
Die Kundendienstteams ertranken mit dem überwältigenden Volumen der Kundenanfragen in jedem Unternehmen, an dem ich gearbeitet habe. Haben Sie ähnliche Erfahrungen gemacht?
Was wäre, wenn ich Ihnen sagen würde, dass Sie mit KI automatisch verwenden könnten identifizierenAnwesend kategorisieren, und gleichmäßig lösen Die häufigsten Probleme?
Durch die Feinabstimmung eines Transformatormodells wie Bert können Sie ein automatisiertes System erstellen, das Tickets mit dem Ausgabenart markiert und an das richtige Workforce weiterleitet.
In diesem Tutorial zeige ich Ihnen, wie Sie in fünf Schritten ein Transformatormodell für die Emotionsklassifizierung einstellen:
- Richten Sie Ihre Umgebung ein: Bereiten Sie Ihren Datensatz vor und installieren Sie die erforderlichen Bibliotheken.
- Final- und Vorverarbeitungsdaten: Analysieren Sie Textdateien und organisieren Sie Ihre Daten.
- Feinabstimmung Distilbert: Zugmodell zur Klassifizierung von Emotionen mit Ihrem Datensatz.
- Leistung bewerten: Verwenden Sie Metriken wie Genauigkeit, F1-Rating und Verwirrungsmatrizen, um die Modellleistung zu messen.
- Vorhersagen interpretieren: Visualisieren und verstehen Sie Vorhersagen mithilfe von Form (Shapley additive Erklärungen).
Am Ende haben Sie ein fein abgestimmtes Modell, das Emotionen aus Texteingaben mit hoher Genauigkeit klassifiziert, und Sie lernen auch, wie Sie diese Vorhersagen mit Shap interpretieren.
Dieser gleiche Ansatz kann auf reale Anwendungsfälle angewendet werden, die über die Emotionsklassifizierung hinausgehen, wie z. B. Kundensupportautomatisierung, Stimmungsanalyse, Inhalts Moderation und mehr.
Lass uns eintauchen!
Auswahl des richtigen Transformatormodells
Bei der Auswahl eines Transformatormodells für TextklassifizierungHier finden Sie eine kurze Aufschlüsselung der häufigsten Modelle:
- Bert: Very best für allgemeine NLP -Aufgaben, aber rechnerisch teuer für Coaching und Inferenz.
- Distilbert: 60% schneller als Bert, während 97% seiner Fähigkeiten beibehalten werden, wodurch es splendid für Echtzeitanwendungen ist.
- Roberta: Eine robustere Model von Bert, erfordert jedoch mehr Ressourcen.
- XLM-Roberta: Eine mehrsprachige Variante von Roberta, die auf 100 Sprachen trainiert wurde. Es ist perfekt für mehrsprachige Aufgaben, aber ziemlich ressourcenintensiv.
Für dieses Tutorial habe ich mich für die Feinabstimmung von Distilbert entschieden, da es die beste Stability zwischen Leistung und Effizienz bietet.
Schritt 1: Abhängigkeiten einrichten und installieren
Stellen Sie sicher, dass die erforderlichen Bibliotheken installiert sind:
!pip set up datasets transformers torch scikit-learn shapSchritt 2: Final- und Vorverarbeitungsdaten
Ich habe die benutzt Feelings -Datensatz für NLP von Praveen Govi, erhältlich auf Kaggle und erhältlich lizenziert für den kommerziellen Gebrauch. Es enthält Textual content mit Emotionen. Die Daten kommen in drei .txt Dateien: Zug, Validierung, Und prüfen.
Jede Zeile enthält einen Satz und sein entsprechendes Emotionslabel, das durch ein Semikolon getrennt ist:
textual content; emotion
"i didnt really feel humiliated"; "unhappiness"
"i'm feeling grouchy"; "anger"
"im updating my weblog as a result of i really feel shitty"; "unhappiness"Analyse des Datensatzes in einen PANDAS -Datenframe
Laden wir den Datensatz:
def parse_emotion_file(file_path):
"""
Parses a textual content file with every line within the format: {textual content; emotion}
and returns a pandas DataFrame with 'textual content' and 'emotion' columns.
