Z.ai bringt sein Flaggschiff-KI-Modell der nächsten Technology auf den Markt und hat es GLM-5.1 getauft. Mit seiner Kombination aus umfangreicher Modellgröße, betrieblicher Effizienz und überlegenen Argumentationsfunktionen stellt das Modell einen großen Fortschritt bei großen Sprachmodellen dar. Das System verbessert gegenüber früheren GLM-Modellen durch die Einführung einer erweiterten Funktion Mischung aus Experten Framework, das es ermöglicht, komplizierte mehrstufige Vorgänge schneller und mit präziseren Ergebnissen durchzuführen.
GLM-5.1 ist außerdem leistungsstark, da es die Entwicklung agentenbasierter Systeme unterstützt, die erweiterte Argumentationsfähigkeiten erfordern. Das Modell bietet sogar neue Funktionen, die sowohl die Codierungsfunktionen als auch das Verständnis langer Kontexte verbessern. All dies beeinflusst die tatsächlichen KI-Anwendungen und die Arbeitsprozesse der Entwickler.
Dies lässt keinen Zweifel daran, dass es sich bei der Einführung des GLM-5.1 um ein wichtiges Replace handelt. Hier konzentrieren wir uns genau darauf und erfahren alles über den neuen GLM-5.1 und seine Fähigkeiten.
GLM-5.1 Modellarchitekturkomponenten
GLM-5.1 baut auf modernen auf LLM-Designprinzipien durch die Kombination von Effizienz, Skalierbarkeit und Langkontextverarbeitung in einer einheitlichen Architektur. Durch die Fähigkeit, bis zu 100 Milliarden Parameter zu verarbeiten, trägt es zur Aufrechterhaltung der betrieblichen Effizienz bei. Dies ermöglicht eine praktische Leistung im täglichen Betrieb.
Das System verwendet a hybrider Aufmerksamkeitsmechanismus zusammen mit einer optimierten Decodierungspipeline. Dies ermöglicht eine effektive Ausführung von Aufgaben, die den Umgang mit langen Dokumenten, die Argumentation und die Codegenerierung erfordern.
Hier sind alle Komponenten, aus denen sich die Architektur zusammensetzt:
- Combination-of-Consultants (MoE): Das MoE-Modell verfügt über 744 Milliarden Parameter, die es auf 256 Experten aufteilt. Das System implementiert High-8-Routing, das es acht Experten ermöglicht, an jedem Token zu arbeiten, plus einem Experten, der über alle Token hinweg arbeitet. Das System benötigt etwa 40 Milliarden Parameter für jeden Token.
- Aufmerksamkeit: Das System verwendet zwei Arten von Aufmerksamkeitsmethoden. Dazu gehören Multi-Head Latent Consideration und DeepSeek Sparse Consideration. Das System kann bis zu 200.000 Token verarbeiten, da seine maximale Kapazität 202.752 Token erreicht. Das KV-Cache-System verwendet komprimierte Daten, die auf LoRA-Rang 512 und Kopfdimension 64 arbeiten, um die Systemleistung zu verbessern.
- Struktur: Das System enthält 78 Schichten, die mit einer versteckten Größe von 6144 arbeiten. Die ersten drei Schichten folgen einer standardmäßigen dichten Struktur, während die folgenden Schichten spärliche MoE-Blöcke implementieren.
- Spekulative Dekodierung (MTP): Der Decodierungsprozess wird durch Speculative Decoding schneller, da ein Multi-Token-Vorhersagekopf verwendet wird, der die gleichzeitige Vorhersage mehrerer Token ermöglicht.
GLM-5.1 erreicht seinen großen Umfang und sein erweitertes Kontextverständnis durch diese Funktionen, die weniger Rechenleistung erfordern als ein vollständig dichtes System.
