
Wenn es darum geht, eine bessere KI aufzubauen, besteht die übliche Strategie darin, Modelle größer zu machen. Aber dieser Ansatz hat ein großes Downside: Er wird unglaublich teuer.
Aber Deepseek-V3.2-exp hat einen anderen Weg eingenommen …
Anstatt nur mehr Kraft hinzuzufügen, konzentrierten sie sich darauf, intelligenter zu arbeiten. Das Ergebnis ist eine neue Artwork von Modell, die eine erstklassige Leistung für einen Bruchteil der Kosten liefert. Durch die Einführung ihres „spärlichen Aufmerksamkeitsmechanismus“ wird Deepseek den Motor nicht nur optimiert. Es wird das Kraftstoffeinspritzsystem für beispiellose Effizienz neu gestaltet.
Lassen Sie uns genau so zusammenbrechen, wie sie es gemacht haben.
Highlights des Replace
- Spärliche Aufmerksamkeit hinzufügen: Der einzige architektonische Unterschied zwischen dem neuen V3.2 -Modell und seinem Vorgänger (V3.1) ist die Einführung von DSA. Dies zeigt, dass sie alle ihre Anstrengungen auf die Lösung des Effizienzproblems konzentriert haben.
- Ein „Blitzindexer“: DSA verwendet eine schnelle, leichte Komponente, die als Lightning Indexer bezeichnet wird. Dieser Indexer scannt schnell den Textual content und wählt nur die wichtigsten Wörter aus, auf die sich das Modell konzentrieren kann und den Relaxation ignoriert.
- Eine large Komplexitätsreduzierung: DSA verändert das Kernproblem von einem exponentiell schwierigen Rechenproblem
O(L²)zu einem viel einfacheren, linearenO(Lk). Dies ist das mathematische Geheimnis hinter den enormen Geschwindigkeits- und Kostenverbesserungen. - Erstellt für echte {Hardware}: Der Erfolg von DSA basiert auf einer hochoptimierten Software program, die perfekt für moderne KI -Chips (wie H800 -GPUs) betrieben wird. Diese enge Integration zwischen dem Good -Algorithmus und der {Hardware} liefert die endgültigen, dramatischen Gewinne.
Lesen Sie hier über das vorherige Replace: Deepseek-V3.1-terminus!
Deepseek spärliche Aufmerksamkeit (DSA)
Im Zentrum jedes LLM steht der „Aufmerksamkeits“ -Mechanismus: das System, das bestimmt, wie wichtig jedes Wort in einem Satz für jedes andere Wort ist.
Das Downside?
Die traditionelle „dichte“ Aufmerksamkeit ist wild ineffizient. Seine Rechenkosten skalen quadratisch (O(L²)), was bedeutet, dass die Verdoppelung der Textlänge die Berechnung und die Kosten verteilt.
Die Aufmerksamkeit von Deepseek (DSA) ist die Lösung für dieses Aufblähen. Es sieht nicht alles an; Es wählt clever aus, worauf Sie sich konzentrieren sollen. Das System besteht aus zwei wichtigen Teilen:
- Der Lightning Indexer: Dies ist ein leichter Hochgeschwindigkeits-Scanner. Für ein bestimmtes Wort (ein „Abfrage -Token“) bewertet es schnell alle vorhergehenden Wörter, um ihre Relevanz zu bestimmen. Entscheidend ist, dass dieser Indexer für Geschwindigkeit ausgelegt ist: Er verwendet eine kleine Anzahl von Köpfen und kann in FP8 -Präzision ausgeführt werden, wodurch der rechnerische Fußabdruck bemerkenswert klein ist.
- Feinkörnige Token-Auswahl: Sobald der Indexer alles bewertet hat, holt DSA nicht nur Textblöcke. Es führt eine genaue „feinkörnige“ Auswahl aus, die nur die am besten relevanten Token aus dem gesamten Dokument zuspuckt. Der Hauptaufmerksamkeitsmechanismus verarbeitet dann nur diesen sorgfältig ausgewählten, spärlichen Satz.
Das Ergebnis: DSA reduziert die Kernaufmerksamkeitskomplexität aus O(L²) Zu O(Lk)Wo okay ist eine feste Anzahl ausgewählter Token. Dies ist die mathematische Grundlage für die massiven Effizienzgewinne. Während der Blitzindexer selbst noch hat O(L²) Komplexität, es ist so leicht, dass der Nettoeffekt immer noch eine dramatische Verringerung der Gesamtberechnung ist.
