
Sie haben das berühmte Zitat „Daten sind das neue Öl“ des britischen Mathematikers Clive Humby gehört. Es ist das einflussreichste Zitat, das die Bedeutung von Daten im 21. Jahrhundert beschreibt, aber nach der explosiven Entwicklung der Daten Großes Sprachmodell und sein Coaching, was wir nicht richtig haben, sind die Daten. denn die Entwicklungsgeschwindigkeit und Trainingsgeschwindigkeit des LLM-Modells übertreffen nahezu die Datengenerierungsgeschwindigkeit des Menschen. Die Lösung besteht darin, die Daten verfeinert und spezifischer für die Aufgabe oder die Generierung synthetischer Daten zu machen. Bei Ersterem handelt es sich um Aufgaben, die stärker von Fachexperten beansprucht werden, bei Letzterem geht es jedoch eher um die große Nachfrage nach heutigen Problemen.
Die qualitativ hochwertigen Trainingsdaten bleiben ein kritischer Engpass. In diesem Blogbeitrag wird ein praktischer Ansatz zur Generierung synthetischer Daten untersucht Lama 3.2 Und Ollama. Es wird gezeigt, wie wir strukturierte Bildungsinhalte programmatisch erstellen können.
Lernergebnisse
- Verstehen Sie die Bedeutung und Techniken der lokalen synthetischen Datengenerierung für die Verbesserung des Modelltrainings für maschinelles Lernen.
- Erfahren Sie, wie Sie die lokale synthetische Datengenerierung implementieren, um qualitativ hochwertige Datensätze zu erstellen und gleichzeitig Datenschutz und Sicherheit zu wahren.
- Erwerben Sie praktische Kenntnisse über die Implementierung robuster Fehlerbehandlungs- und Wiederholungsmechanismen in Datengenerierungspipelines.
- Lernen Sie JSON-Validierung, Reinigungstechniken und ihre Rolle bei der Aufrechterhaltung konsistenter und zuverlässiger Ausgaben kennen.
- Entwickeln Sie Fachwissen im Entwerfen und Verwenden von Pydantic-Modellen, um die Integrität von Datenschemata sicherzustellen.
Was sind synthetische Daten?
Unter synthetischen Daten versteht man künstlich generierte Informationen, die die Eigenschaften realer Daten nachahmen und gleichzeitig wesentliche Muster und statistische Eigenschaften bewahren. Es wird mithilfe von Algorithmen, Simulationen oder KI-Modellen erstellt, um Datenschutzbedenken auszuräumen, begrenzte Daten zu erweitern oder Systeme in kontrollierten Szenarien zu testen. Im Gegensatz zu echten Daten können synthetische Daten auf spezifische Anforderungen zugeschnitten werden und sorgen so für Vielfalt, Ausgewogenheit und Skalierbarkeit. Es wird häufig in Bereichen wie maschinellem Lernen, Gesundheitswesen, Finanzen und autonomen Systemen eingesetzt, um Modelle zu trainieren, Algorithmen zu validieren oder Umgebungen zu simulieren. Synthetische Daten schließen die Lücke zwischen Datenknappheit und realen Anwendungen und reduzieren gleichzeitig ethische und Compliance-Risiken.
Warum brauchen wir heute synthetische Daten?
Die Nachfrage nach synthetischen Daten ist aufgrund mehrerer Faktoren exponentiell gestiegen
- Datenschutzbestimmungen: Mit der DSGVO und ähnlichen Vorschriften bieten synthetische Daten eine sichere Various für Entwicklung und Checks
- Kosteneffizienz: Das Sammeln und Kommentieren realer Daten ist teuer und zeitaufwändig.
- Skalierbarkeiten: Synthetische Daten können in großen Mengen mit kontrollierten Variationen generiert werden
- Kantenabdeckung: Wir können Daten für seltene Szenarien generieren, die auf natürliche Weise möglicherweise nur schwer zu erfassen sind
- Schnelles Prototyping: Schnelle Iteration von ML-Modellen, ohne auf die tatsächliche Datenerfassung warten zu müssen.
- Weniger voreingenommen: Die aus der realen Welt gesammelten Daten können fehleranfällig und voller geschlechtsspezifischer Vorurteile und rassistischer Texte sein und für Kinderwörter nicht sicher sein. Wenn additionally ein Modell mit dieser Artwork von Daten erstellt werden soll, muss das Verhalten des Modells ebenfalls von Natur aus mit diesen Vorurteilen verknüpft sein. Mit synthetischen Daten können wir diese Verhaltensweisen leicht kontrollieren.
