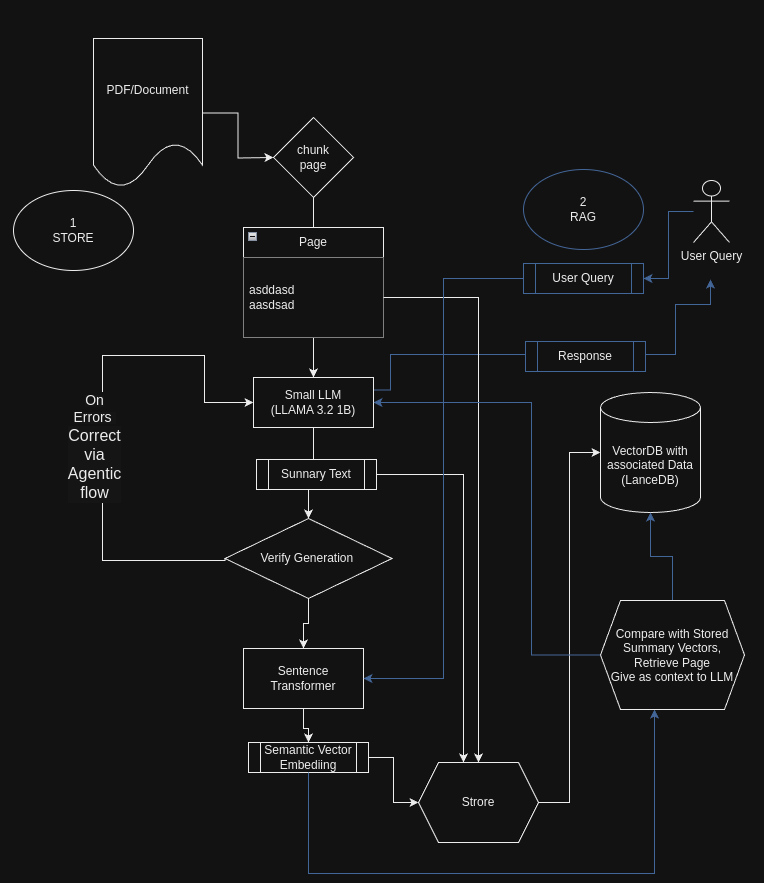
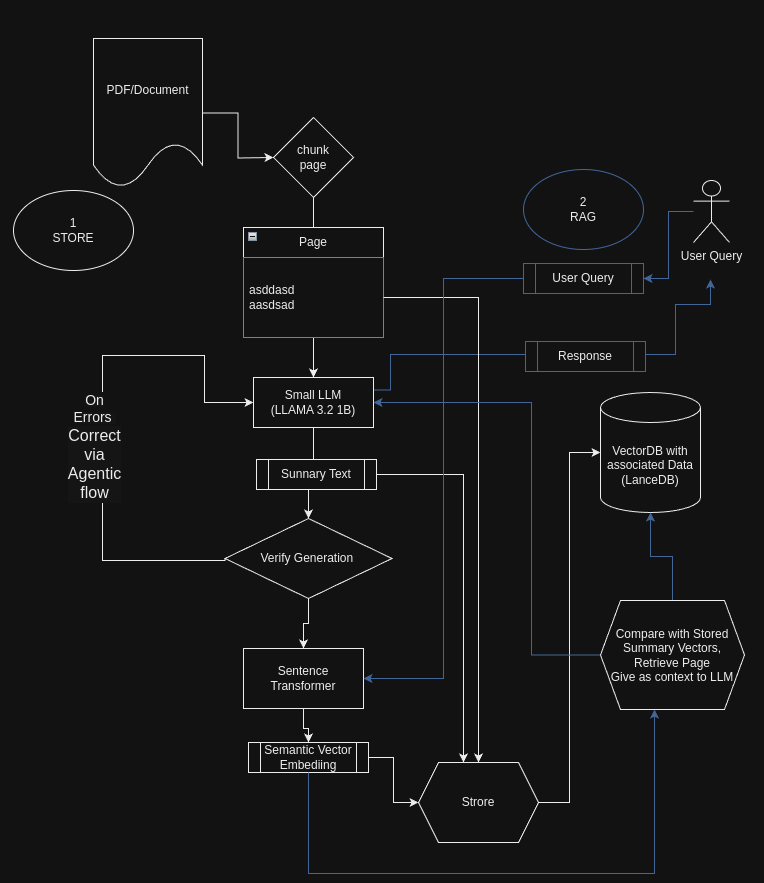
Llama-3.2–1 B-Instruct und LanceDB
Abstrakt: Retrieval-Augmented Era (RAG) kombiniert große Sprachmodelle mit externen Wissensquellen, um genauere und kontextbezogenere Antworten zu erzeugen. In diesem Artikel wird untersucht, wie kleinere Sprachmodelle (LLMs), wie das kürzlich Open-Supply-Modell Meta 1 Billion, effektiv zum Zusammenfassen und Indexieren großer Dokumente genutzt werden können, wodurch die Effizienz und Skalierbarkeit von RAG-Systemen verbessert wird. Wir bieten eine Schritt-für-Schritt-Anleitung mit Codeausschnitten, wie Sie Textabschnitte aus einer Produktdokumentations-PDF-Datei zusammenfassen und zum effizienten Abruf in einer LanceDB-Datenbank speichern.
