

Bild vom Autor | DALLE-3
Es conflict schon immer mühsam, große Sprachmodelle zu trainieren. Selbst bei umfassender Unterstützung durch öffentliche Plattformen wie HuggingFace umfasst der Prozess die Einrichtung unterschiedlicher Skripte für jede Pipeline-Stufe. Von der Einrichtung von Daten für das Vortraining, die Feinabstimmung oder RLHF bis hin zur Konfiguration des Modells aus Quantisierung und LORAs erfordert das Coaching eines LLM mühsamen manuellen Aufwand und Optimierungen.
Die jüngste Veröffentlichung von Lama-Fabrik im Jahr 2024 zielt darauf ab, genau das Downside zu lösen. Das GitHub-Repository macht die Einrichtung des Modelltrainings für alle Phasen eines LLM-Lebenszyklus äußerst bequem. Von der Vorschulung über SFT bis hin zu RLHF bietet das Repository integrierte Unterstützung für die Einrichtung und Schulung aller neuesten verfügbaren LLMs.
Unterstützte Modelle und Datenformate
Das Repository unterstützt alle aktuellen Modelle, darunter unter anderem LLama, LLava, Mixtral Combination-of-Consultants, Qwen, Phi und Gemma. Die vollständige Liste finden Sie hier Hier. Es unterstützt Pretraining, SFT und wichtige RL-Techniken, einschließlich DPO, PPO und ORPO, und ermöglicht alle neuesten Methoden von der vollständigen Feinabstimmung bis zum Freeze-Tuning, LORAs, QLoras und Agent Tuning.
Darüber hinaus stellen sie auch Beispieldatensätze für jeden Trainingsschritt bereit. Die Beispieldatensätze folgen im Allgemeinen dem Alpaka-Vorlage obwohl die Sharegpt-Format wird ebenfalls unterstützt. Wir heben die Formatierung der Alpaca-Daten weiter unten hervor, um besser zu verstehen, wie Sie Ihre proprietären Daten einrichten.
Beachten Sie, dass Sie bei der Verwendung Ihrer Daten Informationen zu Ihrer Datendatei bearbeiten und hinzufügen müssen dataset_info.json Datei im Ordner Llama-Manufacturing facility/information.
Daten vor dem Coaching
Die bereitgestellten Daten werden in einer JSON-Datei gespeichert und nur die Textspalte wird zum Coaching des LLM verwendet. Die Daten müssen im unten angegebenen Format vorliegen, um das Vortraining einzurichten.
(
{"textual content": "doc"},
{"textual content": "doc"}
)
Überwachte Feinabstimmungsdaten
In SFT-Daten gibt es drei erforderliche Parameter; Anweisung, Eingabe und Ausgabe. System und Verlauf können jedoch non-compulsory übergeben werden und werden verwendet, um das Modell entsprechend zu trainieren, sofern sie im Datensatz angegeben sind.
Das allgemeine Alpaka-Format für SFT-Daten ist wie folgt:
(
{
"instruction": "human instruction (required)",
"enter": "human enter (non-compulsory)",
"output": "mannequin response (required)",
"system": "system immediate (non-compulsory)",
"historical past": (
("human instruction within the first spherical (non-compulsory)", "mannequin response within the first spherical (non-compulsory)"),
("human instruction within the second spherical (non-compulsory)", "mannequin response within the second spherical (non-compulsory)")
)
}
)Daten zur Belohnungsmodellierung
Llama-Manufacturing facility bietet Unterstützung beim Coaching eines LLM für die Präferenzausrichtung mithilfe von RLHF. Das Datenformat muss zwei unterschiedliche Antworten für dieselbe Anweisung bereitstellen, die die Präferenz der Ausrichtung hervorheben müssen.
Die besser ausgerichtete Antwort wird an den ausgewählten Schlüssel übergeben und die schlechtere Antwort wird an den abgelehnten Parameter übergeben. Das Datenformat ist wie folgt:
(
{
"instruction": "human instruction (required)",
"enter": "human enter (non-compulsory)",
"chosen": "chosen reply (required)",
"rejected": "rejected reply (required)"
}
)Einrichtung und Set up
Der GitHub-Repository Bietet Unterstützung für eine einfache Set up mithilfe einer setup.py- und Anforderungsdatei. Es wird jedoch empfohlen, beim Einrichten des Repositorys eine saubere Python-Umgebung zu verwenden, um Abhängigkeiten und Paketkonflikte zu vermeiden.
