: Grenz-KI-Modelle laufen zunehmend Gefahr, strengen Exportkontrollen oder steigenden API-Kosten ausgesetzt zu sein.
Während diese Technologie in unser tägliches Leben Einzug hält, ist die Open-Supply-Bewegung nicht nur eine philosophische Präferenz, sondern ein notwendiger Mechanismus, um die KI in den Händen alltäglicher Benutzer zu halten. Wir sind noch nicht gleichberechtigt; Die proprietären Modelle aus den riesigen Technologielabors haben immer noch einen souveränen Vorsprung in Sachen reiner Leistung. Aber wir können hoffen, dass sich die Lücke schnell schließt. Eine unabhängige Gemeinschaft von Forschern und Entwicklern arbeitet rund um die Uhr daran, sicherzustellen, dass diese Technologie für jeden mit einem Pc zugänglich ist.
Heute ist die Grundlage für eine echte Demokratisierung bereits gelegt: Sie können ein leistungsstarkes Modell vollständig auf Ihrem eigenen Laptop computer ausführen. Für das heutige Experiment habe ich mir vorgenommen, ein großes Sprachmodell zu finden, das vollständig auf meinem Laptop computer ausgeführt werden kann – und es für die einfachen Aufgaben zu verwenden, die ich normalerweise einem großen Labormodell überlassen würde.
Wir installieren Qwen 3 8B auf meinem MacBook Air, führe es vollständig offline aus und habe endlich ein Sprachmodell, das auf meinem eigenen Pc statt in einem entfernten Rechenzentrum läuft. Der Qwen Die Modellfamilie wurde von Alibaba (dem chinesischen Unternehmen) geschult und ist vollständig Open Supply und im Web für jedermann zum Herunterladen verfügbar. Das Modell verfügt über 9 Milliarden Gewichte und belegt im geladenen Zustand etwa 6 GB Ihres RAM.
Was nun folgt, ist eine praktische, umfassende Anleitung zum Ausführen eines ordnungsgemäßen lokalen LLM auf einem Apple Silicon Mac und enthält die Terminalbefehle, die Sie benötigen. Doch bevor wir das Terminal öffnen, müssen wir darüber sprechen, warum sich das überhaupt lohnt.
Warum das tun?
Meistens sind Cloud-Modelle besser und einfacher. Ich behaupte nicht, dass ein 8-Milliarden-Parameter-Modell auf einem Laptop computer die Spitzen-KI übertrifft. Das ist nicht der Fall und ich werde weiterhin die Large-Cloud-Modelle für schwere Lasten verwenden.
Aber die ständigen Preis- und Souveränitätskriege rund um KI könnten Open-Supply- und lokale Modelle für eine Zukunft, in der der Zugang zu der Technologie einen großen Unterschied machen wird, sehr related machen. Jedes Mal, wenn Sie Claude oder ChatGPT verwenden, senden Sie Ihre Daten an einige Distant-Server, wo der Zugriff jederzeit blockiert werden kann.
„Digitale Souveränität„ist ein großartiger Ausdruck für einen ganz gewöhnlichen Wunsch: Vielleicht möchten wir das Ding besitzen, das unsere empfindlichsten Gedanken liest, genauso wie Sie ein physisches Notizbuch besitzen oder etwas Bargeld zu Hause aufbewahren.
Ein lokales Modell beantwortet dies in der KI-Welt sauber. Sobald es heruntergeladen ist, verlässt nichts die Maschine. Keine API-Schlüssel, keine wechselnden Nutzungsbedingungen, keine stillschweigenden Richtlinien zur Datenaufbewahrung. Sie können die WLAN-Karte herausziehen und sie funktioniert weiter. Für den hochsensiblen Teil Ihrer Arbeit kann allein das den Eintrittspreis wert sein.