Auswirkungen auf die Leistung von LLM und Small LM
Synthetische Daten haben vielversprechende Ergebnisse bei der Verbesserung sowohl großer als auch kleiner Sprachmodelle gezeigt
- Feinabstimmung der Effizienz: Auf hochwertigen synthetischen Daten fein abgestimmte Modelle zeigen oft eine vergleichbare Leistung wie Modelle, die auf realen Daten trainiert wurden
- Area-Anpassung: Synthetische Daten helfen dabei, Domänenlücken in speziellen Anwendungen zu schließen
- Datenerweiterung: Die Kombination synthetischer und realer Daten führt oft zu besseren Ergebnissen, wenn beide allein verwendet werden.
Projektstruktur und Umgebungseinrichtung
Im folgenden Abschnitt werden wir das Projektlayout aufschlüsseln und Sie durch die Konfiguration der erforderlichen Umgebung führen.
mission/
├── most important.py
├── necessities.txt
├── README.md
└── english_QA_new.jsonJetzt richten wir unsere Projektumgebung mit Conda ein. Befolgen Sie die folgenden Schritte
Erstellen Sie eine Conda-Umgebung
$conda create -n synthetic-data python=3.11
# activate the newly created env
$conda activate synthetic-dataInstallieren Sie Bibliotheken in Conda Env
pip set up pydantic langchain langchain-community
pip set up langchain-ollamaJetzt sind wir bereit, mit der Code-Implementierung zu beginnen
Projektumsetzung
In diesem Abschnitt befassen wir uns mit der praktischen Umsetzung des Projekts und gehen auf jeden Schritt im Element ein.
Bibliotheken importieren
Bevor wir das Projekt starten, erstellen wir eine Datei mit dem Namen most important.py im Projektstamm und importieren alle Bibliotheken in dieser Datei:
from pydantic import BaseModel, Subject, ValidationError
from langchain.prompts import PromptTemplate
from langchain_ollama import OllamaLLM
from typing import Listing
import json
import uuid
import re
from pathlib import Path
from time import sleepJetzt ist es an der Zeit, mit der Codeimplementierung in der Datei most important.py fortzufahren
Zunächst beginnen wir mit der Implementierung des Datenschemas.
Das GermanFragendatenschema ist ein pydantisches Modell, das sicherstellt, dass unsere generierten Daten einer konsistenten Struktur mit erforderlichen Feldern und automatischer ID-Generierung folgen.
Code-Implementierung
class EnglishQuestion(BaseModel):
id: str = Subject(
default_factory=lambda: str(uuid.uuid4()),
description="Distinctive identifier for the query",
)
class: str = Subject(..., description="Query Sort")
query: str = Subject(..., description="The English language query")
reply: str = Subject(..., description="The proper reply to the query")
thought_process: str = Subject(
..., description="Clarification of the reasoning course of to reach on the reply"
)Jetzt haben wir die Datenklasse EnglishQuestion erstellt.
Zweitens beginnen wir mit der Implementierung der QuestionGenerator-Klasse. Diese Klasse ist der Kern der Projektumsetzung.
QuestionGenerator-Klassenstruktur
class QuestionGenerator:
def __init__(self, model_name: str, output_file: Path):
cross
def clean_json_string(self, textual content: str) -> str:
cross
def parse_response(self, outcome: str) -> EnglishQuestion:
cross
def generate_with_retries(self, class: str, retries: int = 3) -> EnglishQuestion:
cross
def generate_questions(
self, classes: Listing(str), iterations: int
) -> Listing(EnglishQuestion):
cross
def save_to_json(self, query: EnglishQuestion):
cross
def load_existing_data(self) -> Listing(dict):
crossLassen Sie uns Schritt für Schritt die Schlüsselmethoden implementieren
Initialisierung
Initialisieren Sie die Klasse mit einem Sprachmodell, einer Eingabeaufforderungsvorlage und einer Ausgabedatei. Damit erstellen wir eine Instanz von OllamaLLM mit Modellname und richten eine PromptTemplate zum Generieren von QA in einem strikten JSON-Format ein.
Code-Implementierung:
def __init__(self, model_name: str, output_file: Path):
self.llm = OllamaLLM(mannequin=model_name)
self.prompt_template = PromptTemplate(
input_variables=("class"),
template="""
Generate an English language query that assessments understanding and utilization.
