
SQL ist die Sprache der Daten; Allerdings kennt jeder, der einige Zeit damit verbracht hat, Abfragen zu schreiben, den Schmerz. Sich die genaue Syntax für Fensterfunktionen, Multi-Desk-Joins und das Debuggen kryptischer SQL-Fehler zu merken, kann mühsam und zeitaufwändig sein. Um einfache Antworten zu erhalten, ist für technisch nicht versierte Benutzer häufig die Hinzuziehung eines Datenanalysten erforderlich. Große Sprachmodelle (LLMs) beginnen, diese State of affairs zu ändern. Als Copiloten können LLMs menschliche Anweisungen aufnehmen und in SQL-Abfragen umwandeln, Menschen komplexe SQL-Abfragen erklären und Optimierungen für schnellere Berechnungen vorschlagen. Die Ergebnisse sind eindeutig: schnellere Iterationen, geringere Hürden für technisch nicht versierte Benutzer und weniger Zeitverschwendung bei der Prüfung der Syntax.
Warum LLMs für SQL sinnvoll sind
LLMs zeichnen sich durch die Abbildung natürlicher Sprachen in strukturierten Texten aus. SQL ist im Wesentlichen strukturierter Textual content mit klar definierten Mustern. Einen LLM fragen „Finden Sie die fünf meistverkauften Produkte des letzten Quartals.” und es kann eine Abfrage erstellen mit GROUP BY (für verschiedene Kanäle), ORDER BYUnd LIMIT (um die Prime 5 zu erhalten) Klauseln.
Zusätzlich zum Entwerfen von Abfragen können LLMs als nützliche Debugging-Companion fungieren. Wenn eine Abfrage fehlschlägt, kann sie den Fehler zusammenfassen, die Fehler in Ihrer Eingabe-SQL erkennen und verschiedene Lösungen zur Behebung empfehlen. Sie können auch effizientere Alternativen vorschlagen, um die Rechenzeit zu verkürzen und die Effizienz zu steigern. Sie können SQL-Probleme zum besseren Verständnis auch in einfaches Englisch übersetzen.
Alltägliche Anwendungsfälle
Der offensichtlichste Anwendungsfall ist die natürliche Sprache für SQL, die es jedem ermöglicht, eine Geschäftsanforderung auszudrücken und einen Abfrageentwurf zu erhalten. Aber es gibt noch viele andere. Ein Analyst kann einen Fehlercode einfügen und LLM kann bei der Fehlerbehebung helfen. Derselbe Analyst kann die Erkenntnisse über die richtigen Eingabeaufforderungen zur genauen Fehlerbehebung des Fehlers weitergeben und diese mit anderen Teammitgliedern teilen, um Zeit zu sparen. Neulinge können sich auf den Copiloten verlassen, um SQL in natürliche Sprache zu übersetzen. Mit dem richtigen Schemakontext können LLMs Abfragen generieren, die auf die tatsächlichen Datenbankstrukturen der Organisation zugeschnitten sind, wodurch sie wesentlich leistungsfähiger sind als generische Syntaxgeneratoren.
