
Objekterkennung ist von zentraler Bedeutung künstliche Intelligenzund dient als Rückgrat für zahlreiche hochmoderne Anwendungen. Von autonomen Fahrzeugen und Überwachungssystemen bis hin zu medizinischer Bildgebung und erweiterter Realität – die Fähigkeit, Objekte in Bildern und Movies zu identifizieren und zu lokalisieren, verändert Industrien weltweit. Die Objekterkennungs-API von TensorFlow, ein leistungsstarkes und vielseitiges Software, vereinfacht die Erstellung robuster Objekterkennungsmodelle. Durch die Nutzung dieser API können Entwickler benutzerdefinierte Modelle trainieren, die auf spezifische Anforderungen zugeschnitten sind, wodurch die Entwicklungszeit und -komplexität erheblich reduziert wird.
In diesem Leitfaden untersuchen wir Schritt für Schritt den Prozess des Trainierens eines Objekterkennungsmodells mit TensorFlow und konzentrieren uns dabei auf die Integration von Datensätzen aus Roboflow-Universumein umfangreiches Repository mit kommentierten Datensätzen, das die KI-Entwicklung beschleunigen soll.
Lernziele
- Erfahren Sie, wie Sie es einrichten und konfigurieren TensorFlow’s Objekterkennungs-API-Umgebung für effizientes Modelltraining.
- Erfahren Sie, wie Sie mithilfe des TFRecord-Codecs Datensätze für das Coaching vorbereiten und vorverarbeiten.
- Erwerben Sie Fachwissen bei der Auswahl und Anpassung eines vorab trainierten Objekterkennungsmodells für spezifische Anforderungen.
- Erfahren Sie, wie Sie Pipeline-Konfigurationsdateien anpassen und Modellparameter optimieren, um die Leistung zu optimieren.
- Beherrschen Sie den Trainingsprozess, einschließlich der Handhabung von Kontrollpunkten und der Bewertung der Modellleistung während des Trainings.
- Erfahren Sie, wie Sie das trainierte Modell zur Inferenz und Bereitstellung in realen Anwendungen exportieren.
Dieser Artikel wurde im Rahmen der veröffentlicht Knowledge Science-Blogathon.
Schrittweise Implementierung der Objekterkennung mit TensorFlow
In diesem Abschnitt führen wir Sie Schritt für Schritt durch die Implementierung der Objekterkennung mit TensorFlow und begleiten Sie von der Einrichtung bis zur Bereitstellung.
Schritt 1: Einrichten der Umgebung
Die TensorFlow Object Detection API erfordert verschiedene Abhängigkeiten. Beginnen Sie mit dem Klonen des TensorFlow-Modellrepositorys:
# Clone the tensorflow fashions repository from GitHub
!pip uninstall Cython -y # Non permanent repair for "No module named 'object_detection'" error
!git clone --depth 1 https://github.com/tensorflow/fashions- Cython deinstallieren: Dieser Schritt stellt sicher, dass es während des Setups zu keinen Konflikten mit der Cython-Bibliothek kommt.
- Klonen Sie das TensorFlow-Modell-Repository: Dieses Repository enthält die offiziellen Modelle von TensorFlow, einschließlich der Objekterkennungs-API.
Kopieren Sie die Setup-Dateien und ändern Sie die Datei setup.py
# Copy setup recordsdata into fashions/analysis folder
%%bash
cd fashions/analysis/
protoc object_detection/protos/*.proto --python_out=.
#cp object_detection/packages/tf2/setup.py .
# Modify setup.py file to put in the tf-models-official repository focused at TF v2.8.0
import re
with open('/content material/fashions/analysis/object_detection/packages/tf2/setup.py') as f:
s = f.learn()
with open('/content material/fashions/analysis/setup.py', 'w') as f:
# Set fine_tune_checkpoint path
s = re.sub('tf-models-official>=2.5.1',
'tf-models-official==2.8.0', s)
f.write(s)Warum ist das notwendig?
- Zusammenstellung der Protokollpuffer: Die Objekterkennungs-API verwendet .proto-Dateien, um Modellkonfigurationen und Datenstrukturen zu definieren. Diese müssen in Python-Code kompiliert werden, damit sie funktionieren.