Deal with {class}.Query will probably be like fill within the blanks,One liner and mut not be MCQ sort. write Output on this strict JSON format:
{{
"query": "<your particular query>",
"reply": "<the right reply>",
"thought_process": "<Clarify reasoning to reach on the reply>"
}}
Don't embrace any textual content outdoors of the JSON object.
""",
)
self.output_file = output_file
self.output_file.contact(exist_ok=True)JSON-Reinigung
Antworten, die wir während des Generierungsprozesses vom LLM erhalten, enthalten viele unnötige zusätzliche Zeichen, die die generierten Daten beeinträchtigen können. Daher müssen Sie diese Daten einem Bereinigungsprozess unterziehen.
Hier werden wir das häufige Formatierungsproblem in JSON-Schlüsseln/-Werten mithilfe von Regex beheben und problematische Zeichen wie Zeilenumbrüche und Sonderzeichen ersetzen.
Code-Implementierung:
def clean_json_string(self, textual content: str) -> str:
"""Improved model to deal with malformed or incomplete JSON."""
begin = textual content.discover("{")
finish = textual content.rfind("}")
if begin == -1 or finish == -1:
increase ValueError(f"No JSON object discovered. Response was: {textual content}")
json_str = textual content(begin : finish + 1)
# Take away any particular characters that may break JSON parsing
json_str = json_str.exchange("n", " ").exchange("r", " ")
json_str = re.sub(r"(^x20-x7E)", "", json_str)
# Repair frequent JSON formatting points
json_str = re.sub(
r'(?<!)"((^")*?)(?<!)":', r'"1":', json_str
) # Repair key formatting
json_str = re.sub(
r':s*"((^")*?)(?<!)"(?=s*(,}))', r': "1"', json_str
) # Repair worth formatting
return json_strAntwortanalyse
Die Parsing-Methode verwendet den oben genannten Bereinigungsprozess, um die Antworten aus dem LLM zu bereinigen, die Antwort auf Konsistenz zu validieren, den bereinigten JSON in ein Python-Wörterbuch zu konvertieren und das Wörterbuch einem EnglishQuestion-Objekt zuzuordnen.
Code-Implementierung:
def parse_response(self, outcome: str) -> EnglishQuestion:
"""Parse the LLM response and validate it towards the schema."""
cleaned_json = self.clean_json_string(outcome)
parsed_result = json.hundreds(cleaned_json)
return EnglishQuestion(**parsed_result)Datenpersistenz
Für die dauerhafte Datengenerierung können wir hierfür zwar einige NoSQL-Datenbanken (MongoDB usw.) verwenden, hier verwenden wir jedoch eine einfache JSON-Datei zum Speichern der generierten Daten.
Code-Implementierung:
def load_existing_data(self) -> Listing(dict):
"""Load current questions from the JSON file."""
attempt:
with open(self.output_file, "r") as f:
return json.load(f)
besides (FileNotFoundError, json.JSONDecodeError):
return ()Robuste Technology
In dieser Datengenerierungsphase haben wir zwei wichtigste Methoden:
- Mit Wiederholungsmechanismus generieren
- Methode zur Fragengenerierung
Der Zweck des Wiederholungsmechanismus besteht darin, die Automatisierung zu zwingen, im Fehlerfall eine Antwort zu generieren. Es wird mehrmals versucht, eine Frage zu generieren (der Standardwert ist dreimal), es werden Fehler protokolliert und eine Verzögerung zwischen den Wiederholungsversuchen hinzugefügt. Es wird auch eine Ausnahme ausgelöst, wenn alle Versuche fehlschlagen.
Code-Implementierung:
def generate_with_retries(self, class: str, retries: int = 3) -> EnglishQuestion:
for try in vary(retries):
attempt:
outcome = self.prompt_template | self.llm
response = outcome.invoke(enter={"class": class})
return self.parse_response(response)
besides Exception as e:
print(
f"Try {try + 1}/{retries} failed for class '{class}': {e}"
)
sleep(2) # Small delay earlier than retry
increase ValueError(
f"Did not course of class '{class}' after {retries} makes an attempt."
