
In der aktuellen Laptop-Imaginative and prescient-Landschaft umfasst die Standardarbeitsanweisung einen modularen „Lego-Baustein“-Ansatz: einen vorab trainierten Imaginative and prescient-Encoder für die Merkmalsextraktion gepaart mit einem separaten Decoder für die Aufgabenvorhersage. Diese architektonische Trennung ist zwar effektiv, erschwert jedoch die Skalierung und behindert die Interaktion zwischen Sprache und Imaginative and prescient.
Der Institut für Technologieinnovation (TII) Das Forschungsteam stellt dieses Paradigma in Frage Falkenwahrnehmungein 600M-Parameter-Unified-Dense-Transformer. Durch die Verarbeitung von Bild-Patches und Textual content-Tokens in einem gemeinsamen Parameterraum von der ersten Ebene an hat das TII-Forschungsteam eine entwickelt frühe Fusion Stack, der Wahrnehmung und Aufgabenmodellierung mit äußerster Effizienz handhabt.
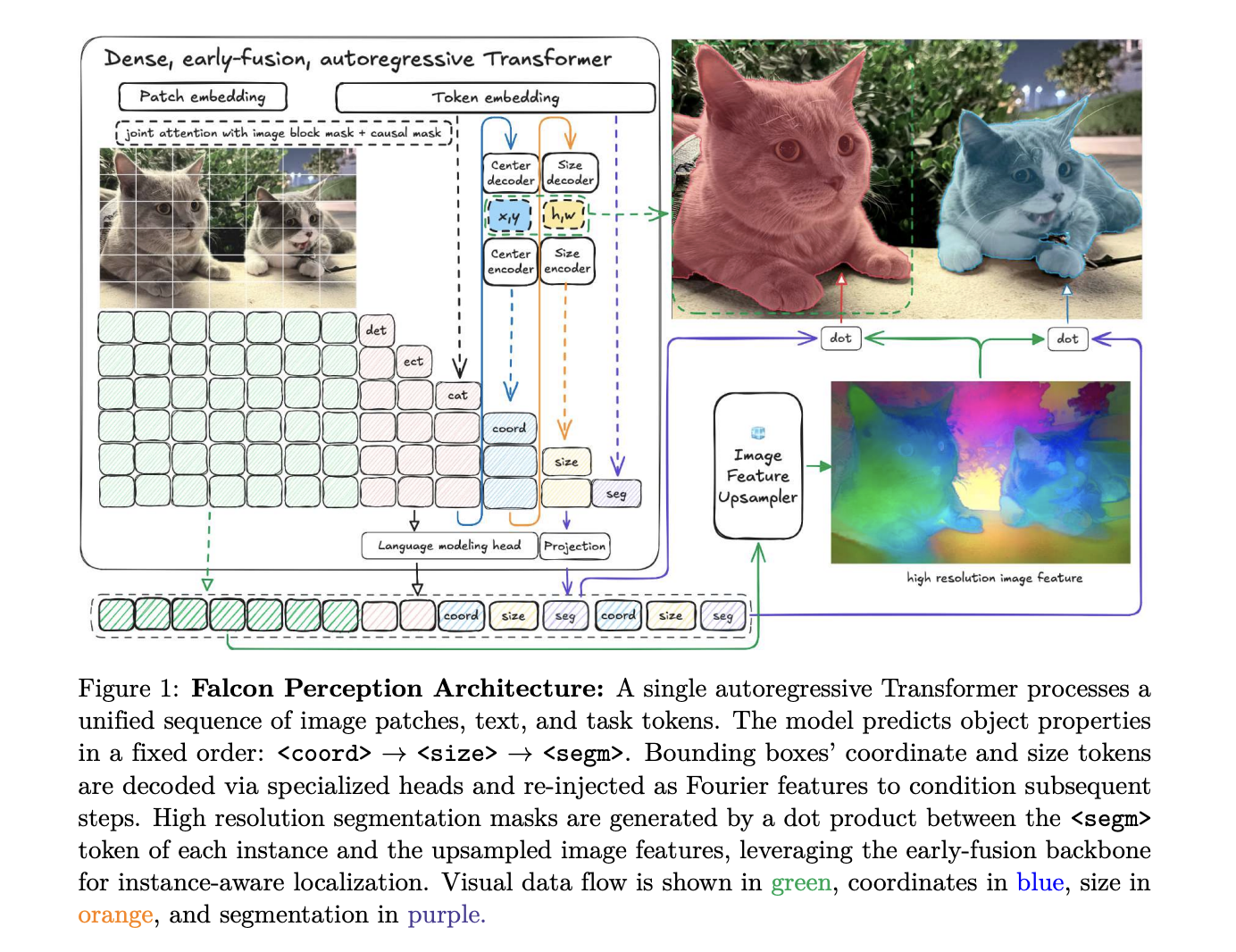
Die Architektur: Ein einzelner Stack für jede Modalität
Das Kerndesign von Falcon Notion basiert auf der Hypothese, dass ein einzelner Transformer gleichzeitig visuelle Darstellungen lernen und eine aufgabenspezifische Generierung durchführen kann.