- Kompatibilität der Abhängigkeitsversion: TensorFlow und seine Abhängigkeiten entwickeln sich weiter. Die Verwendung von tf-models-official>=2.5.1 kann versehentlich eine inkompatible Model für TensorFlow v2.8.0 installieren.
- Durch die explizite Einstellung von tf-models-official==2.8.0 werden mögliche Versionskonflikte vermieden und die Stabilität gewährleistet.
Abhängigkeitsbibliotheken installieren
TensorFlow-Modelle basieren häufig auf bestimmten Bibliotheksversionen. Durch die Korrektur der TensorFlow-Model wird eine reibungslose Integration gewährleistet.
# Set up the Object Detection API
# Have to do a brief repair with PyYAML as a result of Colab is not capable of set up PyYAML v5.4.1
!pip set up pyyaml==5.3
!pip set up /content material/fashions/analysis/
# Have to downgrade to TF v2.8.0 as a result of Colab compatibility bug with TF v2.10 (as of 10/03/22)
!pip set up tensorflow==2.8.0
# Set up CUDA model 11.0 (to keep up compatibility with TF v2.8.0)
!pip set up tensorflow_io==0.23.1
!wget https://developer.obtain.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
!mv cuda-ubuntu1804.pin /and many others/apt/preferences.d/cuda-repository-pin-600
!wget http://developer.obtain.nvidia.com/compute/cuda/11.0.2/local_installers/cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb
!dpkg -i cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb
!apt-key add /var/cuda-repo-ubuntu1804-11-0-local/7fa2af80.pub
!apt-get replace && sudo apt-get set up cuda-toolkit-11-0
!export LD_LIBRARY_PATH=/usr/native/cuda-11.0/lib64:$LD_LIBRARY_PATHWährend Sie diesen Block ausführen, müssen Sie die Sitzungen erneut starten und diesen Codeblock erneut ausführen, um alle Abhängigkeiten erfolgreich zu installieren. Dadurch werden alle Abhängigkeiten erfolgreich installiert.
Installieren einer geeigneten Model der Protobuf-Bibliothek zur Lösung von Abhängigkeitsproblemen
!pip set up protobuf==3.20.1
Schritt 2: Umgebung und Installationen überprüfen
Um zu bestätigen, dass die Set up funktioniert, führen Sie den folgenden Check durch:
# Run Mannequin Bulider Check file, simply to confirm every little thing's working correctly
!python /content material/fashions/analysis/object_detection/builders/model_builder_tf2_test.py
Wenn keine Fehler angezeigt werden, ist Ihre Einrichtung abgeschlossen. Nun haben wir die Einrichtung erfolgreich abgeschlossen.
Schritt 3: Bereiten Sie die Trainingsdaten vor
Für dieses Tutorial verwenden wir die „Personenerkennung“ Datensatz von Roboflow-Universum. Befolgen Sie diese Schritte, um es vorzubereiten:
Besuchen Sie die Datensatzseite:

Verzweigen Sie den Datensatz in Ihren Arbeitsbereich, um ihn für die Anpassung zugänglich zu machen.
Generieren Sie eine Model des Datensatzes, um seine Vorverarbeitungskonfigurationen wie Erweiterung und Größenänderung abzuschließen.
Laden Sie es jetzt im TFRecord-Format herunter, einem Binärformat, das für TensorFlow-Workflows optimiert ist. TFRecord speichert Daten effizient und ermöglicht TensorFlow das Lesen großer Datensätze während des Trainings mit minimalem Overhead.
Platzieren Sie nach dem Herunterladen die Datensatzdateien in Ihrem Google Drive, mounten Sie Ihren Code auf Ihrem Laufwerk und laden Sie diese Dateien in den Code, um ihn zu verwenden.