Die Trainingspipeline: eine zweistufige Melodie
Sie können nicht einfach einen neuen Aufmerksamkeitsmechanismus auf ein Milliarden-Parameter-Modell schlagen und hoffen, dass es funktioniert. Deepseek verwendete einen akribischen zweistufigen Schulungsprozess, um DSA nahtlos zu integrieren.
- Stufe 1: Fortsetzung vor dem Coaching (das Aufwärmen)
- Dichter Aufwärmen (2,1B-Token): Ab dem Checkpoint V3.1-terminus „erwärmt“ Deepseek den neuen Lightning Indexer zuerst. Sie hielten das Hauptmodell gefroren und leiteten eine kurze Trainingsphase, in der der Indexer lernte, die Ausgabe des vollständigen, dichten Aufmerksamkeitsmechanismus vorherzusagen. Dies stimmte den neuen Indexer mit dem vorhandenen Wissen des Modells aus.
- Spärliches Coaching (943,7B -Token): Hier ist die wahre Magie passiert. Nach dem Aufwärmen schaltete Deepseek die volle spärliche Aufmerksamkeit ein und wählte für jede Abfrage die High 2048-Schlüsselwert-Token. Zum ersten Mal wurde das gesamte Modell geschult, um mit dieser neuen, selektiven Imaginative and prescient zu arbeiten und zu lernen, sich auf die spärliche Auswahl und nicht auf das dichte Ganze zu verlassen.
- Stufe 2: Nach der Schulung (die Abschlussschule)
Um einen fairen Vergleich zu gewährleisten, verwendete Deepseek die exakt gleiche Publish-Coaching-Pipeline wie v3.1-terminus. Dieser strenge Ansatz beweist, dass Leistungsunterschiede auf DSA und nicht auf Änderungen der Trainingsdaten zurückzuführen sind.- Spezialist Destillation: Sie erstellten fünf Powerhouse-Spezialmodelle (für Mathematik, Codierung, Argumentation, Agentencodierung und Agentensuche) mithilfe von Hochleistungsverstärkungslernen. Das Wissen dieser Experten wurde dann in das endgültige V3.2 -Modell destilliert.
- Gemischte RL mit GRPO: Anstelle eines mehrstufigen Prozesss verwendeten sie Relative Relativoptimierung der Gruppe (GRPO) In einer einzigen, gemischten Stufe. Die Belohnungsfunktion wurde sorgfältig entwickelt, um wichtige Kompromisse in Einklang zu bringen:
- Länge vs. Genauigkeit: Unnötig lange Antworten bestrafen.
- Sprachkonsistenz vs. Genauigkeit: Die Gewährleistung der Reaktionen blieb kohärent und menschlich.
- Regelbasierte und auf Rubrik basierende Belohnungen: Verwenden automatisierter Schecks für Begründung/Agentenaufgaben und maßgeschneiderte Rubriken für allgemeine Aufgaben.
Die {Hardware} Secret Sauce: Optimierte Kerne
Ein brillanter Algorithmus ist nutzlos, wenn er langsam auf der tatsächlichen {Hardware} ausgeführt wird. Deepseeks Engagement für die Effizienz scheint hier mit tief optimiertem Open-Supply-Code.
Das Modell nutzt spezialisierte Kerne wie FlashMLA, die maßgeschneidert sind, um die komplexen MLA- und DSA-Operationen mit extremer Effizienz des modernen Hopper-GPUs (wie dem H800) auszuführen. Diese Optimierungen sind in Pull-Anfragen an Repositories wie Deepgemm, FlashMLA und Tilelang öffentlich verfügbar, sodass das Modell nahezu theoretische Spitzenspeicherbandbreite (bis zu 3000 GB/s) erreicht und die Leistung berechnete. Dieses hardwarebewusste Design verwandelt die theoretische Effizienz von DSA in materielle, reale Geschwindigkeit.
Leistung & Kosten – ein neues Guthaben
Additionally, was ist das endgültige Ergebnis dieses technischen Wunders? Die Daten zeigen eine klare und überzeugende Geschichte.
Kostensenkung
Der unmittelbarste Aufprall ist unter dem Strich. Deepseek kündigte eine 50% ige Verringerung der API -Preisgestaltung an. Die technischen Benchmarks sind noch auffälliger:
- Inferenzgeschwindigkeit: 2–3x schneller in langen Kontexten.
- Speicherverbrauch: 30–40% niedriger.
