
Wir haben 100 Verstärkungslernen (RL) kontrollierte Autos in den Straßenverkehr mit Rush-Stunde eingesetzt, um die Überlastung zu reibungslos und den Kraftstoffverbrauch für alle zu verringern. Unser Ziel ist es, sich anzugehen „Cease-and-Go“ -Wellendiese frustrierenden Verlangsamungen und Beschleunigungen, die normalerweise keine eindeutige Ursache haben, sondern zu Staus und erheblichen Energieabfällen führen. Um effiziente Stromverlag-Controller auszubilden, haben wir schnelle, datengesteuerte Simulationen erstellt, mit denen RL-Agenten interagieren und lernen, die Energieeffizienz zu maximieren und gleichzeitig den Durchsatz beizubehalten und sicher um menschliche Fahrer zu arbeiten.
Insgesamt reicht ein kleiner Teil der intestine kontrollierten autonomen Fahrzeuge (AVS) aus, um den Verkehrsfluss und die Kraftstoffeffizienz für alle Fahrer auf der Straße erheblich zu verbessern. Darüber hinaus sind die geschulten Controller so konzipiert, dass sie in den meisten modernen Fahrzeugen eingesetzt werden können, dezentralisiert werden und sich auf Customary -Radarsensoren verlassen. In unserem Neueste ArbeitWir untersuchen die Herausforderungen beim Einsetzen von RL-Controllern auf einem großen Maßstab von Simulation bis zum Feld während dieses 100-Autos-Experiments.
Die Herausforderungen von Phantom -Staus

Eine Cease-and-Go-Welle, die sich durch den Autobahnverkehr nach hinten bewegt.
Wenn Sie fahren, haben Sie sicherlich die Frustration von Cease-and-Go-Wellen erlebt, diese scheinbar unerklärlichen Verkehrsabfällen, die aus dem Nichts erscheinen und dann plötzlich aufklären. Diese Wellen werden häufig durch kleine Schwankungen unseres Fahrverhaltens verursacht, die durch den Verkehrsfluss verstärkt werden. Wir stellen unsere Geschwindigkeit natürlich anhand des Fahrzeugs vor uns an. Wenn sich die Lücke öffnet, beschleunigen wir, um mitzuhalten. Wenn sie bremsen, werden wir auch langsamer. Aber aufgrund unserer Reaktionszeit ungleich Null könnten wir nur ein bisschen härter bremsen als das Fahrzeug vorne. Der nächste Fahrer hinter uns macht dasselbe, und dies verstärkt sich weiter. Im Laufe der Zeit verwandelt sich das, was als unbedeutende Verlangsamung begann, zu einem weiteren Stillstand weiter im Verkehr. Diese Wellen bewegen sich durch den Verkehrsstrom rückwärts, was zu erheblichen Tropfen der Energieeffizienz aufgrund häufiger Beschleunigungen führt, begleitet von erhöhtem CO2 Emissionen und Unfallrisiko.
Und das ist kein isoliertes Phänomen! Diese Wellen sind auf belebten Straßen allgegenwärtig, wenn die Verkehrsdichte einen kritischen Schwellenwert überschreitet. Wie können wir dieses Downside angehen? Traditionelle Ansätze wie Rampenmessung und variable Geschwindigkeitsgrenzen versuchen, den Verkehrsfluss zu verwalten, benötigen jedoch häufig eine kostspielige Infrastruktur und eine zentrale Koordination. Ein skalierbarerer Ansatz ist die Verwendung von AVs, wodurch ihr Fahrverhalten in Echtzeit dynamisch anpassen kann. Es ist jedoch nicht ausreichend, AVs in menschliche Fahrer einzuführen: Sie müssen auch auf intelligentere Weise fahren, was den Verkehr für alle besser macht, wo RL ins Spiel kommt.
