LLMs werden Datenwissenschaftler nicht ersetzen, aber sie werden die Artwork und Weise verändern, wie wir mit Entscheidungsträgern zusammenarbeiten.
LLMs sollen die Datenwissenschaft einfacher machen. Sie generieren Python und SQL für jede erdenkliche Funktion und verkürzen so eine sich wiederholende Aufgabe von Minuten auf Sekunden. Doch das Zusammenstellen, Warten und Überprüfen von Daten-Workflows ist mit LLMs schwieriger geworden, nicht einfacher.
LLM-Codegeneratoren stellen für Datenwissenschaftler im privaten Sektor zwei miteinander verbundene Probleme dar. Erstens haben LLMs die Erwartung geweckt, dass Datenwissenschaftler schneller arbeiten sollten, aber Datenschutzerwägungen können erfordern, dass sie keine vertraulichen Daten an einen LLM senden. In diesem Fall müssen Datenwissenschaftler LLMs verwenden, um Code stückweise zu generieren und sicherzustellen, dass der LLM den gesamten Datensatz nicht kennt.
Daraus ergibt sich das zweite Downside: ein Mangel an Transparenz und Reproduzierbarkeit bei der Interpretation der Ergebnisse. Wenn Datenwissenschaftler Analysen auf „traditionelle“ Weise durchführen, erstellen sie deterministischen Code, der beispielsweise in Python in Jupyter-Notebooks geschrieben wird, und erstellen die endgültige Analyseausgabe. Ein LLM ist nicht deterministisch. Stellen Sie ihm dieselbe Frage mehrmals, und Sie erhalten möglicherweise unterschiedliche Antworten. Während der Workflow additionally möglicherweise zu einer Erkenntnis führt, ist der Datenwissenschaftler möglicherweise nicht in der Lage, den Prozess zu reproduzieren, der dazu geführt hat.
Somit können LLMs die Generierung von Code für einzelne Schritte beschleunigen, sie bergen jedoch auch das Risiko, das Vertrauen zwischen Datenteams und Entscheidungsträgern zu untergraben. Die Lösung liegt meiner Meinung nach in einem eher dialogorientierten Ansatz für die Analyse, bei dem Datenexperten und Entscheidungsträger gemeinsam Erkenntnisse gewinnen und diskutieren.
Führungskräfte investieren in ihr Finances für Information Science in der Hoffnung, dass sie damit Entscheidungen vorantreiben, die den Gewinn und den Wert für die Aktionäre steigern – aber sie wissen nicht unbedingt, wie Analytics funktioniert, oder es interessiert sie auch nicht. Sie wollen schneller mehr Informationen, und wenn LLMs die Code-Produktion für Information Science beschleunigen, dann ist es besser, wenn Datenteams mit ihnen Code generieren. Das alles läuft reibungslos Wenn Der Code ist relativ einfach, sodass Datenwissenschaftler jede Komponente erstellen und dann abfragen können, bevor sie mit der nächsten fortfahren. Mit zunehmender Komplexität wird dieser Prozess jedoch komplizierter, was zu Analysen führt, die fehleranfälliger, schwieriger zu dokumentieren und zu überprüfen und für Geschäftsbenutzer viel schwieriger zu erklären sind.
Warum? Erstens arbeiten Datenwissenschaftler zunehmend in mehreren Sprachen und Dialekten, die für ihre Instruments wie Snowflake oder Databricks spezifisch sind. LLMs generieren zwar SQL und Python, entbinden Datenwissenschaftler jedoch nicht von ihrer Verantwortung, diesen Code zu verstehen und zu testen. Die erste Verteidigungslinie gegen Halluzinationen zu sein – in mehreren Programmiersprachen – ist eine erhebliche Belastung.
Zweitens sind LLMs inkonsistent, was die Integration von neu generiertem Code chaotisch machen kann. Wenn ich eine Eingabeaufforderung ausführe, die eine Tabellenverknüpfungsfunktion in Python anfordert, kann mir ein LLM bei jeder Ausführung der Eingabeaufforderung eine andere Ausgabe liefern. Wenn ich einen Workflow leicht ändern möchte, kann das LLM Code generieren, der mit allem, was es mir zuvor geliefert hat, inkompatibel ist. Soll ich in diesem Fall versuchen, den vorhandenen Code anzupassen, oder den neuen Code verwenden? Und was, wenn der alte Code irgendwo in der Produktion eingesetzt wird? Das ist ziemlich chaotisch.