from google.colab import drive
drive.mount('/content material/gdrive')
train_record_fname="/content material/gdrive/MyDrive/photographs/prepare/prepare.tfrecord"
val_record_fname="/content material/gdrive/MyDrive/photographs/take a look at/take a look at.tfrecord"
label_map_pbtxt_fname="/content material/gdrive/MyDrive/photographs/label_map.pbtxt"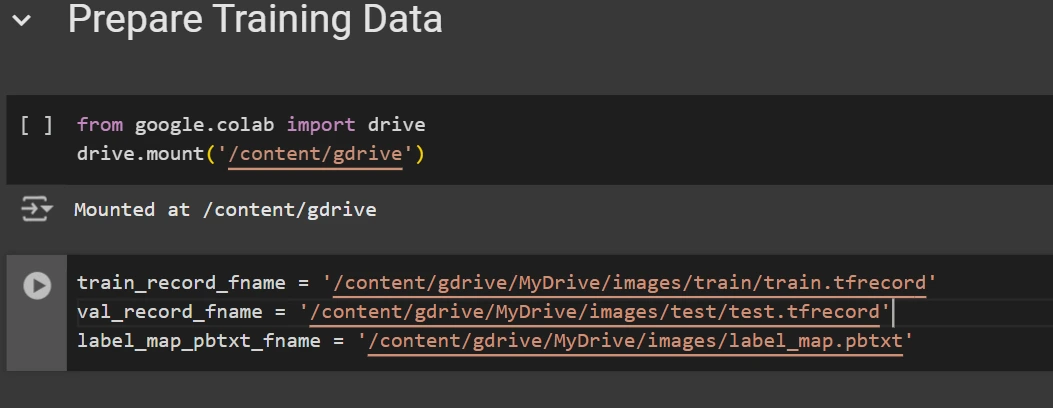
Schritt 4: Richten Sie die Trainingskonfiguration ein
Jetzt ist es an der Zeit, die Konfiguration für das Objekterkennungsmodell einzurichten. Für dieses Beispiel verwenden wir das Modell „efficientdet-d0“. Sie können aus anderen Modellen wie ssd-mobilenet-v2 oder ssd-mobilenet-v2-fpnlite-320 wählen, aber in diesem Leitfaden konzentrieren wir uns aufefficientdet-d0.
# Change the chosen_model variable to deploy totally different fashions obtainable within the TF2 object detection zoo
chosen_model="efficientdet-d0"
MODELS_CONFIG = {
'ssd-mobilenet-v2': {
'model_name': 'ssd_mobilenet_v2_320x320_coco17_tpu-8',
'base_pipeline_file': 'ssd_mobilenet_v2_320x320_coco17_tpu-8.config',
'pretrained_checkpoint': 'ssd_mobilenet_v2_320x320_coco17_tpu-8.tar.gz',
},
'efficientdet-d0': {
'model_name': 'efficientdet_d0_coco17_tpu-32',
'base_pipeline_file': 'ssd_efficientdet_d0_512x512_coco17_tpu-8.config',
'pretrained_checkpoint': 'efficientdet_d0_coco17_tpu-32.tar.gz',
},
'ssd-mobilenet-v2-fpnlite-320': {
'model_name': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8',
'base_pipeline_file': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8.config',
'pretrained_checkpoint': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8.tar.gz',
},
}
model_name = MODELS_CONFIG(chosen_model)('model_name')