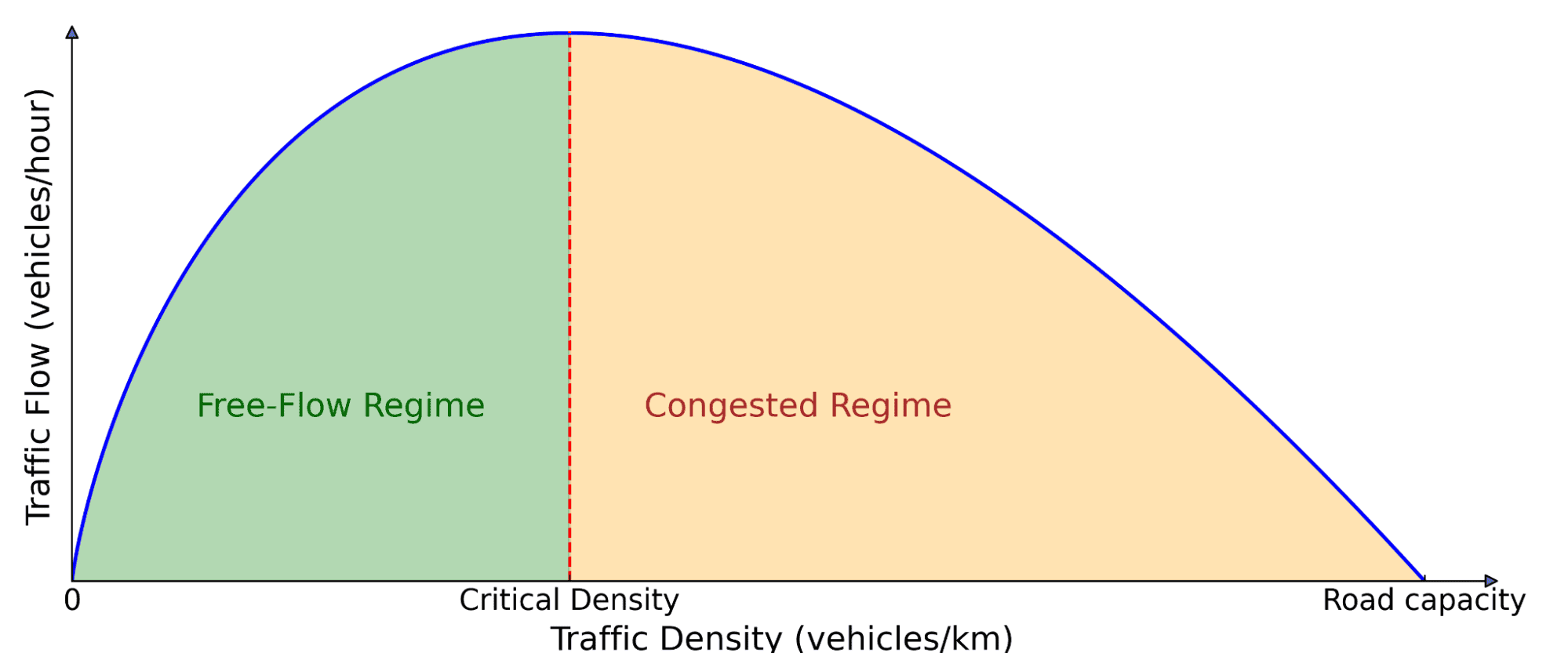
Grundlegendes Diagramm des Verkehrsflusss. Die Anzahl der Autos auf der Straße (Dichte) wirkt sich aus, wie viel Verkehr voranschreitet (Fluss). Bei niedriger Dichte erhöht das Hinzufügen von mehr Autos den Fluss, da mehr Fahrzeuge durchlaufen können. Über eine kritische Schwelle hinaus blockieren die Autos sich gegenseitig, was zu einer Überlastung führt, bei der das Hinzufügen von mehr Autos tatsächlich die Gesamtbewegung verlangsamt.
Verstärkungslernen für Wellengläser-AVs
RL ist ein leistungsstarker Kontrollansatz, bei dem ein Agent lernt, ein Belohnungssignal durch Interaktionen mit einer Umgebung zu maximieren. Der Agent sammelt Erfahrung durch Versuch und Irrtum, lernt aus seinen Fehlern und verbessert sich im Laufe der Zeit. In unserem Fall ist die Umwelt ein Mischautonomie-Verkehrsszenario, in dem AVs Fahrstrategien zur Dämpfung von Cease-and-Go-Wellen und die Verringerung des Kraftstoffverbrauchs sowohl für sich selbst als auch für die in der Nähe von Menschen betriebenen Fahrzeugen lernen.
