Kleine Sprachmodelle (SLMs) haben einen erheblichen Einfluss auf die KI. Sie bieten eine starke Leistung und sind gleichzeitig effizient und kostengünstig. Ein herausragendes Beispiel ist der Llama 3.2 3B. Es schneidet bei Retrieval-Augmented Technology (RAG)-Aufgaben außergewöhnlich intestine ab und senkt die Rechenkosten und den Speicherverbrauch bei gleichzeitig hoher Genauigkeit. In diesem Artikel wird die Feinabstimmung des Llama 3.2 3B-Modells erläutert. Erfahren Sie, wie kleinere Modelle bei RAG-Aufgaben hervorragende Leistungen erbringen und die Grenzen dessen erweitern können, was kompakte KI-Lösungen leisten können.
Was ist Lama 3.2 3B?
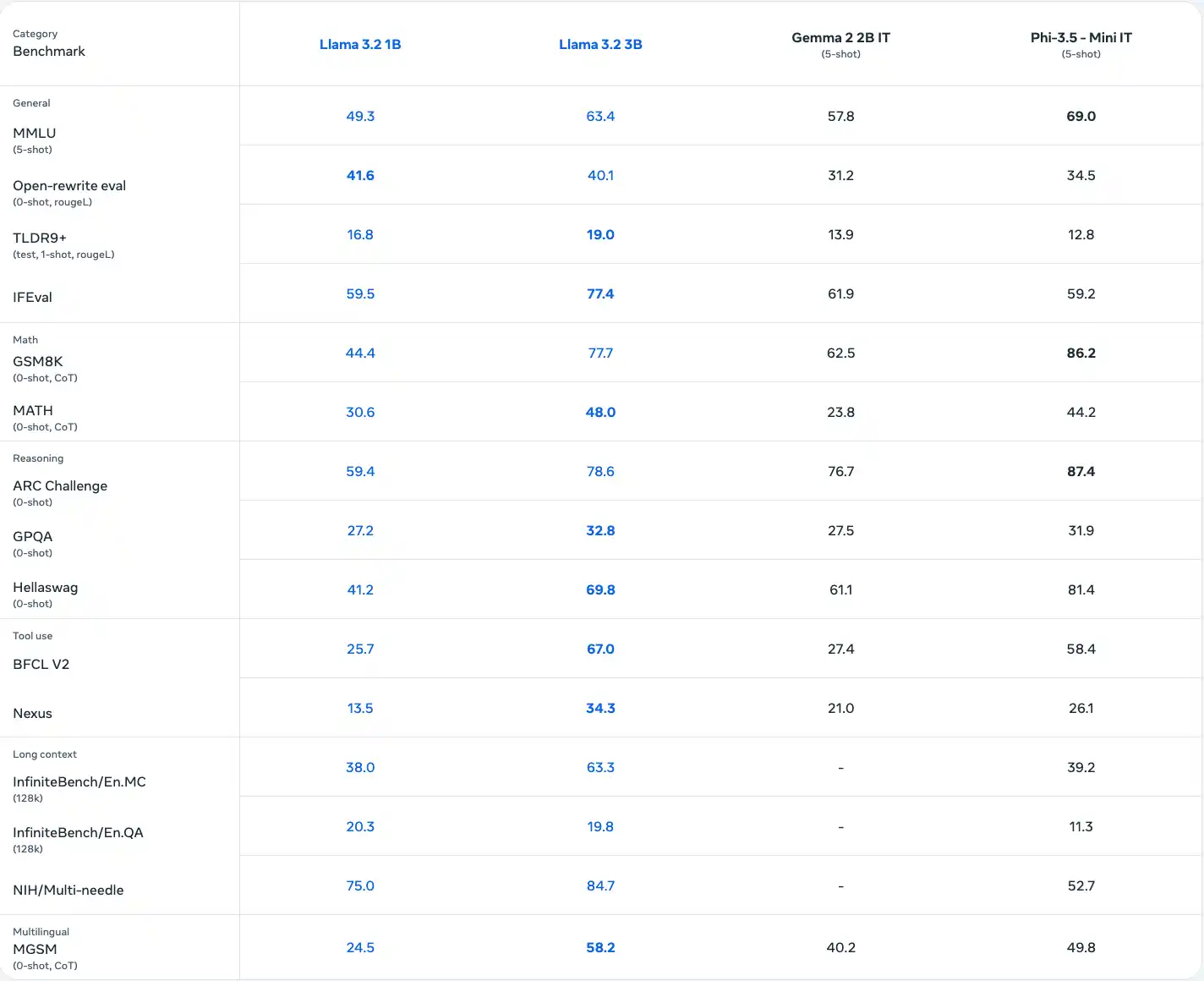
Das von Meta entwickelte Llama 3.2 3B-Modell ist ein mehrsprachiges SLM mit 3 Milliarden Parametern, das für Aufgaben wie Fragenbeantwortung, Zusammenfassung und Dialogsysteme entwickelt wurde. Es übertrifft viele Open-Supply-Modelle bei Branchen-Benchmarks und unterstützt verschiedene Sprachen. Llama 3.2 ist in verschiedenen Größen erhältlich und bietet eine effiziente Rechenleistung sowie quantisierte Versionen für eine schnellere, speichereffiziente Bereitstellung in mobilen und Edge-Umgebungen.

Lesen Sie auch: Die 13 besten Small Language Fashions (SLMs)
Feinabstimmung von Lama 3.2 3B
Eine Feinabstimmung ist für die Anpassung von SLM oder LLMs an bestimmte Bereiche oder Aufgaben, beispielsweise medizinische, rechtliche oder RAG-Anwendungen, unerlässlich. Während das Vortraining es Sprachmodellen ermöglicht, Texte zu verschiedenen Themen zu generieren, trainiert die Feinabstimmung das Modell erneut auf domänen- oder aufgabenspezifischen Daten, um Relevanz und Leistung zu verbessern. Um den hohen Rechenaufwand für die Feinabstimmung aller Parameter zu bewältigen, konzentrieren sich Techniken wie Parameter Environment friendly Advantageous-Tuning (PEFT) darauf, nur eine Teilmenge der Parameter des Modells zu trainieren und so die Ressourcennutzung zu optimieren und gleichzeitig die Leistung aufrechtzuerhalten.