Mehr lesen: Natürliche Sprache für SQL-Anwendungen
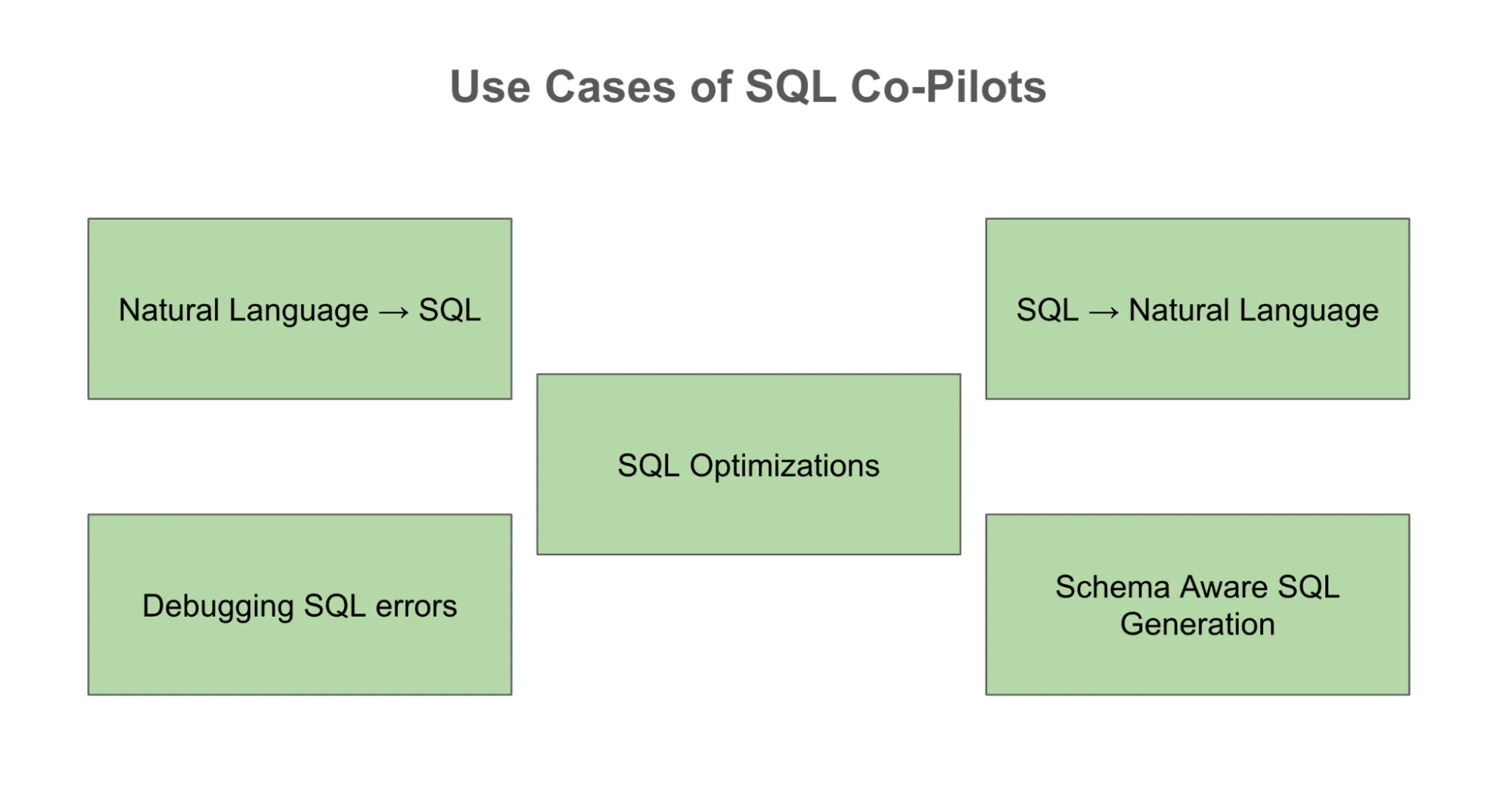
Copilot, kein Autopilot
Trotz all ihrer Versprechen weisen LLMs auch einige bekannte Einschränkungen auf. Die bekanntesten sind Spaltenhalluzinationen und die Generierung zufälliger Tabellennamen, wenn diese nicht angegeben werden. Ohne einen korrekten Schemakontext ist es wahrscheinlich, dass LLM auf Annahmen zurückgreift und etwas falsch macht. Die von LLMs generierten Abfragen können ausgeführt werden, sind jedoch nicht effizient, was zu höheren Kosten und langsameren Ausführungszeiten führt. Zusätzlich zu all diesen Problemen besteht ein offensichtliches Sicherheitsrisiko, da wise interne Schemata mit externen APIs geteilt würden.
Die Schlussfolgerung ist sehr einfach: LLMs sollten als Kopiloten behandelt werden, anstatt vollständig von ihnen abhängig zu sein. Sie können bei der Ausarbeitung und Beschleunigung von Arbeiten helfen, für die Validierung vor der Ausführung ist jedoch menschliches Eingreifen erforderlich.
Verbesserung der LLM-Ergebnisse durch schnelles Engineering
Prompte Technik ist eine der wichtigsten Fähigkeiten, um den effektiven Einsatz von LLMs zu erlernen. Für SQL-Copiloten ist die Eingabeaufforderung ein zentraler Hebel, da vage Eingabeaufforderungen häufig zu unvollständigen, falschen und manchmal sinnlosen Abfragen führen können. Mit dem richtigen Schemakontext, den richtigen Tabellenspalteninformationen und der richtigen Beschreibung kann die Qualität der Ausgabeabfrage erheblich steigen.
