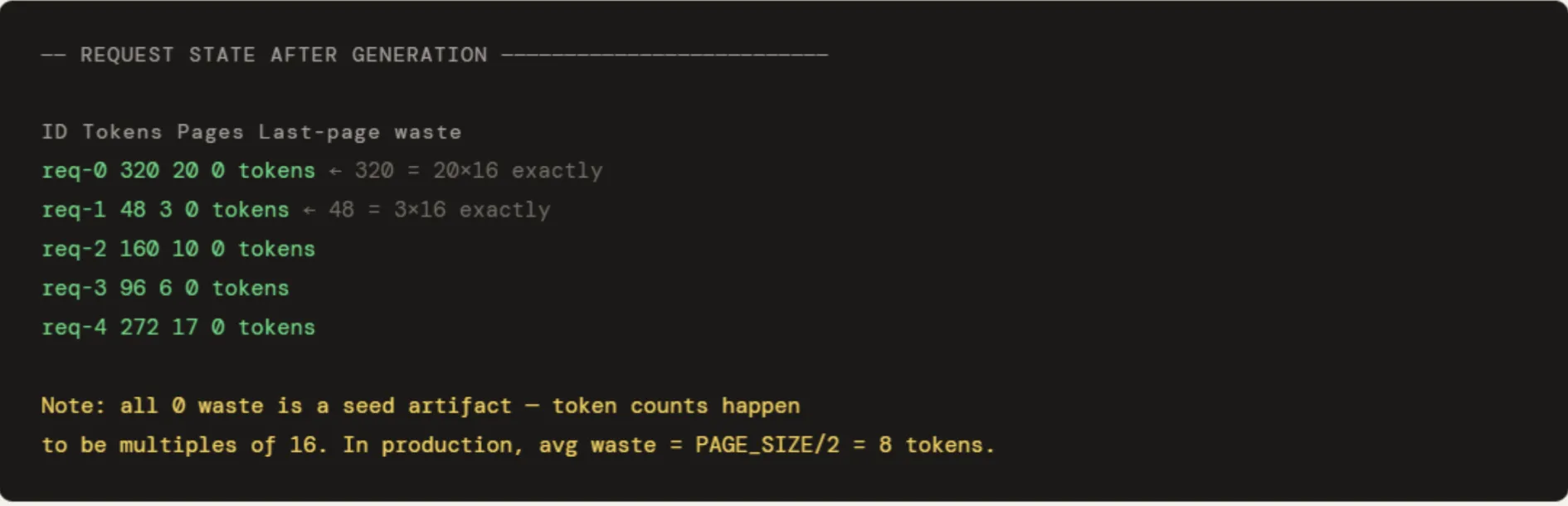
In der Produktion enthält nahezu jede Anfrage an ein bereitgestelltes LLM dieselbe Systemaufforderung – die Anweisungen, die das Verhalten des Modells definieren. Bei der naiven Zuordnung speichert jede dieser Anforderungen eine eigene vollständige Kopie des KV-Cache der Systemeingabeaufforderung. Bei 10 gleichzeitigen Anforderungen und einer Systemaufforderung mit 200 Token bedeutet dies, dass 10 identische Kopien derselben Daten separate Speicherbereiche belegen.
Hier wird derselbe PagePool aus Abschnitt 2 wiederverwendet, erweitert um zwei Methoden: share() erhöht die Ref-Anzahl einer Seite, ohne etwas Neues zuzuweisen, und cow_copy() weist eine neue Seite zu und verringert die Ref-Anzahl des Originals. Ein neuer Pool wird instanziiert und die Systemeingabeaufforderung wird in 13 Seiten codiert – math.ceil(200/16). Jede der 10 Benutzeranfragen ruft dann share() auf allen 13 Seiten auf und verweist ihre Blocktabellen auf denselben physischen Speicher. Es werden keine neuen Seiten zugewiesen. Die Ref-Anzahl auf jeder geteilten Seite steigt einfach auf 11.