So greifen Sie auf GLM-5.1 zu
Entwickler können GLM-5.1 auf verschiedene Arten nutzen. Die vollständigen Modellgewichte sind als Open-Supply-Software program unter der MIT-Lizenz verfügbar. Die folgende Liste enthält einige der verfügbaren Optionen:
- Hugging Face (MIT-Lizenz): Gewichte zum Obtain verfügbar. Als Mindestanforderung benötigt das System Enterprise-GPU-{Hardware}.
- Z.ai API/Codierungspläne: Der Dienst bietet direkten API-Zugriff zu einem Preis von etwa 1,00 US-Greenback professional Million Token und 3,20 US-Greenback professional Million Token. Das System funktioniert mit den aktuellen Claude- und OpenAI-System-Toolchains.
- Plattformen von Drittanbietern: Das System funktioniert mit Inferenz-Engines, zu denen OpenRouter und SGLang gehören, die voreingestellte GLM-5.1-Modelle unterstützen.
- Lokale Bereitstellung: Benutzer mit ausreichenden Hardwareressourcen können GLM-5.1 lokal über vLLM- oder SGLang-Instruments implementieren, wenn sie über mehrere B200-GPUs oder gleichwertige {Hardware} verfügen.
GLM-5.1 bietet offene Gewichtungen und kommerziellen API-Zugriff, wodurch es sowohl für Unternehmen als auch für Einzelpersonen verfügbar ist. Speziell für diesen Weblog werden wir den Hugging Face-Token verwenden, um auf dieses Modell zuzugreifen.
GLM-5.1-Benchmarks
Hier sind die verschiedenen Ergebnisse, die GLM-5.1 in verschiedenen Benchmarks erzielt hat.
Codierung
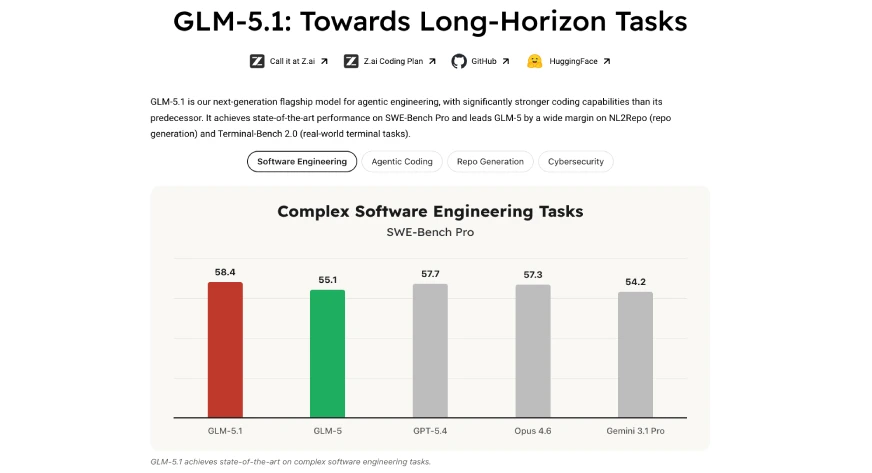
GLM-5.1 zeigt eine außergewöhnliche Fähigkeit, Programmieraufgaben zu erledigen. Seine Codierungsleistung erreichte auf SWE-Bench Professional einen Wert von 58,4 und übertraf damit sowohl GPT-5,4 (57,7) als auch Claude Opus 4.6 (57.3). GLM-5.1 erreichte in drei Codierungstests, darunter SWE-Bench Professional, Terminal-Bench 2.0 und CyberGym, eine Punktzahl von über 55 und sicherte sich damit weltweit den dritten Platz hinter GPT-5.4 (58,0) und Claude 4,6 (57,5) insgesamt. Das System übertrifft GLM-5 deutlich, was seine bessere Leistung bei Codierungsaufgaben mit Werten von 68,7 im Vergleich zu 48,3 zeigt. Das neue System ermöglicht es GLM-5.1, komplizierten Code mit größerer Genauigkeit als zuvor zu erstellen.
