und fragte, ob ich dabei helfen könnte, Revisionsnummern aus über 4.700 technischen Zeichnungs-PDFs zu extrahieren. Sie migrierten auf ein neues Asset-Administration-System und benötigten den aktuellen REV-Wert jeder Zeichnung, ein kleines Feld im Titelblock jedes Dokuments. Die Various bestand darin, dass ein Staff von Ingenieuren jedes PDF einzeln öffnete, den Titelblock lokalisierte und den Wert manuell in eine Tabelle eingab. Bei zwei Minuten professional Ziehung sind das etwa 160 Personenstunden. Vier Wochen Ingenieursarbeit. Bei voll ausgelasteten Tarifen von etwa 50 £ professional Stunde sind das über 8.000 £ Arbeitskosten für eine Aufgabe, die über das Ausfüllen einer Tabellenspalte hinaus keinen technischen Mehrwert bringt.
Dies warfare kein KI-Downside. Es handelte sich um ein Systemdesignproblem mit echten Einschränkungen: Funds, Genauigkeitsanforderungen, gemischte Dateiformate und ein Staff, das Ergebnisse benötigte, denen es vertrauen konnte. Die KI warfare eine Komponente der Lösung. Die damit verbundenen technischen Entscheidungen sorgten dafür, dass das System tatsächlich funktionierte.
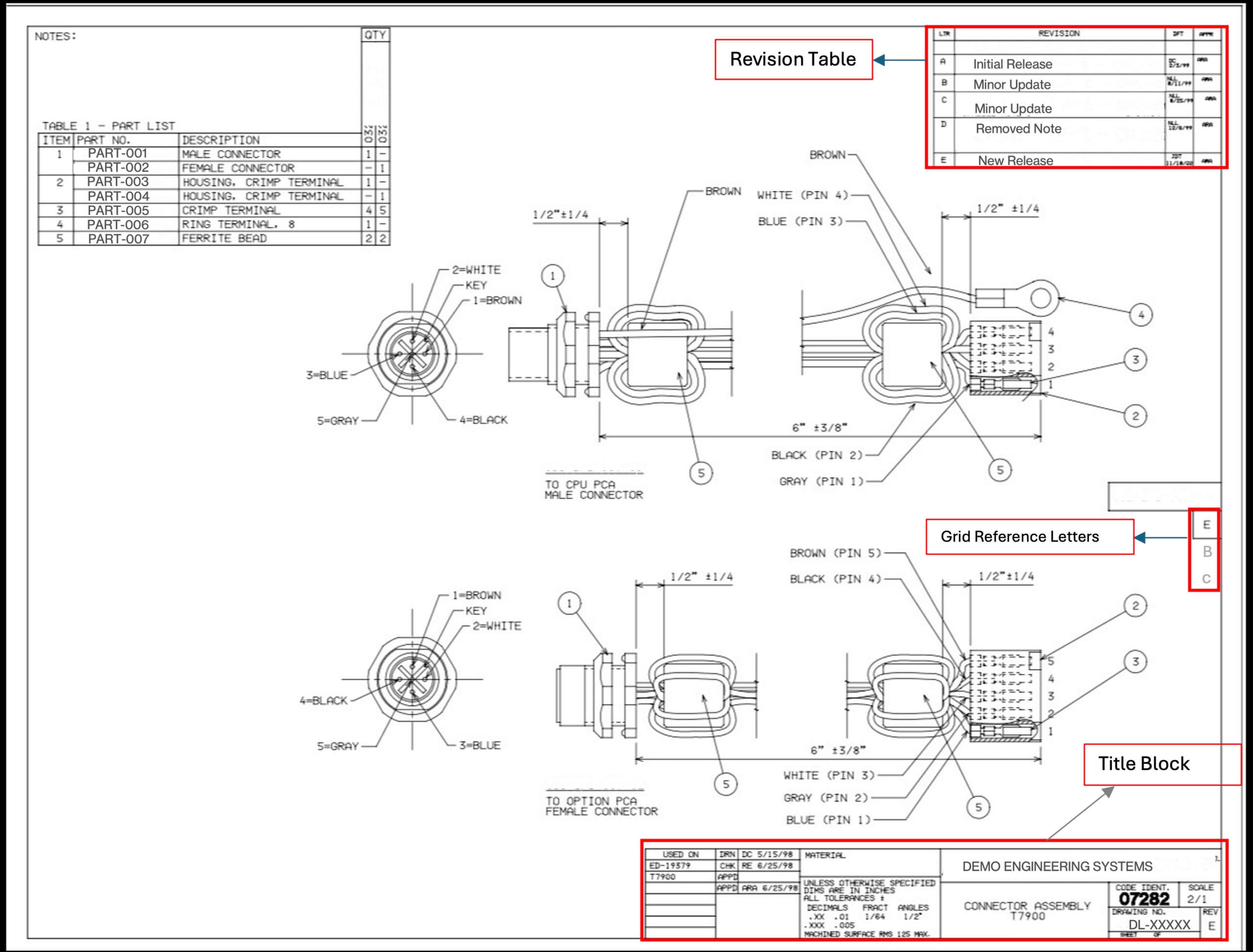
Die verborgene Komplexität „einfacher“ PDFs
Technische Zeichnungen sind keine gewöhnlichen PDFs. Einige wurden in CAD-Software program erstellt und als textbasierte PDFs exportiert, aus denen Sie Textual content programmgesteuert extrahieren können. Andere, insbesondere ältere Zeichnungen aus den 1990er und frühen 2000er Jahren, wurden von Papieroriginalen gescannt und als bildbasierte PDFs gespeichert. Die gesamte Seite ist ein flaches Rasterbild ohne Textebene.