Die Einsparungen sind sofort spürbar: Eine naive Zuordnung würde 130 Seiten für 10 Anfragen erfordern. Bei CoW existieren nur 13 physische Seiten. Das sind 936 MB, die durch ein einzelnes gemeinsames Präfix eingespart werden.
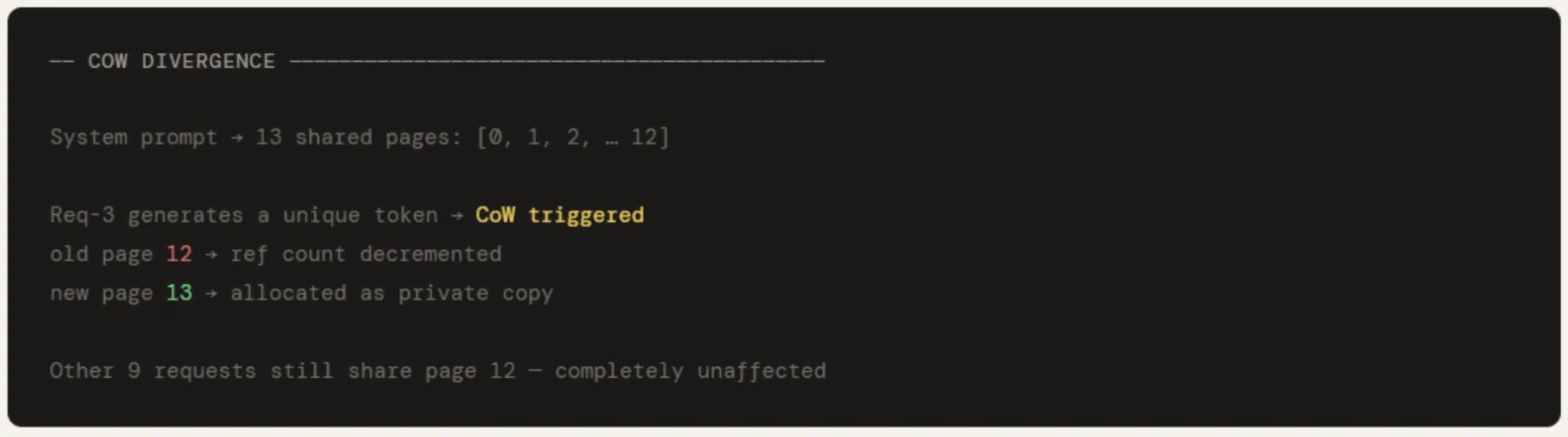
Wenn req-3 sein erstes eindeutiges Token generiert, wird cow_copy() auf seiner letzten freigegebenen Seite aufgerufen – Seite 12. Eine neue Seite 13 wird als personal Kopie von req-3 zugewiesen und die Referenzanzahl auf Seite 12 sinkt um eins. Die anderen 9 Anfragen verweisen weiterhin völlig unbeeinflusst auf Seite 12. Dies ist der CoW-Vertrag: geteilt bis zur Divergenz, privat nur bei Bedarf.

print("n" + "=" * 60)
print("SECTION 3 -- Copy-on-Write: Shared System Prompts")
print("=" * 60)
"""
If N requests share a system immediate, naive allocation shops N copies.
With CoW, all requests level to the SAME bodily pages.
A personal copy is made solely when a request writes a diverging token.