LoRA
Eine solche PEFT-Methode ist Low Rank Adaptation (LoRA).
In Lora wird die Gewichtsmatrix in SLM oder LLM in ein Produkt aus zwei Matrizen mit niedrigem Rang zerlegt.
W = WA * WB
Wenn W m Zeilen und n Spalten hat, kann es in WA mit m Zeilen und r Spalten und WB mit r Zeilen und n Spalten zerlegt werden. Hier ist r viel kleiner als m oder n. Anstatt additionally m*n Werte zu trainieren, können wir nur r*(m+n) Werte trainieren. r heißt Rang und ist der Hyperparameter, den wir wählen können.
def lora_linear(x):
h = x @ W # common linear
h += scale * (x @ W_A @ W_B) # low-rank replace
return h
Kasse: Parametereffiziente Feinabstimmung großer Sprachmodelle mit LoRA und QLoRA
Lassen Sie uns LoRA auf dem Llama 3.2 3B-Modell implementieren.
Bibliotheken erforderlich
- unsloth – 2024.12.9
- Datensätze – 3.1.0
Durch die Set up der oben genannten Sloth-Model werden auch die kompatiblen Pytorch-, Transformer- und Nvidia-GPU-Bibliotheken installiert. Wir können Google Colab verwenden, um auf die GPU zuzugreifen.
Schauen wir uns jetzt die Umsetzung an!
Importieren Sie die Bibliotheken
from unsloth import FastLanguageModel, is_bfloat16_supported, train_on_responses_only
from datasets import load_dataset, Dataset
from trl import SFTTrainer, apply_chat_template
from transformers import TrainingArguments, DataCollatorForSeq2Seq, TextStreamer
import torchInitialisieren Sie das Modell und die Tokenizer
max_seq_length = 2048
dtype = None # None for auto-detection.
load_in_4bit = True # Use 4bit quantization to cut back reminiscence utilization. May be False.
mannequin, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Llama-3.2-3B-Instruct",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use if utilizing gated fashions like meta-llama/Llama-3.2-11b
)
Weitere von Unsloth unterstützte Modelle finden Sie hier dieses Dokument.
