
Die verwendete Datenqualität ist der Eckpfeiler eines jeden Datenwissenschaftsprojekts. Schlechte Datenqualität führt zu fehlerhaften Modellen, irreführenden Erkenntnissen und kostspieligen Geschäftsentscheidungen. In diesem umfassenden Leitfaden untersuchen wir die Konstruktion einer leistungsstarken und prägnanten Datenreinigung und Validierungspipeline mit Python.
Was ist eine Datenreinigungs- und Validierungspipeline?
Eine Datenreinigungs- und Validierungspipeline ist ein automatisierter Workflow, der systematisch Rohdaten verarbeitet, um sicherzustellen, dass die Qualität akzeptierte Kriterien entspricht, bevor sie einer Analyse unterzogen werden. Betrachten Sie es als ein Qualitätskontrollsystem für Ihre Daten:
- Erkennung und Umgang mit fehlenden Werten – Erkennt Lücken in Ihrem Datensatz und wendet eine geeignete Behandlungsstrategie an
- Validiert Datentypen und Formate – Stellen Sie sicher, dass jedes Feld Informationen über den erwarteten Typ enthält
- Identifiziert und beseitigt Ausreißer – Erkennt Ausreißer, die Ihre Analyse verzerren können
- Erzwingt Geschäftsregeln -Anwendet domänenspezifische Einschränkungen und Validierungslogik
- Pflege der Abstammung – verfolgt, welche Transformationen vorgenommen wurden und wann
Die Pipeline fungiert im Wesentlichen als Gatekeeper, um sicherzustellen, dass nur saubere und validierte Daten in Ihre Analytik- und maschinellen Lernen -Workflows fließt.
Warum Datenreinigungspipelines?
Einige der wichtigsten Vorteile von automatisierten Reinigungsleitungen sind:
- Konsistenz und Reproduzierbarkeit: Manuelle Methoden können menschliche Fehler und Inkonsistenz in die Reinigungsverfahren einführen. Das automatisierte Pipelining implementiert immer wieder dieselbe Reinigungslogik, wodurch das Ergebnis reproduzierbar und glaubwürdig wird.
- Zeit- und Ressourceneffizienz: Die Erstellung der Daten kann zwischen 70 und 80% der Zeit eines Datenwissenschaftlers dauern. Pipelines automatisieren ihren Datenreinigungsprozess und reduzieren diesen Overhead weitgehend und leiten das Staff in die Analyse und Modellierung.
- Skalierbarkeit: Zum Beispiel wird die manuelle Reinigung mit zunehmendem Datenvolumen unhaltbar. Pipelines optimieren die Verarbeitung großer Datensätze und kostet quick automatisch mit steigenden Datenlasten.
- Fehlerreduzierung: Die automatisierte Validierung erfasst Datenqualitätsprobleme, die manuelle Inspektion möglicherweise verpassen kann, wodurch das Risiko einer falschen Schlussfolgerungen aus gefälschten Daten verringert wird.
- Prüfpfad: Pipelines, die genau für Sie sind, genau welche Schritte zur Reinigung der Daten befolgt wurden, was für die Einhaltung von Vorschriften und das Debuggen der Regulierung sehr instrumental wäre.
Einrichtung der Entwicklungsumgebung
Lassen Sie uns vor dem Aufstellen des Pipeline -Gebäudes sicher sein, dass wir alle Werkzeuge haben. Unsere Pipeline nutzt die aus Python Kraftpaketbibliotheken:
import pandas as pd
import numpy as np
from datetime import datetime
import logging
from typing import Dict, Record, Any, Optionally availableWarum diese Bibliotheken?