Neben Datenschemainformationen ist auch der SQL-Dialekt wichtig. Alle SQL-Dialekte wie Postgres, BigQuery und Presto weisen kleine Unterschiede auf, und die Erwähnung des SQL-Dialekts gegenüber dem LLM hilft, Syntaxkonflikte zu vermeiden. Es ist auch wichtig, detailliert über die Ausgabe zu sprechen, z. B. durch Angabe des Datumsbereichs, der Prime-N-Benutzer usw., um falsche Ergebnisse und unnötige Datenscans (die zu teuren Abfragen führen können) zu vermeiden.
Meiner Erfahrung nach funktioniert bei komplexen Abfragen die iterative Eingabeaufforderung am besten. Am besten funktioniert es, wenn man den LLM bittet, zunächst eine einfache Abfragestruktur aufzubauen und diese dann Schritt für Schritt zu verfeinern. Sie können das LLM auch verwenden, um seine Logik zu erklären, bevor Sie die endgültige SQL erhalten. Dies ist nützlich zum Debuggen und um dem LLM beizubringen, sich auf die richtigen Themen zu konzentrieren. Sie können verwenden Eingabeaufforderung für wenige Schüssewobei Sie dem LLM eine Beispielabfrage zeigen, bevor Sie es auffordern, eine neue zu generieren, damit es mehr Kontext hat. Schließlich hilft die fehlergesteuerte Eingabeaufforderung dem Endbenutzer, die Fehlermeldung zu debuggen und eine Lösung zu finden. Diese Aufforderungsstrategien machen den Unterschied zwischen Abfragen, die „quick korrekt“ sind, und solchen, die tatsächlich ausgeführt werden.
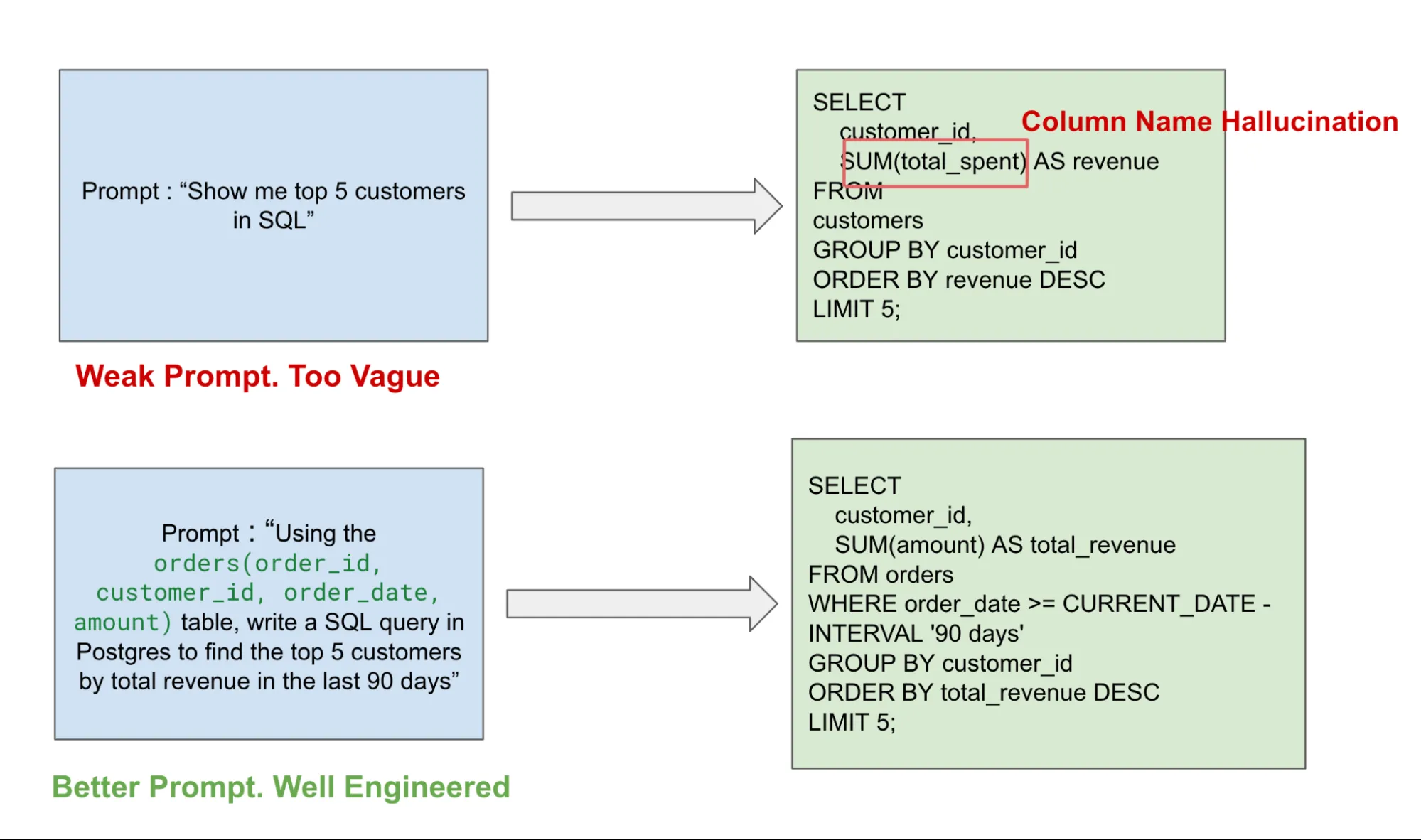
Sie können dies im Beispiel unten sehen, wo eine vage Eingabeaufforderung zu einer Halluzination des Spaltennamens führt. Im Vergleich zu einer ausgereiften und detaillierteren Eingabeaufforderung erhalten Sie eine klar definierte Abfrage, die dem erforderlichen SQL-Dialekt entspricht, ohne dass es zu Halluzinationen kommt.
