

Bild vom Autor
Maschinelles Lernen ist eine Artwork Computeralgorithmus, der Maschinen beim Lernen unterstützt, ohne dass eine explizite Programmierung erforderlich ist.
Heute finden sich Anwendungen für maschinelles Lernen überall – in Navigationssystemen, Movie-Streaming-Plattformen und E-Commerce-Anwendungen.
Tatsächlich haben Sie vom Aufwachen am Morgen bis zum Schlafengehen wahrscheinlich mit Dutzenden von Modellen des maschinellen Lernens interagiert, ohne es überhaupt zu merken.
Es wird erwartet, dass die Branche des maschinellen Lernens zwischen 2024 und 2030 um über 36 % wächst.
Angesichts der Tatsache, dass nahezu jedes große Unternehmen aktiv in KI investiert, können Sie nur davon profitieren, Ihre Fähigkeiten im Bereich maschinelles Lernen zu verbessern.
Egal, ob Sie ein Information-Science-Fanatic, Entwickler oder jemand sind, der sein Wissen in diesem Bereich verbessern möchte, hier sind 5 häufig verwendete Modelle des maschinellen Lernens, die Sie kennen sollten:
1. Lineare Regression
Die lineare Regression ist das am häufigsten verwendete maschinelle Lernmodell zur Durchführung quantitativer Aufgaben.
Dieser Algorithmus wird verwendet, um ein kontinuierliches Ergebnis (y) unter Verwendung einer oder mehrerer unabhängiger Variablen (X) vorherzusagen.
Sie würden beispielsweise eine lineare Regression anwenden, wenn Sie die Aufgabe hätten, die Preise von Häusern auf Grundlage ihrer Größe vorherzusagen.
In diesem Fall ist die Hausgröße Ihre unabhängige Variable X, die zur Vorhersage des Hauspreises verwendet wird, der die unabhängige Variable ist.
Dies geschieht durch die Anpassung einer linearen Gleichung, die die Beziehung zwischen X und y modelliert, dargestellt durch y=mX+c.