Die Leute sagen gerne, dass lokale Fashions „demokratisierend„KI. Ich möchte, dass das wahr ist, aber wir sind noch nicht am Ziel. Das Ausführen dieses Stacks setzt immer noch voraus, dass Sie einen 1.500-Euro-Laptop computer mit riesigem einheitlichem Speicher besitzen und sich mit einer Befehlszeile auskennen. Das ist ein schmaler, glücklicher Ausschnitt der Welt.“
Aber die Flugbahn ist demokratisierend. Vor zwei Jahren erforderte der Betrieb eines anständigen Offline-Modells eine dedizierte Workstation und erhebliche technische Probleme. Dieses Wochenende habe ich ein paar Stunden und 5 Gigabyte Festplattenspeicher gebraucht.
Additionally lasst uns das Ding installieren.
Die Maschine und die Spezifikationen
Ich habe das auf einem gebaut MacBook Air M4 mit 24 GB einheitlicher Speicher und etwa 235 GB freier Speicherplatz. Das battle ein Neuanfang: kein Homebrew, keine Albträume in der Python-Umgebung.
Die Zahl, die hier wirklich zählt, ist die 24 GB. Der „Unified Reminiscence“ von Apple Silicon ist der Zaubertrick, der Macs dabei so außergewöhnlich intestine macht. Da sich CPU und GPU genau den gleichen Speicherpool teilen, müssen große neuronale Netzwerkgewichte nicht mühsam hin- und hergeschoben werden.
Ein 8B-Modell belegt etwa 5 GB auf der Festplatte und verfügt im geladenen Zustand über etwa 6 GB Speicher. Auf einer 24-GB-Maschine ist das äußerst komfortabel. Sie könnten ein 14B-Modell verwenden und trotzdem Dutzende Browser-Registerkarten geöffnet lassen. (Wenn Sie einen 8-GB-Mac verwenden, bleiben Sie bei den 1,5B- oder 3B-Modellen und schließen Sie Ihre anderen Apps.)
Warum Ollama?
Es gibt ein Dutzend Möglichkeiten, lokale KI auszuführen, und die meisten erfordern, dass Sie sich um Compiler-Flags und Abhängigkeitsbäume kümmern. Das solltest du nicht müssen.
Ollama ist ein Open-Supply-Framework und -Device, das einfach funktioniert. Es handelt sich um eine einzelne Binärdatei, die einen hochoptimierten Modellläufer bündelt (llama.cpp unter Verwendung von Apples Steel zur GPU-Beschleunigung), einer Modellregistrierung im Docker-Stil und einer lokalen HTTP-API. Sie installieren es, ziehen ein Modell und sprechen mit ihm. Das ist es!
Schritt 1: Ollama installieren (kein Homebrew erforderlich)
Ollama wird als Customary-MacOS-App in einer ZIP-Datei geliefert. Die Befehlszeilenschnittstelle (CLI) befindet sich verborgen im App-Bundle, sodass wir sie vollständig von Hand einrichten können.
# Obtain the Apple Silicon construct
cd ~/Downloads
curl -L -o Ollama-darwin.zip https://ollama.com/obtain/Ollama-darwin.zip
# Unzip and transfer the app into your Functions folder
unzip -o -q Ollama-darwin.zip
mv Ollama.app /Functions/Wenn Sie nicht wissen, wie Sie das Terminal öffnen, gehen Sie einfach zu Ihren Mac-Anwendungen und suchen Sie nach „Terminal“:
Schritt 2: Setzen Sie Ollama auf Ihren WEG
Ich wollte nicht mit ihm kämpfen sudo Berechtigungen in /usr/native/binadditionally habe ich die gebündelte CLI mit einem lokalen Verzeichnis, das ich besitze, symbolisch verknüpft – dies ist nur eine praktische Verknüpfung, um die Set up zu beschleunigen und das LLM hochzufahren.
