
Vor ein paar Wochen stellte mir mein Freund Vasu eine einfache, aber knifflige Frage: „Gibt es eine Möglichkeit, non-public LLMs lokal auf meinem Laptop computer auszuführen?“ Ich machte mich sofort auf die Suche nach Weblog-Beiträgen, YouTube-Tutorials usw. und kam mit leeren Händen zurück. Nichts, was ich finden konnte, erklärt es wirklich für Nicht-Ingenieure, für jemanden, der diese Modelle nur sicher und privat nutzen wollte.
Das hat mich zum Nachdenken gebracht. Wenn ein kluger Freund wie Vasu Schwierigkeiten hat, eine klare Ressource zu finden, wie viele andere da draußen stecken dann auch fest? Leute, die keine Entwickler sind, mit denen man sich nicht herumschlagen will Docker, Pythonoder GPU Fahrer, die aber dennoch die Magie der KI auf ihrer eigenen Maschine nutzen möchten.
Hier sind wir additionally. Vielen Dank, Vasu, dass du mich auf dieses Bedürfnis hingewiesen und mich dazu angeregt hast, diesen Leitfaden zu schreiben. Dieser Weblog richtet sich an alle, die hochmoderne LLMs lokal, sicher und privat ausführen möchten, ohne den Verstand in der Setup-Hölle zu verlieren.
Wir gehen die Instruments durch, die ich ausprobiert habe: Ollama, LM Studio und AnythingLLM (plus ein paar lobende Erwähnungen). Am Ende wissen Sie nicht nur, was funktioniert, sondern auch, warum es funktioniert und wie Sie Ihre eigene lokale KI im Jahr 2025 zum Laufen bringen.
Warum LLMs überhaupt lokal ausführen?
Bevor wir eintauchen, lasst uns einen Schritt zurücktreten. Warum sollte sich jemand die Mühe machen, Multi-Gigabyte-Modelle auf seinem persönlichen Rechner auszuführen, wenn OpenAI oder Anthropic nur einen Klick entfernt sind?
Drei Gründe:
- Datenschutz und Kontrolle: Keine API-Aufrufe. Keine Protokolle. Nein „Ihre Daten dürfen zur Verbesserung unserer Modelle verwendet werden.“ Sie können Llama 3 oder Mistral buchstäblich ausführen, ohne dass etwas aus Ihrer Maschine austritt.
- Offline-Fähigkeit: Sie können es in einem Flugzeug ausführen. In einem Keller. Während eines Stromausfalls (okay, vielleicht auch nicht). Der Punkt ist, dass es lokal ist, es gehört Ihnen.
- Kosten und Freiheit: Sobald Sie das Modell heruntergeladen haben, ist die Nutzung kostenlos. Keine Abonnementstufen, keine Abrechnung professional Token. Sie können jedes beliebige offene Modell laden, es optimieren oder morgen austauschen.
Der Kompromiss ist natürlich die {Hardware}.
Das Ausführen eines 70B-Parametermodells auf einem MacBook Air ist wie der Versuch, eine Rakete mit einem Fahrrad zu starten. Aber kleinere Modelle wie 7B, 13B und sogar einige effiziente 30B-Varianten laufen heutzutage dank Quantisierung und intelligenteren Laufzeiten wie GGUF, llama.cpp usw. überraschend intestine.
1. Ollama: Das minimalistische Arbeitstier
Das erste Device, das wir sehen werden, ist Ollama. Wenn Sie in letzter Zeit auf Reddit oder Hacker Information waren, haben Sie es wahrscheinlich in jedem „lokalen LLM“-Diskussionsthread gesehen.
Die Set up von Ollama ist kinderleicht, Sie können es direkt von der Web site herunterladen und schon kann es losgehen. Kein Docker. Keine Python-Hölle. Kein CUDA-Treiber-Albtraum.
Das ist das offizielle Web site zum Obtain des Instruments:
Es ist für MacOS, Linux und Home windows verfügbar. Nach der Set up können Sie Ihr Modell aus der Liste der verfügbaren Modelle auswählen und es einfach herunterladen.
