
Bild vom Autor
In Python sind Zeichenfolgen unveränderliche Zeichenfolgen, die für Menschen lesbar sind und normalerweise in einer bestimmten Zeichenkodierung wie UTF-8 kodiert sind. Während Bytes rohe Binärdaten darstellen. Ein Byte-Objekt ist unveränderlich und besteht aus einem Array von Bytes (8-Bit-Werten). In Python 3 sind Zeichenfolgenliterale standardmäßig Unicode, während Byteliterale mit einem b.
Das Konvertieren von Bytes in Zeichenfolgen ist eine häufige Aufgabe in Python, insbesondere beim Arbeiten mit Daten aus Netzwerkvorgängen, Datei-E/A oder Antworten von bestimmten APIs. Dies ist ein Tutorial zum Konvertieren von Bytes in Zeichenfolgen in Python.
1. Konvertieren Sie Bytes mit der Methode decode() in Zeichenfolgen
Der einfachste Weg, Bytes in einen String umzuwandeln, ist die Verwendung des decode() Methode auf dem Byte-Objekt (oder der Byte-Zeichenfolge). Diese Methode erfordert die Angabe der verwendeten Zeichenkodierung.
Notiz: Strings haben keine zugehörige Binärkodierung und Bytes haben keine zugehörige Textkodierung. Um Bytes in Strings umzuwandeln, können Sie den
decode()Methode auf dem Bytes-Objekt. Und um Strings in Bytes umzuwandeln, können Sie dieencode()Methode auf die Zeichenfolge. Geben Sie in beiden Fällen die zu verwendende Kodierung an.
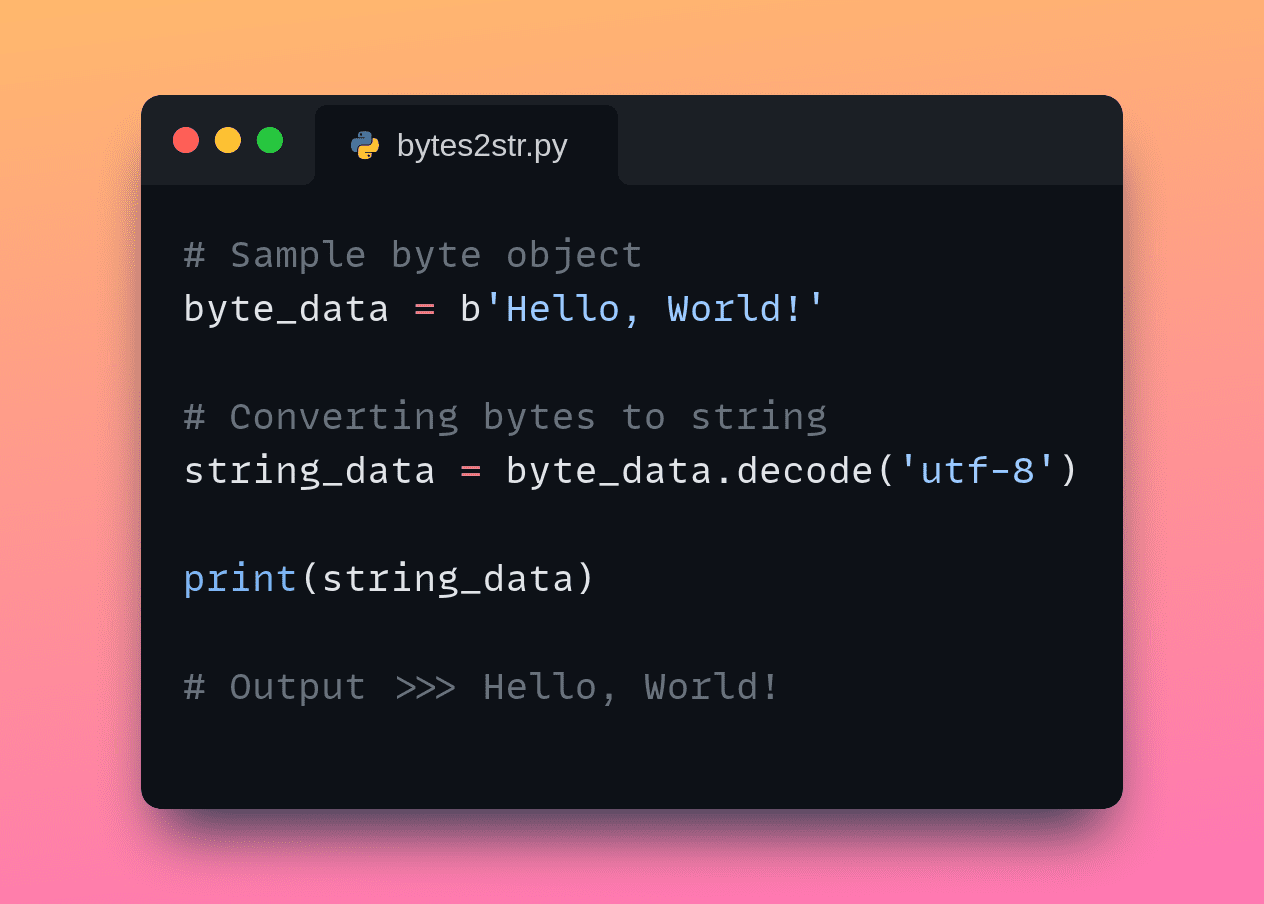
Beispiel 1: UTF-8-Kodierung
Hier konvertieren wir byte_data in einen UTF-8-kodierten String mit dem decode() Methode:
# Pattern byte object
byte_data = b'Whats up, World!'
# Changing bytes to string
string_data = byte_data.decode('utf-8')
print(string_data) Sie sollten die folgende Ausgabe erhalten:
Sie können die Datentypen vor und nach der Konvertierung wie folgt überprüfen:
print(sort(bytes_data))
print(sort(string_data))
Die Datentypen sollten wie erwartet sein:
Output >>>
<class 'bytes'>
<class 'str'>Beispiel 2: Umgang mit anderen Kodierungen
Manchmal kann die Bytefolge andere Kodierungen als UTF-8 enthalten. Sie können dies umgehen, indem Sie das entsprechende Kodierungsschema angeben, das beim Aufruf des decode() Methode für das Byteobjekt.
So können Sie eine Bytefolge mit UTF-16-Kodierung dekodieren:
# Pattern byte object
byte_data_utf16 = b'xffxfeHx00ex00lx00lx00ox00,x00 x00Wx00ox00rx00lx00dx00!x00'
# Changing bytes to string
string_data_utf16 = byte_data_utf16.decode('utf-16')
print(string_data_utf16)
Und hier ist die Ausgabe:
Verwenden von Chardet zum Erkennen von Kodierungen
In der Praxis ist Ihnen das verwendete Kodierungsschema möglicherweise nicht immer bekannt. Und nicht übereinstimmende Kodierungen können zu Fehlern oder verstümmeltem Textual content führen. Wie können Sie dieses Downside additionally umgehen?
Du kannst den … benutzen Chardet-Bibliothek (Chardet mit Pip installieren: pip set up chardet), um die Kodierung zu erkennen. Und verwenden Sie sie dann im Methodenaufruf `decode()`. Hier ist ein Beispiel:
import chardet
# Pattern byte object with unknown encoding
byte_data_unknown = b'xe4xbdxa0xe5xa5xbd'
# Detecting the encoding
detected_encoding = chardet.detect(byte_data_unknown)
encoding = detected_encoding('encoding')
print(encoding)
# Changing bytes to string utilizing detected encoding
string_data_unknown = byte_data_unknown.decode(encoding)
print(string_data_unknown)
Sie sollten eine ähnliche Ausgabe erhalten:
Fehlerbehandlung bei der Dekodierung
Der bytes Das Objekt, mit dem Sie arbeiten, ist möglicherweise nicht immer gültig. Es kann manchmal ungültige Sequenzen für die angegebene Kodierung enthalten. Dies führt zu Fehlern.
Hier, byte_data_invalid
enthält die ungültige Sequenz xff:
# Pattern byte object with invalid sequence for UTF-8
byte_data_invalid = b'Whats up, World!xff'
# strive changing bytes to string
string_data = byte_data_invalid.decode('utf-8')
print(string_data)
Beim Versuch, es zu dekodieren, wird die folgende Fehlermeldung angezeigt:
Traceback (most up-to-date name final):
File "/residence/balapriya/bytes2str/foremost.py", line 5, in
string_data = byte_data_invalid.decode('utf-8')
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
UnicodeDecodeError: 'utf-8' codec cannot decode byte 0xff in place 13: invalid begin byte
Es gibt jedoch mehrere Möglichkeiten, mit diesen Fehlern umzugehen. Sie können solche Fehler beim Dekodieren ignorieren oder ungültige Sequenzen durch einen Platzhalter ersetzen.