Das folgende Diagramm stellt eine lineare Regression dar, die die Beziehung zwischen Hauspreis und -größe modelliert:
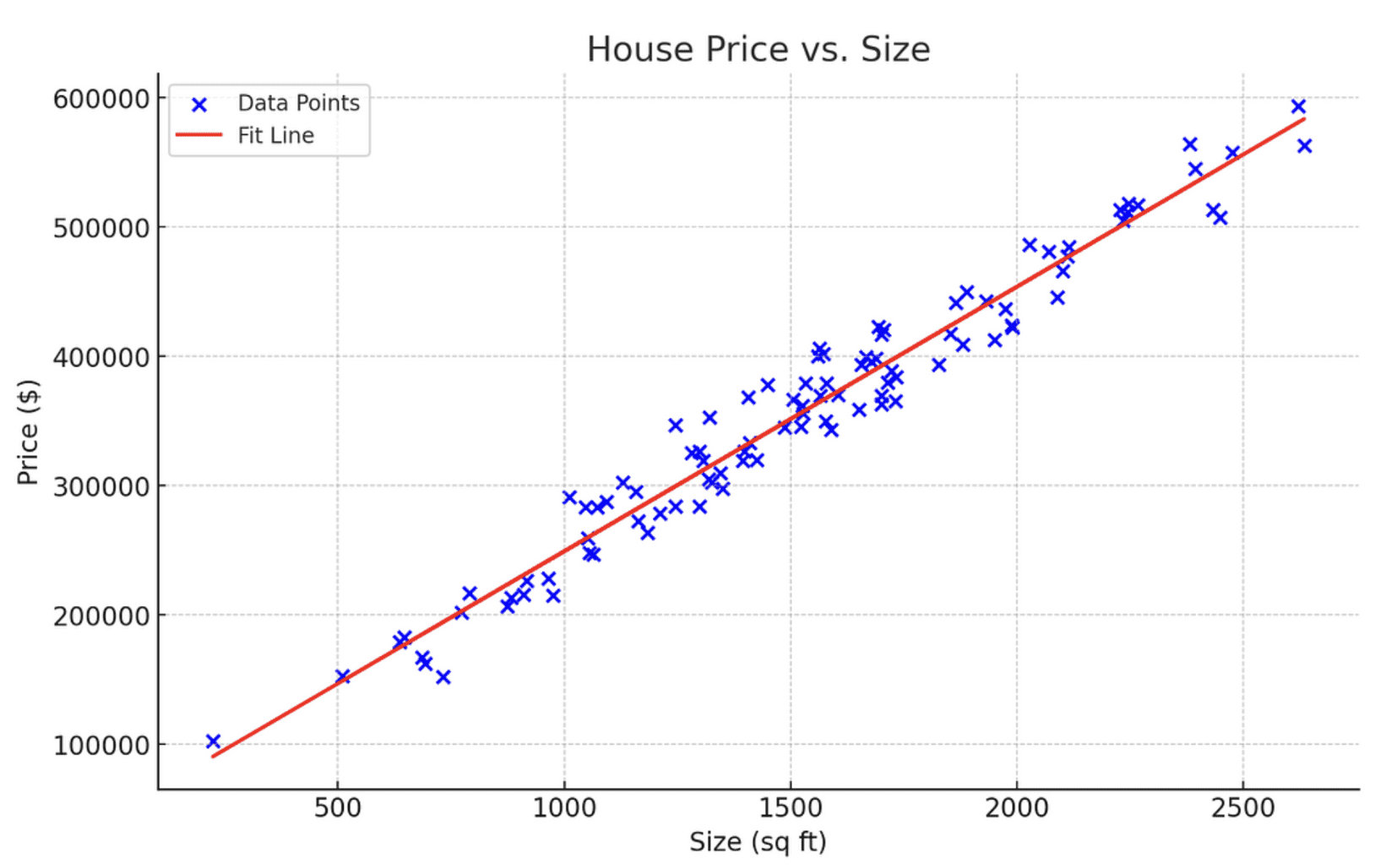
Bild vom Autor
Lernressource
Um mehr über die Instinct hinter der linearen Regression und ihre mathematische Funktionsweise zu erfahren, empfehle ich Ihnen, sich anzusehen Krish Naiks YouTube-Tutorial zum Thema.
2. Logistische Regression
Die logistische Regression ist ein Klassifizierungsmodell, das zur Vorhersage eines diskreten Ergebnisses bei einer oder mehreren unabhängigen Variablen verwendet wird.
Anhand der Anzahl negativer Schlüsselwörter in einem Satz lässt sich mithilfe der logistischen Regression beispielsweise vorhersagen, ob eine bestimmte Nachricht als legitim oder als Spam eingestuft werden sollte.
Hier ist ein Diagramm, das zeigt, wie die logistische Regression funktioniert:

Bild vom Autor
Beachten Sie, dass die logistische Regression im Gegensatz zur linearen Regression, die eine gerade Linie darstellt, als S-förmige Kurve modelliert wird.
Wie aus der obigen Kurve ersichtlich, steigt mit der Anzahl der auszuschließenden Schlüsselwörter auch die Wahrscheinlichkeit, dass die Nachricht als Spam eingestuft wird.
Die x-Achse dieser Kurve stellt die Anzahl der negativen Schlüsselwörter dar und die y-Achse zeigt die Wahrscheinlichkeit, dass es sich bei der E-Mail um Spam handelt.
Typischerweise weist bei der logistischen Regression eine Wahrscheinlichkeit von 0,5 oder mehr auf ein positives Ergebnis hin – in diesem Kontext bedeutet es, dass es sich bei der Nachricht um Spam handelt.
Umgekehrt weist eine Wahrscheinlichkeit von weniger als 0,5 auf ein negatives Ergebnis hin und bedeutet, dass es sich bei der Nachricht nicht um Spam handelt.