Greatest Practices für LLMs als SQL-Copiloten
Es gibt einige Greatest Practices, die man bei der Verwendung eines SQL Copiloten befolgen kann. Es empfiehlt sich immer, die Abfrage vor der Ausführung manuell zu überprüfen, insbesondere in einer Produktionsumgebung. Sie sollten LLM-Ausgaben als Entwürfe und nicht als tatsächliche Ausgabe behandeln. Zweitens ist die Integration von entscheidender Bedeutung, da ein in die vorhandene IDE, Notebooks usw. des Unternehmens integrierter Copilot diese benutzerfreundlicher und effektiver macht.

Leitplanken und Risiken
SQL Copilots können enorme Produktivitätssteigerungen mit sich bringen, es gibt jedoch einige Risiken, die wir berücksichtigen sollten, bevor wir sie unternehmensweit einführen. Erstens besteht die Sorge darin, dass man sich zu sehr darauf verlässt. Copiloten können dazu führen, dass sich Datenanalysten stark darauf verlassen und nie grundlegende SQL-Kenntnisse aufbauen. Dies kann zu potenziellen Kompetenzlücken führen, da Groups SQL-Eingabeaufforderungen erstellen, diese aber nicht beheben können.
Ein weiteres Downside betrifft die Datenverwaltung. Wir müssen sicherstellen, dass Copiloten keine sensiblen Daten ohne entsprechende Berechtigungen an Benutzer weitergeben, um so Immediate-Injection-Angriffe zu verhindern. Unternehmen müssen die richtige Knowledge-Governance-Ebene aufbauen, um Informationslecks zu verhindern. Schließlich gibt es auch Kostenauswirkungen, da häufige API-Aufrufe an Copiloten dazu führen können, dass sich die Kosten schnell summieren. Ohne korrekte Nutzungs- und Token-Richtlinien kann dies zu Budgetproblemen führen.