Hybride Aufmerksamkeit und GGROPE
Im Gegensatz zu Normal-Sprachmodellen, die eine strikte kausale Maskierung verwenden, verwendet Falcon Notion eine Hybride Aufmerksamkeitsstrategie. Bild-Token kümmern sich bidirektional umeinander, um einen globalen visuellen Kontext aufzubauen, während Textual content- und Aufgaben-Token sich um alle vorhergehenden Token kümmern (kausale Maskierung), um eine autoregressive Vorhersage zu ermöglichen.
Um zweidimensionale räumliche Beziehungen in einer abgeflachten Reihenfolge aufrechtzuerhalten, verwendet das Forschungsteam 3D-Rotationspositionseinbettungen. Dadurch wird die Kopfdimension in eine sequentielle Komponente und eine räumliche Komponente zerlegt Golden Gate SEIL (GGROPE). Mit GGROPE können Aufmerksamkeitsköpfe auf relative Positionen entlang beliebiger Winkel achten, wodurch das Modell sturdy gegenüber Rotations- und Seitenverhältnisschwankungen wird.
Minimalistische Sequenzlogik
Die grundlegende architektonische Abfolge folgt a Wahrnehmungskette Format:
(Picture) (Textual content) <coord> <dimension> <seg> ... <eos>.
Dadurch wird sichergestellt, dass das Modell räumliche Mehrdeutigkeiten (Place und Größe) als Konditionierungssignal auflöst, bevor die endgültige Segmentierungsmaske generiert wird.
Engineering for Scale: Myon, FlexAttention und Raster Ordering
Das TII-Forschungsteam führte mehrere Optimierungen ein, um das Coaching zu stabilisieren und die GPU-Auslastung für diese heterogenen Sequenzen zu maximieren.
- Myonenoptimierung: Das Forschungsteam berichtet, dass der Einsatz von Myonen-Optimierer für spezialisierte Köpfe (Koordinaten, Größe und Segmentierung) führte zu geringeren Trainingsverlusten und einer verbesserten Leistung bei Benchmarks im Vergleich zum Normal-AdamW.
- FlexAttention und Sequence Packing: Um Bilder mit nativen Auflösungen zu verarbeiten, ohne Rechenleistung für das Auffüllen zu verschwenden, verwendet das Modell a Scatter-and-Pack-Strategie. Gültige Patches werden in Blöcke fester Länge gepackt und FlexAttention wird verwendet, um die Selbstaufmerksamkeit innerhalb der Grenzen jedes Bildbeispiels einzuschränken.
- Rasterreihenfolge: Wenn mehrere Objekte vorhanden sind, sagt Falcon Notion diese voraus Rasterreihenfolge (von oben nach unten, von hyperlinks nach rechts). Es wurde festgestellt, dass dies eine schnellere Konvergenz und einen geringeren Koordinatenverlust verursacht als eine zufällige oder größenbasierte Reihenfolge.
Das Trainingsrezept: Destillation auf 685 GT
Das Modell verwendet Multi-Lehrer-Destillation zur Initialisierung, zum Destillieren von Wissen DINOv3 (ViT-H) für lokale Besonderheiten und SigLIP2 (So400m) für sprachorientierte Funktionen. Nach der Initialisierung durchläuft das Modell a dreistufige Wahrnehmungstrainingspipeline insgesamt ca 685 Gigatokens (GT):
- In-Context-Itemizing (450 GT): Lernen, den Szenenbestand aufzulisten, um einen globalen Kontext aufzubauen.
- Aufgabenausrichtung (225 GT): Übergang zu unabhängigen Abfrageaufgaben mit Abfragemaskierung um sicherzustellen, dass das Modell jede Abfrage ausschließlich auf dem Bild basiert.
- Langkontext-Feinabstimmung (10 GT): Kurze Anpassung für excessive Dichte, wodurch das Maskenlimit auf 600 professional Ausdruck erhöht wird.
In diesen Phasen wird die aufgabenspezifische Serialisierung verwendet:
<picture>expr1<current><coord><dimension><seg> <eoq>expr2<absent> <eoq> <eos>.