Obwohl Python 3.8 eine Mindestanforderung ist, wird empfohlen, Python 3.11 oder höher zu installieren. Klonen Sie das Repository von GitHub mit dem folgenden Befehl:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Manufacturing facility.git
cd LLaMA-Manufacturing facilityMit den folgenden Befehlen können wir jetzt eine neue Python-Umgebung erstellen:
python3.11 -m venv venv
supply venv/bin/activateJetzt müssen wir die erforderlichen Pakete und Abhängigkeiten mithilfe der Datei setup.py installieren. Wir können sie mit dem folgenden Befehl installieren:
pip set up -e ".(torch,metrics)"Dadurch werden alle erforderlichen Abhängigkeiten installiert, einschließlich Torch, TRL, Speed up und andere Pakete. Um eine korrekte Set up sicherzustellen, sollten wir nun in der Lage sein, die Befehlszeilenschnittstelle für Llama-Manufacturing facility zu verwenden. Wenn Sie den folgenden Befehl ausführen, sollten die Hilfeinformationen zur Verwendung auf dem Terminal ausgegeben werden, wie im Bild gezeigt.

Dies sollte in der Befehlszeile ausgegeben werden, wenn die Set up erfolgreich conflict.
Feinabstimmung von LLMs
Wir können jetzt mit der Ausbildung eines LLM beginnen! Dies ist so einfach wie das Schreiben einer Konfigurationsdatei und das Aufrufen eines Bash-Befehls.
Beachten Sie, dass eine GPU ein Muss ist, um ein LLM mit Llama-Manufacturing facility zu trainieren.
Wir wählen ein kleineres Modell, um GPU-Speicher und Trainingsressourcen zu sparen. In diesem Beispiel führen wir LORA-basiertes SFT für Phi3-mini-Instruct durch. Wir haben uns für die Erstellung einer Yaml-Konfigurationsdatei entschieden, Sie können aber auch eine JSON-Datei verwenden.
Erstellen Sie wie folgt eine neue config.yaml-Datei. Diese Konfigurationsdatei dient dem SFT-Coaching. Weitere Beispiele für verschiedene Methoden finden Sie im Beispielverzeichnis.
### mannequin
model_name_or_path: microsoft/Phi-3.5-mini-instruct
### technique
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
### dataset
dataset: alpaca_en_demo
template: llama3
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/phi-3/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### practice
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500Obwohl es selbsterklärend ist, müssen wir uns auf zwei wichtige Teile der Konfigurationsdatei konzentrieren.
Konfigurieren des Datensatzes für das Coaching
Der Vorname des Datensatzes ist ein Schlüsselparameter. Weitere Particulars zum Datensatz müssen vor dem Coaching zur Datei dataset_info.json im Datenverzeichnis hinzugefügt werden. Zu diesen Informationen gehören notwendige Informationen über den tatsächlichen Datendateipfad, das verwendete Datenformat und die aus den Daten zu verwendenden Spalten.
Für dieses Tutorial verwenden wir den Datensatz alpaca_demo, der Fragen und Antworten zum Thema Englisch enthält. Sie können den vollständigen Datensatz anzeigen Hier.
Die Daten werden dann automatisch aus den bereitgestellten Informationen geladen. Darüber hinaus akzeptiert der Datensatzschlüssel eine Liste von durch Kommas getrennten Werten. Anhand einer Liste werden alle Datensätze geladen und zum Trainieren des LLM verwendet.
Konfigurieren des Modelltrainings
Das Ändern des Trainingstyps in Llama-Manufacturing facility ist so einfach wie das Ändern eines Konfigurationsparameters. Wie unten gezeigt, benötigen wir nur die folgenden Parameter, um LORA-basiertes SFT für das LLM einzurichten.
### technique
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
Wir können SFT durch Pre-Coaching und Belohnungsmodellierung mit genauen Konfigurationsdateien ersetzen, die im verfügbar sind Beispielverzeichnis. Sie können die SFT ganz einfach auf Belohnungsmodellierung umstellen, indem Sie die angegebenen Parameter ändern.
Beginnen Sie mit der Ausbildung eines LLM
Jetzt haben wir alles eingerichtet. Jetzt müssen Sie nur noch einen Bash-Befehl aufrufen und die Konfigurationsdatei als Befehlszeileneingabe übergeben.
Rufen Sie den folgenden Befehl auf:
llamafactory-cli practice config.yamlDas Programm richtet automatisch alle erforderlichen Datensätze, Modelle und Pipelines für das Coaching ein. Ich habe 10 Minuten gebraucht, um eine Epoche auf einer TESLA T4-GPU zu trainieren. Das Ausgabemodell wird im Ausgabeverzeichnis gespeichert, das in der Datei config.yaml angegeben ist.
Schlussfolgerung
Die Schlussfolgerung ist noch einfacher als das Trainieren eines Modells. Wir benötigen eine Konfigurationsdatei ähnlich dem Coaching, die das Basismodell und den Pfad zum trainierten LORA-Adapter bereitstellt.