Einführung
Retrieval-Augmented Era ist ein Paradigma, das die Fähigkeiten von Sprachmodellen durch deren Integration in externe Wissensdatenbanken erweitert. Während große LLMs wie GPT-4 bemerkenswerte Fähigkeiten bewiesen haben, sind sie mit erheblichen Rechenkosten verbunden. Kleine LLMs bieten eine ressourceneffizientere Different, insbesondere für Aufgaben wie Textzusammenfassung und Schlüsselwortextraktion, die für die Indizierung und den Abruf in RAG-Systemen von entscheidender Bedeutung sind.
In diesem Artikel zeigen wir, wie Sie mit einem kleinen LLM Folgendes erreichen:
- Extrahieren und fassen Sie Textual content aus einem PDF-Dokument zusammen.
- Generieren Sie Einbettungen für Zusammenfassungen und Schlüsselwörter.
- Speichern Sie die Daten effizient in einer LanceDB-Datenbank.
- Nutzen Sie dies für eine effektive RAG
- Außerdem ein Agenten-Workflow zur Selbstkorrektur von Fehlern aus dem LLM
Die Verwendung eines kleineren LLM reduziert die Kosten für diese Artwork von Konvertierungen bei großen Datensätzen drastisch und bietet ähnliche Vorteile für einfachere Aufgaben wie die LLMs mit größeren Parametern und kann mit minimalen Kosten problemlos im Unternehmen oder in der Cloud gehostet werden.
Wir werden verwenden Lama 3,2 1 Milliarde Parametermodell, das derzeit kleinste hochmoderne LLM.
Das Downside beim Einbetten von Rohtext
Bevor wir uns mit der Implementierung befassen, ist es wichtig zu verstehen, warum das Einbetten von Rohtext aus Dokumenten in RAG-Systemen problematisch sein kann.
Ineffektive Kontexterfassung
Das Einbetten von Rohtext von einer Seite ohne Zusammenfassung führt häufig zu folgenden Einbettungen:
- Hochdimensionales Rauschen: Rohtext kann irrelevante Informationen, Formatierungsartefakte oder Textbausteine enthalten, die nicht zum Verständnis des Kerninhalts beitragen.
- Verwässerte Schlüsselkonzepte: Wichtige Konzepte können in fremdem Textual content verborgen sein, wodurch die Einbettungen weniger repräsentativ für die kritischen Informationen sind.
Ineffizienz beim Abrufen
Wenn Einbettungen die Schlüsselkonzepte des Textes nicht genau wiedergeben, versagt das Retrieval-System möglicherweise:
- Passen Sie Benutzeranfragen effektiv an: Die Einbettungen stimmen möglicherweise nicht intestine mit den Abfrageeinbettungen überein, was zu einem schlechten Abruf relevanter Dokumente führt.
- Geben Sie den richtigen Kontext an: Selbst wenn ein Dokument abgerufen wird, bietet es aufgrund des Rauschens bei der Einbettung möglicherweise nicht die genauen Informationen, die der Benutzer sucht.