- Trainingseffizienz: 50% schneller.
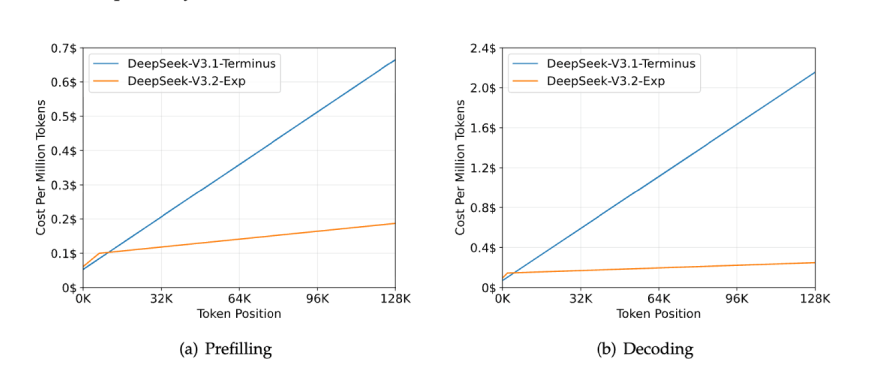
Die realen Inferenzkosten für die Dekodierung eines Kontextfensters von 128.000 sinken auf geschätzte 0,25 USD im Vergleich zu $ 2,20 für dichte Aufmerksamkeit, um es 10x billiger zu machen.
Bessere Leistung
Insgesamt behält V3.2-exp die Leistungsparität mit seinem Vorgänger bei. Ein genauerer Blick zeigt jedoch einen logischen Kompromiss:
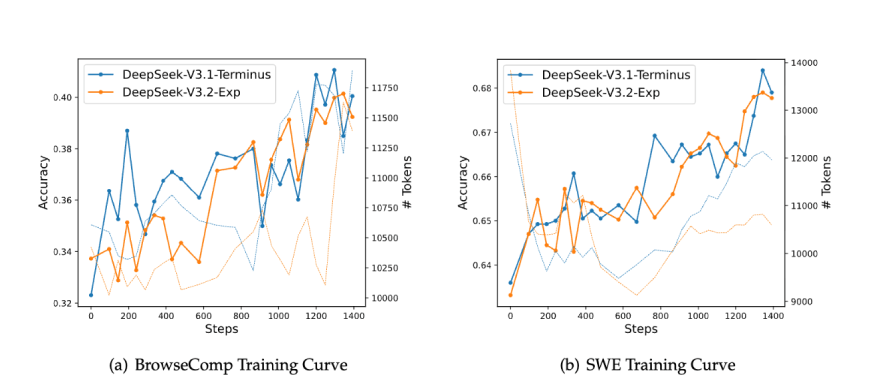
- Die Siege: Das Modell zeigt signifikante Gewinne bei Codierung (Codeforces) und agentenaufgaben (BrowsComp). Dies ist vollkommen sinnvoll: Code und Werkzeugnutzung enthalten häufig redundante Informationen, und die Fähigkeit der DSA, Rauschen zu filtern, ist ein direkter Vorteil.
- Die Kompromisse: Es gibt kleinere Regressionen in einigen ultra-komplexen, abstrakten Argumentationsbenchmarks (wie GPQA Diamond und HMMT). Die Hypothese ist, dass diese Aufgaben darauf angewiesen sind, sehr subtile langfristige Abhängigkeiten zu verbinden, die die aktuelle DSA-Maske gelegentlich vermissen könnte.
