Reinforcement Studying – Lernen aus Beobachtungen und Belohnungen – ist die Methode, die der Artwork und Weise, wie Menschen (und Tiere) lernen, am ähnlichsten ist.
Trotz dieser Ähnlichkeit bleibt es auch der komplizierteste und problematischste Bereich des modernen maschinellen Lernens. Um den berühmten Andej Karpathy zu zitieren:
Reinforcement Studying ist schrecklich. Es ist einfach so, dass alles, was wir vorher hatten, viel schlimmer struggle.
Um das Verständnis der Methode zu erleichtern, werde ich ein Schritt-für-Schritt-Beispiel eines Agenten erstellen, der mithilfe von Q-Studying lernt, in einer Umgebung zu navigieren. Der Textual content beginnt mit den ersten Prinzipien und endet mit einem voll funktionsfähigen Beispiel, das Sie in der Unity-Spiel-Engine ausführen können.
Für diesen Artikel sind Grundkenntnisse der Programmiersprache C# erforderlich. Wenn Sie mit der Unity-Spiel-Engine nicht vertraut sind, bedenken Sie einfach, dass jedes Objekt ein Agent ist, der:
- ausführt
Begin()einmal zu Beginn des Programms, - Und
Replace()kontinuierlich parallel zu den anderen Agenten.
Das zugehörige Repository für diesen Artikel ist verfügbar GitHub. Alle Bilder stammen vom Autor, sofern nicht anders angegeben.
Was ist Reinforcement Studying?
Beim Reinforcement Studying (RL) haben wir einen Agenten, der in der Lage ist, Maßnahmen zu ergreifen, die Ergebnisse dieser Maßnahmen zu beobachten und aus Belohnungen/Strafen für diese Maßnahmen zu lernen.

Die Artwork und Weise, wie ein Agent in einem bestimmten Zustand über eine Aktion entscheidet, hängt von ihm ab Politik. Eine Politik π ist eine Funktion, die das Verhalten eines Agenten definiert und Zustände Aktionen zuordnet. Gegeben eine Reihe von Zuständen S und eine Reihe von Aktionen A Eine Richtlinie ist eine direkte Zuordnung: π: S → A .
Wenn wir außerdem möchten, dass der Agent mehr mögliche Optionen mit einer Auswahl hat, können wir eine erstellen Stochastische Politik. Dann bestimmt eine Richtlinie anstelle einer einzelnen Aktion die Wahrscheinlichkeit, jede Aktion in einem bestimmten Zustand zu ergreifen: π: S × A → (0, 1).