Lösung: Zusammenfassung vor dem Einbetten
Das Zusammenfassen des Textes vor dem Generieren von Einbettungen behebt diese Probleme durch:
- Wichtige Informationen destillieren: Durch die Zusammenfassung werden die wesentlichen Punkte und Schlüsselwörter extrahiert und unnötige Particulars entfernt.
- Verbesserung der Einbettungsqualität: Aus Zusammenfassungen generierte Einbettungen sind fokussierter und repräsentativer für den Hauptinhalt, wodurch die Abrufgenauigkeit verbessert wird.
Voraussetzungen
Bevor wir beginnen, stellen Sie sicher, dass Sie Folgendes installiert haben:
- Python 3.7 oder höher
- PyTorch
- Transformers-Bibliothek
- SatzTransformers
- PyMuPDF (zur PDF-Verarbeitung)
- LanceDB
- Ein Laptop computer mit mindestens 6 GB GPU oder Colab (T4-GPU reicht aus) oder ähnliches
Schritt 1: Einrichten der Umgebung
Importieren Sie zunächst alle erforderlichen Bibliotheken und richten Sie die Protokollierung zum Debuggen und Nachverfolgen ein.
import pandas as pd
import fitz # PyMuPDF
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import lancedb
from sentence_transformers import SentenceTransformer
import json
import pyarrow as pa
import numpy as np
import re
Schritt 2: Hilfsfunktionen definieren
Erstellen der Eingabeaufforderung
Wir definieren eine Funktion zum Erstellen von Eingabeaufforderungen, die mit dem LLAMA 3.2-Modell kompatibel sind.
def create_prompt(query):
"""
Create a immediate as per LLAMA 3.2 format.
"""
system_message = "You're a useful assistant for summarizing textual content and lead to JSON format"
prompt_template = f'''
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_message}<|eot_id|><|start_header_id|>person<|end_header_id|>
{query}<|eot_id|><|start_header_id|>assistant1231231222<|end_header_id|>
'''
return prompt_template
Verarbeitung der Eingabeaufforderung
Diese Funktion verarbeitet die Eingabeaufforderung mithilfe des Modells und des Tokenizers. Wir stellen die Temperatur auf 0,1 ein, um das Modell weniger kreativ (weniger halluzinierend) zu machen.
def process_prompt(immediate, mannequin, tokenizer, machine, max_length=500):
"""
Processes a immediate, generates a response, and extracts the assistant's reply.
"""
prompt_encoded = tokenizer(immediate, truncation=True, padding=False, return_tensors="pt")
mannequin.eval()
output = mannequin.generate(
input_ids=prompt_encoded.input_ids.to(machine),
max_new_tokens=max_length,
attention_mask=prompt_encoded.attention_mask.to(machine),
temperature=0.1 # Extra deterministic
)
reply = tokenizer.decode(output(0), skip_special_tokens=True)
elements = reply.break up("assistant1231231222", 1)
if len(elements) > 1:
words_after_assistant = elements(1).strip()
return words_after_assistant
else:
print("The assistant's response was not discovered.")
return "NONE"
Schritt 3: Laden des Modells
Zur Zusammenfassung verwenden wir das LLAMA 3.2 1B Instruct-Modell. Wir laden das Modell mit bfloat16, um den Speicher zu reduzieren, und führen es auf einer NVIDIA-Laptop computer-GPU (NVIDIA GeForce RTX 3060 6 GB/Treiber NVIDIA-SMI 555.58.02/Cuda-Kompilierungstools, Model 12.5, V12.5.40) unter einem Linux-Betriebssystem aus.
Besser wäre es, über vLLM oder besser zu hosten exLLamaV2
model_name_long = "meta-llama/Llama-3.2-1B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_long)
machine = torch.machine("cuda" if torch.cuda.is_available() else "cpu")
log.information(f"Loading the mannequin {model_name_long}")
bf16 = False
fp16 = True
if torch.cuda.is_available():
main, _ = torch.cuda.get_device_capability()
if main >= 8:
log.information("Your GPU helps bfloat16: speed up coaching with bf16=True")
bf16 = True
fp16 = False
# Load the mannequin
device_map = {"": 0} # Load on GPU 0
torch_dtype = torch.bfloat16 if bf16 else torch.float16
mannequin = AutoModelForCausalLM.from_pretrained(
model_name_long,
torch_dtype=torch_dtype,
device_map=device_map,
)
log.information(f"Mannequin loaded with torch_dtype={torch_dtype}")
Schritt 4: Lesen und Verarbeiten des PDF-Dokuments
Wir extrahieren Textual content aus jeder Seite des PDF-Dokuments.
