
Einführung
Funktionsaufruf große Sprachmodelle (LLMs) hat die Artwork und Weise, wie KI-Agenten mit externen Systemen, APIs oder Instruments interagieren, verändert und eine strukturierte Entscheidungsfindung auf der Grundlage natürlicher Spracheingaben ermöglicht. Durch die Verwendung von JSON-Schema-definierten Funktionen können diese Modelle externe Vorgänge autonom auswählen und ausführen und so ein neues Maß an Automatisierung bieten. In diesem Artikel wird gezeigt, wie Funktionsaufrufe mit Mistral 7B implementiert werden können, einem hochmodernen Modell, das für Aufgaben zur Befolgung von Anweisungen entwickelt wurde.
Lernergebnisse
- Verstehen Sie die Rolle und Arten von KI-Agenten in der generativen KI.
- Erfahren Sie, wie Funktionsaufrufe die LLM-Funktionen mithilfe von JSON-Schemas verbessern.
- Einrichten und laden Mistral 7B Modell zur Textgenerierung.
- Implementieren Sie Funktionsaufrufe in LLMs, um externe Operationen auszuführen.
- Extrahieren Sie Funktionsargumente und generieren Sie Antworten mit Mistral 7B.
- Führen Sie Echtzeitfunktionen wie Wetterabfragen mit strukturierter Ausgabe aus.
- Erweitern Sie die KI-Agent-Funktionalität mithilfe mehrerer Instruments über verschiedene Domänen hinweg.
Dieser Artikel wurde im Rahmen der veröffentlicht Knowledge Science-Blogathon.
Was sind KI-Agenten?
Im Rahmen von Generative KI (GenAI) stellen KI-Agenten eine bedeutende Weiterentwicklung der Fähigkeiten der künstlichen Intelligenz dar. Diese Agenten verwenden Modelle wie große Sprachmodelle (LLMs), um Inhalte zu erstellen, Interaktionen zu simulieren und komplexe Aufgaben autonom auszuführen. Die KI-Agenten verbessern ihre Funktionalität und Anwendbarkeit in verschiedenen Bereichen, einschließlich Kundensupport, Bildung und medizinischem Bereich.
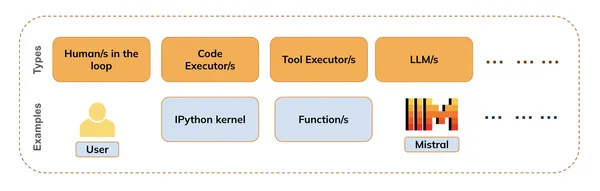
Es gibt verschiedene Arten (wie in der Abbildung unten gezeigt), darunter:
- Menschen auf dem Laufenden (z. B. für die Bereitstellung von Suggestions)
- Code-Ausführer (z. B. IPython-Kernel)
- Instrument-Ausführer (z. B. Funktions- oder API-Ausführungen)
- Modelle (LLMs, VLMs usw.)
Funktionsaufruf ist die Kombination aus Codeausführung, Toolausführung und Modellinferenz. Das heißt, während die LLMs das Verständnis und die Generierung natürlicher Sprache übernehmen, kann der Code Executor alle Codeausschnitte ausführen, die zur Erfüllung von Benutzeranforderungen erforderlich sind.
Wir können auch die Menschen in der Schleife nutzen, um während des Prozesses Suggestions zu erhalten oder um zu erfahren, wann der Prozess beendet werden muss.
Was ist Funktionsaufruf in großen Sprachmodellen?
Entwickler definieren Funktionen mithilfe von JSON-Schemas (die an das Modell übergeben werden), und das Modell generiert die erforderlichen Argumente für diese Funktionen basierend auf Benutzereingaben. Zum Beispiel: Es kann Wetter-APIs aufrufen, um Echtzeit-Wetteraktualisierungen basierend auf Benutzeranfragen bereitzustellen (in diesem Notizbuch sehen wir ein ähnliches Beispiel). Mit Funktionsaufrufen können LLMs clever auswählen, welche Funktionen oder Instruments als Reaktion auf eine Benutzeranfrage verwendet werden sollen. Diese Fähigkeit ermöglicht es Agenten, selbstständig Entscheidungen darüber zu treffen, wie sie eine Aufgabe am besten erfüllen, und steigert so ihre Effizienz und Reaktionsfähigkeit.