Args:
- file_path (str): Path to the .txt file to be parsed
Returns:
- df (pd.DataFrame): DataFrame containing 'textual content' and 'emotion' columns
"""
texts = ()
feelings = ()
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
attempt:
# Break up every line by the semicolon separator
textual content, emotion = line.strip().cut up(';')
# append textual content and emotion to separate lists
texts.append(textual content)
feelings.append(emotion)
besides ValueError:
proceed
return pd.DataFrame({'textual content': texts, 'emotion': feelings})
# Parse textual content information and retailer as Pandas DataFrames
train_df = parse_emotion_file("prepare.txt")
val_df = parse_emotion_file("val.txt")
test_df = parse_emotion_file("check.txt")Verständnis der Etikettenverteilung
Dieser Datensatz enthält 16K -Trainingsbeispiele Und 2k Beispiele Für die Validierung und Prüfung. Hier ist die Aufschlüsselung der Etikettenverteilung:
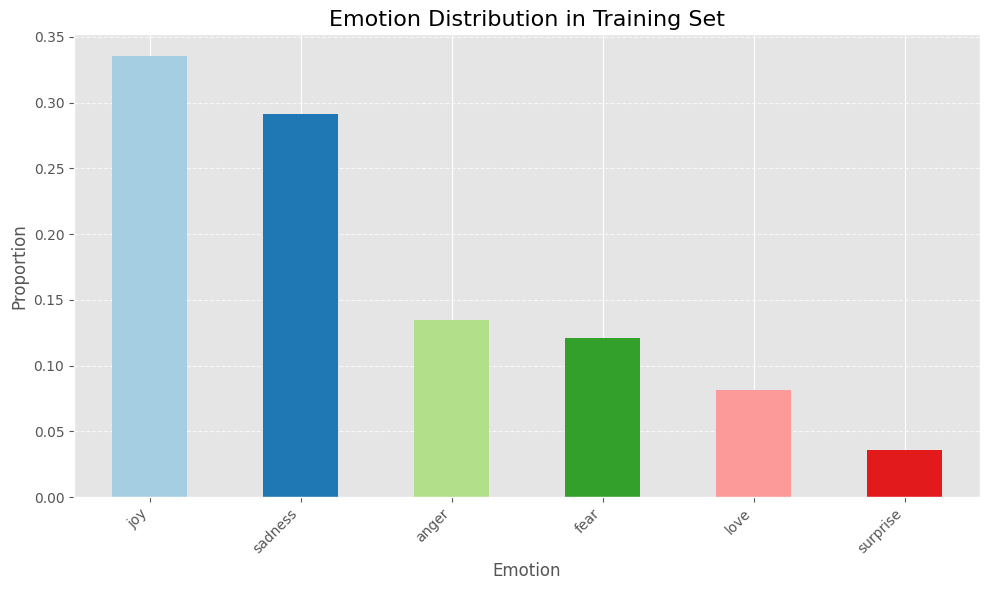
Das obige Balkendiagramm zeigt, dass der Datensatz ist unausgewogen, mit der Mehrheit der Proben als Freude und Traurigkeit bezeichnet.
Für eine Feinabstimmung eines Produktionsmodells würde ich in Betracht ziehen, mit verschiedenen Stichprobentechniken zu experimentieren, um dieses Drawback der Klassenungleiche zu überwinden und die Leistung des Modells zu verbessern.
Schritt 3: Tokenisierung und Datenvorverarbeitung
Als nächstes habe ich in Distilberts Tokenizer geladen:
from transformers import AutoTokenizer
# Outline the mannequin path for DistilBERT
model_name = "distilbert-base-uncased"
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)Dann habe ich es verwendet, um Textdaten zu token und die Beschriftungen in numerische IDs umzuwandeln:
# Tokenize information
def preprocess_function(df, label2id):
"""
Tokenizes textual content information and transforms labels into numerical IDs.
Args:
df (dict or pandas.Collection): A dictionary-like object containing "textual content" and "emotion" fields.
label2id (dict): A mapping from emotion labels to numerical IDs.