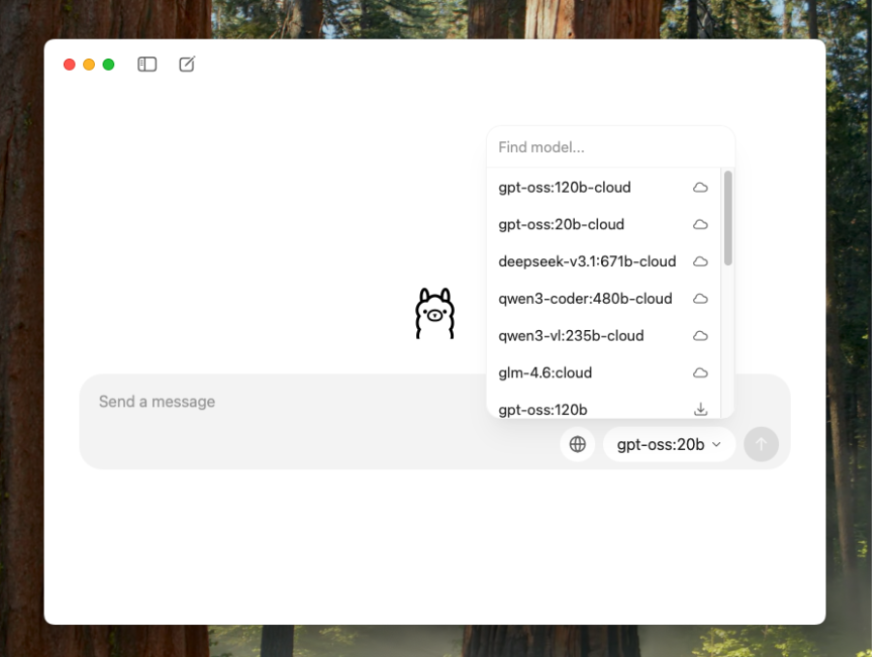
Ich habe Qwen3 4B heruntergeladen und Sie können sofort mit dem Chatten beginnen. Hier sind die nützlichen Datenschutzeinstellungen, die Sie vornehmen können:
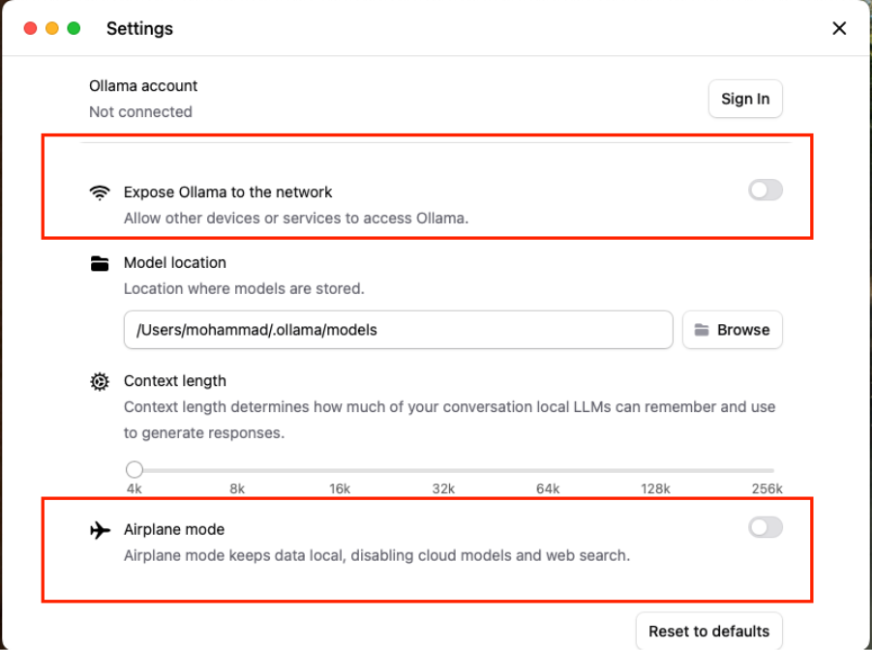
Sie können steuern, ob Ollama mit anderen Geräten in Ihrem Netzwerk kommuniziert oder nicht. Außerdem gibt es diesen netten „Flugzeugmodus“-Schalter, der im Grunde alles sperrt: Ihre Chats, Ihre Modelle, alles bleibt vollständig lokal.
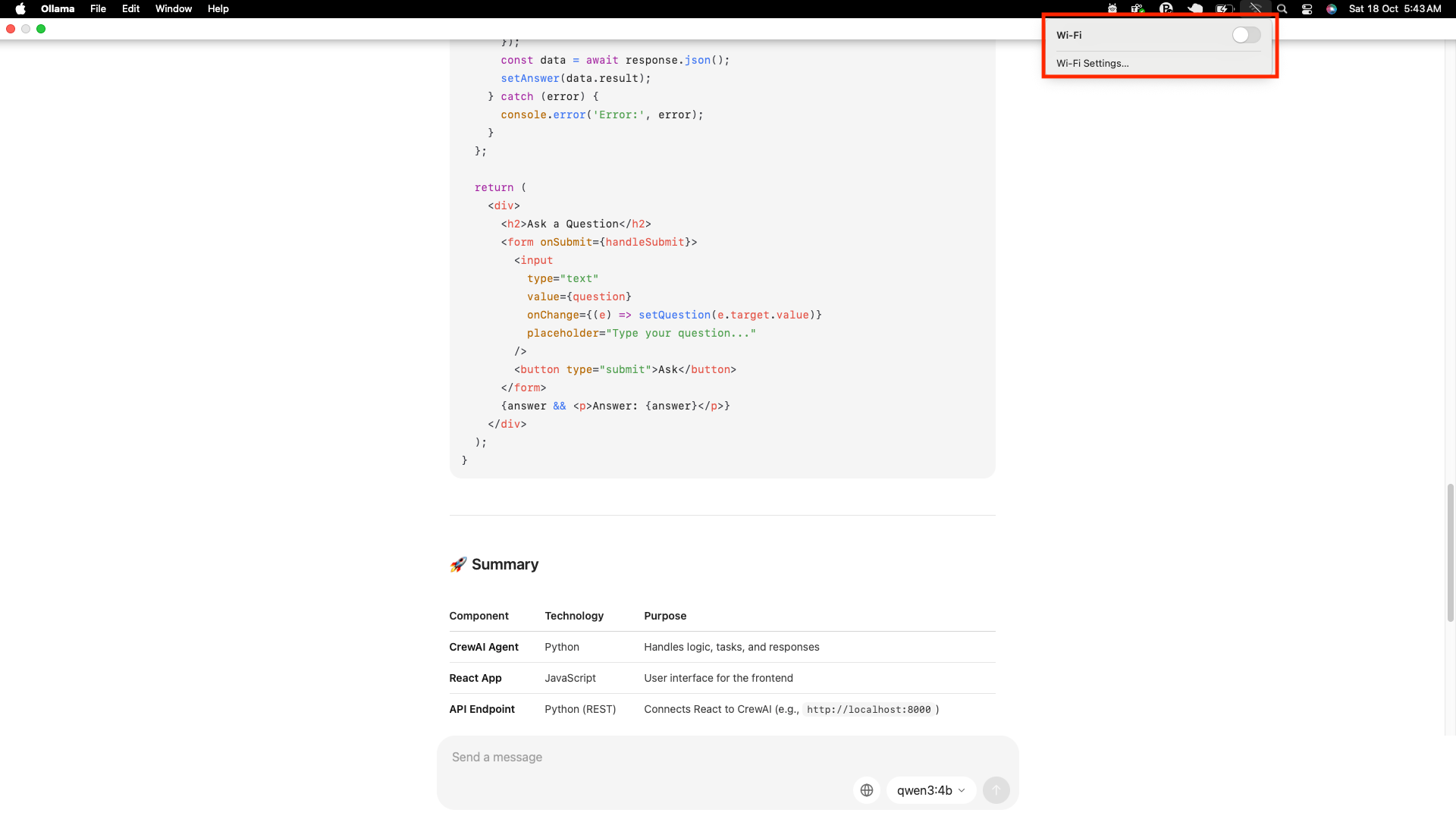
Und natürlich musste ich es auf die altmodische Artwork testen. Ich habe mein WLAN buchstäblich mitten im Chat ausgeschaltet, nur um zu sehen, ob es noch funktioniert (Spoiler: Ja, haha).