file_path = './knowledge/troubleshooting.pdf'
dict_pages = {}
# Open the PDF file
with fitz.open(file_path) as pdf_document:
for page_number in vary(pdf_document.page_count):
web page = pdf_document.load_page(page_number)
page_text = web page.get_text()
dict_pages(page_number) = page_text
print(f"Processed PDF web page {page_number + 1}")
Schritt 5: Einrichten von LanceDB und SentenceTransformer
Wir initialisieren das SentenceTransformer-Modell zum Generieren von Einbettungen und richten LanceDB zum Speichern der Daten ein. Wir verwenden ein PyArrow-basiertes Schema für die LanceDB-Tabellen
Beachten Sie, dass Schlüsselwörter derzeit nicht verwendet werden, aber für die Hybridsuche verwendet werden können, d. h. für die Suche nach Vektorähnlichkeit sowie bei Bedarf auch für die Textsuche.
# Initialize the SentenceTransformer mannequin
sentence_model = SentenceTransformer('all-MiniLM-L6-v2')
# Connect with LanceDB
db = lancedb.join('./knowledge/my_lancedb')
# Outline the schema utilizing PyArrow
schema = pa.schema((
pa.discipline("page_number", pa.int64()),
pa.discipline("original_content", pa.string()),
pa.discipline("abstract", pa.string()),
pa.discipline("key phrases", pa.string()),
pa.discipline("vectorS", pa.list_(pa.float32(), 384)), # Embedding dimension of 384
pa.discipline("vectorK", pa.list_(pa.float32(), 384)),
))
# Create or connect with a desk
desk = db.create_table('summaries', schema=schema, mode='overwrite')
Schritt 6: Daten zusammenfassen und speichern
Wir durchlaufen jede Seite, generieren eine Zusammenfassung und Schlüsselwörter und speichern sie zusammen mit Einbettungen in der Datenbank.
# Loop by way of every web page within the PDF
for page_number, textual content in dict_pages.gadgets():
query = f"""For the given passage, present an extended abstract about it, incorporating all the principle key phrases within the passage.
Format must be in JSON format like under:
{{
"abstract": <textual content abstract>,
"key phrases": <a comma-separated record of major key phrases and acronyms that seem within the passage>,
}}
Be sure that JSON fields have double quotes and use the proper closing delimiters.
Passage: {textual content}"""
immediate = create_prompt(query)
response = process_prompt(immediate, mannequin, tokenizer, machine)
# Error dealing with for JSON decoding
attempt:
summary_json = json.masses(response)
besides json.decoder.JSONDecodeError as e:
exception_msg = str(e)
query = f"""Right the next JSON {response} which has {exception_msg} to correct JSON format. Output solely JSON."""
log.warning(f"{exception_msg} for {response}")
immediate = create_prompt(query)
response = process_prompt(immediate, mannequin, tokenizer, machine)
log.warning(f"Corrected '{response}'")
attempt:
summary_json = json.masses(response)
besides Exception as e:
log.error(f"Did not parse JSON: '{e}' for '{response}'")
proceed
key phrases = ', '.be a part of(summary_json('key phrases'))
# Generate embeddings
vectorS = sentence_model.encode(summary_json('abstract'))
vectorK = sentence_model.encode(key phrases)
# Retailer the info in LanceDB
desk.add(({
"page_number": int(page_number),
"original_content": textual content,
"abstract": summary_json('abstract'),
"key phrases": key phrases,
"vectorS": vectorS,
"vectorK": vectorK
}))
print(f"Knowledge for web page {page_number} saved efficiently.")
Verwendung von LLMs zur Korrektur ihrer Ausgaben
Beim Generieren von Zusammenfassungen und Extrahieren von Schlüsselwörtern können LLMs manchmal Ausgaben erzeugen, die nicht im erwarteten Format vorliegen, z. B. fehlerhaftes JSON.