Initialisieren Sie das Modell für PEFT
mannequin = FastLanguageModel.get_peft_model(
mannequin,
r = 16,
target_modules = ("q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",),
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 42,
use_rslora = False,
loftq_config = None,
)
Beschreibung für jeden Parameter
- r: Rang von LoRA; Höhere Werte verbessern die Genauigkeit, verbrauchen aber mehr Speicher (empfohlen: 8–128).
- target_modules: Module zur Feinabstimmung; Beziehen Sie alles ein, um bessere Ergebnisse zu erzielen
- lora_alpha: Skalierungsfaktor; typischerweise gleich oder doppelt so hoch wie der Rang r.
- lora_dropout: Abbrecherquote; Für optimiertes und schnelleres Coaching auf 0 setzen.
- Bias: Bias-Typ; „none“ ist auf Geschwindigkeit und minimale Überanpassung optimiert.
- use_gradient_checkpointing: Reduziert den Speicher für Langkontexttraining; „unsloth“ ist sehr zu empfehlen.
- random_state: Seed für deterministische Läufe, um reproduzierbare Ergebnisse sicherzustellen (z. B. 42).
- use_rslora: Automatisiert die Alpha-Auswahl; nützlich für rangstabilisiertes LoRA.
- loftq_config: Initialisiert LoRA mit High-r-Singulärvektoren für eine bessere Genauigkeit, obwohl speicherintensiv.
Datenverarbeitung
Wir werden die RAG-Daten zur Feinabstimmung verwenden. Laden Sie die Daten von Huggingface herunter.
dataset = load_dataset("neural-bridge/rag-dataset-1200", break up = "prepare")Der Datensatz verfügt über die folgenden drei Schlüssel:
Datensatz({ Options: (‚Kontext‘, ‚Frage‘, ‚Antwort‘), num_rows: 960 })
Die Daten müssen je nach Sprachmodell in einem bestimmten Format vorliegen. Weitere Particulars lesen Hier.
Additionally konvertieren wir die Daten in das erforderliche Format:
def convert_dataset_to_dict(dataset):
dataset_dict = {
"immediate": (),
"completion": ()
}
for row in dataset:
user_content = f"Context: {row('context')}nQuestion: {row('query')}"
assistant_content = row('reply')
dataset_dict("immediate").append((
{"function": "person", "content material": user_content}
))
dataset_dict("completion").append((
{"function": "assistant", "content material": assistant_content}
))
return dataset_dict
converted_data = convert_dataset_to_dict(dataset)
dataset = Dataset.from_dict(converted_data)
dataset = dataset.map(apply_chat_template, fn_kwargs={"tokenizer": tokenizer})
Die Datensatznachricht lautet wie folgt:

Einrichten der Trainerparameter
Wir können den Coach für die Feinabstimmung des SLM initialisieren:
coach = SFTTrainer(
mannequin = mannequin,
tokenizer = tokenizer,
train_dataset = dataset,
max_seq_length = max_seq_length,
data_collator = DataCollatorForSeq2Seq(tokenizer = tokenizer),
dataset_num_proc = 2,
packing = False, # Could make coaching 5x sooner for brief sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
# num_train_epochs = 1, # Set this for 1 full coaching run.
max_steps = 6, # utilizing small quantity to check
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none", # Use this for WandB and so forth
),
)
Beschreibung einiger Parameter:
- per_device_train_batch_size: Stapelgröße professional Gerät; erhöhen, um mehr GPU-Speicher zu nutzen, aber achten Sie auf Ineffizienzen beim Auffüllen (empfohlen: 2).
- gradient_accumulation_steps: Simuliert größere Stapelgrößen ohne zusätzliche Speichernutzung; Erhöhung für glattere Verlustkurven (empfohlen: 4).