Was mir gefallen hat?
- Tremendous saubere UX: Die Benutzeroberfläche kommt ChatGPT/Claude/Gemini bekannt vor und Sie können problemlos Modelle herunterladen.
- Effizientes Ressourcenmanagement: Ollama verwendet unter der Haube llama.cpp und unterstützt quantisierte Modelle (This autumn, Q5, Q6 usw.), was bedeutet, dass Sie sie tatsächlich auf einem anständigen MacBook ausführen können, ohne es zu zerstören.
- API-kompatibel: Sie erhalten einen lokalen HTTP-Endpunkt, der die API von OpenAI nachahmt. Wenn Sie additionally über openai.ChatCompletion.create vorhandenen Code haben, können Sie ihn einfach umleiten http://localhost:11434.
- Integrationen: Viele Apps wie AnythingLLM, Chatbox und sogar LM Studio können Ollama als Backend verwenden. Es ist wie die lokale Modell-Engine, an die sich jeder anschließen möchte.
Ollama fühlt sich wie ein Geschenk an. Es ist stabil, schön und macht lokale KI auch für Nicht-Ingenieure zugänglich. Wenn Sie nur Modelle verwenden und sich nicht mit der Einrichtung herumschlagen möchten, ist Ollama perfekt.
Vollständiger Leitfaden: Wie führe ich LLM-Modelle lokal mit Ollama aus?
2. LM Studio: Lokale KI mit Stil
LM Studio bietet Ihnen eine elegante Desktop-Oberfläche (Mac/Home windows/Linux), über die Sie mit Modellen chatten, offene Modelle von Hugging Face durchsuchen und sogar Systemeingabeaufforderungen oder Sampling-Einstellungen optimieren können; alles ohne das Terminal zu berühren.
Als ich es zum ersten Mal öffnete, hatte ich das Gefühl: „Okay, so würde ChatGPT aussehen, wenn es auf meinem Desktop wäre und nicht mit einem Server kommunizieren würde.“
Sie können es einfach herunterladen LM Studio von seiner offiziellen Web site:
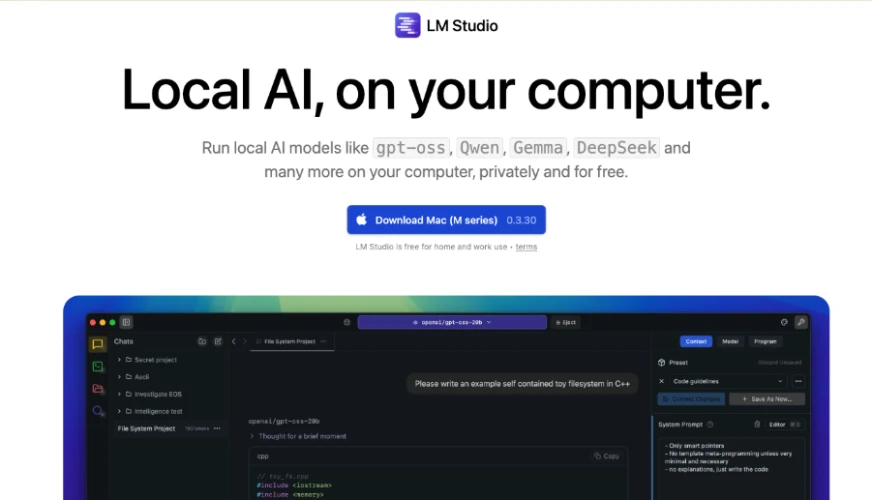
Beachten Sie, dass Modelle wie GPT-OSS, Qwen, Gemma, DeepSeek und mehr als kompatible Modelle aufgeführt werden, die kostenlos sind und privat verwendet werden können (auf Ihren Pc heruntergeladen). Sobald Sie es heruntergeladen haben, können Sie Ihren Modus auswählen:
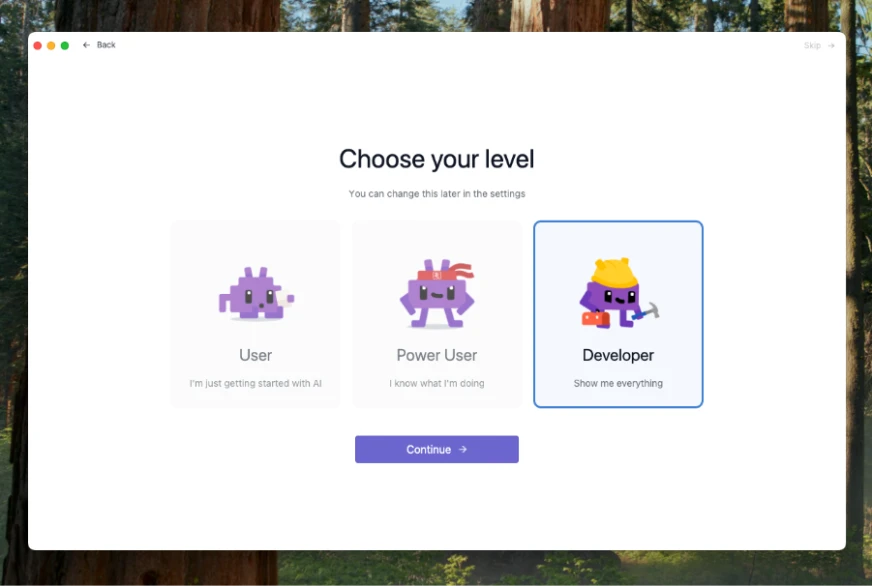
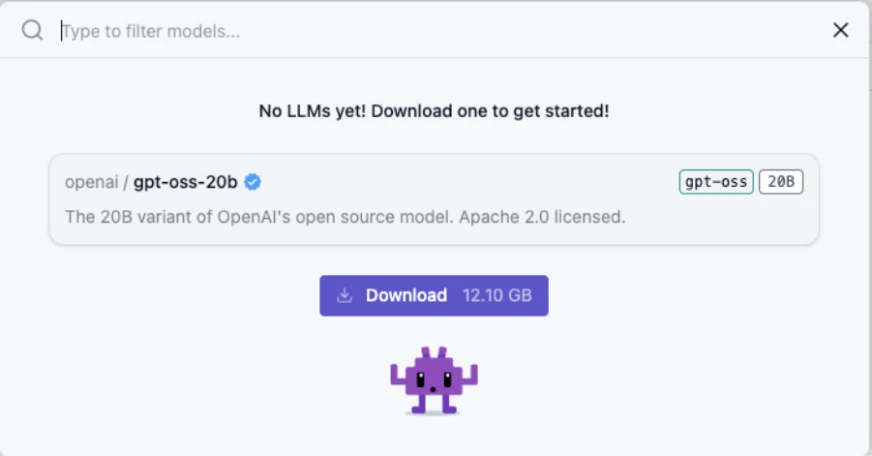
Ich habe den Entwicklermodus gewählt, weil ich alle Optionen/Informationen sehen wollte, die während des Chats angezeigt werden. Sie können jedoch einfach einen Benutzer auswählen und mit dem Betrieb beginnen. Sie müssen auswählen, welches Modell Sie als Nächstes herunterladen möchten:
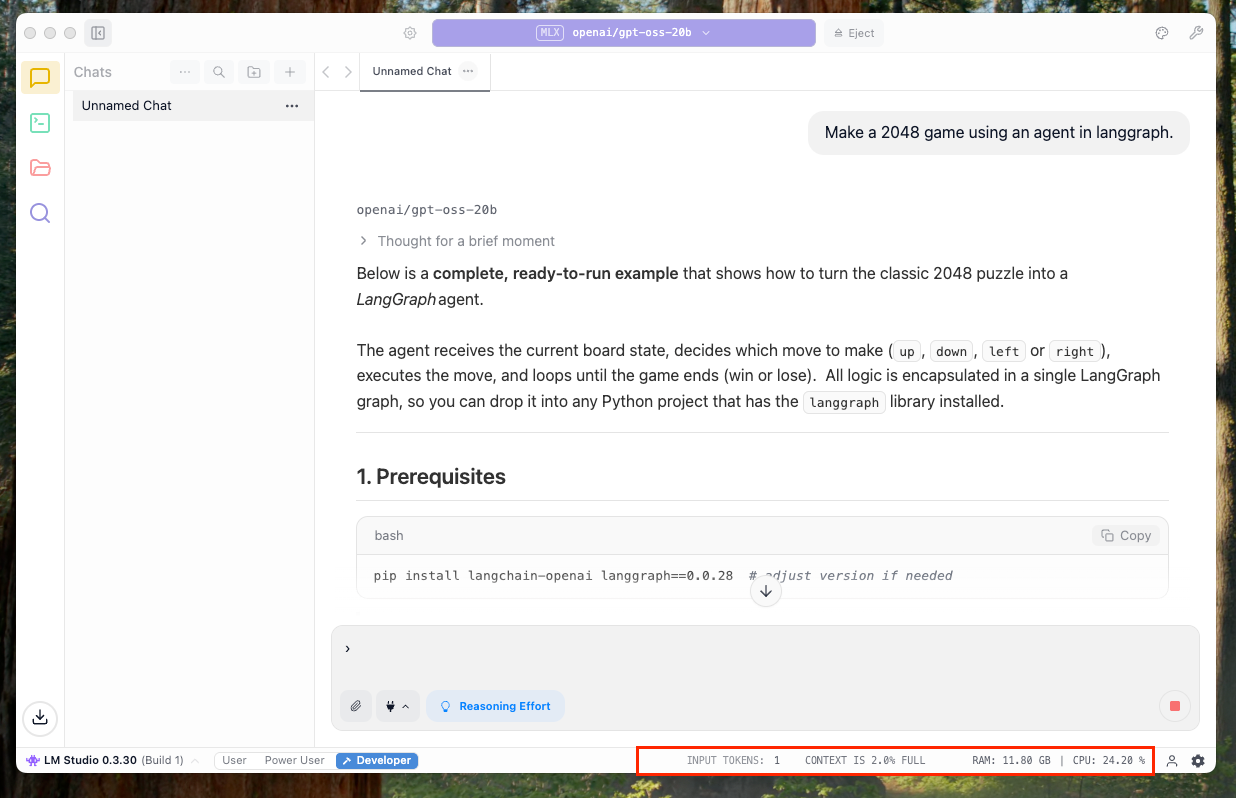
Sobald Sie fertig sind, können Sie einfach mit dem Mannequin chatten. Da dies außerdem der Entwicklermodus ist, konnte ich direkt unten zusätzliche Messwerte zum Chat wie CPU-Auslastung und Token-Nutzung sehen:
Und Sie haben zusätzliche Funktionen wie die Möglichkeit, eine „Systemaufforderung“ festzulegen, die beim Einrichten der Persona des Modells oder des Themas des Chats nützlich ist:
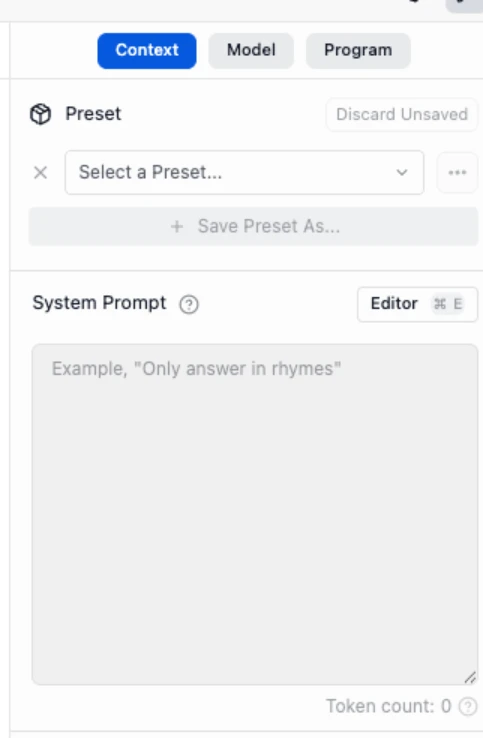
Abschließend finden Sie hier die Liste der verfügbaren Modelle:

Was mir gefallen hat?
- Schöne Benutzeroberfläche: Ehrlich gesagt, LM Studio sieht aus Skilled. Chat-Sitzungen mit mehreren Registerkarten, Speicher, Eingabeaufforderungsverlauf, alles übersichtlich gestaltet.
- Ollama-Backend-Unterstützung: LM Studio kann Ollama im Hintergrund verwenden, was bedeutet, dass Sie Modelle über die Laufzeit von Ollama laden können, während Sie weiterhin in der Benutzeroberfläche von LM Studio chatten.