)Die Methode zur Fragengenerierung generiert mehrere Fragen für eine Liste von Kategorien und speichert sie im Speicher (hier JSON-Datei). Es durchläuft die Kategorien und ruft für jede Kategorie die Methode generic_with_retries auf. Und im letzten Schritt wird jede erfolgreich generierte Frage mit der Methode save_to_json gespeichert.
def generate_questions(
self, classes: Listing(str), iterations: int
) -> Listing(EnglishQuestion):
"""Generate a number of questions for an inventory of classes."""
all_questions = ()
for _ in vary(iterations):
for class in classes:
attempt:
query = self.generate_with_retries(class)
self.save_to_json(query)
all_questions.append(query)
print(f"Efficiently generated query for class: {class}")
besides (ValidationError, ValueError) as e:
print(f"Error processing class '{class}': {e}")
return all_questionsAnzeige der Ergebnisse auf dem Terminal
Um eine Vorstellung davon zu bekommen, welche Antworten LLM liefert, finden Sie hier eine einfache Druckfunktion.
def display_questions(questions: Listing(EnglishQuestion)):
print("nGenerated English Questions:")
for query in questions:
print("n---")
print(f"ID: {query.id}")
print(f"Query: {query.query}")
print(f"Reply: {query.reply}")
print(f"Thought Course of: {query.thought_process}")Testen der Automatisierung
Erstellen Sie vor der Ausführung Ihres Projekts eine Datei english_QA_new.json im Projektstammverzeichnis.
if __name__ == "__main__":
OUTPUT_FILE = Path("english_QA_new.json")
generator = QuestionGenerator(model_name="llama3.2", output_file=OUTPUT_FILE)
classes = (
"phrase utilization",
"Phrasal Ver",
"vocabulary",
"idioms",
)
iterations = 2
generated_questions = generator.generate_questions(classes, iterations)
display_questions(generated_questions)
Gehen Sie nun zum Terminal und geben Sie Folgendes ein:
python most important.pyAusgabe:

Diese Fragen werden in Ihrem Projektstamm gespeichert. Die gespeicherte Frage sieht folgendermaßen aus:
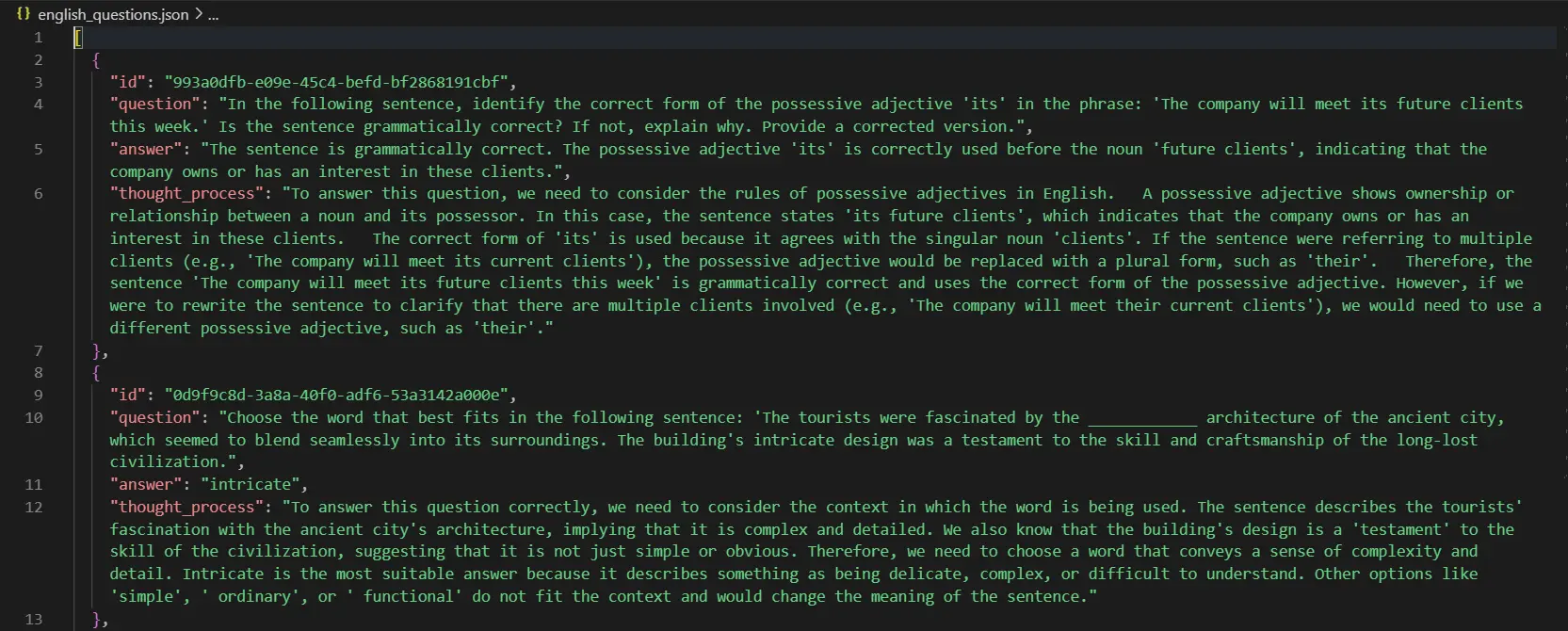
Der gesamte in diesem Projekt verwendete Code ist Hier.