# Create a neighborhood bin listing and symlink the CLI
mkdir -p ~/.native/bin
ln -sf /Functions/Ollama.app/Contents/Assets/ollama ~/.native/bin/ollama
# Make it everlasting in your zsh profile
echo 'export PATH="$HOME/.native/bin:$PATH"' >> ~/.zshrc
# Apply it to your present shell
export PATH="$HOME/.native/bin:$PATH"
ollama --versionSchritt 3: Starten Sie den Server
Ollama führt einen schlanken Hintergrundserver aus, um die API verfügbar zu machen und den Speicher Ihres Computer systems zu verwalten.
# Begin the server and log output
mkdir -p ~/.ollama/logs
nohup ollama serve > ~/.ollama/logs/serve.log 2>&1 &
# Ping it to verify if it is alive
curl -s http://127.0.0.1:11434/api/modelWenn der obige Befehl eine „Model“ zurückgibt, ist Ollama eingerichtet!

Hinweis: Sie können auch einfach auf die Ollama-App in Ihrem Anwendungsordner doppelklicken, um diesen Server über Ihre Menüleiste auszuführen. Ich habe es über das Terminal gemacht, um genau zu sehen, was unter der Haube passiert.
Schritt 4: Ziehen Sie das Modell
Nun, das hier ist so einfach wie es nur geht:
ollama pull qwen3:8b
ollama recordGeh und mach einen Kaffee. Der Obtain ist ca. 5,2 GB groß.
Nachdem Sie ollama record ausgeführt haben, sehen Sie das für Sie verfügbare Modell:

Schritt 5: Sprechen Sie mit dem neuen digitalen Gehirn in Ihrem Pc
Sie haben drei verschiedene Möglichkeiten, mit Ihrem neuen lokalen Modell zu interagieren.
1. Interaktiver Chat (am einfachsten)
ollama run qwen3:8bDurch Ausführen des folgenden Befehls wird der interaktive Chat gestartet:

Im Standardmodus gibt das Modell die „Denk-Tokens“ aus, etwas, das in den meisten kommerziellen Instruments normalerweise abstrahiert und verborgen ist.
Ich werde damit beginnen, mein lokales Modell zu fragen, was es über Open-Supply-Modelle denkt:

Der hellgraue Textual content stellt den internen Argumentationsprozess des Modells dar. Diese Modelle führen umfangreiche Berechnungen durch, bevor sie eine Antwort generieren, und bei lokalen Modellen macht diese Denkphase einen erheblichen Teil der Gesamtzeit aus, bis das Modell eine Antwort ausgibt.
Nach dem Denkprozess ist hier die Antwort des Modells:

Bei den meisten Instruments behalten diese Modelle auch einen gewissen Kontext aus früheren Interaktionen bei:

Da ich mich im Batteriesparmodus befinde, gibt das Modell 5,7 Token professional Sekunde aus. Wenn ich es ablehne, werden wir wahrscheinlich einen Wert von 15–20 Token professional Sekunde sehen.
2. One-Shot-Terminalbefehle
Um mit Ihrem lokalen Modell zu interagieren, können Sie die Frage auch außerhalb des interaktiven Modus stellen:
ollama run qwen3:8b "write a python script that tells me what number of vowels a phrase has"Hier ist das Skript, das unser lokales großes Sprachmodell erstellt hat:
```python
# Immediate the person for a phrase
phrase = enter("Enter a phrase: ")
# Outline the set of vowels
vowels = {'a', 'e', 'i', 'o', 'u'}
# Initialize a counter
rely = 0
# Convert the phrase to lowercase and verify every character
for char in phrase.decrease():
if char in vowels:
rely += 1
# Output the end result
print(f"Variety of vowels: {rely}")3. Die HTTP-API (für Skripte und Apps)
Können Sie dies nur innerhalb der Terminalbefehle verwenden?