Erstellen Sie eine neue Datei infer_config.yaml und geben Sie Werte für die angegebenen Schlüssel an:
model_name_or_path: microsoft/Phi-3.5-mini-instruct
adapter_name_or_path: saves/phi3-8b/lora/sft/ # Path to skilled mannequin
template: llama3
finetuning_type: loraMit diesem Befehl können wir direkt in der Befehlszeile mit dem trainierten Modell chatten:
llamafactory-cli chat infer_config.yamlDadurch wird das Modell mit dem trainierten Adapter geladen und Sie können ganz einfach über die Befehlszeile chatten, ähnlich wie bei anderen Paketen wie Ollama.
Eine Beispielantwort auf dem Terminal ist im Bild unten dargestellt:
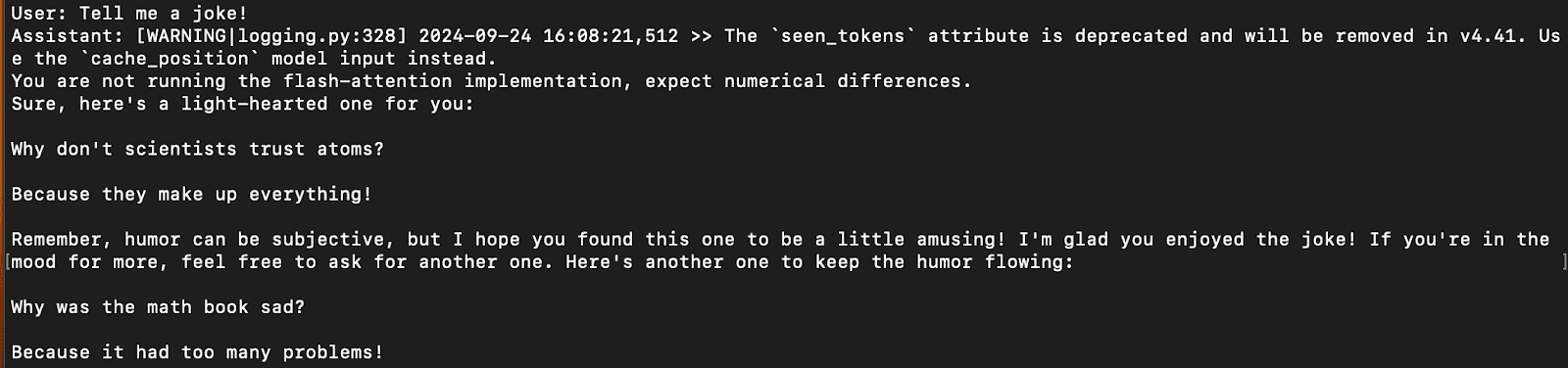
Ergebnis der Schlussfolgerung
WebUI
Wenn das nicht einfach genug wäre, bietet Llama-factory mit dem LlamaBoard eine Trainings- und Inferenzoption ohne Code.
Sie können die GUI mit dem Bash-Befehl starten:
Dadurch wird eine webbasierte GUI auf localhost gestartet, wie im Bild gezeigt. Wir können das Modell und die Trainingsparameter auswählen, den Datensatz laden und in der Vorschau anzeigen, Hyperparameter festlegen, trainieren und alles auf der GUI ableiten.
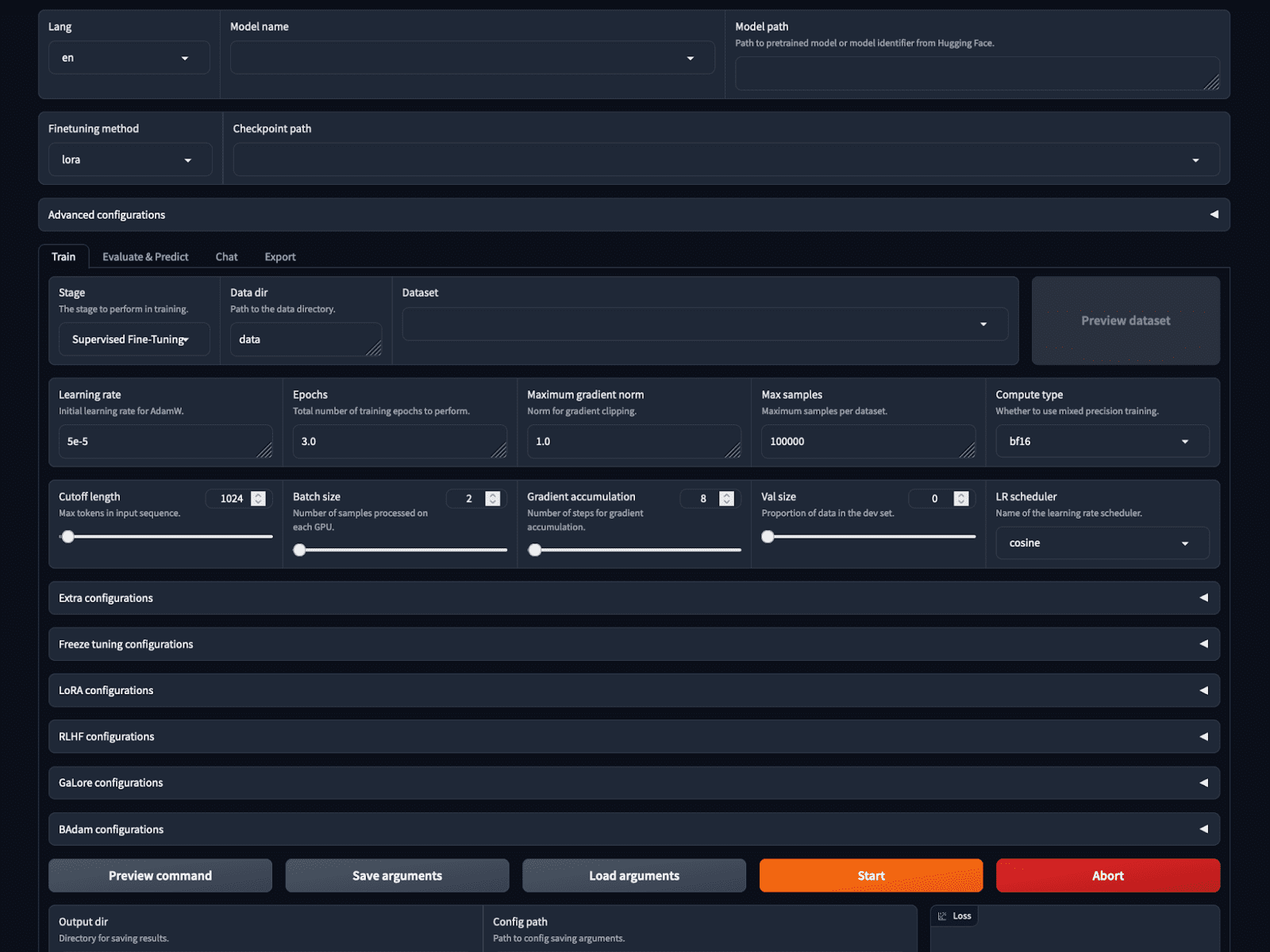
Screenshot der LlamaBoard-WebUI
Abschluss
Llama-Manufacturing facility erfreut sich mit mittlerweile über 30.000 Sternen auf GitHub immer größerer Beliebtheit. Es vereinfacht die Konfiguration und das Coaching eines LLM von Grund auf erheblich und macht die manuelle Einrichtung der Trainingspipeline für verschiedene Methoden überflüssig.