In diesem Artikel wird gezeigt, wie wir das LLM (hier Mistral) verwendet haben, um Argumente für die definierte Funktion zu generieren, basierend auf der Frage des Benutzers, insbesondere: Der Benutzer fragt nach der Temperatur in Delhi, das Modell extrahiert die Argumente, die der Die Funktion ruft die Echtzeitinformationen ab (hier haben wir zu Demonstrationszwecken die Rückgabe eines Standardwerts festgelegt), und dann generiert der LLM die Antwort in einfacher Sprache für den Benutzer.
Aufbau einer Pipeline für Mistral 7B: Modell- und Textgenerierung
Lassen Sie uns die erforderlichen Bibliotheken importieren und das Modell und den Tokenizer von Huggingface für die Inferenzeinrichtung importieren. Das Modell ist verfügbar Hier.
Importieren notwendiger Bibliotheken
from transformers import pipeline ## For sequential textual content technology
from transformers import AutoModelForCausalLM, AutoTokenizer # For main the mannequin and tokenizer from huggingface repository
import warnings
warnings.filterwarnings("ignore") ## To take away warning messages from outputBereitstellung des Huggingface-Modell-Repository-Namens für Mistral 7B
model_name = "mistralai/Mistral-7B-Instruct-v0.3"Herunterladen des Modells und Tokenizers
- Da es sich bei diesem LLM um ein geschlossenes Modell handelt, müssen Sie sich zuerst bei Huggingface anmelden und deren Geschäftsbedingungen akzeptieren. Nach der Anmeldung können Sie den Anweisungen hierzu folgen Seite um Ihr Benutzerzugriffstoken zu generieren, um dieses Modell auf Ihren Laptop herunterzuladen.
- Nachdem Sie das Token mithilfe der oben genannten Schritte generiert haben, übergeben Sie das Huggingface-Token (in hf_token) zum Laden des Modells.
mannequin = AutoModelForCausalLM.from_pretrained(model_name, token = hf_token, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained(model_name, token = hf_token)Funktionsaufrufe mit Mistral 7B implementieren
In der sich schnell entwickelnden Welt der KI ermöglicht die Implementierung von Funktionsaufrufen mit Mistral 7B Entwicklern die Entwicklung anspruchsvoller Agenten, die nahtlos mit externen Systemen interagieren und präzise, kontextbezogene Antworten liefern können.
Schritt 1: Angeben von Instruments (Funktion) und Abfrage (erste Eingabeaufforderung)
Hier definieren wir die Instruments (Funktion(en), auf deren Informationen das Modell Zugriff hat, um die Funktionsargumente basierend auf der Benutzerabfrage zu generieren.
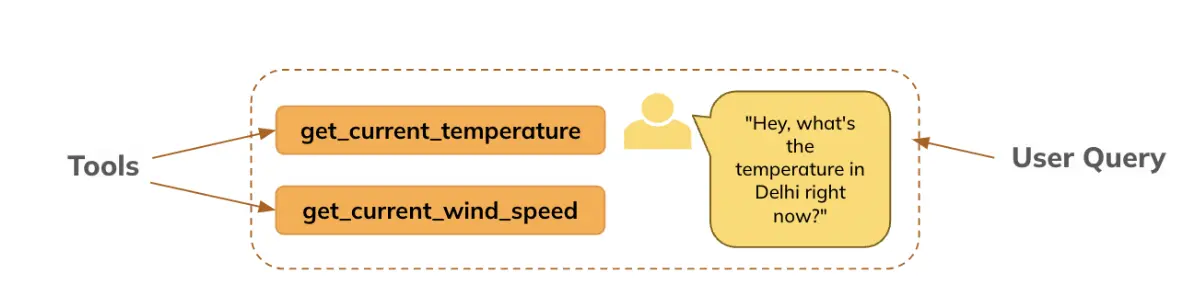
Das Werkzeug ist unten definiert:
def get_current_temperature(location: str, unit: str) -> float:
"""
Get the present temperature at a location.