"""
cow_pool = PagePool(total_pages=512)
SYSTEM_TOKENS = 200
system_pages = math.ceil(SYSTEM_TOKENS / PAGE_SIZE)
shared_pids = (cow_pool.allocate() for _ in vary(system_pages))
print(f"nSystem immediate → {system_pages} shared pages: {shared_pids}")
N = 10
user_tables = ()
for i in vary(N):
desk = listing(shared_pids)
for pid in shared_pids:
cow_pool.share(pid) # ref rely up -- no bodily copy
user_tables.append(desk)
saved_mb = (system_pages * N - system_pages) * PAGE_SIZE * KV_MB_PER_TOKEN
print(f"nStoring system immediate for {N} requests:")
print(f" Naive : {system_pages * N} pages ({system_pages * N * PAGE_SIZE * KV_MB_PER_TOKEN:.1f} MB)")
print(f" CoW : {system_pages} pages ({system_pages * PAGE_SIZE * KV_MB_PER_TOKEN:.1f} MB)")
print(f" Saved : {saved_mb:.1f} MB")
old_pid = user_tables(3)(-1)
new_pid = cow_pool.cow_copy(old_pid)
user_tables(3)(-1) = new_pid
print(f"nReq-3 diverges → CoW: previous web page {old_pid} → new web page {new_pid}")
print(f"All different {N-1} requests nonetheless share web page {old_pid} unaffected")
Es werden zwei Funktionen definiert, um die Auslastung bei jedem Ansatz über verschiedene Chargengrößen hinweg zu messen.