Der <current> Und <absent> Token zwingen das Modell, vor der Lokalisierung eine binäre Entscheidung über die Existenz eines Objekts zu treffen.
PBench: Profilierungsfunktionen über gesättigte Basislinien hinaus
Um den Fortschritt zu messen, stellte das TII-Forschungsteam vor PBenchein Benchmark, der Stichproben in fünf Ebenen semantischer Komplexität organisiert, um Modellfehlermodi zu entwirren.
Hauptergebnisse: Falcon Notion vs. SAM 3 (Makro-F1)
| Benchmark-Break up | SAM 3 | Falkenwahrnehmung (600M) |
| L0: Einfache Objekte | 64.3 | 65.1 |
| L1: Attribute | 54.4 | 63,6 |
| L2: OCR-gesteuert | 24.6 | 38,0 |
| L3: Räumliches Verständnis | 31.6 | 53,5 |
| L4: Beziehungen | 33.3 | 49.1 |
| Dichte Spaltung | 58.4 | 72,6 |
Falcon Notion übertrifft SAM 3 bei komplexen semantischen Aufgaben deutlich und zeigt insbesondere a +21,9 Punktegewinn zum räumlichen Verständnis (Stufe 3).
FalconOCR: Der 300M-Dokumentenspezialist
Das TII-Group hat dieses Early-Fusion-Rezept auch auf erweitert FalconOCRein kompakter 300M-Parameter Das Modell wurde von Grund auf initialisiert, um der feinkörnigen Glyphenerkennung Priorität einzuräumen. FalconOCR ist mit mehreren größeren proprietären und modularen OCR-Systemen konkurrenzfähig:
- olmOCR: Erfolgt 80,3 % Genauigkeitentspricht oder übertrifft Gemini 3 Professional (80,2 %) und GPT 5.2 (69,8 %).
- OmniDocBench: Erreicht eine Gesamtpunktzahl von 88,64vor GPT 5.2 (86,56) und Mistral OCR 3 (85,20), liegt jedoch hinter der High-Modulpipeline PaddleOCR VL 1.5 (94,37) zurück.
Wichtige Erkenntnisse
- Einheitliche Early-Fusion-Architektur: Falcon Notion ersetzt modulare Encoder-Decoder-Pipelines durch einen einzigen dichten Transformer, der Bild-Patches und Textual content-Tokens in einem gemeinsamen Parameterraum aus der ersten Ebene verarbeitet. Es nutzt eine hybride Aufmerksamkeitsmaske – bidirektional für visuelle Token und kausal für Aufgabentoken –, um gleichzeitig als Imaginative and prescient-Encoder und autoregressiver Decoder zu fungieren.
- Wahrnehmungskettensequenz: Das Modell serialisiert die Instanzsegmentierung in eine strukturierte Sequenz was es dazu zwingt, die räumliche Place und Größe als Konditionierungssignal aufzulösen, bevor die Maske auf Pixelebene generiert wird.
- Spezialisierte Köpfe und GGROPE: Um dichte räumliche Daten zu verwalten, verwendet das Modell Fourier-Characteristic-Encoder für die hochdimensionale Koordinatenkartierung und Golden Gate ROPE (GGROPE), um isotrope 2D-Raumaufmerksamkeit zu ermöglichen. Der Muon-Optimierer wird für diese spezialisierten Köpfe eingesetzt, um die Lernraten mit dem vorab trainierten Rückgrat abzugleichen.
- Semantische Leistungssteigerungen: Beim neuen PBench-Benchmark, der semantische Fähigkeiten (Stufen 0–4) entwirrt, zeigt das 600M-Modell erhebliche Vorteile gegenüber SAM 3 in komplexen Kategorien, einschließlich eines Vorsprungs von +13,4 Punkten bei OCR-gesteuerten Abfragen und eines Vorsprungs von +21,9 Punkten beim räumlichen Verständnis.
- Hocheffiziente OCR-Erweiterung: Die Architektur lässt sich auf Falcon OCR herunterskalieren, ein 300-M-Parameter-Modell, das bei olmOCR 80,3 % und bei OmniDocBench 88,64 % erreicht. Es erreicht oder übertrifft die Genauigkeit viel größerer Systeme wie Gemini 3 Professional und GPT 5.2 und sorgt gleichzeitig für einen hohen Durchsatz für die Verarbeitung umfangreicher Dokumente.
Schauen Sie sich das an Papier, Modellgewicht, Repo Und Technische Particulars. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 120.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.