- Modellmarktplatz: Sie können Modelle direkt in der App suchen und herunterladen: Llama 3, Mistral, Falcon, Phi-3, alle sind da.
- Parametersteuerung: Sie können Temperatur, Prime-P, Kontextlänge usw. anpassen. Very best für schnelle Experimente.
- Offline- und lokale Einbettungen: Es unterstützt auch lokale Einbettungen, was hilfreich ist, wenn Sie abruferweiterte Setups erstellen möchten (LAPPEN) ohne Web.
Vollständiger Leitfaden: Wie führe ich LLM lokal mit LM Studio aus?
3. AnythingLLM: Lokale Modelle tatsächlich nützlich machen
Ich habe AnythingLLM hauptsächlich deshalb ausprobiert, weil ich wollte, dass mein lokales Mannequin mehr kann als nur chatten. Es verbindet Ihr LLM (wie Ollama) mit echten Dingen: PDFs, Notizen, Dokumente und ermöglicht die Beantwortung von Fragen anhand Ihrer eigenen Daten.
Die Einrichtung battle einfach und das Beste daran? Alles bleibt lokal. Einbettungen, Abruf, Kontext und alles geschieht auf Ihrem Pc.
Und ja, ich habe meinen üblichen WLAN-Check durchgeführt und ihn während der Abfrage ausgeschaltet, nur um sicherzugehen. Hat immer noch funktioniert, keine geheimen Anrufe, kein Drama.
Es ist nicht perfekt, aber es ist tatsächlich das erste Mal, dass mein lokales Modell dabei ist fühlte sich nützlich an statt nur gesprächig.
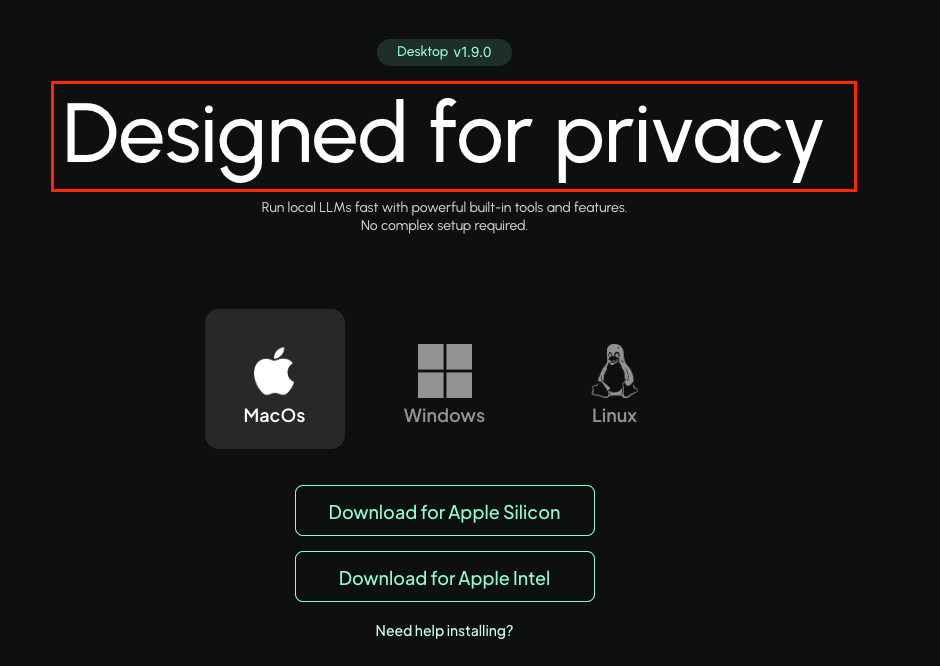
Lassen Sie es uns von dort aus einrichten offizielle Web site:

Gehen wir zur Obtain-Seite, sie ist für Linux/Home windows/Mac verfügbar. Beachten Sie, wie deutlich und klar sie ihr Versprechen, die Privatsphäre zu wahren, von Anfang an zum Ausdruck bringen:
Nach der Einrichtung können Sie Ihren Modellanbieter und Ihr Modell auswählen.