Agent
Der GLM-5.1 unterstützt Agenten-Workflows, die mehrere Schritte umfassen, die sowohl Planung als auch Codeausführung und Toolnutzung erfordern. Dieses System zeigt während längerer Betriebsperioden erhebliche Fortschritte. Durch seinen Betrieb auf der VectorDBBench Für die Optimierungsaufgabe führte GLM-5.1 655 Iterationen durch, die mehr als 6000 Toolfunktionen umfassten, um mehrere algorithmische Verbesserungen zu entdecken. Behält seinen Entwicklungspfad auch nach Erreichen von 1000 Werkzeugnutzungen bei, was seine Fähigkeit beweist, sich durch nachhaltige Optimierung kontinuierlich zu verbessern.
- VectorDBBench: Erzielte 21.500 QPS über 655 Iterationen (6-facher Gewinn) bei einer Indexoptimierungsaufgabe.
- KernelBench: 3,6-facher ML-Leistungszuwachs bei GPU-Kerneln gegenüber 2,6-fach bei GLM-5, weiterhin über 1000 Runden hinaus.
- Selbst-Debugging: Wie von Z.ai angegeben, hat er innerhalb von 8 Stunden einen kompletten Linux-Desktop-Stack von Grund auf erstellt (Planung, Assessments, Fehlerkorrektur).
Argumentation
GLM-5.1 liefert hervorragende Ergebnisse bei Standardtests zum logischen Denken und QA-Bewertungstests. Das System weist Leistungsergebnisse auf, die mit führenden Systemen zur allgemeinen Intelligenzbewertung übereinstimmen.
GLM-5.1 erreichte 95,3 % bei AIME, einem fortgeschrittenen Mathematikwettbewerb, und 86,2 % bei GPQA, bei dem fortgeschrittene Fähigkeiten zur Beantwortung von Fragen getestet werden. Die Ergebnisse nähern sich der höchsten Leistung der High-Systeme an, darunter GPT-5.4, das in zwei separaten Bewertungen 98,7 % und 94,3 % erreichte. GLM-5.1 weist umfangreiche akademische Fähigkeiten auf, die zu hohen Leistungen in mehreren Disziplinen und Olympia-Wettbewerben führen.
GLM-5.1-Funktionen
GLM-5.1 schneidet bei drei spezifischen Aufgaben außergewöhnlich intestine ab – langfristige Planung, Codegenerierung und logisches Denken mit mehreren Runden. Die Software program kann Computercode erstellen und debuggen, gleichzeitig schwierige Fragestellungen lösen und komplexe Aufgaben mit hervorragenden Ergebnissen ausführen. Das System ermöglicht es Entwicklern, „Agenten“ zu konstruieren, die seine Funktionsaufruf- und strukturierten Ausgabefunktionen nutzen, um mit verschiedenen Instruments zu interagieren. Die beiden hier gezeigten Aufgaben demonstrieren die Programmierfähigkeiten des Methods. Das System ermöglicht es Benutzern, Probleme durch Eingabeaufforderungen zu lösen, was zu präzisen Lösungen führt, die häufig Code enthalten.
Aufgabe 1: Ermitteln der Fakultät einer großen Zahl
Immediate:
„Hallo, Sie sind ein ausgezeichneter Code-Lehrer, additionally helfen Sie mir bei dieser Frage.
F. Schreiben Sie Python-Code zum Ermitteln der Fakultät einer großen Zahl.“
Antwort von GLM-5.1:
def factorial_large(n: int) -> str:
if n < 0: return ""
if n == 0: return "1"
# Array to retailer particular person digits (saved in reverse order for simpler carry dealing with)
res = (1)
for x in vary(2, n + 1):
carry = 0
# Multiply x with each digit within the present outcome
for i in vary(len(res)):
product = res(i) * x + carry
res(i) = product % 10
carry = product // 10
# Append the remaining carry to the outcome array
whereas carry:
res.append(carry % 10)
carry //= 10
# The digits are saved in reverse order, so reverse and be a part of them
return "".be a part of(map(str, res(::-1)))Ausgabe:

Urteil: Das System funktioniert effizient, da es einer Zwei-Punkte-Technik folgt und die besten Leistungsergebnisse liefert. Die Lösung verbraucht minimale Overhead-Ressourcen und implementiert gleichzeitig effektive Hilfsfunktionen. Die Implementierung liegt in einem kurzen Format vor, ohne vollständige Dokumentation und Kommentare. Dadurch eignet es sich besser für die schnelle Lösung von Problemen als für den Einsatz in Produktionsumgebungen, die lesbaren und wartbaren Code benötigen.