Drittens bietet die LLM-Codegenerierung das Potenzial, einen Fehler schnell zu skalieren und dann die Grundursache zu verbergen. Wenn der Code beispielsweise tief verschachtelt ist, kann es einfacher sein, von vorne zu beginnen, als das Downside zu beheben.
Wenn eine Analyse hervorragend funktioniert und Entscheidungsträger davon profitieren, wird niemand die Particulars des Workflows wissen wollen. Wenn Entscheidungsträger jedoch herausfinden, dass sie auf der Grundlage irreführender Analysen gehandelt haben – und damit ihre Prioritäten nicht mehr berücksichtigen –, werden sie den Daten zunehmend misstrauen und verlangen, dass Datenwissenschaftler ihre Arbeit erklären. Es ist schwierig, Geschäftsbenutzer davon zu überzeugen, einer Analyse zu vertrauen, wenn diese in einem Pocket book vorliegt und in verschachteltem Code gerendert wird, wobei jede Komponente aus einem LLM stammt.
Wenn ich anderen Datenwissenschaftlern ein Python-Notizbuch zeigen würde, würden sie verstehen, was ich vorhabe – aber sie hätten Schwierigkeiten, die Grundursache für etwaige Probleme in diesem Code zu identifizieren. Das Downside ist, dass wir versuchen, in Code zu denken und zu argumentieren. Programmiersprachen sind wie Morsecode in dem Sinne, dass sie ohne eine Umgangssprache, die Kontext und Bedeutung liefert, nichts bedeuten. Eine mögliche Lösung besteht additionally darin, weniger Zeit im Land des Codes und mehr Zeit im Land des einfachen Englischen zu verbringen.
Wenn wir Analysen auf Englisch durchführen, dokumentieren und diskutieren, können wir die von uns entwickelten Workflows und deren Sinnhaftigkeit besser verstehen. Außerdem fällt es uns leichter, diese Workflows den Geschäftsbenutzern zu vermitteln, die diese Analysen zwar umsetzen sollen, ihnen aber möglicherweise nicht vollständig vertrauen.
Seit 2016 erforsche ich, wie man Code ins Englische und natürliche Sprachen in SQL und Python abstrahiert. Diese Arbeit führte schließlich dazu, dass mein Kollege Rogers Jeffrey Leo John und ich ein Unternehmen namens DataChat gründeten, das auf der Idee basierte, Analysen mithilfe von einfachen englischen Befehlen und Fragen zu erstellen. Bei meiner Arbeit an der Carnegie Mellon College verwende ich dieses Instrument häufig für die anfängliche Datenbereinigung und -aufbereitung, -erkundung und -analyse.
Was wäre, wenn Unternehmensdatenteams, statt ihre Arbeit nur auf Englisch zu dokumentieren, mit Entscheidungsträgern zusammenarbeiten würden, um ihre ersten Analysen in einer Reside-Umgebung zu erstellen? Anstatt Stunden isoliert an Analysen zu arbeiten, die möglicherweise nicht reproduzierbar sind und die wichtigsten Fragen der Führungskräfte nicht beantworten, würden Datenwissenschaftler Analysesitzungen so leiten, wie Kreative Brainstorming-Sitzungen leiten. Dies ist ein Ansatz, der Vertrauen und Konsens schaffen könnte.
Um zu verdeutlichen, warum dies eine lohnende Richtung für die Enterprise Information Science ist, werde ich anhand eines Beispiels demonstrieren, wie dies aussehen könnte. Ich werde DataChat verwenden, möchte aber betonen, dass es andere Möglichkeiten gibt, Code in der Umgangssprache darzustellen und Daten-Workflows mit LLMs zu dokumentieren.
Um es noch einmal zusammenzufassen: Wir verwenden Programmiersprachen, die LLMs mittlerweile fließend beherrschen – aber sie können zahlreiche Lösungen für dieselbe Frage finden, was unsere Fähigkeit beeinträchtigt, die Qualität unseres Codes aufrechtzuerhalten und Analysen zu reproduzieren. Dieser Establishment birgt ein hohes Risiko, dass Analysen Entscheidungsträger in die Irre führen und zu kostspieligen Maßnahmen führen, was das Vertrauen zwischen Analyseentwicklern und -nutzern untergräbt.