Das Coaching dieser RL-Agenten erfordert schnelle Simulationen mit realistischer Verkehrsdynamik, die Autobahn-Cease-and-Go-Verhalten wiederholen können. Um dies zu erreichen, nutzten wir experimentelle Daten, die auf der Interstate 24 (I-24) in der Nähe von Nashville, Tennessee, gesammelt wurden, und bauten damit Simulationen, bei denen Fahrzeuge die Autobahn-Trajektorien wiederholen und einen instabilen Verkehr erzeugen, der hinter ihnen fährt, lernen, sich zu glätten.
Simulation Nachspiel einer Autobahnbahn, die mehrere Cease-and-Go-Wellen aufweist.
Wir haben die AVs berücksichtigt, um sicherzustellen, dass sie nur grundlegende Sensorinformationen über sich selbst und das Fahrzeug vor dem Fahrzeug betreiben können. Die Beobachtungen bestehen aus der Geschwindigkeit des AV, der Geschwindigkeit des führenden Fahrzeugs und der Weltraumlücke zwischen ihnen. Angesichts dieser Eingänge schreibt der RL -Agent dann entweder eine sofortige Beschleunigung oder eine gewünschte Geschwindigkeit für den AV vor. Der Hauptvorteil der Verwendung nur dieser lokalen Messungen besteht darin, dass die RL -Controller auf dezentrale Weise in den meisten modernen Fahrzeugen eingesetzt werden können, ohne zusätzliche Infrastruktur zu erfordern.
Belohnungsdesign
Der schwierigste Teil ist die Gestaltung einer Belohnungsfunktion, die, wenn sie maximiert wird, mit den verschiedenen Zielen übereinstimmt, die wir die AVs erreichen möchten:
- Wellenglättung: Reduzieren Sie Cease-and-Go-Oszillationen.
- Energieeffizienz: Niedrigerer Kraftstoffverbrauch für alle Fahrzeuge, nicht nur AVs.
- Sicherheit: Gewährleisten Sie eine angemessene folgende Entfernungen und vermeiden Sie abruptes Bremsen.
- Fahrkomfort: Vermeiden Sie aggressive Beschleunigungen und Verzögerungen.
- Einhaltung menschlicher Fahrnormen: Stellen Sie sicher, dass ein „normales“ Fahrverhalten, das die umliegenden Fahrer nicht unangenehm macht.
Es ist schwierig, diese Ziele zusammenzubilden, da geeignete Koeffizienten für jeden Begriff gefunden werden müssen. Wenn beispielsweise der Minimieren des Kraftstoffverbrauchs die Belohnung dominiert, lernen RL AVs, mitten auf der Autobahn zum Stillstand zu kommen, da dies Energie optimum ist. Um dies zu verhindern, haben wir dynamische Mindest- und maximale Lückenschwellen eingeführt, um ein sicheres und angemessenes Verhalten zu gewährleisten und gleichzeitig die Kraftstoffeffizienz zu optimieren. Wir bestrafen auch den Kraftstoffverbrauch von Menschen, die von Menschen angetrieben werden, die hinter dem AV unter dem Lernen eines egoistischen Verhaltens, das die Energieeinsparungen für den AV auf Kosten des umgebenden Verkehrs optimiert, davon abhalten. Insgesamt wollen wir ein Gleichgewicht zwischen Energieeinsparungen und angemessenem und sicherem Fahrverhalten haben.