naive_utilisation bezieht die Token-Anzahl aus einer Normalverteilung mit avg=500 und std=200, begrenzt auf (200, 2048). Dies spiegelt eine realistische Produktionsverteilung wider – die meisten Antworten liegen zwischen 200 und 800 Token, gelegentlich gibt es auch längere. Für jede Anfrage wird unabhängig davon der gesamte 2048-Slot-Block vorab zugewiesen. Die Auslastung beträgt dann „actual_tokens_sum / (2048 × n)“ – das Verhältnis zwischen dem, was geschrieben wurde, und dem, was reserviert wurde.
paged_utilisation verwendet die gleichen tatsächlichen Token-Zählungen, berechnet aber, wie viele Seiten jede Anfrage benötigen würde – ceil(tokens / 16). Der einzige Abfall ist der nicht ausgefüllte Schwanz der letzten Seite jeder Anfrage, der durchschnittlich 8 Token ausmacht. Die Auslastung beträgt „actual_tokens_sum“ / (pages_allocated × 16).
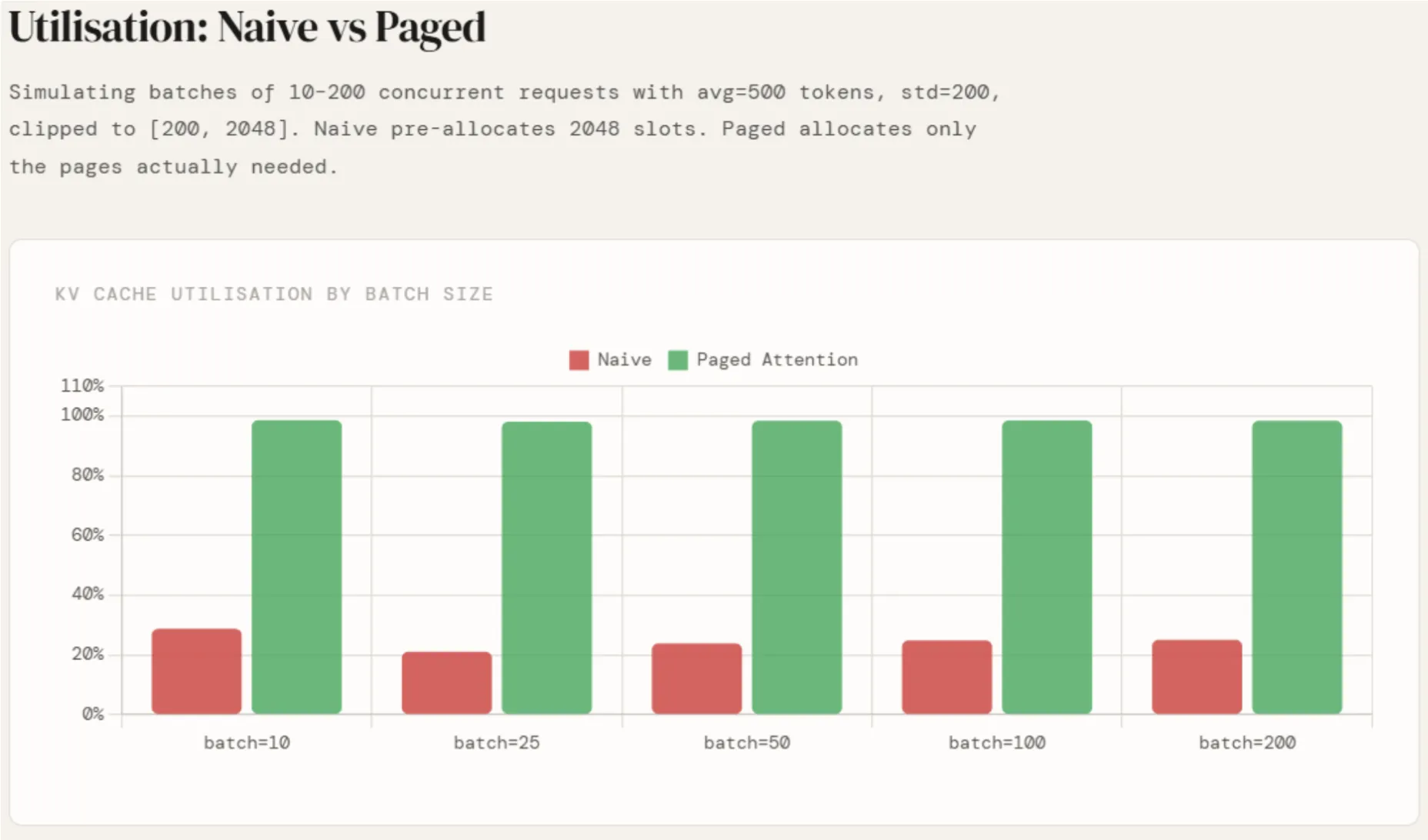
Die Ergebnisse werden auf Chargengrößen von 10, 25, 50, 100 und 200 angewendet. Die naive Auslastung liegt bei etwa 24 % über alle Chargengrößen hinweg – mit einer gewissen Abweichung bei kleineren Chargen aufgrund von Stichprobenrauschen –, was genau avg / max_seq = 500 / 2048 entspricht. Es verbessert sich nicht mit der Skalierung, da der Abfall strukturell und nicht statistisch ist.
Die Seitenauslastung liegt unabhängig von der Stapelgröße konstant bei etwa 98,5 %, da der Abfall professional Anfrage durch eine einzelne Teilseite begrenzt ist und überhaupt nicht mit max_seq_len skaliert. Die Lücke zwischen den beiden Zahlen – etwa 74 Prozentpunkte – ist direkt dafür verantwortlich, dass vLLM zwei- bis viermal mehr gleichzeitige Anforderungen in denselben GPU-Speicher unterbringen kann.