Returns:
dict: A dictionary containing:
- "input_ids": Encoded token sequences
- "attention_mask": Masks to point padding tokens
- "label": Numerical labels for classification
Instance utilization:
train_dataset = train_dataset.map(lambda x: preprocess_function(x, tokenizer, label2id), batched=True)
"""
tokenized_inputs = tokenizer(
df("textual content"),
padding="longest",
truncation=True,
max_length=512,
return_tensors="pt"
)
tokenized_inputs("label") = (label2id.get(emotion, -1) for emotion in df("emotion"))
return tokenized_inputs
# Convert the DataFrames to HuggingFace Dataset format
train_dataset = Dataset.from_pandas(train_df)
# Apply the 'preprocess_function' to tokenize textual content information and rework labels
train_dataset = train_dataset.map(lambda x: preprocess_function(x, label2id), batched=True)Schritt 4: Feinabstimmungsmodell
Als nächstes habe ich ein vorgebildetes Distilbert-Modell mit einem Klassifizierungskopf für unseren Textklassifizierungstext geladen. Ich habe auch angegeben, wie die Beschriftungen für diesen Datensatz aussehen:
# Get the distinctive emotion labels from the 'emotion' column within the coaching DataFrame
labels = train_df("emotion").distinctive()
# Create label-to-id and id-to-label mappings
label2id = {label: idx for idx, label in enumerate(labels)}
id2label = {idx: label for idx, label in enumerate(labels)}
# Initialize mannequin
mannequin = AutoModelForSequenceClassification.from_pretrained(
model_name,
num_labels=len(labels),
id2label=id2label,
label2id=label2id
)Das vorgebildete Distilbert-Modell für die Klassifizierung besteht aus Fünf Schichten plus ein Klassifizierungskopf.
Um eine Überanpassung zu verhindern, ich Die ersten vier Schichten eingefrorendas während der Vorversion gelernte Wissen aufrechterhalten. Auf diese Weise kann das Modell das allgemeine Sprachverständnis beibehalten, während nur die fünfte Ebene und der Klassifizierungskopf fein abtun, sich an meinen Datensatz anzupassen. So habe ich das gemacht:
# freeze base mannequin parameters
for title, param in mannequin.base_model.named_parameters():
param.requires_grad = False
# maintain classifier trainable
for title, param in mannequin.base_model.named_parameters():
if "transformer.layer.5" in title or "classifier" in title:
param.requires_grad = TrueMetriken definieren
Angesichts des Ungleichgewichts von Etiketten dachte ich, Genauigkeit sei möglicherweise nicht die am besten geeignete Metrik, daher habe ich mich dafür entschieden, andere Metriken einzubeziehen, die für Klassifizierungsprobleme wie Präzision, Rückruf, F1-Rating und AUC-Rating geeignet sind.
Ich habe auch eine „gewichtete“ Mittelung für F1-Rating, Präzision und Rückruf verwendet, um das Drawback der Klassenungleiche zu lösen. Dieser Parameter stellt sicher, dass alle Klassen proportional zur Metrik beitragen und verhindern, dass eine einzelne Klasse die Ergebnisse dominiert:
def compute_metrics(p):
"""
Computes accuracy, F1 rating, precision, and recall metrics for multiclass classification.
Args:
p (tuple): Tuple containing predictions and labels.
Returns:
dict: Dictionary with accuracy, F1 rating, precision, and recall metrics, utilizing weighted averaging
to account for sophistication imbalance in multiclass classification duties.
"""
logits, labels = p
# Convert logits to chances utilizing softmax (PyTorch)
softmax = torch.nn.Softmax(dim=1)
probs = softmax(torch.tensor(logits))
# Convert logits to predicted class labels
preds = probs.argmax(axis=1)
return {
"accuracy": accuracy_score(labels, preds), # Accuracy metric
"f1_score": f1_score(labels, preds, common="weighted"), # F1 rating with weighted common for imbalanced information
"precision": precision_score(labels, preds, common="weighted"), # Precision rating with weighted common
"recall": recall_score(labels, preds, common="weighted"), # Recall rating with weighted common
"auc_score": roc_auc_score(labels, probs, common="macro", multi_class="ovr")
}Lassen Sie uns den Trainingsprozess einrichten:
# Outline hyperparameters
lr = 2e-5
batch_size = 16
num_epochs = 3
weight_decay = 0.01
# Arrange coaching arguments for fine-tuning fashions
training_args = TrainingArguments(
output_dir="./outcomes",
evaluation_strategy="steps",
eval_steps=500,
learning_rate=lr,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=num_epochs,
weight_decay=weight_decay,
logging_dir="./logs",
logging_steps=500,
load_best_model_at_end=True,
metric_for_best_model="eval_f1_score",
greater_is_better=True,
)
# Initialize the Coach with the mannequin, arguments, and datasets
coach = Coach(
mannequin=mannequin,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
# Prepare the mannequin
print(f"Coaching {model_name}...")