Wir können das LLM selbst nutzen, um diese Ausgaben zu korrigieren, indem wir es auffordern, die Fehler zu beheben. Dies wird im obigen Code gezeigt
# Use the Small LLAMA 3.2 1B mannequin to create abstract
for page_number, textual content in dict_pages.gadgets():
query = f"""For the given passage, present an extended abstract about it, incorporating all the principle key phrases within the passage.
Format must be in JSON format like under:
{{
"abstract": <textual content abstract> instance "Some Abstract textual content",
"key phrases": <a comma separated record of major key phrases and acronyms that seem within the passage> instance ("keyword1","keyword2"),
}}
Be sure that JSON fields have double quotes, e.g., as an alternative of 'abstract' use "abstract", and use the closing and ending delimiters.
Passage: {textual content}"""
immediate = create_prompt(query)
response = process_prompt(immediate, mannequin, tokenizer, machine)
attempt:
summary_json = json.masses(response)
besides json.decoder.JSONDecodeError as e:
exception_msg = str(e)
# Use the LLM to appropriate its personal output
query = f"""Right the next JSON {response} which has {exception_msg} to correct JSON format. Output solely the corrected JSON.
Format must be in JSON format like under:
{{
"abstract": <textual content abstract> instance "Some Abstract textual content",
"key phrases": <a comma separated record of key phrases and acronyms that seem within the passage> instance ("keyword1","keyword2"),
}}"""
log.warning(f"{exception_msg} for {response}")
immediate = create_prompt(query)
response = process_prompt(immediate, mannequin, tokenizer, machine)
log.warning(f"Corrected '{response}'")
# Attempt parsing the corrected JSON
attempt:
summary_json = json.masses(response)
besides json.decoder.JSONDecodeError as e:
log.error(f"Did not parse corrected JSON: '{e}' for '{response}'")
proceed
Wenn in diesem Codeausschnitt die anfängliche Ausgabe des LLM nicht als JSON geparst werden kann, fordern wir den LLM erneut auf, den JSON zu korrigieren. Dieses Selbstkorrekturmuster verbessert die Robustheit unserer Pipeline.
Angenommen, das LLM generiert das folgende fehlerhafte JSON:
{
'abstract': 'This web page explains the set up steps for the product.',
'key phrases': ('set up', 'setup', 'product')
}
Der Versuch, diesen JSON-Code zu analysieren, führt aufgrund der Verwendung von einfachen Anführungszeichen anstelle von doppelten Anführungszeichen zu einem Fehler. Wir erkennen diesen Fehler und fordern das LLM auf, ihn zu korrigieren:
exception_msg = "Anticipating property identify enclosed in double quotes"
query = f"""Right the next JSON {response} which has {exception_msg} to correct JSON format. Output solely the corrected JSON."""
Das LLM stellt dann den korrigierten JSON bereit:
{
"abstract": "This web page explains the set up steps for the product.",
"key phrases": ("set up", "setup", "product")
}
Durch die Verwendung des LLM zur Korrektur der eigenen Ausgabe stellen wir sicher, dass die Daten im richtigen Format für die Weiterverarbeitung vorliegen.
Erweiterung der Selbstkorrektur durch LLM-Agenten
Dieses Muster der Verwendung des LLM zur Korrektur seiner Ausgaben kann durch die Verwendung von erweitert und automatisiert werden LLM-Agenten. LLM-Agenten können:
- Automatisieren Sie die Fehlerbehandlung: Fehler erkennen und ohne explizite Anweisungen autonom entscheiden, wie diese behoben werden.
- Effizienz verbessern: Reduzieren Sie den Bedarf an manuellen Eingriffen oder zusätzlichem Code zur Fehlerkorrektur.
- Verbessern Sie die Robustheit: Kontinuierlich aus Fehlern lernen, um zukünftige Ergebnisse zu verbessern.
LLM-Agenten fungieren als Vermittler, die den Informationsfluss verwalten und Ausnahmen clever behandeln. Sie können so gestaltet werden, dass sie:
- Analysieren Sie Ausgaben und validieren Sie Formate.
- Fordern Sie das LLM erneut mit verfeinerten Anweisungen auf, wenn Fehler auftreten.
- Protokollieren Sie Fehler und Korrekturen zur späteren Referenz und Feinabstimmung des Modells.