Fehler ignorieren
Um ungültige Sequenzen beim Dekodieren zu ignorieren, können Sie die Fehler festlegen, die Sie festlegen können errors Zu ignore im decode() Methodenaufruf:
# Pattern byte object with invalid sequence for UTF-8
byte_data_invalid = b'Whats up, World!xff'
# Changing bytes to string whereas ignoring errors
string_data = byte_data_invalid.decode('utf-8', errors="ignore")
print(string_data)
Sie erhalten nun die folgende Ausgabe ohne Fehler:
Ersetzen von Fehlern
Sie können ungültige Sequenzen auch durch den Platzhalter ersetzen. Dazu können Sie errors Zu substitute wie gezeigt:
# Pattern byte object with invalid sequence for UTF-8
byte_data_invalid = b'Whats up, World!xff'
# Changing bytes to string whereas changing errors with a placeholder
string_data_replace = byte_data_invalid.decode('utf-8', errors="substitute")
print(string_data_replace)
Nun wird die ungültige Sequenz (am Ende) durch einen Platzhalter ersetzt:
Output >>>
Whats up, World!�
2. Konvertieren Sie Bytes mit dem str()-Konstruktor in Zeichenfolgen
Der decode() Methode ist die häufigste Methode, um Bytes in Strings umzuwandeln. Sie können aber auch die str() Konstruktor, um einen String aus einem Bytes-Objekt zu erhalten. Sie können das Kodierungsschema übergeben an str() etwa so:
# Pattern byte object
byte_data = b'Whats up, World!'
# Changing bytes to string
string_data = str(byte_data,'utf-8')
print(string_data)
Dies gibt aus:
3. Konvertieren Sie Bytes mit dem Codecs-Modul in Zeichenfolgen
Eine weitere Methode zum Konvertieren von Bytes in Zeichenfolgen in Python ist die Verwendung von decode() Funktion aus dem eingebauten Codecs Modul. Dieses Modul bietet Komfortfunktionen zum Kodieren und Dekodieren.
Sie erreichen uns unter decode() Funktion mit dem Bytes-Objekt und dem Kodierungsschema wie gezeigt:
import codecs
# Pattern byte object
byte_data = b'Whats up, World!'
# Changing bytes to string
string_data = codecs.decode(byte_data,'utf-8')
print(string_data)
Wie erwartet wird auch Folgendes ausgegeben:
Zusammenfassung
In diesem Tutorial haben wir gelernt, wie man in Python Bytes in Zeichenfolgen umwandelt und dabei auch verschiedene Kodierungen und potenzielle Fehler problemlos handhabt. Insbesondere haben wir Folgendes gelernt:
- Verwenden Sie die
decode()Methode zum Konvertieren von Bytes in eine Zeichenfolge unter Angabe der richtigen Kodierung. - Behandeln Sie potenzielle Decodierungsfehler mit dem
errorsParameter mit Optionen wieignoreodersubstitute. - Verwenden Sie die
str()Konstruktor zum Konvertieren eines gültigen Byteobjekts in eine Zeichenfolge. - Verwenden Sie die
decode()Funktion aus demcodecsModul, das in die Python-Standardbibliothek integriert ist, um ein gültiges Byteobjekt in eine Zeichenfolge zu konvertieren.
Viel Spaß beim Programmieren!
Bala Priya C ist Entwicklerin und technische Redakteurin aus Indien. Sie arbeitet gerne an der Schnittstelle zwischen Mathematik, Programmierung, Datenwissenschaft und Inhaltserstellung. Ihre Interessens- und Fachgebiete umfassen DevOps, Datenwissenschaft und natürliche Sprachverarbeitung. Sie liest, schreibt, programmiert und trinkt gerne Kaffee! Derzeit arbeitet sie daran, ihr Wissen zu lernen und mit der Entwickler-Neighborhood zu teilen, indem sie Tutorials, Anleitungen, Meinungsbeiträge und mehr verfasst. Bala erstellt auch ansprechende Ressourcenübersichten und Programmier-Tutorials.