Unser Korpus bestand zu etwa 70–80 % aus Textual content und zu 20–30 % aus Bildern. Aber selbst die textbasierte Teilmenge warfare tückisch. REV-Werte erschienen in mindestens vier Formaten: getrennte numerische Versionen wie 1-0, 2-0 oder 5-1; einzelne Buchstaben wie A, B, C; Doppelbuchstaben wie AA oder AB; und gelegentlich leere oder fehlende Felder. Einige Zeichnungen wurden um 90 oder 270 Grad gedreht. Bei vielen befanden sich Revisionsverlaufstabellen (mehrzeilige Änderungsprotokolle) direkt neben dem aktuellen REV-Feld, was eine offensichtliche Falsch-Positiv-Falle darstellt. Rasterreferenzbuchstaben entlang des Zeichnungsrahmens könnten leicht mit Einzelbuchstabenüberarbeitungen verwechselt werden.
Warum ein vollständig KI-Ansatz die falsche Wahl warfare
Sie könnten jedes Dokument auf GPT-4 Imaginative and prescient werfen und damit Schluss machen, aber bei etwa 0,01 US-Greenback professional Bild und 10 Sekunden professional Aufruf sind das 47 US-Greenback und quick 100 Minuten API-Zeit. Noch wichtiger ist, dass Sie für teure Rückschlüsse auf Dokumente bezahlen würden, bei denen ein paar Zeilen Python die Antwort in Millisekunden extrahieren könnten.
Die Logik warfare einfach: Wenn ein Dokument über extrahierbaren Textual content verfügt und der REV-Wert vorhersehbaren Mustern folgt, gibt es keinen Grund, ein LLM einzubeziehen. Bewahren Sie das Modell für die Fälle auf, in denen deterministische Methoden versagen.
Die Hybridarchitektur, die funktioniert hat

Stufe 1: PyMuPDF-Extraktion (deterministisch, keine Kosten). Für jedes PDF versuchen wir eine regelbasierte Extraktion mit PyMuPDF. Die Logik konzentriert sich auf den unteren rechten Quadranten der Seite, in dem sich Titelblöcke befinden, und sucht nach Textual content in der Nähe bekannter Anker wie „REV“, „DWG NO“, „SHEET“ und „SCALE“. Eine Bewertungsfunktion ordnet Kandidaten nach Nähe zu diesen Ankern und Konformität mit bekannten REV-Formaten ein.
def extract_native_pymupdf(pdf_path: Path) -> Non-obligatory(RevResult):
"""Attempt native PyMuPDF textual content extraction with spatial filtering."""
strive:
finest = process_pdf_native(
pdf_path,
brx=DEFAULT_BR_X, # bottom-right X threshold
bry=DEFAULT_BR_Y, # bottom-right Y threshold
blocklist=DEFAULT_REV_2L_BLOCKLIST,
edge_margin=DEFAULT_EDGE_MARGIN
)
if finest and finest.worth:
worth = _normalize_output_value(finest.worth)
return RevResult(
file=pdf_path.identify,
worth=worth,
engine=f"pymupdf_{finest.engine}",
confidence="excessive" if finest.rating > 100 else "medium",
notes=finest.context_snippet
)
return None
besides Exception:
return None
Die Sperrliste filtert häufige Fehlalarme heraus: Abschnittsmarkierungen, Rasterverweise, Seitenindikatoren. Durch die Beschränkung der Suche auf den Titelblockbereich werden falsche Treffer auf nahezu Null reduziert.