Simulationsergebnisse
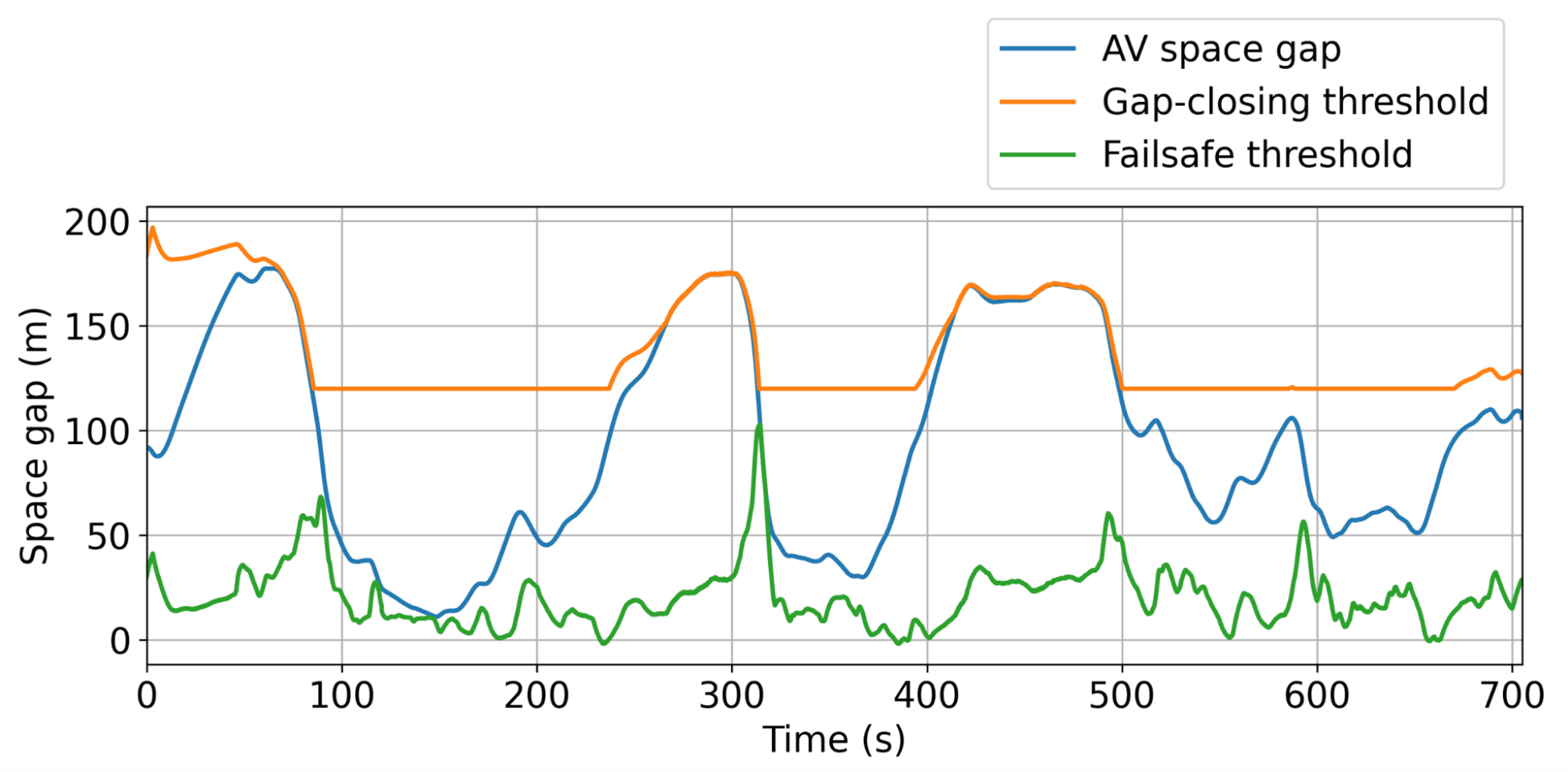
Darstellung der dynamischen Mindest- und maximalen Spaltschwellen, innerhalb derer der AV den Verkehr so effizient wie möglich frei reiben kann.
Das typische Verhalten der AVS besteht darin, etwas größere Lücken aufrechtzuerhalten als menschliche Treiber, sodass sie die bevorstehenden, möglicherweise abrupten Verkehrsabfälle effektiver absorbieren können. In der Simulation führte dieser Ansatz zu einer erheblichen Kraftstoffeinsparung von bis zu 20% bei allen Straßenkonsumenten in den am stärksten überlasteten Szenarien, wobei weniger als 5% der AVs unterwegs waren. Und diese AVs müssen keine besonderen Fahrzeuge sein! Sie können einfach Customary -Konsumgüter sein, die mit einer intelligenten adaptiven Geschwindigkeitsregelung (ACC) ausgestattet sind, was wir im Maßstab getestet haben.
