Ein grundlegendes Verständnis der Funktionsweise von NeRF durch visuelle Darstellungen
Wer sollte diesen Artikel lesen?
Ziel dieses Artikels ist es, durch visuelle Darstellungen ein grundlegendes Verständnis der Funktionsweise von NeRF für Anfänger zu vermitteln. Während verschiedene Blogs ausführliche Erklärungen zu NeRF bieten, richten sich diese oft an Leser mit einem ausgeprägten technischen Hintergrund in den Bereichen Volumenrendering und 3D-Grafik. Im Gegensatz dazu versucht dieser Artikel, NeRF mit minimalen Vorkenntnissen zu erklären, mit einem optionalen technischen Auszug am Ende für neugierige Leser. Für diejenigen, die sich für die mathematischen Particulars hinter NeRF interessieren, finden Sie am Ende eine Liste mit weiteren Lektüren.
Was ist NeRF und wie funktioniert es?
NeRF, Kurzform für Neuronale Strahlungsfelderist ein Artikel aus dem Jahr 2020, der eine neuartige Methode zum Rendern von 2D-Bildern aus 3D-Szenen vorstellt. Traditionelle Ansätze basieren auf physikbasierten, rechenintensiven Techniken wie Ray Casting und Ray Tracing. Dabei wird ein Lichtstrahl von jedem Pixel des 2D-Bilds zurück zu den Szenenpartikeln verfolgt, um die Pixelfarbe abzuschätzen. Während diese Methoden eine hohe Genauigkeit bieten (z. B. von Telefonkameras aufgenommene Bilder kommen dem, was das menschliche Auge aus demselben Winkel wahrnimmt, sehr nahe), sind sie oft langsam und erfordern erhebliche Rechenressourcen, wie z. B. GPUs, für die Parallelverarbeitung. Daher ist die Implementierung dieser Methoden auf Edge-Geräten mit begrenzten Rechenkapazitäten nahezu unmöglich.
NeRF geht dieses Downside an, indem es als Szenenkomprimierungsmethode fungiert. Es verwendet ein überangepasstes mehrschichtiges Perzeptron (MLP), um Szeneninformationen zu kodieren, die dann aus jeder Blickrichtung abgefragt werden können, um ein 2D-gerendertes Bild zu erzeugen. Bei richtiger Schulung reduziert NeRF den Speicherbedarf erheblich; Beispielsweise kann eine einfache 3D-Szene typischerweise in etwa 5 MB Daten komprimiert werden.
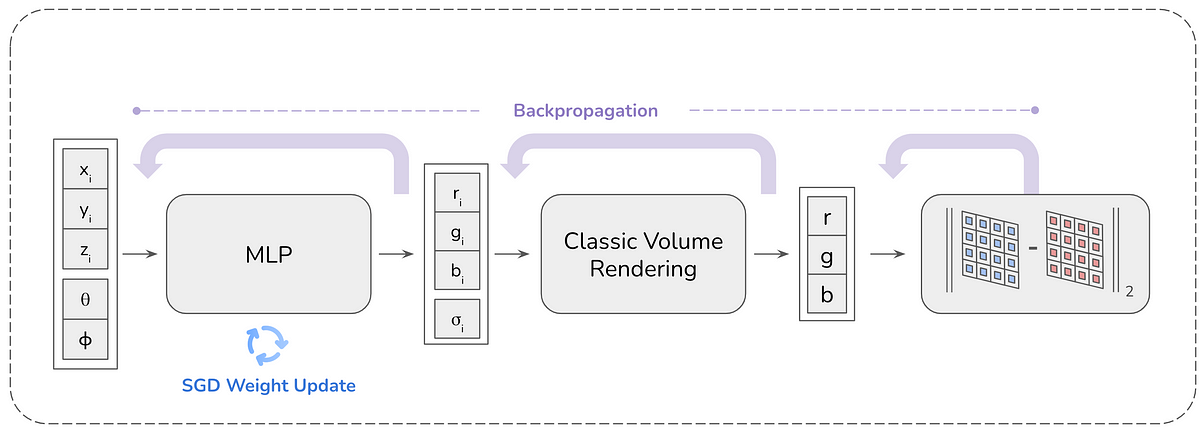
Im Kern beantwortet NeRF die folgende Frage mithilfe eines MLP:
Was sehe ich, wenn ich die Szene aus dieser Richtung betrachte?
Diese Frage wird beantwortet, indem dem MLP die Betrachtungsrichtung (in Kind von zwei Winkeln (θ, φ) oder einem Einheitsvektor) als Eingabe bereitgestellt wird und MLP RGB (gerichtet emittierte Farbe) und Volumendichte bereitstellt, die dann verarbeitet werden volumetrisches Rendering, um den endgültigen RGB-Wert zu erzeugen, den das Pixel sieht. Um ein Bild mit einer bestimmten Auflösung (z. B. HxB) zu erstellen, wird der MLP HxB-mal für die Blickrichtung jedes Pixels abgefragt und das Bild erstellt. Seit der Veröffentlichung des ersten NeRF-Papiers wurden zahlreiche Aktualisierungen vorgenommen, um die Rendering-Qualität und -Geschwindigkeit zu verbessern. Dieser Weblog konzentriert sich jedoch auf das Originalpapier von NeRF.
Schritt 1: Eingabebilder mehrfach anzeigen
NeRF benötigt verschiedene Bilder aus unterschiedlichen Blickwinkeln, um eine Szene zu komprimieren. MLP lernt, diese Bilder für unsichtbare Blickrichtungen (neuartige Ansichten) zu interpolieren. Die Informationen zur Blickrichtung eines Bildes werden mithilfe der intrinsischen und extrinsischen Matrizen der Kamera bereitgestellt. Je mehr Bilder ein breites Spektrum an Blickrichtungen abdecken, desto besser ist die NeRF-Rekonstruktion der Szene. Kurz gesagt, das grundlegende NeRF nimmt Eingabekamerabilder und die zugehörigen kamerainternen und extrinsischen Matrizen auf. (Mehr über die Kameramatrizen erfahren Sie im Weblog unten)
Schritt 2 bis 4: Sampling, Pixeliteration und Ray Casting
Jedes Bild in den Eingabebildern wird (der Einfachheit halber) unabhängig verarbeitet. Von der Eingabe werden ein Bild und die zugehörigen Kameramatrizen abgetastet. Für jedes Kamerabildpixel wird ein Strahl von der Kameramitte zum Pixel verfolgt und nach außen verlängert. Wenn die Kameramitte als o definiert ist und die Blickrichtung als Richtungsvektor d, dann kann der Strahl r