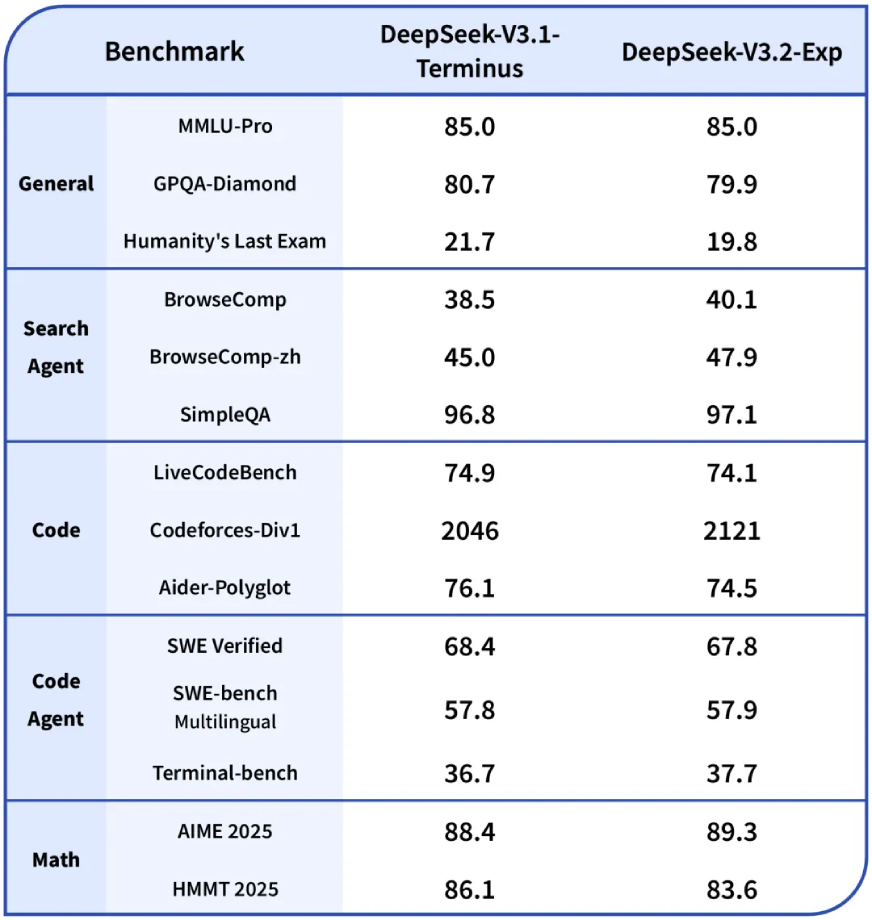
Deepseek-V3.1-terminus gegen Deepseek-V3.2-exp
Probieren wir den neuen Deepseek-V3.2-Exp aus
Die Aufgaben, die ich hier machen werde, werden gleich sein wie in einem unserer vorherigen Artikel über Deepseek-v3.1-terminus. Dies wird dazu beitragen, zu erkennen, wie das neue Replace besser ist.
Aufgabe 1: Reiseplan
Mitte November muss ich eine 7-tägige Reise nach Kyoto, Japan, planen. Die Reiseroute sollte sich auf die traditionelle Kultur konzentrieren, einschließlich Tempel, Gärten und Teezeremonien. Finden Sie die beste Zeit, um die Herbstblätter zu sehen, eine Liste von drei Should-Besuchs-Tempeln für ‚Momiji‘ (Herbstblätter) und ein hoch bewertetes traditionelles Teehaus mit englischfreundlichen Diensten. Finden Sie auch einen intestine bewerteten Ryokan (traditionelles japanisches Gasthaus) im Distrikt Gion. Organisieren Sie alle Informationen in eine klare, tägliche Reiseroute.
Ausgabe:

Sie können die vollständige Ausgabe hier anzeigen.
Deepseek-V3.1-Terminus gegen Deepseek-V3.2-Exp-Ausgangsvergleich
| Besonderheit | Deepseek-v3.1-terminus | Deepseek-V3.2-exp | Gewinner |
|---|---|---|---|
| Struktur & Organisation | Einzelabsatz | Intestine strukturiert mit klaren Abschnitten und Kugelpunkten | V3.2-exp |
| Befehlspräsentation | Befehle, die in den laufenden Textual content eingebettet sind | Dedizierte Codeblöcke mit ordnungsgemäßer Formatierung | V3.2-exp |
| Vollständigkeit und Tiefe | Nur grundlegende Erklärung | Beinhaltet praktische Beispiele und Anwendungsfälle | V3.2-exp |
| Anfänger Freundlichkeit | Nimmt Vorkenntnisse an | Erklärt Konzepte klar für Neuankömmlinge | V3.2-exp |
Aufgabe 2: Codierungsagent
Ich brauche ein Python-Skript, das eine öffentliche Liste der 100 besten Filme aller Zeiten von einer Web site abkratzt (Sie können eine zuverlässige Quelle wie IMDB, Rotten Tomaten oder eine bekannte Zeitschriftenliste auswählen). Das Drehbuch sollte dann die Filmtitel, die Veröffentlichung von Jahren und eine kurze Beschreibung für jeden Movie in eine JSON -Datei speichern. Fügen Sie Fehlerbehandlungen für Netzwerkprobleme oder Änderungen in der Struktur der Web site hinzu. Können Sie das vollständige Skript generieren und jeden Schritt des Prozesses erläutern?