Ungefähre Umsetzung:
Anstatt Ausnahmen manuell abzufangen und erneut aufzufordern, könnte ein LLM-Agent diese Logik kapseln:
def generate_summary_with_agent(textual content):
agent = LLMAgent(mannequin, tokenizer, machine)
query = f"""For the given passage, present a abstract and key phrases in correct JSON format."""
immediate = create_prompt(query)
response = agent.process_and_correct(immediate)
return response
Die LLMAgent-Klasse würde die anfängliche Verarbeitung, Fehlererkennung, erneute Eingabeaufforderung und Korrektur intern übernehmen.
Sehen wir uns nun an, wie wir die Einbettungen erneut für ein effektives RAG-Muster verwenden können, indem wir das LLM als Hilfe beim Rating verwenden.
Abruf und Generierung: Verarbeitung der Benutzerabfrage
Dies ist der übliche Ablauf. Wir nehmen die Frage des Benutzers auf und suchen nach den relevantesten Zusammenfassungen.
# Instance utilization
user_question = "Not in a position to handle new units"
outcomes = search_summary(user_question, sentence_model)
Vorbereiten der abgerufenen Zusammenfassungen
Wir stellen die abgerufenen Zusammenfassungen in einer Liste zusammen und verknüpfen jede Zusammenfassung mit ihrer Seitenzahl als Referenz.
summary_list = ()
for idx, lead to enumerate(outcomes):
summary_list.append(f"{end result('page_number')}# {end result('abstract')}")
Rangfolge der Zusammenfassungen
Wir veranlassen das Sprachmodell, die abgerufenen Zusammenfassungen nach ihrer Relevanz für die Frage des Benutzers zu ordnen und die relevanteste auszuwählen. Dabei wird für die kontextbezogene Einbettungsübereinstimmung (Vektorübereinstimmung) wiederum das LLM bei der Rangfolge der Zusammenfassungen anstelle der Ok-Nearest Neighbor- oder Cosinus-Distanz oder anderer Rangfolgealgorithmen allein verwendet.
query = f"""From the given record of summaries {summary_list}, rank which abstract may have
the reply to the query '{user_question}'. Return solely that abstract from the record."""
log.information(query)
Extrahieren der ausgewählten Zusammenfassung und Generieren der endgültigen Antwort
Wir rufen den Originalinhalt ab, der mit der ausgewählten Zusammenfassung verknüpft ist, und veranlassen das Sprachmodell, unter Verwendung dieses Kontexts eine detaillierte Antwort auf die Frage des Benutzers zu generieren.
for idx, lead to enumerate(outcomes):
if int(page_number) == end result('page_number'):
web page = end result('original_content')
query = f"""Are you able to reply the question: '{user_question}'
utilizing the context under?
Context: '{web page}'
"""
log.information(query)
immediate = create_prompt(
query,
"You're a useful assistant that can undergo the given question and context, assume in steps, after which attempt to reply the question
with the knowledge within the context."
)
response = process_prompt(immediate, mannequin, tokenizer, machine, temperature=0.01) # Much less freedom to hallucinate
log.information(response)
print("Closing Reply:")
print(response)
break
Erläuterung des Workflows
- Vektorisierung von Benutzerabfragen: Die Frage des Benutzers wird mithilfe desselben SentenceTransformer-Modells, das bei der Indizierung verwendet wurde, in eine Einbettung umgewandelt.
- Ähnlichkeitssuche: Die Abfrageeinbettung wird verwendet, um die Vektordatenbank (LanceDB) nach den ähnlichsten Zusammenfassungen zu durchsuchen und High 3 zurückzugeben
>> From the VectorDB Cosine search and High 3 nearest neighbour search end result,
prepended by linked web page numbers
07:04:00 INFO:From the given record of abstract ((
'112# Can't place newly found machine in managed state',
'113# The passage discusses the troubleshooting steps for managing newly found units on the NSF platform, particularly addressing points with machine placement, configuration, and deployment.',
'116# Troubleshooting Machine Configuration Backup Challenge')) rank which abstract may have the potential reply to the query Not in a position to handle new units. Return solely that abstract from the record
3. Zusammenfassendes Rating: Die abgerufenen Zusammenfassungen werden an das Sprachmodell übergeben, das sie basierend auf ihrer Relevanz für die Frage des Benutzers einordnet.