pretrained_checkpoint = MODELS_CONFIG(chosen_model)('pretrained_checkpoint')
base_pipeline_file = MODELS_CONFIG(chosen_model)('base_pipeline_file')Anschließend laden wir die vorab trainierten Gewichte und die entsprechende Konfigurationsdatei für das gewählte Modell herunter:
# Create "mymodel" folder for holding pre-trained weights and configuration recordsdata
%mkdir /content material/fashions/mymodel/
%cd /content material/fashions/mymodel/
# Obtain pre-trained mannequin weights
import tarfile
download_tar="http://obtain.tensorflow.org/fashions/object_detection/tf2/20200711/" + pretrained_checkpoint
!wget {download_tar}
tar = tarfile.open(pretrained_checkpoint)
tar.extractall()
tar.shut()
# Obtain coaching configuration file for mannequin
download_config = 'https://uncooked.githubusercontent.com/tensorflow/fashions/grasp/analysis/object_detection/configs/tf2/' + base_pipeline_file
!wget {download_config}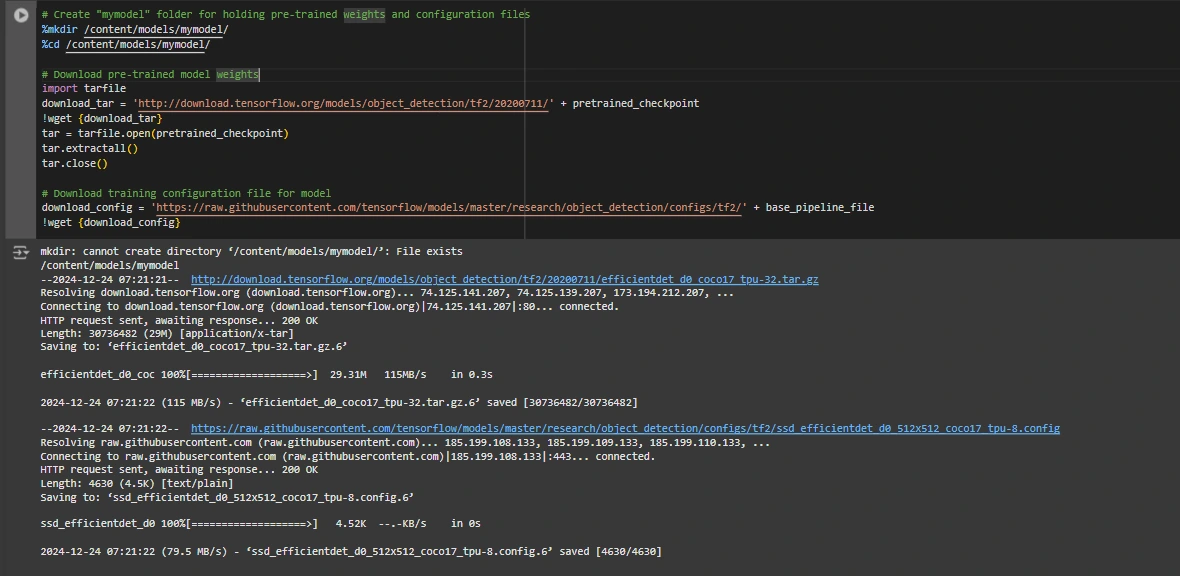
Danach richten wir die Anzahl der Trainingsschritte und die Batchgröße basierend auf dem ausgewählten Modell ein:
# Set coaching parameters for the mannequin
num_steps = 4000
if chosen_model == 'efficientdet-d0':
batch_size = 8
else:
batch_size = 8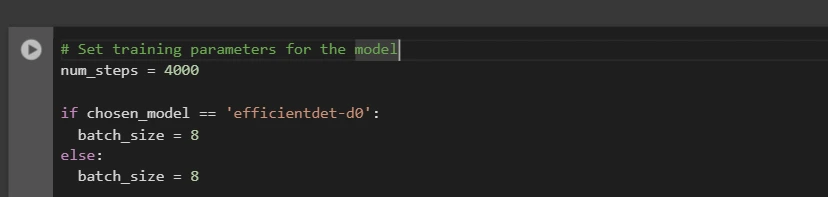
Sie können „num_steps“ und „batch_size“ entsprechend Ihren Anforderungen erhöhen und verringern.
Schritt 5: Ändern Sie die Pipeline-Konfigurationsdatei
Wir müssen die Datei „pipeline.config“ mit den Pfaden zu unseren Datensatz- und Modellparametern anpassen. Die Datei „pipeline.config“ enthält verschiedene Konfigurationen wie die Stapelgröße, die Anzahl der Klassen und Prüfpunkte zur Feinabstimmung. Wir nehmen diese Änderungen vor, indem wir die Vorlage lesen und die relevanten Felder ersetzen:
# Set file areas and get variety of courses for config file
pipeline_fname="/content material/fashions/mymodel/" + base_pipeline_file
fine_tune_checkpoint="/content material/fashions/mymodel/" + model_name + '/checkpoint/ckpt-0'
def get_num_classes(pbtxt_fname):
from object_detection.utils import label_map_util
label_map = label_map_util.load_labelmap(pbtxt_fname)
classes = label_map_util.convert_label_map_to_categories(
label_map, max_num_classes=90, use_display_name=True)
category_index = label_map_util.create_category_index(classes)
return len(category_index.keys())
num_classes = get_num_classes(label_map_pbtxt_fname)
print('Whole courses:', num_classes)
# Create customized configuration file by writing the dataset, mannequin checkpoint, and coaching parameters into the bottom pipeline file
import re
%cd /content material/fashions/mymodel
print('writing customized configuration file')
with open(pipeline_fname) as f:
s = f.learn()
with open('pipeline_file.config', 'w') as f:
# Set fine_tune_checkpoint path
s = re.sub('fine_tune_checkpoint: ".*?"',
'fine_tune_checkpoint: "{}"'.format(fine_tune_checkpoint), s)
# Set tfrecord recordsdata for prepare and take a look at datasets
s = re.sub(
'(input_path: ".*?)(PATH_TO_BE_CONFIGURED/prepare)(.*?")', 'input_path: "{}"'.format(train_record_fname), s)
s = re.sub(
'(input_path: ".*?)(PATH_TO_BE_CONFIGURED/val)(.*?")', 'input_path: "{}"'.format(val_record_fname), s)
# Set label_map_path
s = re.sub(
'label_map_path: ".*?"', 'label_map_path: "{}"'.format(label_map_pbtxt_fname), s)
# Set batch_size
s = re.sub('batch_size: (0-9)+',