Jetzt jedoch sitzen wir in einem Sitzungssaal mit Führungskräften der obersten Führungsebene eines E-Commerce-Unternehmens, das auf Elektronik spezialisiert ist. Die Datensätze in diesem Beispiel werden so generiert, dass sie realistisch aussehen, stammen aber nicht von einem tatsächlichen Unternehmen.
Eine typische Schritt-für-Schritt-Anleitung zur Analyse eines E-Commerce-Datensatzes in Python könnte wie folgt beginnen:
import pandas as pd# Path to your dataset
file_path = 'path/to/your/dataset.csv'
# Load the dataset
df = pd.read_csv(file_path)
# Show the primary few rows of the dataframe
print(df.head())
Dies ist für einen Datenwissenschaftler aufschlussreich – wir wissen, dass der Programmierer einen Datensatz geladen hat. Genau das werden wir vermeiden. Dem Geschäftsbenutzer ist das egal. In englischer Sprache zusammengefasst ist hier der entsprechende Schritt mit unseren Datensätzen:

Das C-Degree-Staff versteht jetzt, welche Datensätze wir in die Analyse einbezogen haben, und möchte sie als einen Datensatz untersuchen. Daher müssen wir diese Datensätze zusammenführen. Ich verwende einfache englische Befehle, als würde ich mit einem LLM sprechen (was ich indirekt auch bin):

Ich habe jetzt einen kombinierten Datensatz und eine KI-generierte Beschreibung, wie sie verknüpft wurden. Beachten Sie, dass mein vorheriger Schritt, das Laden des Datensatzes, sichtbar ist. Wenn mein Publikum mehr über die tatsächlichen Schritte erfahren möchte, die zu diesem Ergebnis geführt haben, kann ich den Workflow aufrufen. Es handelt sich um eine ausführliche Beschreibung des Codes, geschrieben in Guided English Language (GEL), den wir ursprünglich in einer wissenschaftlichen Arbeit entwickelt haben:

Jetzt kann ich Fragen des C-Degree-Groups beantworten, der Fachexperten in diesem Geschäft. Gleichzeitig führe ich die Analyse durch und schule das Staff im Umgang mit diesem Instrument (denn letztendlich möchte ich, dass sie die grundlegenden Fragen selbst beantworten und mir Aufgaben zuweisen, bei denen ich mein gesamtes Können einsetzen kann).
Dem CFO fällt auf, dass für jeden bestellten Artikel ein Preis angegeben ist, jedoch nicht der Gesamtbetrag professional Bestellung. Er möchte den Wert jeder Bestellung sehen, additionally fragen wir:

Der CMO fragt nach den Umsätzen bestimmter Artikel und wie diese zu verschiedenen Zeitpunkten im Jahr schwanken. Dann wirft der CEO eine strategischere Frage auf. Wir haben ein Mitgliedschaftsprogramm wie Amazon Prime, das darauf ausgelegt ist, den Buyer Lifetime Worth zu erhöhen. Wie wirkt sich die Mitgliedschaft auf den Umsatz aus? Das Staff geht davon aus, dass die Mitglieder mehr bei uns ausgeben, aber wir fragen:

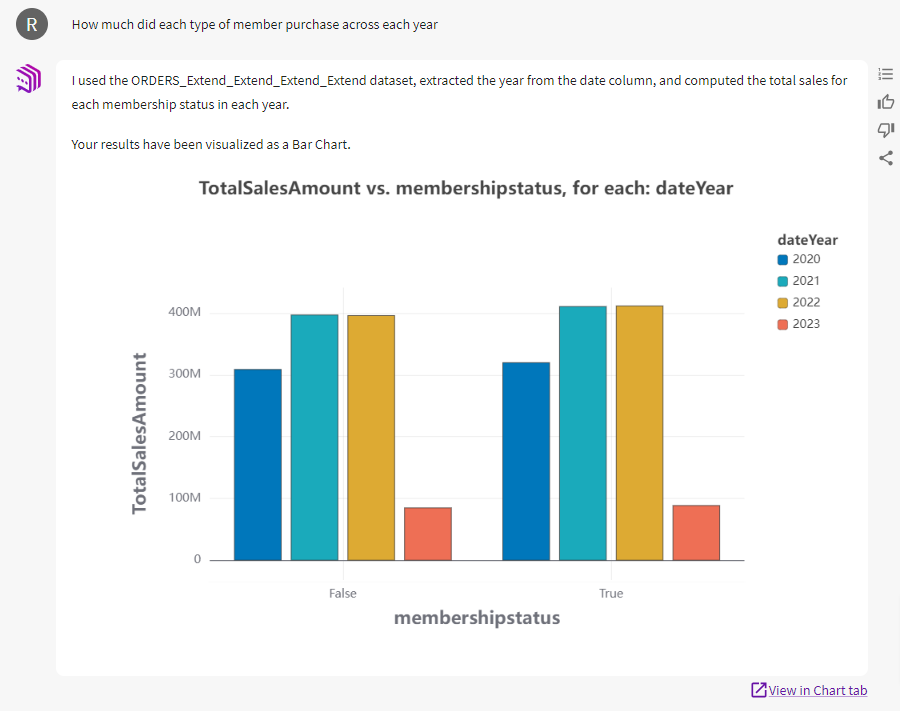