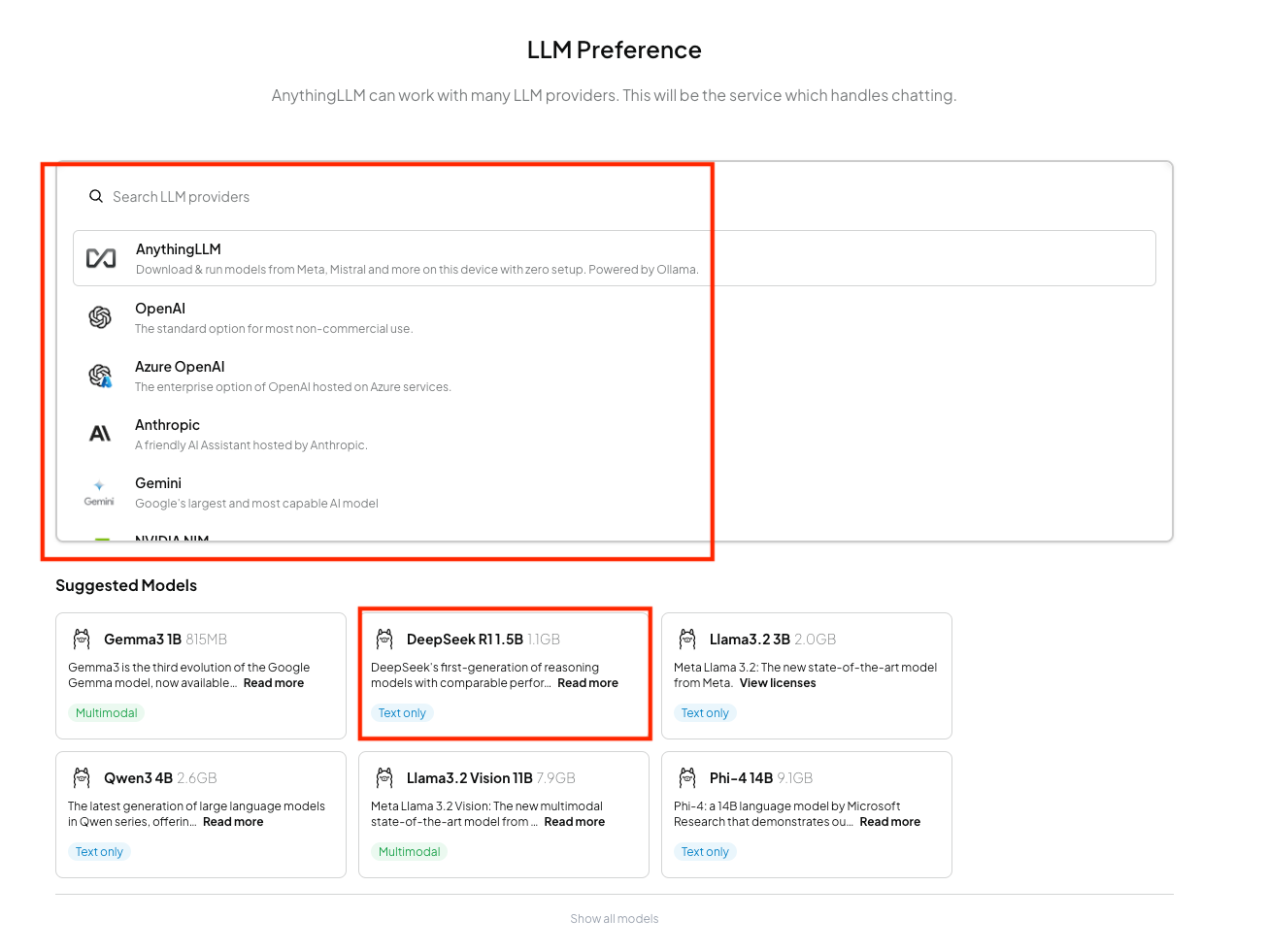
Es stehen alle Arten von Modellen zur Verfügung, von Googles Gemma bis hin zu Qwen, Phi, DeepSeek und vielem mehr. Und für Anbieter haben Sie Optionen wie AnythingLLM, OpenAI, Anthropic, Gemini, Nvidia und die Liste geht weiter!