Lernressource
Wenn Sie mehr über logistische Regression erfahren möchten, StatQuests Tutorial zur logistischen Regression ist ein guter Ausgangspunkt.
3. Entscheidungsbäume
Entscheidungsbäume sind ein beliebtes maschinelles Lernmodell, das sowohl für Klassifizierungs- als auch für Regressionsaufgaben verwendet wird.
Sie funktionieren, indem sie den Datensatz anhand seiner Merkmale aufschlüsseln und eine baumartige Struktur zur Modellierung dieser Daten erstellen.
Vereinfacht ausgedrückt ermöglichen uns Entscheidungsbäume, Daten kontinuierlich anhand bestimmter Parameter aufzuteilen, bis eine endgültige Entscheidung getroffen ist.
Hier ist ein Beispiel für einen einfachen Entscheidungsbaum, der bestimmt, ob eine Particular person an einem bestimmten Tag ein Eis essen sollte:

Bild vom Autor
- Der Baum beginnt mit dem Wetter und ermittelt, ob es zum Eisessen geeignet ist.
- Wenn das Wetter heat ist, geht es weiter zum nächsten Knoten, Gesundheit. Andernfalls lautet die Entscheidung Nein und es gibt keine weiteren Splits.
- Beim nächsten Knoten gilt: Wenn die Particular person gesund ist, kann sie das Eis essen. Andernfalls sollte sie darauf verzichten.
Beachten Sie, wie die Daten an jedem Knoten im Entscheidungsbaum aufgeteilt werden und der Klassifizierungsprozess dadurch in einfache, überschaubare Fragen zerlegt wird.
Sie können einen ähnlichen Entscheidungsbaum für Regressionsaufgaben mit einem quantitativen Ergebnis zeichnen, und die Instinct hinter dem Prozess bliebe dieselbe.
Lernressource
Um mehr über Entscheidungsbäume zu erfahren, empfehle ich Ihnen, sich anzusehen Video-Tutorial von StatsQuest zum Thema.
4. Zufällige Wälder
Das Random-Forest-Modell kombiniert die Vorhersagen mehrerer Entscheidungsbäume und gibt eine einzelne Ausgabe zurück.
Intuitiv sollte dieses Modell eine bessere Leistung erbringen als ein einzelner Entscheidungsbaum, da es die Fähigkeiten mehrerer Vorhersagemodelle nutzt.
Dies geschieht mit Hilfe einer Technik namens Bagging oder Bootstrap-Aggregation.
Und so funktioniert das Bagging:
Mithilfe einer statistischen Technik namens Bootstrap wird der Datensatz mehrfach mit Zurücklegen abgetastet.
Anschließend wird für jeden Beispieldatensatz ein Entscheidungsbaum trainiert. Die Ergebnisse aller Bäume werden schließlich zu einer einzigen Vorhersage kombiniert.
Bei einem Regressionsproblem wird die endgültige Ausgabe durch Mittelung der Vorhersagen jedes Entscheidungsbaums generiert. Bei Klassifizierungsproblemen wird eine Mehrheitsklassenvorhersage gemacht.
Lernressource
Sie können zuschauen Krish Naiks Tutorial zu Random Forests um mehr über die Theorie und Instinct hinter dem Modell zu erfahren.
5. Ok-Means-Clustering
Alle bisher besprochenen Modelle des maschinellen Lernens fallen unter den Oberbegriff einer Methode namens „überwachtes Lernen“.
Überwachtes Lernen ist eine Technik, bei der ein gekennzeichneter Datensatz verwendet wird, um Algorithmen zur Vorhersage eines Ergebnisses zu trainieren.
Im Gegensatz dazu ist unüberwachtes Lernen eine Technik, die nicht mit gekennzeichneten Daten arbeitet. Stattdessen erkennt sie Muster in den Daten, ohne darauf trainiert zu sein, nach welchen spezifischen Ergebnissen sie suchen soll.