Das Diagramm zeigt, dass die Mitgliedschaft den Umsatz kaum steigert. Das Führungsteam ist überrascht, aber sie haben die Analyse mit mir durchgegangen. Sie wissen, dass ich einen robusten Datensatz verwende. Sie fragen, ob dieser Pattern über mehrere Jahre anhält:
Von Jahr zu Jahr scheint die Mitgliedschaft kaum einen Unterschied bei den Käufen zu machen. Aktuelle Investitionen in die Steigerung der Mitgliederzahlen sind wohl verschwendet. Es könnte sinnvoller sein, Mitgliedervorteile oder -stufen zu testen, die darauf ausgelegt sind, die Käufe zu steigern. Dies könnte ein interessantes Projekt für unser Datenteam sein. Wenn wir stattdessen einen Bericht per E-Mail an die Geschäftsführung geschickt hätten, in dem behauptet wird, dass die Mitgliedschaft keinen Einfluss auf die Verkäufe hat, wäre der Widerstand viel größer.
Wenn jemand, der an der aktuellen Mitgliedschaftsstrategie beteiligt ist, mit dieser Schlussfolgerung nicht zufrieden ist – und selbst sehen möchte, wie wir zu dieser Schlussfolgerung gekommen sind –, können wir den Workflow für dieses Diagramm allein teilen:
Unsere Analysesitzung geht zu Ende. Der Workflow ist dokumentiert, was bedeutet, dass ihn jeder überprüfen und reproduzieren kann (GEL steht für den exakten Code). In einigen Monaten, nachdem wir neue Mitgliedschaftsfunktionen getestet und implementiert haben, könnten wir diese Schritte für die aktualisierten Datensätze erneut ausführen, um zu sehen, ob sich die Beziehung zwischen Mitgliedschaft und Umsatz im Laufe der Zeit geändert hat.
Normalerweise wird Information Science auf Bestellung erstellt. Entscheidungsträger fordern Analysen zu dem einen oder anderen Thema an; das Datenteam liefert sie; ob und wie die Entscheidungsträger diese Informationen verwenden, ist den Analysten und Datenwissenschaftlern nicht unbedingt bekannt. Vielleicht haben die Entscheidungsträger aufgrund der ersten Analyse neue Fragen, aber die Zeit ist abgelaufen – sie müssen sofort handeln. Es bleibt keine Zeit, weitere Erkenntnisse anzufordern.
Durch die Nutzung von LLMs können wir die Datenwissenschaft gesprächiger und kollaborativer gestalten und gleichzeitig die Geheimnisse darüber lüften, woher die Analysen kommen und ob sie vertrauenswürdig sind. Datenwissenschaftler können mithilfe weit verbreiteter Instruments Sitzungen in einfachem Englisch durchführen, wie ich sie gerade veranschaulicht habe.
Konversationsanalysen machen die Pocket book-Umgebung nicht irrelevant – sie ergänzen sie, indem sie die Qualität der Kommunikation zwischen Datenwissenschaftlern und Geschäftsbenutzern verbessern. Hoffentlich führt dieser Analyseansatz zu besser informierten Entscheidungsträgern, die lernen, interessantere und gewagtere Fragen zu Daten zu stellen. Vielleicht führen diese Gespräche dazu, dass sie sich mehr um die Qualität der Analysen kümmern und weniger darum, wie schnell wir sie mit LLMs zur Codegenerierung erstellen können.
Sofern nicht anders angegeben, stammen alle Bilder vom Autor.