- max_steps: Gesamte Trainingsschritte; Stellen Sie es für schnellere Läufe ein (z. B. 60) oder verwenden Sie „num_train_epochs“ für vollständige Datensatzdurchläufe (z. B. 1–3).
- learning_rate: Steuert Trainingsgeschwindigkeit und Konvergenz; Niedrigere Raten (z. B. 2e-4) verbessern die Genauigkeit, verlangsamen jedoch das Coaching.
Lassen Sie das Modell nur auf Antworten trainieren, indem Sie die Antwortvorlage angeben:
coach = train_on_responses_only(
coach,
instruction_part = "<|start_header_id|>person<|end_header_id|>nn",
response_part = "<|start_header_id|>assistant<|end_header_id|>nn",
)
Feinabstimmung des Modells
trainer_stats = coach.prepare()Hier sind die Trainingsstatistiken:

Testen und speichern Sie das Modell
Lassen Sie uns das Modell zur Schlussfolgerung verwenden:
FastLanguageModel.for_inference(mannequin)
messages = (
{"function": "person", "content material": "Context: The sky is usually clear throughout the day. Query: What colour is the water?"},
)
inputs = tokenizer.apply_chat_template(
messages,
tokenize = True,
add_generation_prompt = True,
return_tensors = "pt",
).to("cuda")
text_streamer = TextStreamer(tokenizer, skip_prompt = True)
_ = mannequin.generate(input_ids = inputs, streamer = text_streamer, max_new_tokens = 128,
use_cache = True, temperature = 1.5, min_p = 0.1)
Um die trainierten Gewichte einschließlich LoRA zu speichern, verwenden Sie den folgenden Code
mannequin.save_pretrained_merged("mannequin", tokenizer, save_method = "merged_16bit")
Kasse: Leitfaden zur Feinabstimmung großer Sprachmodelle
Abschluss
Die Feinabstimmung von Llama 3.2 3B für RAG-Aufgaben zeigt die Effizienz kleinerer Modelle bei der Bereitstellung hoher Leistung bei reduzierten Rechenkosten. Techniken wie LoRA optimieren die Ressourcennutzung und wahren gleichzeitig die Genauigkeit. Dieser Ansatz ermöglicht domänenspezifische Anwendungen, macht fortschrittliche KI zugänglicher, skalierbarer und kostengünstiger, treibt Innovationen in der abrufgestützten Generierung voran und demokratisiert KI für reale Herausforderungen.
Lesen Sie auch: Erste Schritte mit Meta Llama 3.2
Häufig gestellte Fragen
A. RAG kombiniert Retrieval-Systeme mit generativen Modellen, um Antworten zu verbessern, indem es sie auf externem Wissen aufbaut, was es supreme für Aufgaben wie die Beantwortung und Zusammenfassung von Fragen macht.
A. Llama 3.2 3B bietet ein ausgewogenes Verhältnis von Leistung, Effizienz und Skalierbarkeit, wodurch es für RAG-Aufgaben geeignet ist und gleichzeitig den Rechen- und Speicherbedarf reduziert.
A. Low-Rank Adaptation (LoRA) minimiert den Ressourcenverbrauch, indem nur Matrizen mit niedrigem Rang anstelle aller Modellparameter trainiert werden, was eine effiziente Feinabstimmung auf eingeschränkter {Hardware} ermöglicht.
A. Hugging Face stellt den RAG-Datensatz bereit, der Kontext, Fragen und Antworten enthält, um das Llama 3.2 3B-Modell für eine bessere Aufgabenleistung zu optimieren.
A. Ja, Llama 3.2 3B ist, insbesondere in seiner quantisierten Type, für den speichereffizienten Einsatz in Edge- und mobilen Umgebungen optimiert.
Ich arbeite als Affiliate Knowledge Scientist bei Analytics Vidhya, einer Plattform, die sich dem Aufbau des Knowledge Science-Ökosystems widmet. Meine Interessen liegen in den Bereichen Pure Language Processing (NLP), Deep Studying und KI-Agenten.