Es unterstützt alle neuesten Methoden und Modelle und behauptet immer noch, 3,7-mal schneller als ChatGLMs P-Tuning zu sein und gleichzeitig weniger GPU-Speicher zu verbrauchen. Dies macht es für normale Benutzer und Enthusiasten einfacher, ihre LLMs mit minimalem Code zu trainieren.
Kanwal Mehreen Kanwal ist ein Ingenieur für maschinelles Lernen und technischer Redakteur mit einer großen Leidenschaft für Datenwissenschaft und die Schnittstelle zwischen KI und Medizin. Sie ist Mitautorin des E-Books „Maximizing Productiveness with ChatGPT“. Als Google Era Scholar 2022 für APAC setzt sie sich für Vielfalt und akademische Exzellenz ein. Sie ist außerdem als Teradata Variety in Tech Scholar, Mitacs Globalink Analysis Scholar und Harvard WeCode Scholar anerkannt. Kanwal ist ein leidenschaftlicher Verfechter von Veränderungen und hat FEMCodes gegründet, um Frauen in MINT-Bereichen zu stärken.
Unsere High 3 Partnerempfehlungen
![]()
![]() 1. Bestes VPN für Ingenieure – Bleiben Sie on-line sicher und privat mit einer kostenlosen Testversion
1. Bestes VPN für Ingenieure – Bleiben Sie on-line sicher und privat mit einer kostenlosen Testversion
![]()
![]() 2. Bestes Projektmanagement-Device für Tech-Groups – Steigern Sie noch heute die Effizienz Ihres Groups
2. Bestes Projektmanagement-Device für Tech-Groups – Steigern Sie noch heute die Effizienz Ihres Groups
![]()
![]() 4. Bestes Netzwerkverwaltungstool – Am besten für mittlere bis große Unternehmen
4. Bestes Netzwerkverwaltungstool – Am besten für mittlere bis große Unternehmen