Beispiel für einen navigierenden Roboter
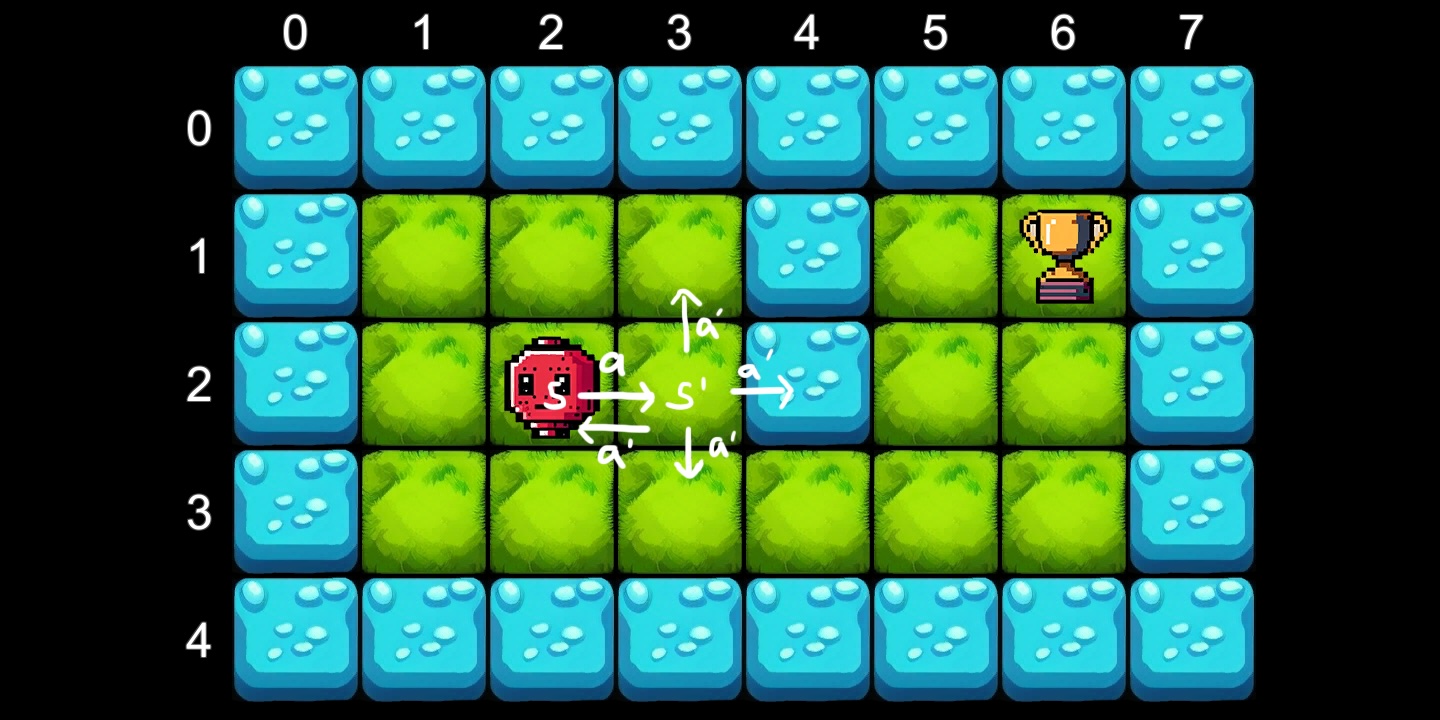
Um den Lernprozess zu veranschaulichen, erstellen wir ein Beispiel eines navigierenden Roboters in einer 2D-Umgebung und verwenden dabei eine von vier Aktionen: A = {Left, Proper, Up, Down} . Der Roboter muss zu jedem Zeitpunkt auf der Karte den Weg zur Auszeichnung finden, ohne ins Wasser zu fallen.

Die Belohnungen werden zusammen mit den Kacheltypen mithilfe einer Enum codiert:
public enum TileEnum { Water = -1, Grass = 0, Award = 1 }Der Zustand wird durch seine Place im Raster angegeben, was bedeutet, dass wir 40 mögliche Zustände haben: S = (0…7) × (0…4) (ein 8 × 5-Kachelgitter), das wir mithilfe eines 2D-Arrays codieren:
_map = {
{ -1, -1, -1, -1, -1, -1, -1, -1 }, // all water border
{ -1, 0, 0, 0, -1, 0, 1, -1 }, // 1 = Award (trophy)
{ -1, 0, 0, 0, -1, 0, 0, -1 },
{ -1, 0, 0, 0, 0, 0, 0, -1 },
{ -1, -1, -1, -1, -1, -1, -1, -1 }, // all water border
}Wir speichern die Karte in einer Kachel TileGrid das die folgenden Hilfsfunktionen hat:
// Acquire a tile at a coordinate
public T GetTileByCoords<T>(int x, int y);
// Given a tile and an motion, get hold of the following tile
public T GetTargetTile<T>(T supply, ActionEnum motion);
// Create a tile grid from the map
public void GenerateTiles();Wir werden verschiedene Kacheltypen verwenden, daher das Allgemeine T. Jede Kachel hat eine TileType gegeben durch die TileEnum und daher auch seine Belohnung, die als erhalten werden kann (int) TileType.
Die Bellman-Gleichung
Das Downside, eine optimale Richtlinie zu finden, kann mithilfe von iterativ gelöst werden Bellman-Gleichung. Die Bellman-Gleichung postuliert, dass die langfristige Belohnung einer Aktion gleich der unmittelbaren Belohnung für diese Aktion ist Plus die erwartete Belohnung aller zukünftigen Aktionen.
