Popularität von Lappen
In den letzten zwei Jahren habe ich während der Zusammenarbeit mit Finanzunternehmen aus erster Hand beobachtet, wie sie generative KI -Anwendungsfälle identifizieren und priorisiert haben, was die Komplexität mit potenziellem Wert in Einklang bringt.
Wiederholungsgeneration . Durch Kombination a Retriever dass relevante Dokumente mit einem überfliegen Llm Das synthetisiert Antworten, Lappen Stromlinienzugrifffür Anwendungen wie Kundenunterstützung, Forschung und internes Wissensmanagement von unschätzbarem Wert.
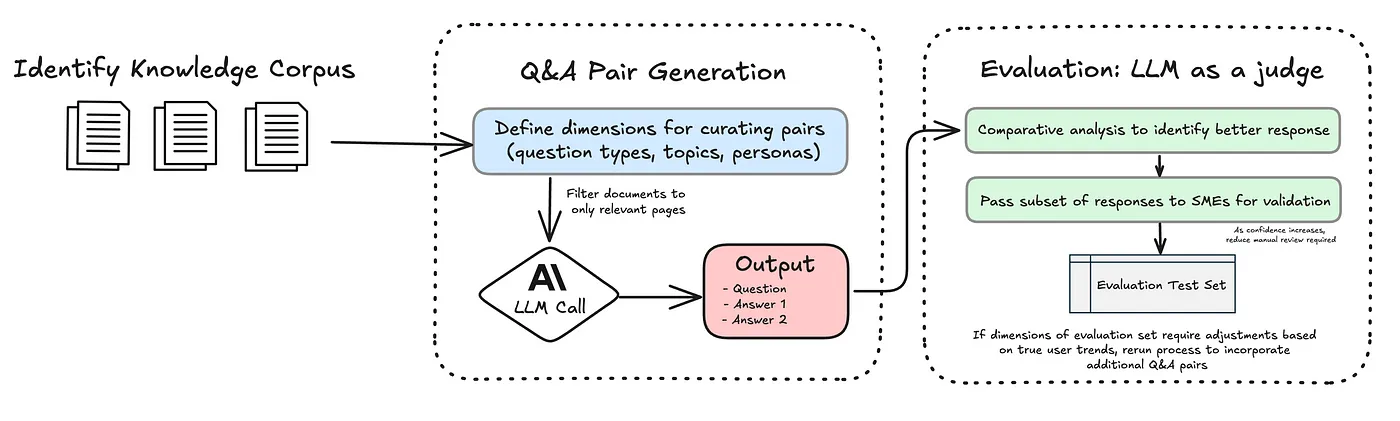
Das Definieren klarer Bewertungskriterien ist der Schlüssel zur Sicherstellung von LLM-Lösungen, die die Leistungsstandards entsprechen, genau wie die testgetriebene Entwicklung (TDD) die Zuverlässigkeit in der herkömmlichen Software program gewährleistet. Aus Zeichnen von TDD-Prinzipien setzt ein bewertungsgetriebener Ansatz messbare Benchmarks fest, um KI-Workflows zu validieren und zu verbessern. Dies wird besonders wichtig für LLMs, wo die Komplexität der offenen Antworten eine konsistente und nachdenkliche Bewertung erfordert, um zuverlässige Ergebnisse zu liefern.
Bei LABE-Anwendungen enthält ein typischer Bewertungssatz repräsentative Eingangsput-Paare, die mit dem beabsichtigten Anwendungsfall übereinstimmen. In Chatbot -Anwendungen kann dies beispielsweise Q & A -Paare umfassen, die Benutzeranfragen widerspiegeln. In anderen Kontexten wie Abrufen und Zusammenfassen des relevanten Textes könnte der Bewertungssatz Quellendokumente sowie erwartete Zusammenfassungen oder extrahierte Schlüsselpunkte enthalten. Diese Paare werden häufig aus einer Untergruppe von Dokumenten erzeugt, wie sie am meisten betrachtet oder häufig zugegriffen werden, um sicherzustellen, dass sich die Bewertung auf den relevantesten Inhalt konzentriert.
Wichtige Herausforderungen
Das Erstellen von Bewertungsdatensätzen für RAG -Systeme hat traditionell zwei großen Herausforderungen gestellt.
- Der Prozess stützte sich häufig auf Experten (KMU), um Dokumente manuell zu überprüfen und Q & A -Paare zu generieren, um es zu erstellen zeitintensiv, inkonsistent und kostspielig.