Natürlich nicht! Wenn Sie mit Python vertraut sind, können Sie jedes lokale Skript mit Ihrem lokalen Modell erstellen:
import json, urllib.request
req = urllib.request.Request(
"http://127.0.0.1:11434/api/generate",
knowledge=json.dumps({
"mannequin": "qwen3:8b",
"immediate": "Give me three makes use of for a neighborhood LLM.",
"stream": False,
"assume": False,
}).encode(),
headers={"Content material-Kind": "software/json"},
)
print(json.hundreds(urllib.request.urlopen(req).learn())("response"))Hier ist die Antwort des Modells nach der Ausführung dieses Python-Skripts:
Positive! Listed below are three widespread and sensible makes use of for a **native LLM (Massive Language Mannequin)**:
1. **Personalised Help and Productiveness**
An area LLM can act as a personal AI assistant, serving to with duties like e-mail drafting, scheduling, note-taking, and even coding. Because it runs regionally, it maintains person privateness and does not depend on web connectivity.
2. **Content material Creation and Language Processing**
You should utilize a neighborhood LLM to generate artistic content material resembling weblog posts, tales, scripts, or advertising copy. It could possibly additionally help with language translation, grammar checking, and summarizing textual content.
3. **Customized Functions and Integration**
An area LLM could be built-in into customized functions or workflows, resembling chatbots, buyer assist techniques, or knowledge evaluation instruments. This enables for tailor-made options with out exposing delicate knowledge to exterior servers.
Let me know if you would like examples of the right way to implement these makes use of!Cool! Sie können jetzt ganz einfach Ihre eigenen Anwendungen mit Ihrem eigenen lokalen Modell erstellen.
Feinabstimmung der Erfahrung – Zähmung der „Denk“-Token
Qwen 3 ist ein hybrides Argumentationsmodell. Standardmäßig wird eine ausführliche Meldung generiert <assume>...</assume> Block skizziert seinen Gedankengang, bevor er die eigentliche Antwort gibt. Manchmal möchten Sie die Mathematik sehen, aber meistens möchten Sie einfach nur schnell eine Antwort erhalten (und etwas Zeit sparen, indem Sie auf die Ausgabe-Tokens des Denkprozesses warten).
So umgehen Sie den Argumentationsdurchgang:
- Deaktivieren Sie es vollständig:
ollama run qwen3:8b --think=false - Führen Sie es aus, aber verstecken Sie es auf der Benutzeroberfläche:
ollama run qwen3:8b --hidethinking - In Skripten: Passieren
"assume": falsein Ihrer JSON-Nutzlast.
Eine Warnung zur Websuche
Modelle sind bis zu ihren Trainingsdaten statisch. Das bedeutet, dass sie nach der Schulung nicht mehr auf Daten zugreifen können und Unternehmen sich auf Websuchtools verlassen, um die Leistungsfähigkeit der Modelle zu erweitern. Zum Beispiel für unser lokales Modell:

Mit Ollama können Sie dem Modell jedoch ein Websuchtool zur Verfügung stellen. Das klingt unglaublich, aber es gibt einen Haken.
Die Suche selbst wird auf dem gehosteten Cloud-Dienst von Ollama ausgeführt. Sobald Sie es aktivieren, werden Ihre Eingabeaufforderungen über das Web gesendet, um Suchergebnisse abzurufen. Das Modell bleibt lokal, Ihre Abfragen jedoch nicht. Dies verstößt möglicherweise gegen den Grundsatz der Privatsphäre, den Sie mit der Einrichtung gewährleisten möchten.
Bonus: VS-Code-Integration
Das ultimative Endspiel für mich battle die Anschaffung eines Offline-Codierungsassistenten. Der sauberste und völlig freie Weg hierfür ist der Proceed.dev Verlängerung.
- Installieren Sie VS Code und die Proceed-Erweiterung.