Es kann iterativ für Systeme mit diskreten Zuständen und diskreten Zustandsübergängen berechnet werden. Haben:
s— aktueller Stand,A— Menge aller Aktionen,s'— Zustand, der durch das Ergreifen einer Aktion erreicht wirdaim Staats,γ— Abzinsungsfaktor (je weiter die Belohnung, desto geringer ihr Wert),R(s, a)— sofortige Belohnung für das Handelnaim Staats
Die Bellman-Gleichung gibt dann den Wert an V(s) eines Staates s Ist:

Iteratives Lösen der Bellman-Gleichung
Die Berechnung der Bellman-Gleichung ist ein dynamisches Programmierproblem. Bei jeder Iteration nberechnen wir die erwartete zukünftige Belohnung, die in erreichbar ist n+1 Schritte für alle Kacheln. Für jede Kachel speichern wir dies mit a Worth Variable.
Wir vergeben eine Belohnung basierend auf dem Zielplättchen, d. h 1 wenn die Auszeichnung erreicht wird, -1 im Roboter fällt ins Wasser, und 0 ansonsten. Sobald entweder Auszeichnung oder Wasser erreicht sind, sind keine Aktionen mehr möglich, daher bleibt der Wert des Zustands auf dem Anfangswert 0 .
Wir erstellen einen Supervisor, der das Raster generiert und die Iterationen berechnet:
non-public void Begin()
{
tileGrid.GenerateTiles();
}
non-public void Replace()
{
CalculateValues();
Step();
}Um den Überblick über die Werte zu behalten, verwenden wir a VTile Klasse, die a enthält Worth. Um zu vermeiden, dass aktualisierte Werte direkt übernommen werden, legen wir zunächst fest NextValue und stellen Sie dann alle Werte auf einmal im ein Step() Funktion.
non-public float gamma = 0.9; // Discounting issue
// The Bellman equation
non-public double GetNewValue(VTile tile)
{
return Agent.Actions
.Choose(a => tileGrid.GetTargetTile(tile, a))
.Choose(t => t.Reward + gamma * t.Worth) // Reward in (1, 0, -1)
.Max();
}
// Get subsequent values for all tiles
non-public void CalculateValues()
{
for (var y = 0; y < TileGrid.BOARD_HEIGHT; y++)
{
for (var x = 0; x < TileGrid.BOARD_WIDTH; x++)
{
var tile = tileGrid.GetTileByCoords<VTile>(x, y);
if (tile.TileType == TileEnum.Grass)
{
tile.NextValue = GetNewValue(tile);
}
}
}
}
// Copy subsequent values to present values (iteration step)
non-public void Step()
{
for (var y = 0; y < TileGrid.BOARD_HEIGHT; y++)
{
for (var x = 0; x < TileGrid.BOARD_WIDTH; x++)
{
tileGrid.GetTileByCoords<VTile>(x, y).Step();
}
}
}Bei jedem Schritt der Wert V(s) Der Wert jedes Plättchens wird über alle Aktionen hinweg auf das Most der unmittelbaren Belohnung plus dem reduzierten Wert des resultierenden Plättchens aktualisiert. Die zukünftige Belohnung breitet sich vom Auszeichnungsplättchen nach außen aus, wobei die abnehmende Rendite von gesteuert wird γ = 0.9 .

Aktionsqualität (Q-Werte)
Wir haben einen Weg gefunden, Zustände mit Werten zu verknüpfen, was für dieses Wegfindungsproblem ausreicht. Hierbei steht jedoch die Umgebung im Mittelpunkt und der Agent wird außer Acht gelassen. Für einen Agenten möchten wir normalerweise wissen, was in der Umgebung eine gute Aktion wäre.
Im Q-Studying wird dieser Wert einer Aktion als ihr bezeichnet Qualität (Q-Wert). Jede (state, motion) Dem Paar wird ein einzelner Q-Wert zugewiesen.