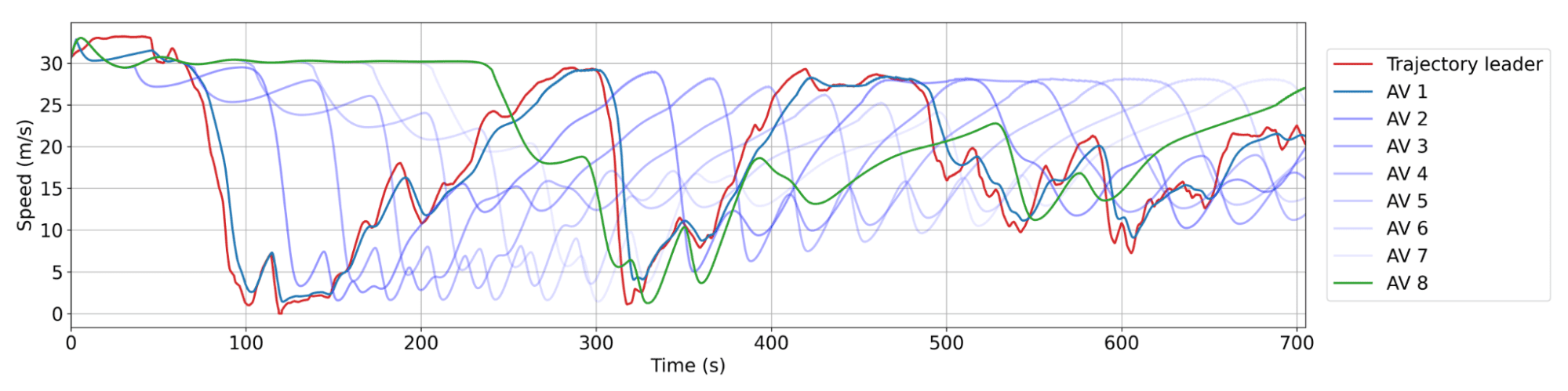
Glättungsverhalten von Rl AVs. Rot: Eine menschliche Flugbahn aus dem Datensatz. Blau: aufeinanderfolgende AVs im Zug, wo Av 1 der am engsten hinter der menschlichen Flugbahn ist. Es gibt typischerweise zwischen 20 und 25 menschliche Fahrzeuge zwischen AVs. Jeder AV verlangsamt nicht so viel oder beschleunigt nicht so schnell wie sein Anführer, was zu einer Verringerung der Wellenamplitude im Laufe der Zeit und damit zu Energieeinsparungen führt.
100 AV -Feldtest: Bereitstellen von RL im Maßstab


Unsere 100 Autos parkten während der Experimentwoche in unserem Betriebszentrum.
Angesichts der vielversprechenden Simulationsergebnisse bestand der natürliche nächste Schritt darin, die Lücke von der Simulation auf die Autobahn zu schließen. Wir nahmen die ausgebildeten RL-Controller mit und stellten sie während mehreren Tagen während der Hauptverkehrszeiten auf 100 Fahrzeugen auf der I-24 ein. Dieses groß angelegte Experiment, das wir Megavandertest bezeichneten, ist das größte Mischautonomie-Verkehrsverlagerungsexperiment, das jemals durchgeführt wurde.
Bevor wir RL -Controller im Feld bereitstellten, haben wir sie ausführlich in der Simulation geschult und bewertet und auf der {Hardware} validiert. Insgesamt beteiligten die Schritte zum Einsatz:
- Coaching in datengesteuerten Simulationen: Wir haben Autobahnverkehrsdaten von I-24 verwendet, um eine Trainingsumgebung mit realistischer Wellendynamik zu erstellen, und dann die Leistung und Robustheit des geschulten Agenten in einer Vielzahl neuer Verkehrsszenarien validieren.
- Bereitstellung auf {Hardware}: Nachdem der geschulte Controller in der Robotik -Software program validiert wurde, wird er auf das Auto hochgeladen und kann die festgelegte Geschwindigkeit des Fahrzeugs steuern. Wir arbeiten durch die Tempomat des Fahrzeugs, die als Sicherheitscontroller auf niedrigerer Ebene fungiert.
- Modularer Steuerungsrahmen: Eine wichtige Herausforderung während des Checks bestand darin, keinen Zugang zu den führenden Fahrzeuginformationssensoren zu haben. Um dies zu überwinden, wurde der RL -Controller in ein hierarchisches System, den Megacontroller, der einen Geschwindigkeitsplaner -Leitfaden kombiniert, der nachgeschaltete Verkehrsbedingungen berücksichtigt, mit dem RL -Controller als endgültiger Entscheidungsträger.
- Validierung auf {Hardware}: Die RL-Agenten waren so konzipiert, dass sie in einer Umgebung operieren, in der die meisten Fahrzeuge von Menschen angetrieben wurden, die robuste Richtlinien erfordern, die sich an unvorhersehbares Verhalten anpassen. Wir überprüfen dies, indem wir die von RL kontrollierten Fahrzeuge unter sorgfältiger menschlicher Aufsicht auf der Straße fahren und sich aufgrund der Rückmeldung ändern.