Ok-Means-Clustering ist ein unüberwachtes Lernmodell, das im Wesentlichen unmarkierte Daten aufnimmt und jeden Datenpunkt einem Cluster zuweist.
Die Beobachtungen gehören zum Cluster mit dem nächsten Mittelwert.
Hier ist eine visuelle Darstellung des Ok-Means-Clustermodells:
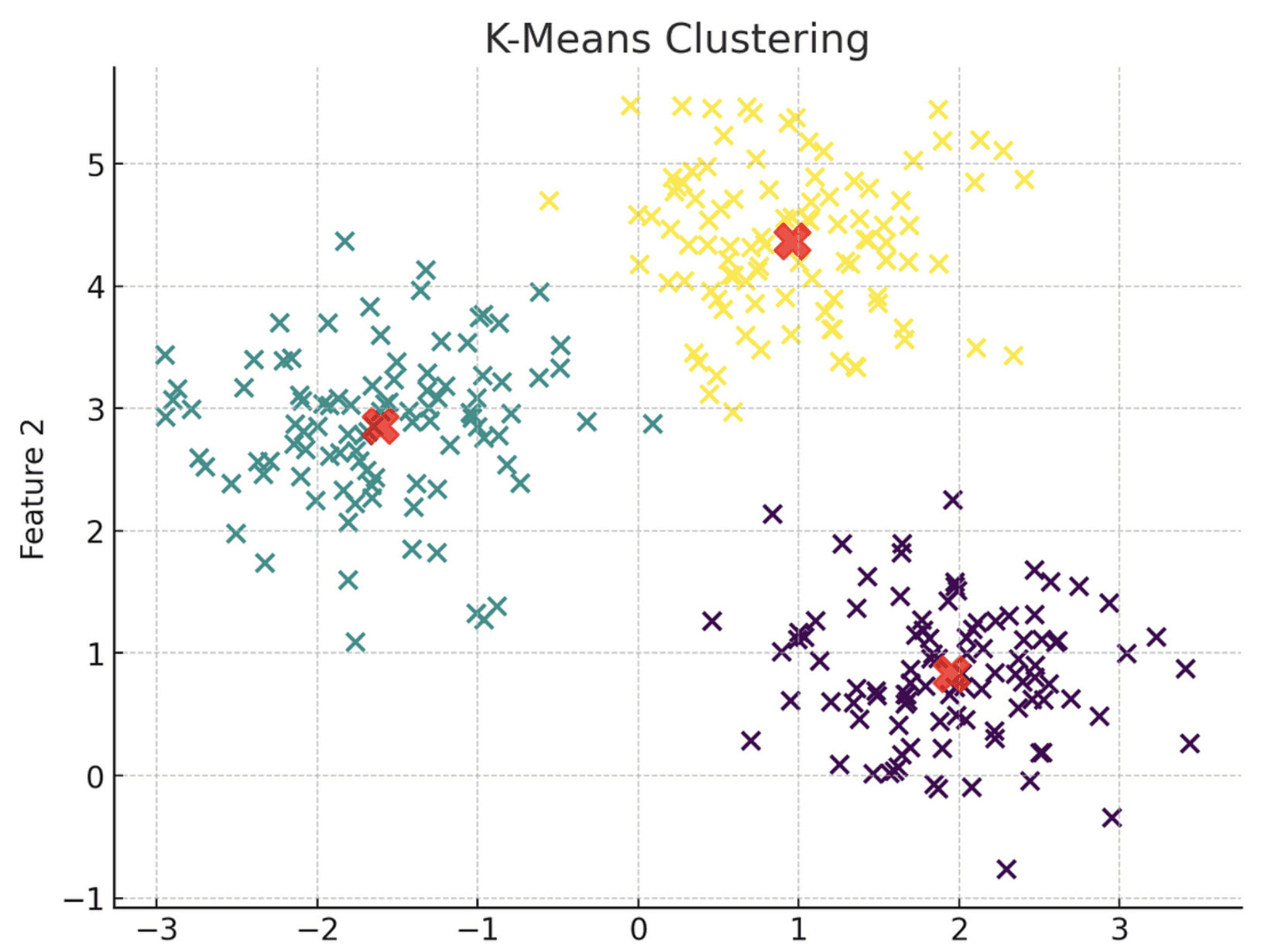
Bild vom Autor
Beachten Sie, wie der Algorithmus jeden Datenpunkt in drei verschiedene Cluster gruppiert hat, die jeweils durch eine andere Farbe dargestellt werden. Diese Cluster werden basierend auf ihrer Nähe zum Schwerpunkt gruppiert, der durch ein rotes X-Image gekennzeichnet ist.