Wo der neue Hyperparameter α definiert eine Lernrate – wie schnell neue Informationen alte überschreiben. Dies ist analog zum standardmäßigen maschinellen Lernen und die Werte sind normalerweise ähnlich, hier verwenden wir 0.005 . Anschließend berechnen wir den Nutzen einer Maßnahme anhand der zeitlichen Differenz D(s,a):

Da wir nicht mehr alle Aktionen im aktuellen Zustand betrachten, sondern die Qualität jeder Aktion einzeln, maximieren wir nicht über alle möglichen Aktionen im aktuellen Zustand, sondern über alle möglichen Aktionen in dem Zustand, den wir erreichen werden, nachdem wir die Aktion ausgeführt haben, deren Qualität wir berechnen, kombiniert mit der Belohnung für die Durchführung dieser Aktion.

Der zeitliche Differenzterm kombiniert die unmittelbare Belohnung mit der bestmöglichen zukünftigen Belohnung und ist somit eine direkte Ableitung der Bellman-Gleichung (siehe Wiki für Particulars).
Um den Agenten zu trainieren, instanziieren wir erneut ein Raster, aber dieses Mal erstellen wir auch eine Instanz des Agenten, platziert unter (2,2).
non-public Agent _agent;
non-public void ResetAgentPos()
{
_agent.State = tileGrid.GetTileByCoords<QTile>(2, 2);
}
non-public void Begin()
{
tileGrid.GenerateTiles();
_agent = Instantiate(agentPrefab, rework);
ResetAgentPos();
}
non-public void Replace()
{
Step();
}Ein Agent Objekt hat einen aktuellen Zustand QState. Jede QStatebehält den Q-Wert für jede verfügbare Aktion bei. Bei jedem Schritt aktualisiert der Agent die Qualität jeder im Standing verfügbaren Aktion:
non-public void Step()
{
if (_agent.State.TileType != TileEnum.Grass)
{
ResetAgentPos();
}
else
{
QTile s = _agent.State;
// Replace Q-values for ALL actions from present state
foreach (var a in Agent.Actions)
{
double q = s.GetQValue(a);
QTile sPrime = tileGrid.GetTargetTile(s, a);
double r = sPrime.Reward;
double qMax = Agent.Actions.Choose(sPrime.GetQValue).Max();
double td = r + gamma * qMax - q;
s.SetQValue(a, q + alpha * td);
}
// Take the most effective obtainable motion a
ActionEnum chosen = PickAction(s);
_agent.State = tileGrid.GetTargetTile(s, chosen);
}
}Ein Agent verfügt über eine Reihe möglicher Maßnahmen in jedem Bundesstaat und wird in jedem Bundesstaat die besten Maßnahmen ergreifen.
Gibt es mehrere beste Aktionen, wird eine davon zufällig ausgewählt, da wir die Aktionen zuvor gemischt haben. Aufgrund dieser Zufälligkeit verläuft jedes Coaching anders, stabilisiert sich jedoch im Allgemeinen zwischen 500 und 1000 Schritten.
Dies ist die Grundlage von Q-Studying. Anders als die ZustandswerteDie Aktionsqualität kann in Situationen angewendet werden, in denen:
- die Beobachtung ist jeweils unvollständig (Sichtfeld des Agenten)
- die Beobachtung ändert sich (Objekte bewegen sich in der Umgebung)
Exploration vs. Ausbeutung (ε-Grasping)
Bisher hat der Agent jedes Mal die bestmögliche Aktion durchgeführt, was jedoch dazu führen kann, dass der Agent schnell in einem lokalen Optimum stecken bleibt. Eine zentrale Herausforderung beim Q-Studying ist der Kompromiss zwischen Exploration und Exploitation:
- Ausnutzen – Wählen Sie die Aktion mit dem höchsten bekannten Q-Wert (gierig).
- Erkunden – Wählen Sie eine zufällige Aktion aus, um potenziell bessere Pfade zu entdecken.