Args:
location: The situation to get the temperature for, within the format "Metropolis, Nation".
unit: The unit to return the temperature in. (selections: ("celsius", "fahrenheit"))
Returns:
The present temperature on the specified location within the specified models, as a float.
"""
return 30.0 if unit == "celsius" else 86.0 ## We're setting a default output only for demonstration objective. In actual life it might be a working operateDie Eingabeaufforderungsvorlage für Mistral muss in dem für Mistral unten aufgeführten spezifischen Format vorliegen.
Abfrage (die Eingabeaufforderung), die an das Modell übergeben werden soll
messages = (
{"function": "system", "content material": "You're a bot that responds to climate queries. You must reply with the unit used within the queried location."},
{"function": "consumer", "content material": "Hey, what is the temperature in Delhi proper now?"}
)Schritt 2: Modell generiert ggf. Funktionsargumente
Insgesamt wird die Anfrage des Benutzers zusammen mit den Informationen über die verfügbaren Funktionen an das LLM übergeben, woraufhin das LLM die Argumente aus der Anfrage des Benutzers für die auszuführende Funktion extrahiert.

- Anwenden der spezifischen Chat-Vorlage für Mistral-Funktionsaufrufe
- Das Modell generiert die Antwort, die enthält, welche Funktion und welche Argumente angegeben werden müssen.
- Der LLM wählt die auszuführende Funktion aus und extrahiert die Argumente aus der vom Benutzer bereitgestellten natürlichen Sprache.
inputs = tokenizer.apply_chat_template(
messages, # Passing the preliminary immediate or dialog context as a listing of messages.
instruments=(get_current_temperature), # Specifying the instruments (capabilities) out there to be used in the course of the dialog. These might be APIs or helper capabilities for duties like fetching temperature or wind velocity.
add_generation_prompt=True, # Whether or not so as to add a system technology immediate to information the mannequin in producing applicable responses primarily based on the instruments or enter.
return_dict=True, # Return the leads to dictionary format, which permits simpler entry to tokenized knowledge, inputs, and different outputs.
return_tensors="pt" # Specifies that the output ought to be returned as PyTorch tensors. That is helpful in case you're working with fashions in a PyTorch-based setting.
)
inputs = {ok: v.to(mannequin.gadget) for ok, v in inputs.gadgets()} # Strikes all of the enter tensors to the identical gadget (CPU/GPU) because the mannequin.
outputs = mannequin.generate(**inputs, max_new_tokens=128)
response = tokenizer.decode(outputs(0)(len(inputs("input_ids")(0)):), skip_special_tokens=True)# Decodes the mannequin's output tokens again into human-readable textual content.
print(response)Ausgabe : ({„identify“: „get_current_temperature“, „arguments“: {„location“: „Delhi, Indien“, „unit“: „celsius“}})
Schritt 3: Generieren einer eindeutigen Instrument-Name-ID (Mistral-spezifisch)
Es wird verwendet, um Werkzeugaufrufe eindeutig zu identifizieren und mit ihren entsprechenden Antworten abzugleichen, um Konsistenz und Fehlerbehandlung bei komplexen Interaktionen mit externen Werkzeugen sicherzustellen
import json
import random
import string
import reGenerieren Sie eine zufällige tool_call_id
Es wird verwendet, um Werkzeugaufrufe eindeutig zu identifizieren und mit ihren entsprechenden Antworten abzugleichen, um Konsistenz und Fehlerbehandlung bei komplexen Interaktionen mit externen Werkzeugen sicherzustellen.