- Öffnen Sie die Konfigurationsdatei von Proceed unter
~/.proceed/config.yaml. - Richten Sie es auf Ihren lokalen Ollama-Server:
identify: Native Assistant
model: 1.0.0
fashions:
- identify: Qwen3 8B (native)
supplier: ollama
mannequin: qwen3:8b
roles:
- chat
- edit
- apply
- identify: Qwen3 8B Autocomplete
supplier: ollama
mannequin: qwen3:8b
roles:
- autocompleteProfi-Tipp: Ein 8B-Modell ist etwas zu schwer für die Latenz von Sekundenbruchteilen, die Sie für die automatische Vervollständigung von Inline-Code wünschen. Ich empfehle dringend, speziell für diese Aufgabe ein kleineres Modell zu verwenden (ollama pull qwen2.5-coder:1.5b-base), ordnet es dem zu autocomplete Rolle und überlassen Qwen3 8B die schwerere Rolle chat Aufgaben.
Was ist, wenn ich einen Home windows-Pc habe?
Da ich für dieses Tutorial kein Home windows verwende, habe ich es nicht ausführlich ausprobiert. Die gute Nachricht ist jedoch, dass das Ollama-Paket für Home windows-Pc verfügbar ist Hier.
Der Installationsprozess unterscheidet sich möglicherweise etwas, aber die Logik hinter der Verwendung von Ollama und dem Ziehen der Modelle ist genau dieselbe.
Wohin mich das führt
Mein Gesamtspeicherplatz für dieses Projekt betrug 156 MB für die Software program und 5,2 GB für das Modell selbst.
Ich habe jetzt ein hochleistungsfähiges Sprachmodell, das dauerhaft auf meiner Festplatte gespeichert ist. Für öffentliche, komplexe Arbeiten werde ich weiterhin zur Cloud greifen. Aber für die Entwürfe, die ich nicht in die Trainingsdaten, die Offline-Flüge und die rechtlich gebundenen Kundendokumente einfließen lassen möchte? Diese Informationen befinden sich jetzt auf meinem Pc.
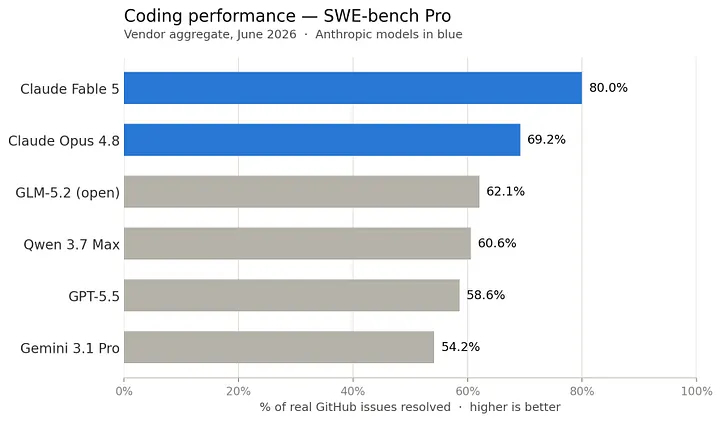
Für die meisten Menschen magazine das immer noch etwas zu technisch sein, aber die Dinge werden immer demokratisierter. Dabei kommt es nicht nur auf die Verfügbarkeit an. Was die Leistung betrifft, verbessern sich Open-Supply-Modelle rasant und liefern Ergebnisse, die die Zukunft der lokalen KI unglaublich vielversprechend erscheinen lassen. Zum Beispiel, GLM 5.2 Und Qwen 3,7 Max holen mit der Leistung der großen Labormodelle auf:

Da die technischen Anforderungen immer weiter sinken, wird „der Besitz einer eigenen KI“ kein Luxus mehr sein, der Entwicklern mit teuren Laptops vorbehalten ist. Das ist die Model der KI-Demokratisierung, an die ich tatsächlich glaube.
Geben Sie Ihrem Laptop computer dieses Wochenende ein neues Gehirn und es lebe Open Supply!