Jedes der 100 Autos ist mit einem Himbeer -Pi verbunden, auf dem der RL -Controller (ein kleines neuronales Netzwerk) eingesetzt wird.
Der RL -Controller steuert direkt das ACC -System (adaptive Cruise Management) an Bord und setzt seine Geschwindigkeit und den Wunsch nach der Entfernung ein.
Nach der Validierung wurden die RL-Controller auf 100 Autos eingesetzt und während der morgendlichen Hauptverkehrszeit auf der I-24 gefahren. Der umgebende Verkehr conflict sich des Experiments nicht bewusst, was das unvoreingenommene Verhalten des Fahrers sicherstellte. Die Daten wurden während des Experiments von Dutzenden von Overhead -Kameras entlang der Autobahn gesammelt, was zur Extraktion von Millionen einzelner Fahrzeugbahnen über eine Pc -Imaginative and prescient -Pipeline führte. Auf diesen Flugbahnen berechneten Metriken zeigen einen Pattern des reduzierten Kraftstoffverbrauchs um AVs, wie aus Simulationsergebnissen und früheren kleineren Validierungsbereitstellungen erwartet. Zum Beispiel können wir beobachten, dass je näher die Menschen hinter unseren AVs fahren, desto weniger Kraftstoff scheinen sie im Durchschnitt zu konsumieren (was unter Verwendung eines kalibrierten Energiemodells berechnet wird):
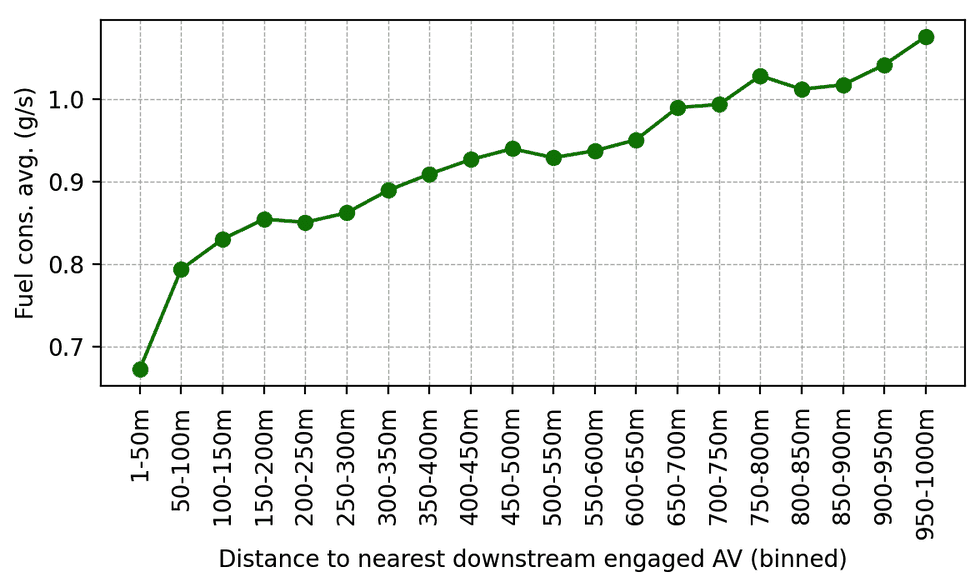
Durchschnittlicher Kraftstoffverbrauch als Funktion der Entfernung hinter dem nächstgelegenen RL-gesteuerten AV im nachgeschalteten Verkehr. Wenn menschliche Fahrer weiter hinter AVS entfernt sind, steigt ihr durchschnittlicher Kraftstoffverbrauch.
Eine andere Möglichkeit, die Auswirkungen zu messen, besteht darin, die Varianz der Geschwindigkeiten und Beschleunigungen zu messen: Je niedriger die Varianz ist, desto weniger Amplitude sollten die Wellen haben, was wir aus den Feldtestdaten beobachten. Obwohl es kompliziert ist, genaue Messungen aus einer großen Menge Kamerabotten zu erhalten, beobachten wir einen Pattern von 15 bis 20% der Energieeinsparungen in unseren kontrollierten Autos.