tool_call_id = ''.be a part of(random.selections(string.ascii_letters + string.digits, ok=9))Hängen Sie den Instrument-Aufruf an die Konversation an
messages.append({"function": "assistant", "tool_calls": ({"kind": "operate", "id": tool_call_id, "operate": response})})print(messages)Ausgabe :

Schritt 4: Antwort im JSON-Format analysieren
strive :
tool_call = json.masses(response)(0)
besides :
# Step 1: Extract the JSON-like half utilizing regex
json_part = re.search(r'(.*)', response, re.DOTALL).group(0)
# Step 2: Convert it to a listing of dictionaries
tool_call = json.masses(json_part)(0)
tool_callAusgabe : {‚identify‘: ‚get_current_temperature‘, ‚arguments‘: {‚location‘: ‚Delhi, Indien‘, ‚unit‘: ‚celsius‘}}
(Hinweis): In einigen Fällen kann das Modell neben den Funktionsinformationen und Argumenten auch einige Texte erzeugen. Der „Exception“-Block kümmert sich darum, die genaue Syntax aus der Ausgabe zu extrahieren
Schritt 5: Funktionen ausführen und Ergebnisse erhalten
Basierend auf den vom Modell generierten Argumenten übergeben Sie diese an die jeweilige Funktion, um sie auszuführen und die Ergebnisse zu erhalten.
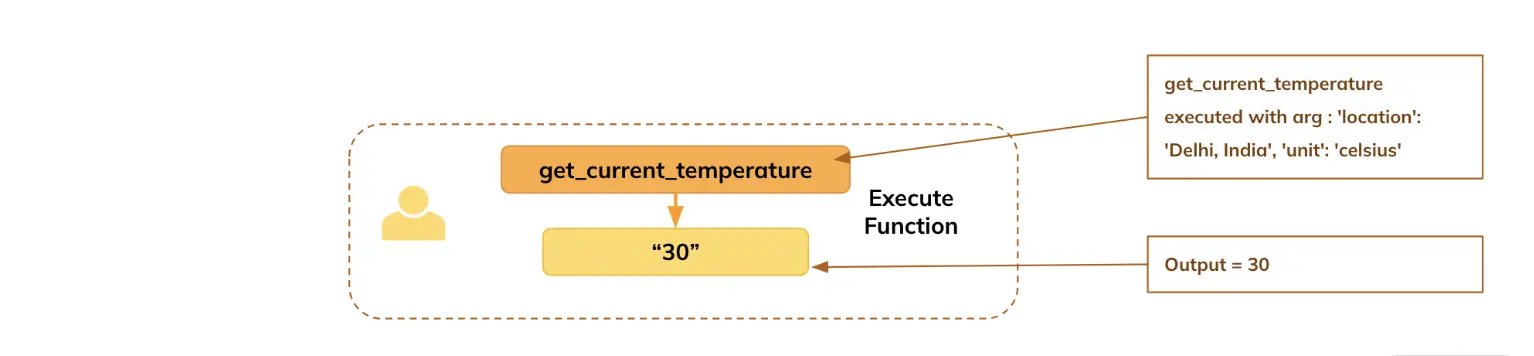
function_name = tool_call("identify") # Extracting the identify of the software (operate) from the tool_call dictionary.
arguments = tool_call("arguments") # Extracting the arguments for the operate from the tool_call dictionary.
temperature = get_current_temperature(**arguments) # Calling the "get_current_temperature" operate with the extracted arguments.
messages.append({"function": "software", "tool_call_id": tool_call_id, "identify": "get_current_temperature", "content material": str(temperature)})Schritt 6: Generieren der endgültigen Antwort basierend auf der Funktionsausgabe
## Now this record accommodates all the data : question and performance particulars, operate execution particulars and the output of the operate
print(messages)Ausgabe

Vorbereiten der Eingabeaufforderung für die Übergabe vollständiger Informationen an das Modell
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = {ok: v.to(mannequin.gadget) for ok, v in inputs.gadgets()}Modell generiert endgültige Antwort
Schließlich generiert das Modell die endgültige Antwort basierend auf der gesamten Konversation, die mit der Anfrage des Benutzers beginnt, und zeigt sie dem Benutzer an.