'batch_size: {}'.format(batch_size), s)
# Set coaching steps, num_steps
s = re.sub('num_steps: (0-9)+',
'num_steps: {}'.format(num_steps), s)
# Set variety of courses num_classes
s = re.sub('num_classes: (0-9)+',
'num_classes: {}'.format(num_classes), s)
# Change fine-tune checkpoint kind from "classification" to "detection"
s = re.sub(
'fine_tune_checkpoint_type: "classification"', 'fine_tune_checkpoint_type: "{}"'.format('detection'), s)
# If utilizing ssd-mobilenet-v2, scale back studying charge (as a result of it is too excessive within the default config file)
if chosen_model == 'ssd-mobilenet-v2':
s = re.sub('learning_rate_base: .8',
'learning_rate_base: .08', s)
s = re.sub('warmup_learning_rate: 0.13333',
'warmup_learning_rate: .026666', s)
# If utilizing efficientdet-d0, use fixed_shape_resizer as an alternative of keep_aspect_ratio_resizer (as a result of it is not supported by TFLite)
if chosen_model == 'efficientdet-d0':
s = re.sub('keep_aspect_ratio_resizer', 'fixed_shape_resizer', s)
s = re.sub('pad_to_max_dimension: true', '', s)
s = re.sub('min_dimension', 'peak', s)
s = re.sub('max_dimension', 'width', s)
f.write(s)
# (Optionally available) Show the customized configuration file's contents
!cat /content material/fashions/mymodel/pipeline_file.config
# Set the trail to the customized config file and the listing to retailer coaching checkpoints in
pipeline_file="/content material/fashions/mymodel/pipeline_file.config"
model_dir="/content material/coaching/"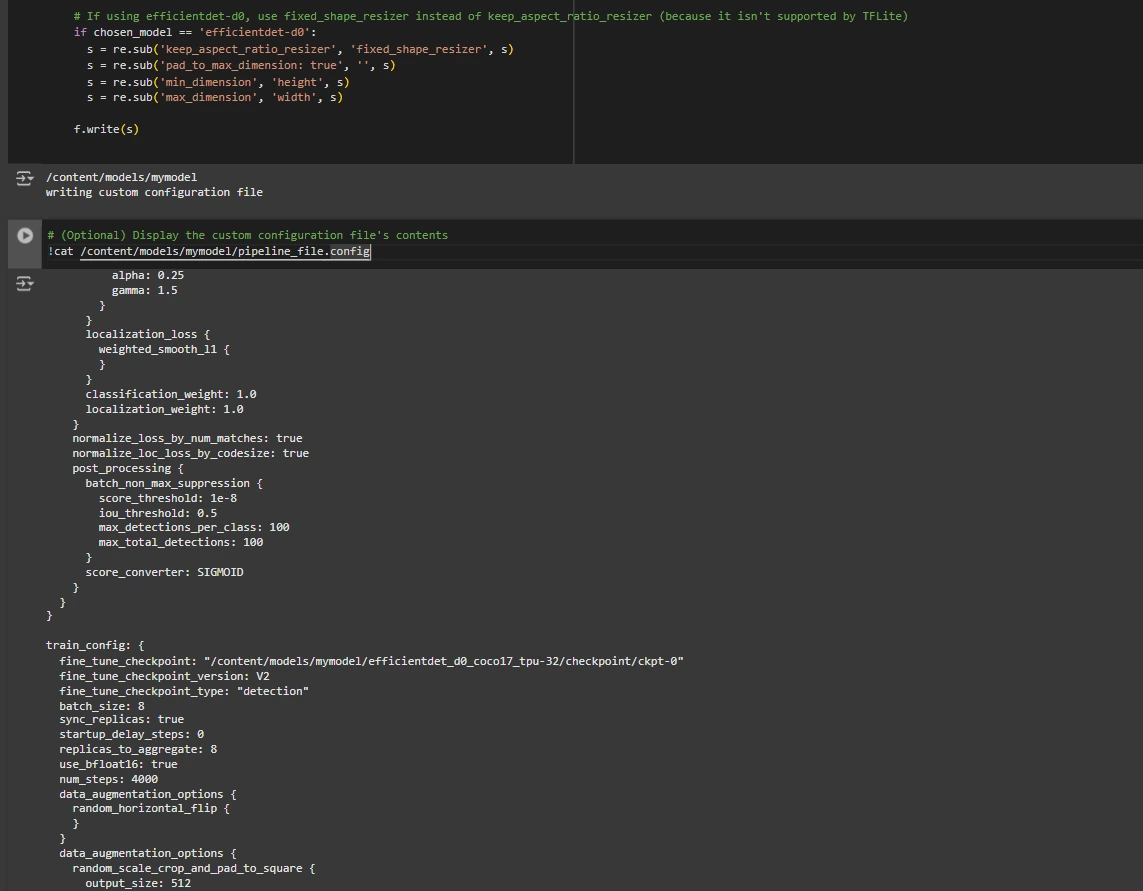
Schritt 6: Trainieren Sie das Modell
Jetzt können wir das Modell mithilfe der benutzerdefinierten Pipeline-Konfigurationsdatei trainieren. Das Trainingsskript speichert Prüfpunkte, mit denen Sie die Leistung Ihres Modells bewerten können:
# Run coaching!
!python /content material/fashions/analysis/object_detection/model_main_tf2.py
--pipeline_config_path={pipeline_file}
--model_dir={model_dir}
--alsologtostderr
--num_train_steps={num_steps}
--sample_1_of_n_eval_examples=1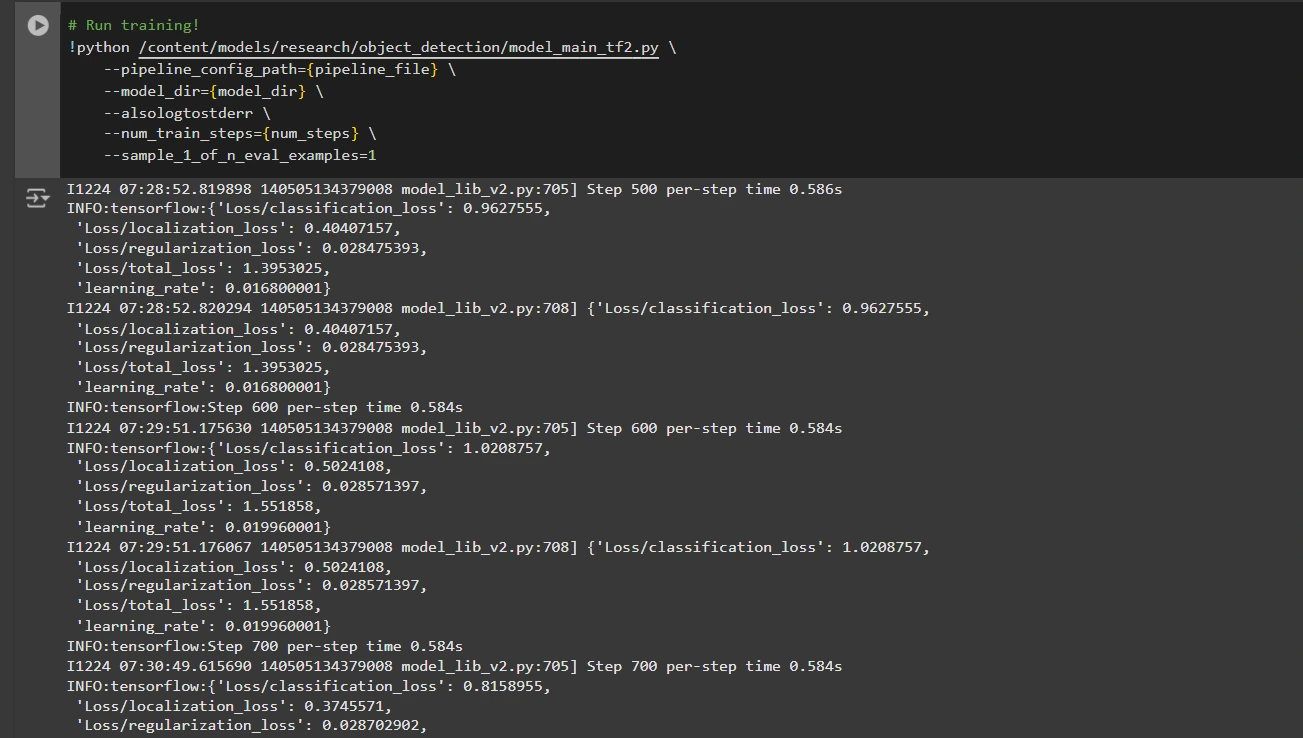
Schritt 7: Speichern Sie das trainierte Modell
Nach Abschluss des Trainings exportieren wir das trainierte Modell, damit es für Inferenzen verwendet werden kann. Wir verwenden das Skript exporter_main_v2.py, um das Modell zu exportieren:
!python /content material/fashions/analysis/object_detection/exporter_main_v2.py
--input_type image_tensor
--pipeline_config_path {pipeline_file}
--trained_checkpoint_dir {model_dir}
--output_directory /content material/exported_model
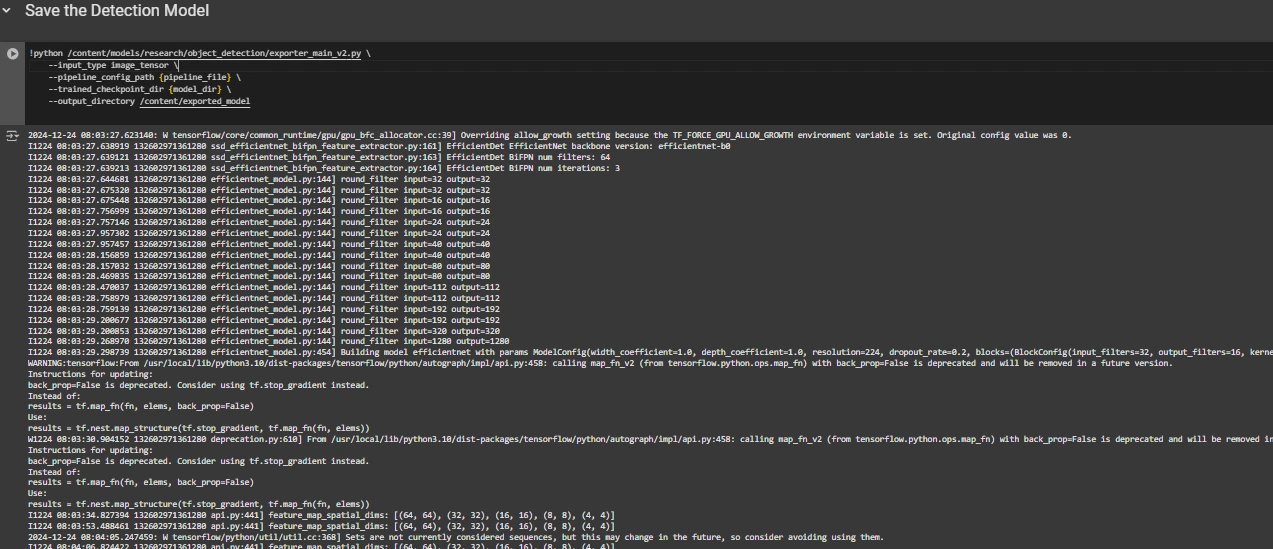
Zum Schluss komprimieren wir das exportierte Modell zum einfachen Herunterladen in eine ZIP-Datei. Anschließend können Sie die ZIP-Datei mit Ihrem trainierten Modell herunterladen:
import shutil
# Path to the exported mannequin folder
exported_model_path="/content material/exported_model"
# Path the place the zip file might be saved
zip_file_path="/content material/exported_model.zip"
# Create a zipper file of the exported mannequin folder
shutil.make_archive(zip_file_path.exchange('.zip', ''), 'zip', exported_model_path)
# Obtain the zip file utilizing Google Colab's file obtain utility
from google.colab import recordsdata
recordsdata.obtain(zip_file_path)
Sie können diese heruntergeladenen Modelldateien je nach Bedarf zum Testen an unsichtbaren Bildern oder in Ihren Anwendungen verwenden.