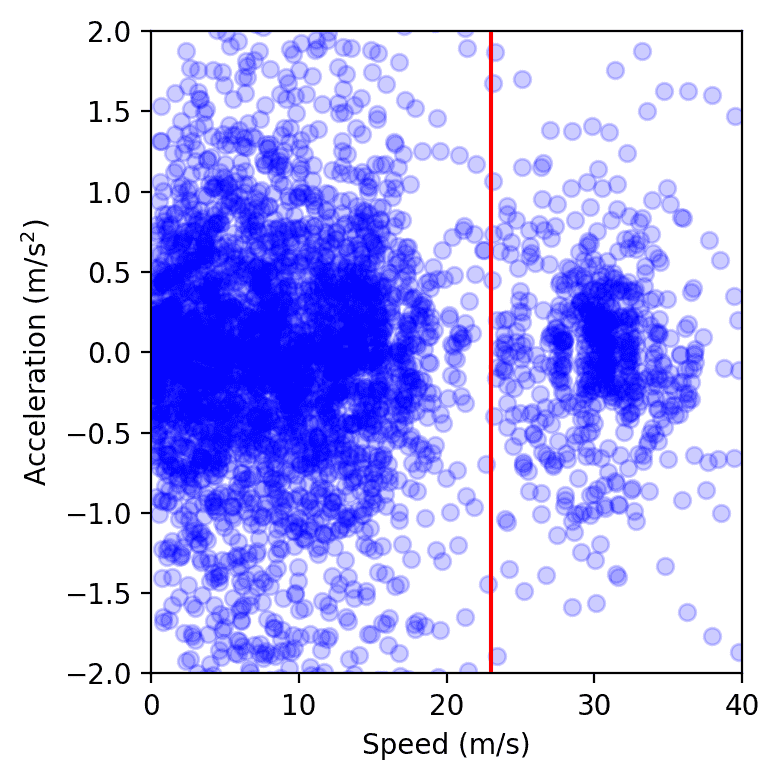
Datenpunkte von allen Fahrzeugen auf der Autobahn über einen einzigen Tag des Experiments, die im Pace-Beschleunigungsraum dargestellt wurden. Der Cluster hyperlinks von der roten Linie repräsentiert Staus, während der rechts dem freien Fluss entspricht. Wir stellen fest, dass der Stauungscluster kleiner ist, wenn AVs vorhanden sind, gemessen durch die Berechnung der Fläche eines weichen konvexen Umschlags oder durch Anpassung eines Gaußschen Kernels.
Letzte Gedanken
Der Betriebstest mit 100-Autos-Feld conflict dezentralisiert, ohne explizite Zusammenarbeit oder Kommunikation zwischen AVs, was die aktuelle Autonomie-Bereitstellung widerspiegelte und uns einen Schritt näher an glattere, energieeffizientere Autobahnen bringt. Es besteht jedoch immer noch ein großes Verbesserungspotenzial. Die Skalierung von Simulationen, um schneller und genauer mit besseren Modellen des menschlichen Fahrens zu sein, ist entscheidend für die Überbrückung der Simulation-zu-Actuality-Lücke. Die Ausstattung von AVs mit zusätzlichen Verkehrsdaten, sei es durch fortschrittliche Sensoren oder eine zentrale Planung, könnte die Leistung der Controller weiter verbessern. Während Multi-Agent RL beispielsweise vielversprechend für die Verbesserung der kooperativen Kontrollstrategien ist, bleibt dies eine offene Frage, wie die explizite Kommunikation zwischen AVs über 5G-Netzwerke die Stabilität weiter verbessern und Cease-and-Go-Wellen weiter mindern kann. Entscheidend ist, dass unsere Controller nahtlos in vorhandene Systeme für adaptive Geschwindigkeitsregelung (ACC) (ACC) integriert sind, wodurch die Feldbereitstellung im Maßstab möglich ist. Je mehr Fahrzeuge mit intelligentem Verkehrsverlagerungen ausgestattet sind, desto weniger Wellen werden wir auf unseren Straßen sehen, was weniger Verschmutzung und Kraftstoffeinsparungen für alle bedeutet!
Viele Mitwirkende haben daran teilgenommen, den Megavandertest zu erreichen! Die vollständige Liste ist auf dem verfügbar Kreiseprojekt Seite zusammen mit weiteren Particulars zum Projekt.
Mehr lesen: (Papier)