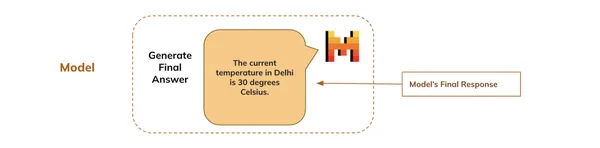
- Eingänge : Entpackt das Eingabewörterbuch, das tokenisierte Daten enthält, die das Modell zum Generieren von Textual content benötigt.
- max_new_tokens=128: Begrenzt die generierte Antwort auf maximal 128 neue Token und verhindert so, dass das Modell übermäßig lange Antworten generiert
outputs = mannequin.generate(**inputs, max_new_tokens=128)
final_response = tokenizer.decode(outputs(0)(len(inputs("input_ids")(0)):),skip_special_tokens=True)
## Last response
print(final_response)Ausgabe: Die aktuelle Temperatur in Delhi beträgt 30 Grad Celsius.
Abschluss
Wir haben unseren ersten Agenten entwickelt, der uns Temperaturstatistiken rund um den Globus in Echtzeit liefern kann! Natürlich haben wir eine zufällige Temperatur als Standardwert verwendet, aber Sie können diese mit Wetter-APIs verbinden, die Echtzeitdaten abrufen.
Technisch gesehen konnten wir basierend auf der Anfrage des Benutzers in natürlicher Sprache die erforderlichen Argumente vom LLM abrufen, um die Funktion auszuführen, die Ergebnisse herausholen und dann vom LLM eine Antwort in natürlicher Sprache generieren.
Was wäre, wenn wir die anderen Faktoren wie Windgeschwindigkeit, Luftfeuchtigkeit und UV-Index wissen wollten? : Wir müssen nur die Funktionen für diese Faktoren definieren und sie im übergeben Werkzeuge Argument der Chat-Vorlage. Auf diese Weise können wir einen umfassenden Wetteragenten erstellen, der Zugriff auf Wetterinformationen in Echtzeit hat.
Wichtige Erkenntnisse
- KI-Agenten nutzen LLMs, um Aufgaben in verschiedenen Bereichen autonom auszuführen.
- Die Integration von Funktionsaufrufen mit LLMs ermöglicht eine strukturierte Entscheidungsfindung und Automatisierung.
- Mistral 7B ist ein effektives Modell für die Implementierung von Funktionsaufrufen in realen Anwendungen.
- Entwickler können Funktionen mithilfe von JSON-Schemas definieren, sodass LLMs die erforderlichen Argumente effizient generieren können.
- KI-Agenten können Echtzeitinformationen wie Wetteraktualisierungen abrufen und so die Benutzerinteraktionen verbessern.
- Sie können ganz einfach neue Funktionen hinzufügen, um die Fähigkeiten von KI-Agenten über verschiedene Domänen hinweg zu erweitern.
Häufig gestellte Fragen
A. Durch Funktionsaufrufe in LLMs kann das Modell vordefinierte Funktionen basierend auf Benutzereingaben ausführen und so strukturierte Interaktionen mit externen Systemen oder APIs ermöglichen.
A. Mistral 7B zeichnet sich durch Anweisungsbefolgungsaufgaben aus und kann autonom Funktionsargumente generieren, wodurch es für Anwendungen geeignet ist, die einen Datenabruf in Echtzeit erfordern.
A. JSON-Schemas definieren die Struktur der von LLMs verwendeten Funktionen und ermöglichen es den Modellen, die notwendigen Argumente für diese Funktionen basierend auf Benutzereingaben zu verstehen und zu generieren.
A. Sie können KI-Agenten für die Handhabung verschiedener Funktionen entwerfen, indem Sie mehrere Funktionen definieren und diese in das Toolset des Agenten integrieren.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.