Aufgabe 2: Überprüfen, ob ein String ein Palindrom ist
Immediate:
„Hallo, Sie sind ein ausgezeichneter Code-Lehrer, additionally helfen Sie mir bei dieser Frage.
F. Geben Sie bei einer gegebenen Zeichenfolge s „true“ zurück, wenn s ein Palindrom sein kann, nachdem höchstens ein Zeichen daraus gelöscht wurde.“
Antwort von GLM-5.1:
def validPalindrome(s: str) -> bool:
def is_palindrome(l: int, r: int) -> bool:
whereas l < r:
if s(l) != s(r):
return False
l += 1
r -= 1
return True
left, proper = 0, len(s) - 1
whereas left < proper:
if s(left) != s(proper):
return is_palindrome(left + 1, proper) or is_palindrome(left, proper - 1)
left += 1
proper -= 1
return TrueAusgabe:

Urteil: Die Antwort von GLM-5.1 zeigt effiziente Leistung kombiniert mit technischer Validität. Es zeigt Kompetenz in der Ausführung umfangreicher numerischer Operationen durch manuelle Ziffernverarbeitung. Das System erreicht seine Entwurfsziele durch seine iterative Methode, die Leistung mit korrekter Ausgabe kombiniert. Die Implementierung liegt in einem Kurzformat vor und bietet eine begrenzte Dokumentation durch grundlegende Fehlerbehandlung. Dadurch ist der Code für die Algorithmenentwicklung geeignet, für den Produktionseinsatz jedoch ungeeignet, da diese Umgebung eine klare, erweiterbare und starke Leistung erfordert.
Gesamtüberblick über die GLM-5.1-Funktionen
GLM-5.1 bietet durch seine Open-Supply-Infrastruktur und sein ausgefeiltes Systemdesign mehrere Anwendungen. Dies ermöglicht es Entwicklern, tiefgreifende Argumentationsfunktionen, Funktionen zur Codegenerierung und Systeme zur Werkzeugnutzung zu erstellen. Das System behält alle bestehenden Stärken der GLM-Familie durch spärliche MoE- und Lengthy-Context-Funktionen bei. Außerdem werden neue Funktionen eingeführt, die adaptives Denken und die Ausführung von Debugging-Schleifen ermöglichen. Durch seine offenen Gewichte und kostengünstigen API-Optionen bietet das System Zugang zur Forschung und unterstützt gleichzeitig praktische Anwendungen in der Softwareentwicklung und anderen Bereichen.
Abschluss
Der GLM-5.1 ist ein lebendiges Beispiel dafür, wie aktuelle KI-Systeme ihre Effizienz und Skalierbarkeit entwickeln und gleichzeitig ihre Denkfähigkeiten verbessern. Mit seiner Combination-of-Consultants-Architektur garantiert es eine hohe Leistung bei gleichzeitig angemessenen Betriebskosten. Insgesamt ermöglicht dieses System die Handhabung realer KI-Anwendungen, die umfangreiche Operationen erfordern.
Während die KI auf sie zusteuert agentenbasierte Systeme und erweitertem Kontextverständnis schafft GLM-5.1 eine Grundlage für zukünftige Entwicklungen. Sein Routing-System und sein Aufmerksamkeitsmechanismus schaffen zusammen mit seinem Multi-Token-Vorhersagesystem neue Möglichkeiten für kommende große Sprachmodelle.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.