Die folgenden Bibliotheken werden im Code verwendet, gefolgt von dem von ihnen bereitgestellten Dienstprogramm:
- Pandas: Manipuliert und analysiert Daten sturdy
- Numpy: Bietet schnelle numerische Operationen und Array -Handhabung
- datetime: Validiert und Formate Daten und Zeiten
- Protokollierung: Ermöglicht die Nachverfolgung der Ausführung und Fehler beim Debuggen von Pipeline
- Typisierung: Fügt praktisch Typ -Tipps für die Codedokumentation und die Vermeidung gemeinsamer Fehler hinzu
Definieren des Validierungsschemas
Ein Validierungsschema ist im Wesentlichen der Entwurf, der die Erwartungen von Daten in Bezug auf die Struktur und die Einschränkungen, die sie beobachten, definiert. Unser Schema soll definiert werden als:
VALIDATION_SCHEMA = {
'user_id': {'kind': int, 'required': True, 'min_value': 1},
'e-mail': {'kind': str, 'required': True, 'sample': r'^(^@)+@(^@)+.(^@)+$'},
'age': {'kind': int, 'required': False, 'min_value': 0, 'max_value': 120},
'signup_date': {'kind': 'datetime', 'required': True},
'rating': {'kind': float, 'required': False, 'min_value': 0.0, 'max_value': 100.0}
}Das Schema gibt eine Reihe von Validierungsregeln an:
- Geben Sie Validierung ein: Überprüft den Datentyp des empfangenen Wertes für jedes Feld
- Erforderliche Subject-Validierung: Identifiziert obligatorische Felder, die nicht fehlen dürfen
- Bereichsvalidierung: Legt den minimalen und maximal akzeptablen Wert fest
- Mustervalidierung: Reguläre Ausdrücke für Validierungszwecke, z. B. gültige E -Mail -Adressen
- Datumsvalidierung: Überprüft, ob das Datumfeld gültige DateTime -Objekte enthält
Aufbau der Pipeline -Klasse
Unsere Pipeline -Klasse fungiert als Orchestrator, der alle Bereitungs- und Validierungoperationen koordiniert:
class DataCleaningPipeline:
def __init__(self, schema: Dict(str, Any)):
self.schema = schema
self.errors = ()
self.cleaned_rows = 0
self.total_rows = 0
# Setup logging
logging.basicConfig(stage=logging.INFO)
self.logger = logging.getLogger(__name__)
def clean_and_validate(self, df: pd.DataFrame) -> pd.DataFrame:
"""Fundamental pipeline orchestrator"""
self.total_rows = len(df)
self.logger.information(f"Beginning pipeline with {self.total_rows} rows")
# Pipeline levels
df = self._handle_missing_values(df)
df = self._validate_data_types(df)
df = self._apply_constraints(df)
df = self._remove_outliers(df)
self.cleaned_rows = len(df)
self._generate_report()
return dfDie Pipeline folgt einem systematischen Ansatz:
- Initialisieren Sie die Monitoring -Variablen, um den Reinigungsfortschritt zu überwachen
- Richten Sie die Protokollierung zum Erfassen von Pipeline -Ausführungsdetails ein
- Führen Sie die Reinigungsstufen in einer logischen Reihenfolge aus
- Generieren Sie Berichte, in denen die Reinigungsergebnisse zusammengefasst sind
Schreiben der Datenreinigungslogik
Lassen Sie uns jede Reinigungsstufe mit robustem Umfang implementieren Fehlerbehandlung:
Fehlende Wertschreibung
Der folgende Code lässt Zeilen mit fehlenden erforderlichen Feldern fallen und füllt fehlende optionale Felder mit Median (für Numeriker) oder „Unbekannte“ (für Nicht-Numeriker).
def _handle_missing_values(self, df: pd.DataFrame) -> pd.DataFrame:
"""Deal with lacking values based mostly on discipline necessities"""
for column, guidelines in self.schema.gadgets():
if column in df.columns:
if guidelines.get('required', False):
# Take away rows with lacking required fields
missing_count = df(column).isnull().sum()
if missing_count > 0:
self.errors.append(f"Eliminated {missing_count} rows with lacking {column}")
df = df.dropna(subset=(column))
else:
# Fill non-obligatory lacking values
if df(column).dtype in ('int64', 'float64'):
df(column).fillna(df(column).median(), inplace=True)
else:
df(column).fillna('Unknown', inplace=True)
return dfDatentypvalidierung
Der folgende Code wandelt Spalten in bestimmte Typen um und beseitigt Zeilen, bei denen die Konvertierung fehlschlägt.