ε-Gierige Politik
Gegeben ein zufälliger Wert r ∈ (0, 1) und Parameter epsilon Es gibt zwei Möglichkeiten:
- Wenn
r > epsilonWählen Sie dann die beste Aktion aus (ausbeuten), - andernfalls wählen Sie eine zufällige Aktion (erkunden).
Verfallendes Epsilon
Normalerweise möchten wir frühzeitig mehr erforschen und später mehr ausnutzen. Dies wird durch Zerfall erreicht epsilon im Laufe der Zeit:
epsilon = max(epsilonMin, epsilon − epsilonDecay)Nach genügend Schritten konvergiert die Strategie des Agenten dahingehend, dass er quick immer die Aktion mit der höchsten Qualität auswählt.
non-public epsilonMin = 0.05;
non-public epsilonDecay = 0.005;
non-public ActionEnum PickAction(QTile state) {
ActionEnum motion = Random.Vary(0f, 1f) > epsilon
? Agent.Actions.Shuffle().OrderBy(state.GetQValue).Final() // exploit
: Agent.RndAction(); // discover
epsilon = Mathf.Max(epsilonMin, epsilon - epsilonDecay);
return motion;
}Das breitere RL-Ökosystem
Q-Studying ist ein Algorithmus innerhalb einer größeren Familie von Reinforcement Studying (RL)-Methoden. Algorithmen können entlang mehrerer Achsen kategorisiert werden:
- Zustandsraum: Diskret (z. B. Brettspiele) | Kontinuierlich (z. B. FPS-Spiele)
- Aktionsraum: Diskret (z. B. Strategiespiele) | Kontinuierlich (z. B. Autofahren)
- Richtlinientyp: Off-Coverage (Q-Studying:
a’ist immer maximiert) | Richtlinienkonform (SARSA:a’wird durch die aktuelle Richtlinie des Agenten ausgewählt) - Operator: Wert | Qualität | Vorteil
A(s, a) = Q(s, a) − V(s)
Eine umfassende Liste der RL-Algorithmen finden Sie im Wikipedia-Seite zum Reinforcement Studying. Weitere Methoden wie das Behavioral Cloning sind dort nicht aufgeführt, kommen aber auch in der Praxis zum Einsatz. Reale Lösungen nutzen typischerweise erweiterte Varianten oder Kombinationen der oben genannten.
Q-Studying ist eine Off-Coverage-Methode mit diskretem Handeln. Die Ausweitung auf kontinuierliche Zustands-/Aktionsräume führt zu Methoden wie Deep Q-Networks (DQN), die die Q-Tabelle durch ein neuronales Netzwerk ersetzen.
Im Beispiel der Grid-Welt hat die Q-Tabelle |S| × |A| = 40 × 4 = 160 Einträge – perfekt überschaubar. Aber für ein Spiel wie Schach ist der Zustandsraum größer 10⁴⁴ Positionen, wodurch eine explizite Tabelle nicht gespeichert oder gefüllt werden kann. In solchen Fällen können neuronale Netze zur Komprimierung der Informationen eingesetzt werden.

(s, a) Paar verwendet das Netzwerk den Zustand als Eingabe und gibt Q-Werte für alle Aktionen aus und verallgemeinert so ähnliche Zustände, die es noch nie zuvor gesehen hat.Praktisches Verstärkungslernen in Spielen
Der obige Textual content soll eine grundlegende Einführung in das Konzept der Reinforcement Studying Brokers bieten. In der Praxis ist es natürlich unwahrscheinlich, dass Sie einen RL-Algorithmus manuell implementieren.
Die Unity-Engine stellt ein RL-Paket bereit ML-Agentendie z. B. zum Trainieren genutzt werden kann Autorennen. In den Frontier Labs wird die Erforschung von RL-Methoden in großem Maßstab unter Verwendung von Spielumgebungen durchgeführt, beispielsweise dem Versteckspiel:
Die Modelle aus diesen Labors haben in komplexen Brettspielen wie z. B. bereits den besten Spieler der Welt geschlagen Gehenschnelle Strategien wie Starcraft Und Dotaund sogar Spiele, die Kommunikation auf menschlicher Ebene erfordern, wie z Diplomatie.