>> Asking LLM to Choose from the High N primarily based on context
07:04:01 INFO:Chosen Abstract ''113# The passage discusses the troubleshooting steps for managing newly found units on the NSF (Community Techniques and Useful Necessities) platform, particularly addressing points with machine placement, configuration, and deployment.''
4. Kontextabruf: Der mit der relevantesten Zusammenfassung verknüpfte Originalinhalt wird durch Parsen der Seitenzahl und Abrufen der zugehörigen Seite aus der LanceDB abgerufen
07:04:01 INFO:Web page quantity: 113
07:04:01 INFO:Are you able to reply the query or question or present extra deatils question:'Not in a position to handle new units' Utilizing the context under
context:'3
Test that the server and consumer platforms are appropriately sized. ...
Failed SNMP communication between the server and managed machine.
SNMP traps from managed units are arriving at one server,
or no SNMP traps are ....
'
5. Antwortgenerierung: Das Sprachmodell generiert anhand des abgerufenen Kontexts eine detaillierte Antwort auf die Frage des Benutzers.
Hier ist eine Beispielausgabe aus einem Beispiel-PDF, das ich verwendet habe
07:04:08 INFO:I'll undergo the steps and supply extra particulars to reply the question.
The question is: "Not in a position to handle new units"
Right here's my step-by-step evaluation:
**Step 1: Test that the server and consumer platforms are appropriately sized**
The context mentions that the NSP Planning Information is accessible, which means that the NSP (Community Service Supplier) has a planning course of to make sure that the server and consumer platforms are sized accurately. This means that the NSP has a course of in place to judge the efficiency and capability of the server and consumer platforms to find out if they're appropriate for managing new units.
**Step 2: Test for resynchronization issues between the managed community and the NFM-P**
The context additionally mentions that resynchronization issues between the managed community and the NFM-P could cause points with managing new units. This means that there could also be an issue with the communication between the server and consumer platforms, which might stop new units from being efficiently managed.
**Step 3: Test for failed SNMP communication between the server and managed machine**
The context particularly mentions that failed SNMP communication between the server and managed machine could cause points with managing new units. This means that there could also be an issue with the communication between the server and the managed machine, which might stop new units from being efficiently managed.
**Step 4: Test for failed deployment of the configuration request**
The context additionally mentions that failed deployment of the configuration request could cause points with managing new units. This means that there could also be an issue with the deployment course of, which might stop new units from being efficiently managed.
**Step 5: Carry out the next steps**
The context instructs the person to carry out the next steps:
1. Select Administration→NE Upkeep→Deployment from the XXX major menu.
2. The Deployment type opens, itemizing incomplete deployments, deployer, tag, state, and different info.
Primarily based on the context, it seems that the person must evaluate the deployment historical past to determine any points that could be stopping the deployment of latest units.
**Reply**
Primarily based on the evaluation, the person must:
1. Test that the server and consumer platforms are appropriately sized.
2. Test for resynchronization issues between the managed community and the NFM-P.
3. Test for failed SNMP communication between the server and managed machine.
4. Test for failed deployment of the configuration request.
By following these steps, the person ought to be capable to determine and resolve the problems stopping the administration of
Abschluss
Mit einem kleinen LLM wie LLAMA 3.2 1B Instruct können wir Schlüsselwörter aus großen Dokumenten effizient zusammenfassen und extrahieren. Diese Zusammenfassungen und Schlüsselwörter können in eine Datenbank wie LanceDB eingebettet und gespeichert werden, was einen effizienten Abruf für RAG-Systeme ermöglicht, die das LLM im Workflow und nicht nur bei der Generierung verwenden
Referenzen
- Meta LLAMA 3.2 1B Instruct-Modell
- SatzTransformers
- LanceDB
- PyMuPDF-Dokumentation
Nutzung kleinerer LLMs für Enhanced Retrieval-Augmented Era (RAG) wurde ursprünglich veröffentlicht in Auf dem Weg zur Datenwissenschaft auf Medium, wo die Leute das Gespräch fortsetzen, indem sie diese Geschichte hervorheben und darauf reagieren.