Stufe 2: GPT-4 Imaginative and prescient (für alles, was in Stufe 1 fehlt). Wenn die native Extraktion leer ausfällt, weil die PDF-Datei entweder bildbasiert ist oder das Textlayout zu mehrdeutig ist, rendern wir die erste Seite als PNG und senden sie über Azure OpenAI an GPT-4 Imaginative and prescient.
def pdf_to_base64_image(self, pdf_path: Path, page_idx: int = 0,
dpi: int = 150) -> Tuple(str, int, bool):
"""Convert PDF web page to base64 PNG with good rotation dealing with."""
rotation, should_correct = detect_and_validate_rotation(pdf_path)
with fitz.open(pdf_path) as doc:
web page = doc(page_idx)
pix = web page.get_pixmap(matrix=fitz.Matrix(dpi/72, dpi/72), alpha=False)
if rotation != 0 and should_correct:
img_bytes = correct_rotation(pix, rotation)
return base64.b64encode(img_bytes).decode(), rotation, True
else:
return base64.b64encode(pix.tobytes("png")).decode(), rotation, False
Nach dem Take a look at haben wir uns für 150 DPI entschieden. Höhere Auflösungen blähten die Nutzlast auf und verlangsamten API-Aufrufe, ohne die Genauigkeit zu verbessern. Bei niedrigeren Auflösungen gehen bei Randscans Particulars verloren.
Was in der Produktion kaputt ging
Zwei Klassen von Problemen tauchten erst auf, als wir den gesamten 4.700 Dokumente umfassenden Korpus durchgingen.
Rotationsmehrdeutigkeit. Technische Zeichnungen werden häufig im Querformat gespeichert, aber die PDF-Metadaten, die diese Ausrichtung kodieren, variieren stark. Einige Dateien stellen /Rotate richtig ein. Andere rotieren den Inhalt physisch, belassen aber die Metadaten auf Null. Wir haben dieses Downside mit einer Heuristik gelöst: Wenn PyMuPDF mehr als zehn Textblöcke aus der unkorrigierten Seite extrahieren kann, ist die Ausrichtung wahrscheinlich in Ordnung, unabhängig davon, was die Metadaten sagen. Andernfalls wenden wir die Korrektur an, bevor wir sie an GPT-4 Imaginative and prescient senden.
Sofortige Halluzination. Das Modell griff manchmal auf Werte aus den eigenen Beispielen der Eingabeaufforderung zurück, anstatt die tatsächliche Zeichnung zu lesen. Wenn jedes Beispiel REV „2-0“ zeigte, entwickelte das Modell eine Tendenz zur Ausgabe von „2-0“, selbst wenn die Zeichnung eindeutig „A“ oder „3-0“ anzeigte. Wir haben dies auf zwei Arten behoben: Wir haben die Beispiele über alle gültigen Formate hinweg mit expliziten Anti-Reminiscence-Warnungen diversifiziert und klare Anweisungen hinzugefügt, die die Revisionsverlaufstabelle (mehrzeiliges Änderungsprotokoll) vom aktuellen REV-Feld (einzelner Wert im Titelblock) unterscheiden.
CRITICAL RULES - AVOID THESE:
✗ DO NOT extract from REVISION HISTORY TABLES
(columns: REV | DESCRIPTION | DATE)
- We would like the CURRENT REV from title block (single worth)
✗ DO NOT extract grid reference letters (A, B, C alongside edges)
✗ DO NOT extract part markers ("SECTION C-C", "SECTION B-B")
Ergebnisse und Kompromisse
Wir haben anhand einer Stichprobe von 400 Dateien mit manuell verifizierter Grundwahrheit validiert.
| Metrisch | Hybrid (PyMuPDF + GPT-4) | Nur GPT-4 |
| Genauigkeit (n=400) | 96 % | 98 % |
| Bearbeitungszeit (n=4.730) | ~45 Minuten | ~100 Minuten |
| API-Kosten | ~10-15 $ | ~47 $ (alle Dateien) |
| Menschliche Bewertungsrate | ~5% | ~1% |
Die Genauigkeitslücke von 2 % warfare der Preis für eine Laufzeitverkürzung um 55 Minuten und begrenzte Kosten. Für eine Datenmigration, bei der Ingenieure ohnehin einen Prozentsatz der Werte stichprobenartig überprüfen würden, waren 96 % mit einer zur Überprüfung gekennzeichneten Price von 5 % akzeptabel. Wäre der Anwendungsfall die Einhaltung gesetzlicher Vorschriften gewesen, hätten wir GPT-4 für jede Datei ausgeführt.