coach.prepare()Schritt 5: Bewertung der Modellleistung
Nach dem Coaching bewertete ich die Leistung des Modells im Testsatz:
# Generate predictions on the check dataset with fine-tuned mannequin
predictions_finetuned_model = coach.predict(test_dataset)
preds_finetuned = predictions_finetuned_model.predictions.argmax(axis=1)
# Compute analysis metrics (accuracy, precision, recall, and F1 rating)
eval_results_finetuned_model = compute_metrics((predictions_finetuned_model.predictions, test_dataset("label")))Auf diese Weise hat das fein abgestimmte Distilbert-Modell im Testsatz im Vergleich zum vorgebliebenen Basismodell gespielt:

Vor der Feinabstimmung hat das vorgebildete Modell in unserem Datensatz schlecht abgebildet, da es die spezifischen Emotionsbezeichnungen zuvor noch nicht gesehen hat. Es conflict im Wesentlichen zufällig zu erraten, wie sich in einem AUC -Rating von 0,5 widerspiegelte, der nicht besser als den Zufall hinweist.
Nach der Feinabstimmung das Modell erheblich verbessert über alle MetrikenErzielung von 83% Genauigkeit bei der korrekten Identifizierung von Emotionen. Dies zeigt, dass das Modell auch mit nur 16K -Trainingsmuster erfolgreich sinnvolle Muster in den Daten gelernt hat.
Das ist unglaublich!
Schritt 6: Interpretation von Vorhersagen mit Shap
Ich habe das feinstimmige Modell auf drei Sätzen getestet und hier sind die Emotionen, die es vorhergesagt hat:
- “Der Gedanke, vor einer großen Menge zu sprechen. ““ → Angst 😱
- „Ich kann nicht glauben, wie respektlos sie waren! Ich habe so hart an diesem Projekt gearbeitet und sie haben es einfach entlassen, ohne zuzuhören. Es ist ärgerlich! „ → Wut 😡
- „Ich liebe dieses neue Telefon absolut! Die Kameraqualität ist unglaublich, der Akku dauert den ganzen Tag und so schnell. Ich könnte mit meinem Kauf nicht glücklicher sein, und ich kann es jedem empfehlen, der ein neues Telefon sucht. “ → Freude 😀
Beeindruckend, richtig?!
Ich wollte verstehen, wie das Modell seine Vorhersagen gemacht hat, und ich benutzte es mit Type (Shapley -Additive Erklärungen) Um die Merkmals Bedeutung zu visualisieren.
Ich begann mit dem Erstellen eines Erklärs:
# Construct a pipeline object for predictions
preds = pipeline(
"text-classification",
mannequin=model_finetuned,
tokenizer=tokenizer,
return_all_scores=True,
)
# Create an explainer
explainer = shap.Explainer(preds)Dann habe ich die Formwerte mit dem Erklärer berechnet:
# Compute SHAP values utilizing explainer
shap_values = explainer(example_texts)
# Make SHAP textual content plot
shap.plots.textual content(shap_values)Das folgende Diagramm zeigt, wie jedes Wort im Eingabetext zur Ausgabe des Modells mithilfe von Shap -Werten beiträgt:

In diesem Fall zeigt die Handlung, dass „Angst“ der wichtigste Faktor für die Vorhersage von „Angst“ als Emotion ist.
Die Type des Formtextes ist eine schöne, intuitive und interaktive Artwork, Vorhersagen zu verstehen, indem sie aufschlüsselt, wie sehr jedes Wort die endgültige Vorhersage beeinflusst.
Zusammenfassung
Sie haben erfolgreich gelernt, Distilbert für die Emotionsklassifizierung aus Textdaten zu fein abteilen! (Sie können sich das Modell beim Umarmungsgesicht ansehen Hier).
Transformatormodelle können für viele reale Anwendungen fein abgestimmt werden, darunter:
- Tagging -Kundendienst -Tickets (wie in der Einführung erläutert),
- Geben Sie die Risiken für psychische Gesundheit in textbasierten Gesprächen ab,
- Erkennung der Stimmung in Produktbewertungen.
Die Feinabstimmung ist eine effektive und effiziente Möglichkeit, leistungsstarke vorgebrachte Modelle mit einem relativ kleinen Datensatz an bestimmte Aufgaben anzupassen.
Was wirst du als nächstes intestine abgestimmen?
Möchten Sie Ihre KI -Fähigkeiten aufbauen?
👉🏻 Ich leite die AI Weekender Und Schreiben Sie wöchentliche Weblog -Beiträge zu Information Science, AI -Wochenendprojekten, Karriereberatung für Fachleute in Daten.
Ressourcen