print("n" + "=" * 60)
print("SECTION 4 -- Utilisation: Naive vs Paged")
print("=" * 60)
def naive_utilisation(n, max_seq=2048, avg=500, std=200):
precise = np.clip(np.random.regular(avg, std, n).astype(int), 200, max_seq)
return precise.sum() / (max_seq * n) * 100, precise
def paged_utilisation(actual_tokens, page_size=PAGE_SIZE):
pages = np.ceil(actual_tokens / page_size).astype(int)
return actual_tokens.sum() / (pages * page_size).sum() * 100
batch_sizes = (10, 25, 50, 100, 200)
naive_u, paged_u = (), ()
print(f"n {'Batch':>6} {'Naive':>8} {'Paged':>8}")
for bs in batch_sizes:
nu, precise = naive_utilisation(bs)
pu = paged_utilisation(precise)
naive_u.append(nu)
paged_u.append(pu)
print(f" {bs:>6} {nu:>7.1f}% {pu:>7.1f}%")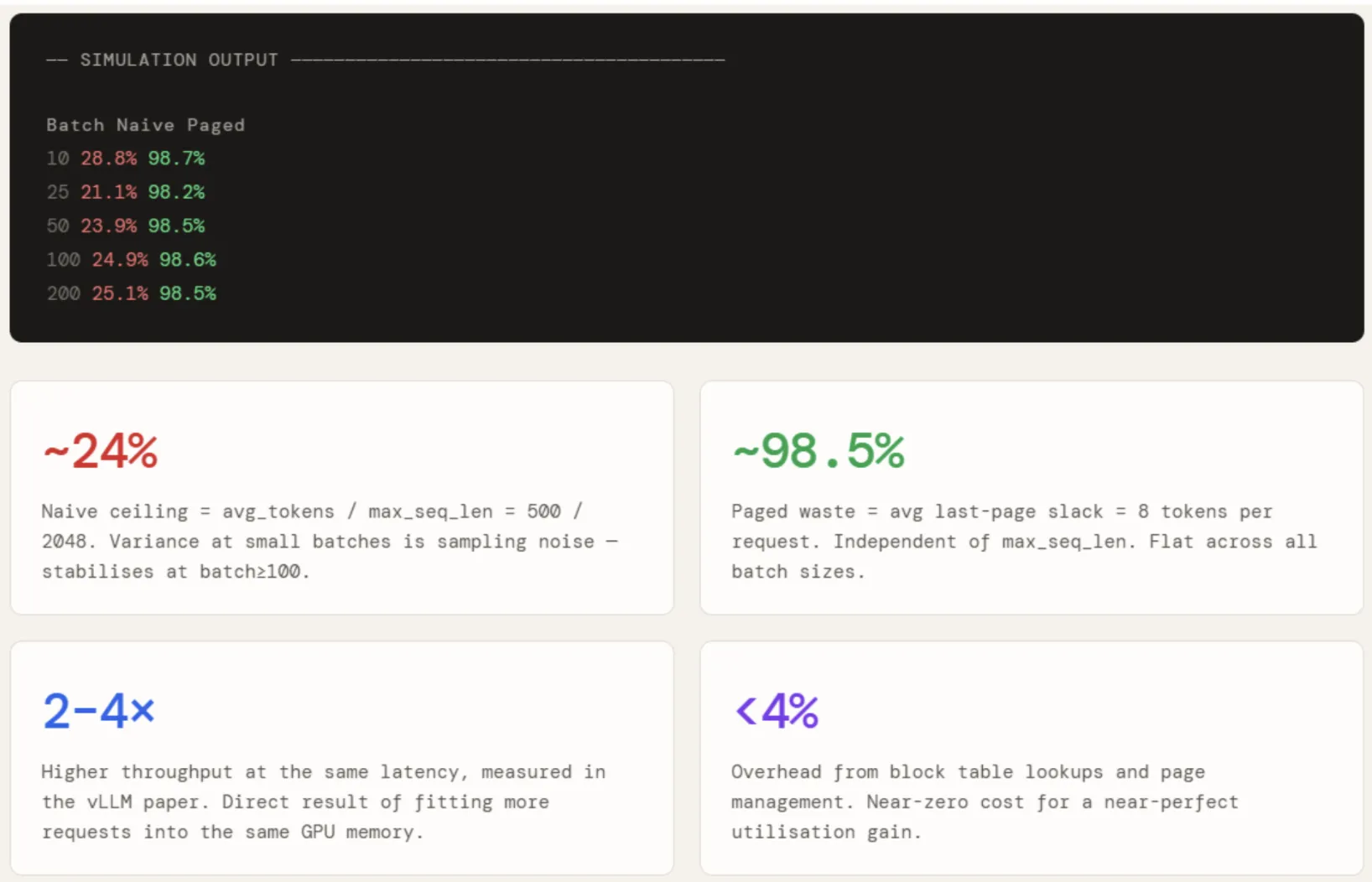
Schauen Sie sich das an Vollständiges Notizbuch hier. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 120.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.

Ich habe einen Abschluss im Bauingenieurwesen (2022) von Jamia Millia Islamia, Neu-Delhi, und interessiere mich sehr für Datenwissenschaft, insbesondere für neuronale Netze und deren Anwendung in verschiedenen Bereichen.