Hier sind die Datenschutzeinstellungen:
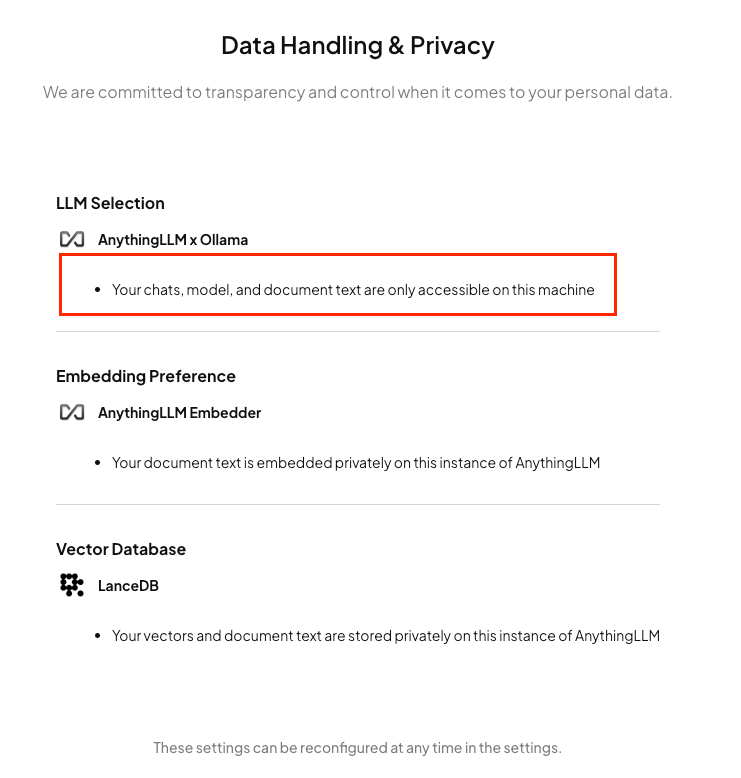
Eine tolle Sache ist, dass dieses Device nicht nur auf den Chat beschränkt ist, sondern Sie auch andere nützliche Dinge tun können, wie zum Beispiel Agenten erstellen, RAG und vieles mehr.
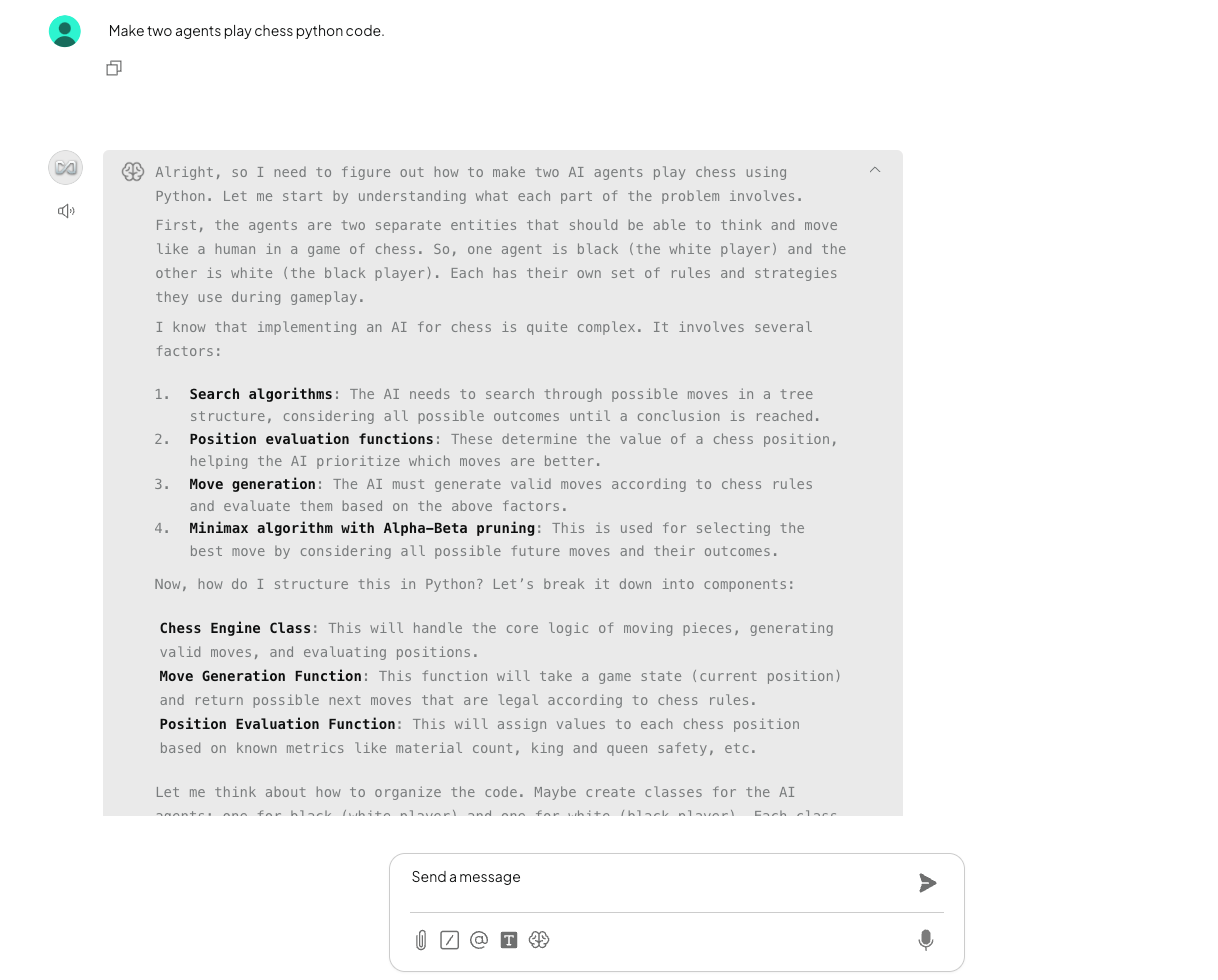
Und so sieht die Chat-Oberfläche aus:
Was mir gefallen hat?