Bewertungsmetriken für den Copilot-Erfolg
Eine wichtige Frage bei der Investition in LLMs für SQL-Copiloten ist: Woher wissen Sie, dass sie funktionieren? Es gibt mehrere Dimensionen, anhand derer Sie die Effektivität von Copiloten messen können, z. B. Korrektheit, menschliche Eingriffsrate, Zeitersparnis und Reduzierung sich wiederholender Supportanfragen. Korrektheit ist eine wichtige Metrik, um festzustellen, ob SQL Copilot in Fällen, in denen SQL Copilot eine Abfrage bereitstellt, die fehlerfrei ausgeführt wird, das richtige erwartete Ergebnis liefert. Dies kann erreicht werden, indem eine Stichprobe der an Copilot übermittelten Eingaben genommen wird und Analysten dieselbe Abfrage entwerfen lassen, um die Ausgaben zu vergleichen. Dies trägt nicht nur zur Validierung der Copilot-Ergebnisse bei, sondern kann auch zur Verbesserung der Eingabeaufforderungen für mehr Genauigkeit verwendet werden. Darüber hinaus erhalten Sie in dieser Übung auch die geschätzte eingesparte Zeit professional Abfrage und können so die Produktivitätssteigerung quantifizieren.
Eine weitere einfach zu berücksichtigende Metrik ist der Prozentsatz der generierten Abfragen, die ohne menschliche Bearbeitung ausgeführt werden. Wenn Copilot konsistent funktionierende, ausführbare Abfragen erstellt, sparen sie eindeutig Zeit. Eine weniger offensichtliche, aber wirksame Maßnahme wäre die Reduzierung wiederholter Supportanfragen von nichttechnischem Private. Wenn Geschäftsteams mehr ihrer Fragen mit Copiloten selbst beantworten können, können Datenteams weniger Zeit mit der Beantwortung grundlegender SQL-Anfragen verbringen und sich mehr auf qualitativ hochwertige Erkenntnisse und die strategische Ausrichtung konzentrieren.
Der Weg voraus
Das Potenzial hier ist sehr spannend. Stellen Sie sich Copiloten vor, die Ihnen beim gesamten Finish-to-Finish-Prozess helfen können: Schema-fähige SQL-Generierung, integriert in einen Datenkatalog, in der Lage, Dashboards oder Visualisierungen zu erstellen. Darüber hinaus können Copiloten aus den vergangenen Anfragen Ihres Groups lernen, um ihren Stil und ihre Geschäftslogik anzupassen. Die Zukunft von SQL besteht nicht darin, es zu ersetzen, sondern darin, die Reibungsverluste zu beseitigen und so die Effizienz zu steigern.
SQL ist immer noch das Rückgrat des Datenstapels; Wenn LLMs als Copiloten arbeiten, wird dies zugänglicher und produktiver. Die Zeitspanne zwischen dem Stellen einer Frage und dem Erhalten einer Antwort wird sich drastisch verkürzen. Dadurch haben Analysten weniger Zeit damit, sich mit Syntaxen herumzuschlagen und zu googeln, und haben mehr Zeit für die Entwicklung von Erkenntnissen. Bei klugem Einsatz, sorgfältiger Anleitung und menschlicher Aufsicht sind LLMs auf dem besten Weg, ein Standardbestandteil des Werkzeugkastens des Datenprofis zu werden.
Häufig gestellte Fragen
A. Sie wandeln natürliche Sprache in SQL um, erklären komplexe Abfragen, beheben Fehler und schlagen Optimierungen vor – und helfen so sowohl technisch versierten als auch nichttechnischen Benutzern, schneller mit Daten zu arbeiten.
A. Weil LLMs Spalten halluzinieren oder Schemaannahmen treffen können. Eine menschliche Überprüfung ist für die Gewährleistung von Genauigkeit, Effizienz und Datensicherheit unerlässlich.
A. Durch die Bereitstellung eines klaren Schemakontexts, die Angabe von SQL-Dialekten und die iterative Verfeinerung von Abfragen. Detaillierte Eingabeaufforderungen reduzieren Halluzinationen und Syntaxfehler drastisch.
Madhura Raut ist Principal Knowledge Scientist bei Workday und leitet dort den Entwurf groß angelegter maschineller Lernsysteme für die Prognose der Arbeitsnachfrage. Sie ist die Haupterfinderin zweier US-Patente im Zusammenhang mit fortschrittlichen Zeitreihentechniken, und ihr ML-Produkt wurde von Human Useful resource Government als bestes HR-Produkt des Jahres ausgezeichnet. Madhura battle Hauptredner auf vielen renommierten Datenwissenschaftskonferenzen, darunter KDD 2025, und fungierte als Juror und Mentor bei mehreren Codecrunch-Hackathons.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.