Ausgabe:
class IMDbTop100Scraper:
def __init__(self):
self.base_url = "https://www.imdb.com/chart/prime"
self.headers = {
'Consumer-Agent': 'Mozilla/5.0 (Home windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
self.films = ()
def fetch_page(self, url: str) -> Non-compulsory(BeautifulSoup):
"""
Fetch the webpage and return BeautifulSoup object.
Handles community errors and retries.
"""
strive:
response = requests.get(url, headers=self.headers, timeout=10)
response.raise_for_status() # Raises an HTTPError for dangerous responses
# Verify if we bought a sound HTML response
if 'textual content/html' not in response.headers.get('content-type', ''):
increase ValueError("Acquired non-HTML response")
return BeautifulSoup(response.content material, 'html.parser')
besides requests.exceptions.RequestException as e:
print(f"Community error occurred: {e}")
return None
besides Exception as e:
print(f"Surprising error whereas fetching web page: {e}")
return None
def parse_movie_list(self, soup: BeautifulSoup) -> Listing(Dict):
"""
Parse the primary film checklist web page to extract titles and years.
"""
films = ()
strive:
# IMDb's prime chart construction - this selector would possibly want updating
movie_elements = soup.choose('li.ipc-metadata-list-summary-item')
if not movie_elements:
# Different selector if the first one fails
movie_elements = soup.choose('.cli-children')
if not movie_elements:
increase ValueError("Couldn't discover film components on the web page")
for factor in movie_elements(:100): # Restrict to prime 100
movie_data = self.extract_movie_data(factor)
if movie_data:
films.append(movie_data)
besides Exception as e:
print(f"Error parsing film checklist: {e}")
return filmsHier finden Sie den vollständigen Code.
Deepseek-V3.1-Terminus gegen Deepseek-V3.2-Exp-Ausgangsvergleich
| Besonderheit | Deepseek-v3.1-terminus | Deepseek-V3.2-exp | Gewinner |
|---|---|---|---|
| Struktur und Präsentation | Einzelabsatz | Klare Überschriften, Kugelpunkte, Zusammenfassungstabelle | V3.2-exp |
| Sicherheits- und Benutzeranleitung | Keine Sicherheitswarnungen | Mutige Warnung über nicht gestaltete Veränderungen Verlust | V3.2-exp |
| Vollständigkeit und Kontext | Nur grundlegende zwei Methoden | Fügt das Legacy -Git Checkout` -Methode und Zusammenfassungstabelle hinzu | V3.2-exp |
| Aktionsfähigkeit | Befehle, die in Textual content eingebettet sind | Dedizierte Befehlsblöcke mit expliziten Flaggenerklärungen | V3.2-exp |
Lesen Sie auch: Evolution von Deepseek: Wie es zu einem globalen KI-Recreation-Changer wurde!
Abschluss
Deepseek-V3.2-exp ist mehr als ein Modell; Es ist eine Aussage. Es beweist, dass der nächste große Sprung in der KI nicht unbedingt ein Sprung in der Rohleistung sein wird, sondern ein Effizienzsprung. Deepseek hat den rechnerischen Abfall in traditionellen Transformatoren chirurgisch angreift, und hat längst kontextierte, hochvolumige KI-Anwendungen für einen viel breiteren Markt finanziell rentabel gemacht.
Das „experimentelle“ Tag ist ein offener Eingeständnis, dass dies eine laufende Arbeit ist, insbesondere bei der Ausgleich der Leistung über alle Aufgaben. Für die überwiegende Mehrheit der Anwendungsfälle für Unternehmen, in denen die Verarbeitung ganzer Codebasen, rechtlicher Dokumente und Datensätze das Ziel ist. Deepseek hat nicht nur ein neues Modell veröffentlicht. Es hat ein neues Rennen begonnen.
Um mehr über das Modell zu erfahren, überprüfen Sie dies Hyperlink.
Hallo, ich bin Nitika, ein technisch versierter Content material-Ersteller und Vermarkter. Kreativität und neue Dinge lernen natürlich für mich. Ich habe Fachkenntnisse bei der Erstellung von ergebnisgesteuerten Inhaltsstrategien. Ich bin mit search engine marketing -Administration, Key phrase -Operationen, Webinhalten, Kommunikation, Inhaltsstrategie, Bearbeitung und Schreiben intestine vertraut.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.