- Einschränkungen, die verhindern, dass LLMs visuelle Elemente in Dokumenten wie Tabellen oder Diagramme verarbeiten, da sie auf den Umgang mit Textual content beschränkt sind. Commonplace -OCR -Werkzeuge haben Schwierigkeiten, diese Lücke zu schließenoft nicht, aussagekräftige Informationen aus nicht-textuellen Inhalten zu extrahieren.
Multimodale Funktionen
Die Herausforderungen des Umgangs mit komplexen Dokumenten haben sich durch die Einführung multimodaler Fähigkeiten in Fundamentmodellen entwickelt. Kommerzielle und Open-Supply-Modelle können jetzt Verarbeiten Sie sowohl Textual content als auch visuelle Inhalte. Diese Visionsfähigkeit beseitigt die Notwendigkeit separater Textual content-Extraktions-Workflows und bietet einen integrierten Ansatz für die Behandlung von PDFs mit gemischter Medien.
Durch die Nutzung dieser Sichtmerkmale, Modelle können ganze Seiten gleichzeitig aufnehmen und Layoutstrukturen, Diagrammbezeichnungen und Tabelleninhalte erkennen. Dies reduziert nicht nur die manuelle Anstrengung, sondern verbessert auch die Skalierbarkeit und Datenqualität, was es zu einem leistungsstarken Ermöglichung für Lag -Workflows macht, die auf genaue Informationen aus einer Vielzahl von Quellen beruhen.
Datensatzkuration für Vermögensverwaltungsforschungsbericht
Um eine Lösung für das Downside der manuellen Bewertungssatzgenerierung zu demonstrieren, habe ich meinen Ansatz mit einem Beispieldokument getestet – dem 2023 Cerulli -Bericht. Diese Artwork von Dokument ist typisch für das Vermögensverwaltung, bei dem Berichte im Analystenstil häufig Textual content mit komplexen Visuals kombinieren. Für einen Suchassistenten mit Lappen würde ein solcher Wissenskorpus wahrscheinlich viele solcher Dokumente enthalten.
Mein Ziel battle es zu Zeigen Sie, wie ein einzelnes Dokument genutzt werden kann, um Q & A -Paare zu generieren, wobei sowohl Textual content- als auch visuelle Elemente einbezogen werden können. Obwohl ich in diesem Check keine spezifischen Dimensionen für die Q & A-Paare definiert habe, würde eine reale Implementierung die Bereitstellung von Particulars zu Arten von Fragen (Vergleiche, Analyse, A number of-Selection), Themen (Anlagestrategien, Kontotypen) und viele andere umfassen Aspekte. Der Hauptaugenmerk dieses Experiments lag darauf, sicherzustellen, dass die LLM Fragen erzeugten, die visuelle Elemente beinhalteten und zuverlässige Antworten verursachten.

Mein im Diagramm illustriertes Workflow nutzt das Claude Sonnet 3.5 -Modell von Anthropic, das den Prozess der Arbeit mit PDFs vereinfacht, indem die Umwandlung von Dokumenten in Bilder behandelt wird, bevor sie an das Modell weitergegeben werden. Das Die integrierte Funktionalität beseitigt die Notwendigkeit zusätzlicher Abhängigkeiten von Drittanbietern, optimiert den Workflow und die Reduzierung der Codekomplexität.
Ich habe vorläufige Seiten des Berichts wie das Inhaltsverzeichnis und das Glossar ausgeschlossen, wobei ich mich auf Seiten mit relevanten Inhalten und Diagrammen für die Generierung von Q & A -Paaren konzentrierte. Im Folgenden finden Sie die Eingabeaufforderung, mit der ich die anfänglichen Frage-Antworten-Units generiert habe.
You're an knowledgeable at analyzing monetary stories and producing question-answer pairs. For the supplied PDF, the 2023 Cerulli report:1. Analyze pages {start_idx} to {end_idx} and for **every** of these 10 pages:
- Determine the **actual web page title** because it seems on that web page (e.g., "Exhibit 4.03 Core Market Databank, 2023").
- If the web page features a chart, graph, or diagram, create a query that references that visible component. In any other case, create a query in regards to the textual content material.
- Generate two distinct solutions to that query ("answer_1" and "answer_2"), each supported by the web page’s content material.
- Determine the proper web page quantity as indicated within the backside left nook of the web page.
2. Return precisely 10 outcomes as a legitimate JSON array (an inventory of dictionaries). Every dictionary ought to have the keys: “web page” (int), “page_title” (str), “query” (str), “answer_1” (str), and “answer_2” (str). The web page title usually consists of the phrase "Exhibit" adopted by a quantity.