- Funktioniert perfekt mit Ollama: vollständige lokale Einrichtung, keine versteckten Cloud-Inhalte.
- Lassen Sie uns echte Daten (PDFs, Notizen usw.) verknüpfen, damit das Modell tatsächlich etwas Nützliches weiß.
- Einfach zu verwenden, saubere Benutzeroberfläche und zum Ausführen ist kein Doktortitel in Entwicklung erforderlich.
- Habe meinen WLAN-Aus-Check mit Bravour bestanden, da ich völlig offline und völlig privat battle.
Vollständiger Leitfaden: Was ist AnythingLLM und wie wird es verwendet?
Lobende Erwähnungen: llama.cpp, OpenWeb UI
Ein kurzer Gruß an ein paar andere Instruments, die etwas Liebe verdienen:
- lama.cpp: das eigentliche OG hinter den meisten dieser lokalen Setups. Es ist nicht auffällig, aber es ist unglaublich effizient. Wenn Ollama die polierte Hülle ist, ist llama.cpp der rohe Muskel, der darunter die schwere Arbeit leistet. Sie können es direkt vom Terminal aus ausführen, jeden Parameter anpassen und es sogar für Ihre spezifische {Hardware} kompilieren. Pure Kontrolle.
- WebUI öffnen: Betrachten Sie es als eine schöne, browserbasierte Ebene für Ihre lokalen Modelle. Es funktioniert mit Ollama und anderen und bietet Ihnen eine saubere Chat-Oberfläche, Speicher und Mehrbenutzerunterstützung. Ein bisschen wie das Hosten Ihres eigenen privaten ChatGPT, aber ohne dass Ihre Daten den Pc verlassen.
Beide sind nicht gerade für Anfänger geeignet, aber wenn Sie gerne basteln, sind sie auf jeden Fall eine Erkundung wert.
Lesen Sie auch: 5 Möglichkeiten, LLMs lokal auf einem Pc auszuführen
Datenschutz, Sicherheit und das Gesamtbild
Der springende Punkt bei der lokalen Ausführung ist der Datenschutz.
Wenn Sie Cloud-LLMs verwenden, sind es Ihre Daten andernorts verarbeitet werden. Selbst wenn das Unternehmen verspricht, es nicht aufzubewahren, vertrauen Sie ihm dennoch.
Bei lokalen Modellen dreht sich diese Gleichung um. Alles bleibt auf Ihrem Gerät. Sie können Protokolle prüfen, in einer Sandbox ausführen und sogar den Netzwerkzugriff vollständig blockieren.
Das ist enorm für Menschen in regulierten Branchen oder einfach für jeden, der Wert auf Privatsphäre legt.
Und es geht nicht nur um Paranoia, es geht um Souveränität. Besitzen Sie Ihre Modellgewichte, Ihre Daten, Ihre Berechnungen; das ist mächtig.
Letzte Gedanken
Ich habe ein paar Instruments zum lokalen Ausführen von LLMs ausprobiert und ehrlich gesagt hat jedes seine eigene Ausstrahlung. Manche fühlen sich wie Motoren an, manche wie Armaturenbretter und manche wie persönliche Assistenten.
Hier ist eine kurze Momentaufnahme dessen, was mir aufgefallen ist:
| Werkzeug | Am besten für | Datenschutz / Offline | Benutzerfreundlichkeit | Besondere Kante |
| Ollama | Schnelle Einrichtung, Prototyping | Sehr stark, vollständig lokal, wenn Sie den Flugmodus umschalten | Tremendous einfach, CLI + optionale GUI | Leicht, effizient, API-fähig |
| LM Studio | Erkunden, Experimentieren, Benutzeroberfläche mit mehreren Modellen | Stark, größtenteils offline | Mäßig, GUI-lastig | Schöne Benutzeroberfläche, Schieberegler, Multi-Tab-Chat |
| Alles LLM | Verwendung eigener Dokumente, kontextbezogener Chat | Starke Offline-Einbettungen | Mittel, Backend-Einrichtung erforderlich | Verbindet LLM mit PDFs, Notizen und Wissensdatenbanken |
Die lokale Durchführung von LLMs ist kein nerdiges Experiment mehr, sondern praktisch, privat und überraschend unterhaltsam.
Ollama fühlt sich wie ein Arbeitstier an, LM Studio ist ein Spielplatz und AnythingLLM stellt tatsächlich die KI her nützlich mit Ihren eigenen Dateien. Lobende Erwähnungen wie llama.cpp oder Open WebUI füllen die Lücken für Bastler und Energy-Person.
Für mich geht es um das Mischen und Anpassen: Geschwindigkeit, Experimentierfreudigkeit und Nützlichkeit; Und das alles, während ich alles auf meinem eigenen Laptop computer behalte.
Das ist die Magie der lokalen KI im Jahr 2025: Kontrolle, Privatsphäre und die seltsame Befriedigung, einem Modell beim Denken zuzusehen … in Ihrer eigenen Maschine.
Sanad ist leitender KI-Wissenschaftler bei Analytics Vidhya und setzt modernste KI-Forschung in reale Agenten-KI-Produkte um. Mit einem MS in Künstlicher Intelligenz von der College of Edinburgh hat er in führenden Forschungslabors an mehrsprachigem NLP und NLP für ressourcenarme indische Sprachen gearbeitet. Er hat eine Leidenschaft für alles, was mit KI zu tun hat, und liebt es, die Lücke zwischen fundierter Forschung und praktischen, wirkungsvollen Produkten zu schließen.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.