Später haben wir neuere Modelle, einschließlich GPT-5+, mit demselben 400-Dateien-Validierungssatz verglichen. Die Genauigkeit warfare mit 98 % vergleichbar mit GPT-4.1. Die neueren Modelle boten für diese Extraktionsaufgabe keine nennenswerte Steigerung, bei höheren Kosten professional Anruf und langsamerer Inferenz. Wir haben GPT-4.1 ausgeliefert. Wenn es sich bei der Aufgabe um einen räumlich eingeschränkten Mustervergleich in einem genau definierten Dokumentbereich handelt, ist die Obergrenze die Eingabeaufforderung und die Vorverarbeitung, nicht die Argumentationsfähigkeit des Modells.
Bei der Produktionsarbeit ist das „richtige“ Genauigkeitsziel nicht immer das höchste erreichbare Ziel. Es ist diejenige, die Kosten, Latenz und den nachgelagerten Workflow, der von Ihrer Ausgabe abhängt, in Einklang bringt.
Vom Skript zum System
Das erste Ergebnis warfare ein Befehlszeilentool: Geben Sie einen Ordner mit PDFs ein und erhalten Sie eine CSV-Datei mit den Ergebnissen. Es lief in unserer Microsoft Azure-Umgebung und nutzte Azure OpenAI-Endpunkte für die GPT-4 Imaginative and prescient-Aufrufe.
Nachdem die erste Migration erfolgreich warfare, fragten die Beteiligten, ob andere Groups sie nutzen könnten. Wir haben die Pipeline in eine schlanke interne Webanwendung mit einer Datei-Add-Schnittstelle verpackt, sodass technisch nicht versierte Benutzer Extraktionen bei Bedarf ausführen können, ohne ein Terminal zu berühren. Das System wurde seitdem von Ingenieurteams an mehreren Standorten im gesamten Unternehmen übernommen, wobei jeder seine eigenen Zeichnungsarchive für Migrations- und Prüfaufgaben darin laufen lässt. Aus Gründen der Vertraulichkeit kann ich keine Screenshots weitergeben, aber die Kernextraktionslogik ist identisch mit der, die ich hier beschrieben habe.
Lektionen für Praktiker
Beginnen Sie mit der günstigsten praktikablen Methode. Der Instinkt bei der Arbeit mit LLMs besteht darin, sie für alles zu nutzen. Widerstehen Sie ihm. Die deterministische Extraktion verarbeitete 70–80 % unseres Korpus zum Nulltarif. Das LLM hat nur deshalb einen Mehrwert geschaffen, weil wir es auf die Fälle konzentriert haben, in denen die Regeln nicht eingehalten wurden.
Validieren Sie im Maßstab, nicht anhand ausgewählter Proben. Die Rotationsmehrdeutigkeit, die Verwirrung in der Revisionsverlaufstabelle und die falsch positiven Rasterreferenzen. Keines davon erschien in unserem ersten Testsatz mit 20 Dateien. Ihr Validierungssatz muss die tatsächliche Verteilung der Randfälle darstellen, die Sie in der Produktion sehen.
Immediate Engineering ist Software program-Engineering. Die Systemaufforderung durchlief mehrere Iterationen mit strukturierten Beispielen, expliziten negativen Fällen und einer Checkliste zur Selbstverifizierung. Wenn man es als Wegwerftext und nicht als sorgfältig versionierte Komponente behandelt, führt dies zu unvorhersehbaren Ergebnissen.
Messen Sie, was für den Stakeholder wichtig ist. Den Ingenieuren warfare es egal, ob die Pipeline PyMuPDF, GPT-4 oder Brieftauben verwendete. Sie legten Wert darauf, dass 4.700 Zeichnungen in 45 Minuten statt in vier Wochen verarbeitet wurden, mit 50–70 $ an API-Aufrufen statt über 8.000 £ an Entwicklungszeit und dass die Ergebnisse genau genug waren, um mit Zuversicht fortfahren zu können.
Die gesamte Pipeline umfasst etwa 600 Python-Zeilen. Es sparte vier Wochen Entwicklungszeit, kostete weniger als ein Staff-Mittagessen an API-Gebühren und wurde seitdem als Produktionstool an mehreren Standorten eingesetzt. Wir haben die neuesten Modelle getestet. Sie waren nicht besser für diesen Job. Manchmal geht es bei der wirkungsvollsten KI-Arbeit nicht darum, das leistungsstärkste verfügbare Modell zu verwenden. Es geht darum zu wissen, wo ein Modell im System hingehört, und es dort zu belassen.
Obinna ist Senior AI/Information Engineer mit Sitz in Leeds, Großbritannien, spezialisiert auf Doc Intelligence und Produktions-KI-Systeme. Er erstellt Inhalte rund um die praktische KI-Technik bei @DataSenseiObi auf X und Wisabi Analytics auf YouTube.