Q & A -Paar -Technology
Um den Q & A -Generationsprozess zu verfeinern, habe ich a implementiert Vergleichender Lernansatz Das erzeugt zwei unterschiedliche Antworten für jede Frage. Während der Bewertungsphase werden diese Antworten in den wichtigsten Dimensionen wie Genauigkeit und Klarheit bewertet, wobei die stärkere Antwort als endgültige Antwort ausgewählt wird.
Dieser Ansatz spiegelt wider, wie Menschen es oft einfacher finden, Entscheidungen beim Vergleich von Alternativen zu treffen, anstatt etwas isoliert zu bewerten. Es ist wie eine Augenuntersuchung: Der Optiker fragt nicht, ob sich Ihr Sehvermögen verbessert oder abgelehnt hat, sondern stellt zwei Objektive und fragt, was klarer ist, Possibility 1 oder Possibility 2? Dieser Vergleichsprozess eliminiert die Mehrdeutigkeit der Beurteilung der absoluten Verbesserung und konzentriert sich auf relative Unterschiededie Wahl einfacher und umsetzbarer machen. In ähnlicher Weise kann das System durch die Präsentation von zwei konkreten Antwortoptionen effektiver bewerten, welche Reaktion stärker ist.
Diese Methodik wird auch als bewährte Verfahren im Artikel angeführt „Was wir aus einem Jahr des Gebäudes mit LLMs gelernt haben“ von Führungskräften im KI -Raum. Sie unterstreichen den Wert paarweise Vergleiche und geben an: “Anstatt die LLM zu bitten, eine einzelne Ausgabe auf einer Likert -Skala zu erzielen, präsentieren Sie sie mit zwei Optionen und bitten Sie sie, das bessere auszuwählen. Dies führt tendenziell zu stabileren Ergebnissen. ““ Ich empfehle dringend, ihre dreiteilige Serie zu lesen, da sie unschätzbare Einblicke in den Aufbau effektiver Systeme mit LLMs bietet!
LLM -Bewertung
Zur Bewertung der generierten Q & A -Paare habe ich Claude Opus für seine fortschrittlichen Argumentationsfunktionen verwendet. Als „Richter“ fungieren, Die LLM verglichen die beiden Antworten, die für jede Frage generiert wurden, und wählte die bessere Possibility basierend auf Kriterien wie Direktheit und Klarheit aus. Dieser Ansatz wird durch umfangreiche Forschungen (Zheng et al., 2023) unterstützt, die zeigt, dass LLMs Bewertungen mit menschlichen Rezensenten gleichzeitig durchführen können.
Dieser Ansatz reduziert die von KMU erforderliche manuelle Überprüfung erheblichErmöglichen Sie einen skalierbaren und effizienteren Verfeinerungsprozess. Während KMU in den Anfangsphasen von wesentlicher Bedeutung sind, um Fragen zu überprüfen und Systemausgänge zu validieren, verringert diese Abhängigkeit im Laufe der Zeit. Sobald ein ausreichendes Maß an Vertrauen in die Leistung des Methods festgelegt ist, wird die Notwendigkeit einer häufigen Überprüfung des Spot-Überprüfung verringert, sodass KMU sich auf höherwertige Aufgaben konzentrieren kann.
Lektionen gelernt
Die PDF-Fähigkeit von Claude hat eine Restrict von 100 Seiten, daher habe ich das Originaldokument in vier 50-seitige Abschnitte unterteilt. Als ich versuchte, jeden 50-seitigen Abschnitt in einer einzigen Anfrage zu verarbeiten-und das Modell ausdrücklich angewiesen, ein Q & A-Paar professional Seite zu generieren-hat es immer noch einige Seiten verpasst. Die Token -Grenze battle nicht das eigentliche Downside; Das Modell konzentrierte sich tendenziell auf den Inhalt, den es als am relevantes als am Related angesehen hat, und ließ bestimmte Seiten unterrepräsentiert.
Um dies anzugehen, habe ich mit der Verarbeitung des Dokuments in kleineren Chargen experimentiert und jeweils 5, 10 und 20 Seiten getestet. In diesen Exams stellte ich fest, dass Stapel von 10 Seiten (z. B. die Seiten 1–10, 11–20 usw.) das beste Gleichgewicht zwischen Präzision und Effizienz darstellte. Die Verarbeitung von 10 Seiten professional Cost sorgte für konsistente Ergebnisse auf allen Seiten und optimierte die Leistung.