def _validate_data_types(self, df: pd.DataFrame) -> pd.DataFrame:
"""Convert and validate information sorts"""
for column, guidelines in self.schema.gadgets():
if column in df.columns:
expected_type = guidelines('kind')
strive:
if expected_type == 'datetime':
df(column) = pd.to_datetime(df(column), errors="coerce")
elif expected_type == int:
df(column) = pd.to_numeric(df(column), errors="coerce").astype('Int64')
elif expected_type == float:
df(column) = pd.to_numeric(df(column), errors="coerce")
# Take away rows with conversion failures
invalid_count = df(column).isnull().sum()
if invalid_count > 0:
self.errors.append(f"Eliminated {invalid_count} rows with invalid {column}")
df = df.dropna(subset=(column))
besides Exception as e:
self.logger.error(f"Kind conversion error for {column}: {e}")
return dfHinzufügen von Validierung mit Fehlerverfolgung
Unser Einschränkungsvalidierungssystem stellt sicher, dass die Daten innerhalb von Grenzen liegen und das Format akzeptabel ist:
def _apply_constraints(self, df: pd.DataFrame) -> pd.DataFrame:
"""Apply field-specific constraints"""
for column, guidelines in self.schema.gadgets():
if column in df.columns:
initial_count = len(df)
# Vary validation
if 'min_value' in guidelines:
df = df(df(column) >= guidelines('min_value'))
if 'max_value' in guidelines:
df = df(df(column) <= guidelines('max_value'))
# Sample validation for strings
if 'sample' in guidelines and df(column).dtype == 'object':
import re
sample = re.compile(guidelines('sample'))
df = df(df(column).astype(str).str.match(sample, na=False))
removed_count = initial_count - len(df)
if removed_count > 0:
self.errors.append(f"Eliminated {removed_count} rows failing {column} constraints")
return dfEinschränkungsbasierte und Querfeldvalidierung
Eine erweiterte Validierung ist normalerweise erforderlich, wenn die Beziehungen zwischen mehreren Feldern berücksichtigt werden:
def _cross_field_validation(self, df: pd.DataFrame) -> pd.DataFrame:
"""Validate relationships between fields"""
initial_count = len(df)
# Instance: Signup date shouldn't be sooner or later
if 'signup_date' in df.columns:
future_signups = df('signup_date') > datetime.now()
df = df(~future_signups)
eliminated = future_signups.sum()
if eliminated > 0:
self.errors.append(f"Eliminated {eliminated} rows with future signup dates")
# Instance: Age consistency with signup date
if 'age' in df.columns and 'signup_date' in df.columns:
# Take away information the place age appears inconsistent with signup timing
suspicious_age = (df('age') < 13) & (df('signup_date') < datetime(2010, 1, 1))
df = df(~suspicious_age)
eliminated = suspicious_age.sum()
if eliminated > 0:
self.errors.append(f"Eliminated {eliminated} rows with suspicious age/date combos")
return dfAusreißererkennung und Entfernung
Die Auswirkungen von Ausreißern können die Ergebnisse der Analyse extrem sein. Die Pipeline verfügt über eine erweiterte Methode zum Erkennen solcher Ausreißer:
def _remove_outliers(self, df: pd.DataFrame) -> pd.DataFrame:
"""Take away statistical outliers utilizing IQR methodology"""
numeric_columns = df.select_dtypes(embrace=(np.quantity)).columns
for column in numeric_columns:
if column in self.schema:
Q1 = df(column).quantile(0.25)
Q3 = df(column).quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = (df(column) < lower_bound) | (df(column) > upper_bound)
outlier_count = outliers.sum()
if outlier_count > 0:
df = df(~outliers)
self.errors.append(f"Eliminated {outlier_count} outliers from {column}")
return dfOrchestrieren die Pipeline
Hier ist unsere vollständige, kompakte Pipeline -Implementierung:
class DataCleaningPipeline:
def __init__(self, schema: Dict(str, Any)):
self.schema = schema
self.errors = ()
self.cleaned_rows = 0
self.total_rows = 0
logging.basicConfig(stage=logging.INFO)
self.logger = logging.getLogger(__name__)
def clean_and_validate(self, df: pd.DataFrame) -> pd.DataFrame:
self.total_rows = len(df)
self.logger.information(f"Beginning pipeline with {self.total_rows} rows")
# Execute cleansing levels
df = self._handle_missing_values(df)
df = self._validate_data_types(df)
df = self._apply_constraints(df)
df = self._remove_outliers(df)
self.cleaned_rows = len(df)
self._generate_report()
return df
def _generate_report(self):
"""Generate cleansing abstract report"""
self.logger.information(f"Pipeline accomplished: {self.cleaned_rows}/{self.total_rows} rows retained")
for error in self.errors:
self.logger.warning(error)Beispiel Verwendung
Lassen Sie uns eine Demonstration einer Pipeline in Aktion mit einem echten Datensatz sehen:
# Create pattern problematic information
sample_data = pd.DataFrame({
'user_id': (1, 2, None, 4, 5, 999999),
'e-mail': ('(e-mail protected)', 'invalid-email', '(e-mail protected)', None, '(e-mail protected)', '(e-mail protected)'),
'age': (25, 150, 30, -5, 35, 28), # Incorporates invalid ages
'signup_date': ('2023-01-15', '2030-12-31', '2022-06-10', '2023-03-20', 'invalid-date', '2023-05-15'),
'rating': (85.5, 105.0, 92.3, 78.1, -10.0, 88.7) # Incorporates out-of-range scores
})
# Initialize and run pipeline
pipeline = DataCleaningPipeline(VALIDATION_SCHEMA)
cleaned_data = pipeline.clean_and_validate(sample_data)
print("Cleaned Knowledge:")
print(cleaned_data)
print(f"nCleaning Abstract: {pipeline.cleaned_rows}/{pipeline.total_rows} rows retained")Ausgabe:
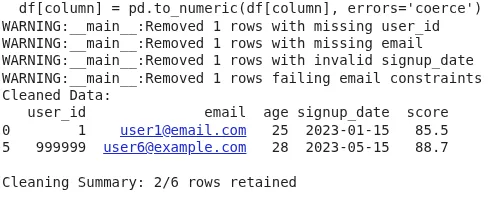
Die Ausgabe zeigt den endgültigen gereinigten Datenrahmen, nachdem die Zeilen mit fehlenden erforderlichen Feldern, ungültigen Datentypen, Einschränkungenverstößen (z. In der Zusammenfassungslinie wird berichtet, wie viele Zeilen aus der Gesamtzahl zurückgehalten wurden. Dies stellt sicher, dass nur gültige, analysebereitete Daten voranschreiten, die Qualität verbessern, Fehler reduzieren und Ihre Pipeline zuverlässig und reproduzierbar machen.