Abschluss
Die Generierung synthetischer Daten hat sich als leistungsstarke Lösung herausgestellt, um der wachsenden Nachfrage nach hochwertigen Trainingsdatensätzen im Zeitalter der rasanten Fortschritte bei KI und LLMs gerecht zu werden. Durch den Einsatz von Instruments wie LLama 3.2 und Ollama sowie robusten Frameworks wie Pydantic können wir strukturierte, skalierbare und verzerrungsfreie Datensätze erstellen, die auf spezifische Anforderungen zugeschnitten sind. Dieser Ansatz verringert nicht nur die Abhängigkeit von der kostspieligen und zeitaufwändigen Erfassung realer Daten, sondern gewährleistet auch Datenschutz und ethische Compliance. Während wir diese Methoden verfeinern, werden synthetische Daten weiterhin eine entscheidende Rolle dabei spielen, Innovationen voranzutreiben, die Modellleistung zu verbessern und neue Möglichkeiten in verschiedenen Bereichen zu erschließen.
Wichtige Erkenntnisse
- Die lokale Generierung synthetischer Daten ermöglicht die Erstellung vielfältiger Datensätze, die die Modellgenauigkeit verbessern können, ohne die Privatsphäre zu beeinträchtigen.
- Die Implementierung der lokalen synthetischen Datengenerierung kann die Datensicherheit erheblich verbessern, indem die Abhängigkeit von sensiblen Daten aus der realen Welt minimiert wird.
- Synthetische Daten gewährleisten den Datenschutz, reduzieren Vorurteile und senken die Kosten für die Datenerfassung.
- Maßgeschneiderte Datensätze verbessern die Anpassungsfähigkeit an verschiedene KI- und LLM-Anwendungen.
- Synthetische Daten ebnen den Weg für eine ethische, effiziente und modern KI-Entwicklung.
Häufig gestellte Fragen
A. Ollama bietet lokale Bereitstellungsfunktionen, reduziert Kosten und Latenz und bietet gleichzeitig mehr Kontrolle über den Generierungsprozess.
A. Um die Qualität aufrechtzuerhalten, verwendet die Implementierung Pydantic-Validierung, Wiederholungsmechanismen und JSON-Bereinigung. Zusätzliche Metriken und Aufrechterhaltung der Validierung können implementiert werden.
A: Lokale LLMs haben im Vergleich zu größeren Modellen möglicherweise eine qualitativ schlechtere Ausgabe und die Generierungsgeschwindigkeit kann durch lokale Rechenressourcen begrenzt sein.
A. Ja, synthetische Daten gewährleisten den Datenschutz, indem sie identifizierbare Informationen entfernen, und fördern eine ethische KI-Entwicklung, indem sie Datenverzerrungen bekämpfen und die Abhängigkeit von sensiblen Daten aus der realen Welt verringern.
A. Zu den Herausforderungen gehören die Sicherstellung des Datenrealismus, die Wahrung der Domänenrelevanz und die Ausrichtung synthetischer Datenmerkmale auf reale Anwendungsfälle für ein effektives Modelltraining.
Als autodidaktischer, projektorientierter Lerner arbeitet er gerne an komplexen Projekten zu Deep Studying, Pc Imaginative and prescient und NLP. Ich versuche immer, ein tiefes Verständnis des Themas zu erlangen, das in jedem Bereich wie Deep Studying, maschinellem Lernen oder Physik liegen kann. Ich liebe es, Inhalte zu meinem Lernen zu erstellen. Versuchen Sie, mein Verständnis mit der Welt zu teilen.