Einfach ausgedrückt weisen alle Datenpunkte in Cluster 1 ähnliche Merkmale auf, weshalb sie zusammen gruppiert werden. Dasselbe Prinzip gilt für Cluster 2 und 3.
Beim Erstellen eines Ok-Means-Clustermodells müssen Sie die Anzahl der Cluster, die Sie generieren möchten, explizit angeben.
Dies lässt sich mithilfe der sogenannten Ellbogenmethode erreichen. Dabei werden die Fehlerwerte des Modells mit verschiedenen Clusterwerten in einem Liniendiagramm dargestellt. Anschließend wählen Sie den Wendepunkt der Kurve oder ihren „Ellbogen“ als optimale Anzahl von Clustern.
Hier ist eine visuelle Darstellung der Ellenbogenmethode:

Bild vom Autor
Beachten Sie, dass der Wendepunkt dieser Kurve bei der 3-Cluster-Markierung liegt, was bedeutet, dass die optimale Anzahl von Clustern für diesen Algorithmus 3 ist.
Lernressource
Wenn Sie mehr über das Thema erfahren möchten, bietet StatQuest eine
8-minütiges Video das die Funktionsweise des Ok-Means-Clusterings klar erklärt.
Nächste Schritte
Die in diesem Artikel erläuterten Algorithmen des maschinellen Lernens werden häufig in branchenweiten Anwendungen wie Prognosen, Spam-Erkennung, Kreditgenehmigung und Kundensegmentierung eingesetzt.
Wenn Sie es geschafft haben, bis hierher zu folgen, herzlichen Glückwunsch! Sie verfügen nun über ein solides Verständnis der am häufigsten verwendeten Vorhersagealgorithmen und haben den ersten Schritt in das Feld des maschinellen Lernens getan.
Aber die Reise endet hier nicht.
Um Ihr Verständnis von Modellen des maschinellen Lernens zu festigen und sie auf reale Anwendungen anwenden zu können, empfehle ich Ihnen, eine Programmiersprache wie Python oder R zu lernen.
Freecodecamps Python für Anfänger Kurs
Kurs ist ein guter Ausgangspunkt. Wenn Sie in Ihrer Programmierreise stecken bleiben, habe ich eine YouTube-Video darin wird erklärt, wie man das Programmieren von Grund auf lernt.
Sobald Sie das Programmieren gelernt haben, können Sie diese Modelle mithilfe von Bibliotheken wie Scikit-Study und Keras in die Praxis umsetzen.
Um Ihre Fähigkeiten in den Bereichen Datenwissenschaft und maschinelles Lernen zu verbessern, empfehle ich Ihnen, mithilfe von generativen KI-Modellen wie ChatGPT einen maßgeschneiderten Lernpfad für sich selbst zu erstellen. Hier finden Sie eine detailliertere Roadmap, die Ihnen den Einstieg in die Nutzung erleichtert ChatGPT, um Datenwissenschaft zu lernen.
Natassha Selvaraj ist eine autodidaktische Datenwissenschaftlerin mit einer Leidenschaft für das Schreiben. Natassha schreibt über alles, was mit Datenwissenschaft zu tun hat, und ist eine wahre Meisterin aller Datenthemen. Sie können mit ihr in Kontakt treten auf LinkedIn oder schau dir ihre Youtube Kanal.