Erweiterung der Pipeline
Unsere Pipeline wurde erweiterbar. Im Folgenden finden Sie einige Ideen zur Verbesserung:
- Benutzerdefinierte Validierungsregeln: iNCORPORATE DOMAIN-spezifische Validierungslogik durch Erweiterung des Schema-Codecs, um benutzerdefinierte Validierungsfunktionen zu akzeptieren.
- Parallele Verarbeitung: Verarbeiten Sie große Datensätze parallel über mehrere CPU -Kerne mit geeigneten Bibliotheken wie Multiprozessierung.
- Maschinelles Lernen Integration: Bringen Sie Anomalie-Erkennungsmodelle zum Erkennen von Problemen der Datenqualität ein, die für regelbasierte Systeme zu kompliziert sind.
- Echtzeitverarbeitung: Ändern Sie die Pipeline zum Streaming von Daten mit Apache Kafka oder Apache Funken Streaming.
- Datenqualitätsmetriken: Entwerfen Sie eine breite Qualitätsbewertung, die mehrere Dimensionen wie Vollständigkeit, Genauigkeit, Konsistenz und Aktualität fördert.

Abschluss
Der Begriff dieser Artwork der Reinigung und Validierung besteht darin, die Daten auf alle Elemente zu überprüfen, die Fehler sein können: fehlende Werte, ungültige Datentypen oder Einschränkungen, Ausreißer und natürlich alle Informationen mit so vielen Particulars wie möglich melden. Diese Pipeline wird dann zu Ihrem Ausgangspunkt für die Datenversicherung in jeder Artwork von Datenanalyse oder maschineller Lernaufgabe. Einige der Vorteile, die Sie aus diesem Ansatz erhalten, umfassen automatische QS -Überprüfungen, sodass keine Fehler unbemerkt, reproduzierbare Ergebnisse, gründliche Fehlerverfolgung und einfache Set up mehrerer Überprüfungen mit bestimmten Domänenbeschränkungen sind.
Durch die Bereitstellung von Pipelines dieser Artwork in Ihren Datenworkflows sind Ihre datengesteuerten Entscheidungen eine weitaus größere Likelihood, korrekt und präzise zu sein. Datenreinigung ist ein iterativer Prozess, und diese Pipeline kann in Ihrer Domäne mit zusätzlichen Validierungsregeln und Reinigungslogik erweitert werden, wenn neue Datenqualitätsprobleme auftreten. Durch ein solches modulares Design können neue Funktionen ohne Zusammenstöße mit derzeit implementierten integriert werden.
Häufig gestellte Fragen
A. Es handelt sich um einen automatisierten Workflow, der fehlende Werte erkennt und behebt, Fehlanpassungen, Einschränkungen gegen Verstöße und Ausreißer typisiert, um sicherzustellen, dass nur saubere Daten eine Analyse oder Modellierung erreicht.
A. Pipelines sind schneller, konsistent, reproduzierbar und weniger fehleranfällige als manuelle Methoden, insbesondere bei der Arbeit mit großen Datensätzen.
A. Zeilen mit fehlenden erforderlichen Feldern oder fehlgeschlagenen Validierungen werden fallen gelassen. Optionale Felder erhalten Standardwerte wie Mediane oder „unbekannt“.
Gen AI -Praktikant bei Analytics Vidhya
Abteilung für Informatik, Vellore Institute of Know-how, Vellore, Indien
Ich arbeite derzeit als Common-AI-Praktikant bei Analytics Vidhya, wo ich zu innovativen KI-gesteuerten Lösungen beiträgt, die Unternehmen dazu befähigen, Daten effektiv zu nutzen. Als Pupil des letzten Jahres am Vellore Institute of Know-how bringe ich eine solide Grundlage für Softwareentwicklung, Datenanalyse und maschinelles Lernen in meine Rolle.
Fühlen Sie sich frei, sich mit mir zu verbinden (E -Mail geschützt)
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.