Darauf können Sie sich beziehen: Kollaborationsnotizbuch für detaillierten Code
Abschluss
Zusammenfassend stattet Sie dieser Leitfaden mit den Kenntnissen und Werkzeugen aus, die Sie zum Trainieren eines Objekterkennungsmodells mithilfe der Objekterkennungs-API von TensorFlow benötigen, wobei Datensätze aus Roboflow Universe für eine schnelle Anpassung genutzt werden. Indem Sie die beschriebenen Schritte befolgen, können Sie Ihre Daten effektiv vorbereiten, die Trainingspipeline konfigurieren, das richtige Modell auswählen und es an Ihre spezifischen Anforderungen anpassen. Darüber hinaus eröffnet die Möglichkeit, Ihr trainiertes Modell zu exportieren und bereitzustellen, enorme Möglichkeiten für reale Anwendungen, sei es in autonomen Fahrzeugen, medizinischen Bildgebungssystemen oder Überwachungssystemen. Mit diesem Workflow können Sie leistungsstarke, skalierbare Objekterkennungssysteme mit geringerer Komplexität und schnellerer Bereitstellung erstellen.
Wichtige Erkenntnisse
- Die TensorFlow Object Detection API bietet ein flexibles Framework zum Erstellen benutzerdefinierter Objekterkennungsmodelle mit vorab trainierten Optionen, wodurch Entwicklungszeit und Komplexität reduziert werden.
- Das TFRecord-Format ist für eine effiziente Datenverarbeitung, insbesondere bei großen Datensätzen in TensorFlow, unerlässlich und ermöglicht schnelles Coaching und minimalen Overhead.
- Pipeline-Konfigurationsdateien sind für die Feinabstimmung und Anpassung des Modells an Ihren spezifischen Datensatz und die gewünschten Leistungsmerkmale von entscheidender Bedeutung.
- Vorab trainierte Modelle wie „efficientdet-d0“ und „ssd-mobilenet-v2“ bieten solide Ausgangspunkte für das Coaching benutzerdefinierter Modelle, wobei jedes Modell je nach Anwendungsfall und Ressourcenbeschränkungen spezifische Stärken aufweist.
- Der Trainingsprozess umfasst die Verwaltung von Parametern wie Batch-Größe, Anzahl der Schritte und Modell-Checkpoints, um sicherzustellen, dass das Modell optimum lernt.
- Der Export des Modells ist unerlässlich, um das trainierte Objekterkennungsmodell in einem realen Modell zu verwenden, das gepackt wird und für die Bereitstellung bereit ist.
Häufig gestellte Fragen
A: Die TensorFlow Object Detection API ist ein flexibles Open-Supply-Framework zum Erstellen, Trainieren und Bereitstellen benutzerdefinierter Objekterkennungsmodelle. Es bietet Instruments zur Feinabstimmung vorab trainierter Modelle und zum Erstellen von Lösungen, die auf bestimmte Anwendungsfälle zugeschnitten sind.
A: TFRecord ist ein binäres Dateiformat, das für TensorFlow-Pipelines optimiert ist. Es ermöglicht eine effiziente Datenverarbeitung und gewährleistet ein schnelleres Laden, minimalen I/O-Overhead und ein reibungsloseres Coaching, insbesondere bei großen Datensätzen.
A: Diese Dateien ermöglichen eine nahtlose Modellanpassung, indem sie Parameter wie Datensatzpfade, Lernrate, Modellarchitektur und Trainingsschritte definieren, um bestimmte Datensätze und Leistungsziele zu erreichen.
A: Wählen Sie EfficientDet-D0 für ein ausgewogenes Verhältnis von Genauigkeit und Effizienz, preferrred für Edge-Geräte, und SSD-MobileNet-V2 für leichte, schnelle Echtzeitanwendungen wie cell Apps.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Ich bin Neha Dwivedi, eine Knowledge-Science-Enthusiastin und habe meinen Abschluss an der MIT World Peace College in Pune gemacht. Ich interessiere mich leidenschaftlich für Knowledge Science und die damit verbundenen steigenden Developments. Ich freue mich darauf, Erkenntnisse zu teilen und von dieser Group zu lernen!