Eine weitere Herausforderung bestand darin, Q & A -Pairs mit ihrer Quelle zurückzuversetzen. Die Verwendung von winzigen Seitenzahlen in der PDF -Fußzeile allein funktionierte nicht konsequent. Im Gegensatz dazu dienten Seitentitel oder klare Überschriften oben auf jeder Seite als zuverlässige Anker. Sie waren leichter für das Modell, um sie abzuholen, und halfen mir, jedes Q & A -Paar genau auf den rechten Abschnitt zu kartieren.
Beispielausgabe
Unten finden Sie eine Beispielseite aus dem Bericht mit zwei Tabellen mit numerischen Daten. Für diese Seite wurde die folgende Frage erstellt:
Wie hat sich die Verteilung von AUM in hybriden RIA-Unternehmen in verschiedenen Größe verändert?

Antwort: Midgröße Unternehmen (25 Mio. USD bis <$ 100 Mio.) verzeichneten einen Rückgang des AUM-Anteils von 2,3% auf 1,0%.
In der ersten Tabelle zeigt die Spalte 2017 einen 2,3% igen AUM-Anteil für mittelgroße Unternehmen, was 2022 auf 1,0% abnimmt und damit die Fähigkeit des LLM, visuellen und tabellarischen Inhalte genau zu synthetisieren, genau zeigt.
Vorteile
Die Kombination von Caching, Cost und einem raffinierten Q & A -Workflow führte zu drei wichtigen Vorteilen:
Ausschnitt
- In meinem Experiment hätte die Bearbeitung eines einzigartigen Berichts ohne Caching 9 US -Greenback gekostet, aber durch die Nutzung des Caching habe ich diese Kosten auf 3 US -Greenback gesenkt – a 3x Kosteneinsparungen. Das Preismodell von Anthropics kostet ein Cache 3,75 USD / Millionen -Token. Die Lesungen aus dem Cache beträgt jedoch nur 0,30 USD / Millionen -Token. Im Gegensatz dazu kosten Enter -Token 3 US -Greenback professional Mio. USD professional Token, wenn keine Zwischenspeicherung verwendet wird.
- In einem realen Szenario mit mehr als einem Dokument werden die Ersparnisse noch bedeutender. Beispielsweise würde die Bearbeitung von 10.000 Forschungsberichten mit ähnlicher Länge ohne Zwischenspeicherung allein 90.000 US -Greenback an Inputkosten kosten. Mit dem Caching sinkt diese Kosten auf 30.000 US 60.000 US -Greenback.
Ermäßigte Stapelverarbeitung
- Die Verwendung von Anthropics Chargen -API senkt die Ausgangskosten in zwei Hälften, wodurch es für bestimmte Aufgaben eine viel billigere Possibility ist. Nachdem ich die Eingabeaufforderungen validiert hatte, leitete ich einen einzelnen Stapeljob, um alle Fragen und Antworten gleichzeitig zu bewerten. Diese Methode erwies sich als weitaus kostengünstiger als die Verarbeitung jedes Q & A-Paares einzeln.
- Zum Beispiel kostet Claude 3 Opus in der Regel 15 USD professional Million Output -Token. Durch die Verwendung von Batching fällt dies auf 7,50 USD professional Million Token – eine Reduzierung von 50%. In meinem Experiment erzeugte jedes Q & A -Paar durchschnittlich 100 Token, was zu ungefähr 20.000 Ausgangs -Token für das Dokument führte. Zum Standardsatz hätte dies 0,30 US -Greenback gekostet. Bei der Batch-Verarbeitung wurden die Kosten auf 0,15 USD gesenkt, wobei der Ansatz die Kosten für nicht-sequenzielle Aufgaben wie die Bewertung optimiert.
Zeit gespeichert für KMU
- Mit genaueren, kontextreichen Q & A-Paaren verbrachten Experten, die sich weniger Zeit mit PDFs durchseiten und Particulars klären, und sich mehr Zeit auf strategische Erkenntnisse konzentrieren. Dieser Ansatz beseitigt auch die Notwendigkeit, zusätzliche Mitarbeiter einzustellen oder interne Ressourcen für manuell kuratierende Datensätze zuzuweisen, ein Prozess, der zeitaufwändig und teuer sein kann. Durch die Automatisierung dieser Aufgaben sparen Unternehmen erheblich bei den Arbeitskosten, während die KMU-Workflows optimiert werden, wodurch dies zu einer skalierbaren und kostengünstigen Lösung wird.