
Suchen Sie nach einem Modell zur Implementierung der Posenschätzung? Ich kenne etwas, das Erkennung, Instanzsegmentierung, Posenschätzung und Klassifizierung durchführen kann, und das alles in Echtzeit. Ja, ich spreche vom YOLO26 von Ultralytika.
Es kann Sicherheitssysteme unterstützen oder fein abgestimmt werden, um auch kleinere Objekte zu erkennen. Sie fragen sich, wie Sie anfangen sollen? Keine Sorge, wir behandeln die Grundlagen von YOLO und lernen, mit dem Modell Inferenzen durchzuführen.
Hintergrundinformationen zu YOLO
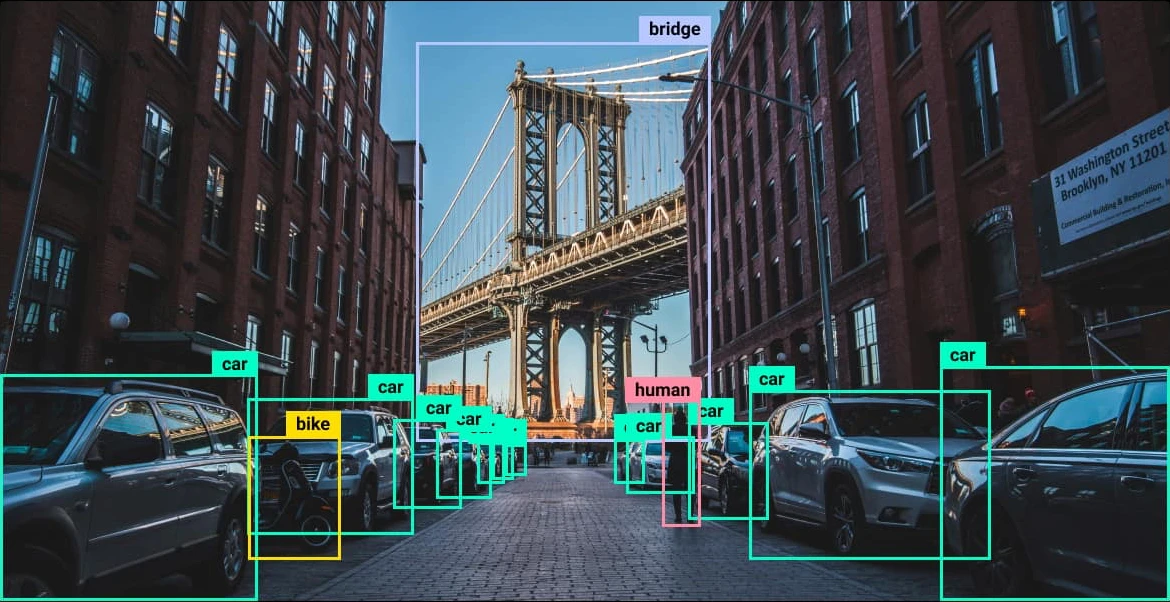
YOLO (Du siehst nur einmal aus) ist eine Familie von Deep-Studying-Modellen, die für Laptop-Imaginative and prescient-Aufgaben verwendet werden; Die grundlegende Logik ist die Verwendung von Lokalisierung und Klassifizierung. Vereinfacht ausgedrückt erkennt die Lokalisierung Objekte und ermittelt deren Koordinaten. Anschließend sagt der Klassifikator die Klassenwahrscheinlichkeiten voraus und weist diesem Objekt die wahrscheinlichste Klasse zu. Die neueste Modellfamilie von YOLO ist YOLO26. Wie bereits erwähnt, können sie Folgendes leisten:
- Objekterkennung: Findet ein oder mehrere Objekte in einem Bild und sagt deren Klassenkonfidenzwert und Begrenzungsrahmen voraus. Dadurch erfahren Sie, um welches Objekt es sich handelt und wo es sich befindet.
- Einstufung: Weist das Bild einer von 1000 ImageNet-Kategorien zu. Als endgültige Vorhersage wird die Klasse mit der höchsten Wahrscheinlichkeit ausgewählt.
- Posenschätzung: Erkennt die 17 Schlüsselpunkte des menschlichen Körpers, die durch definiert werden COCO-Datensatz. Dazu gehören Punkte wie Nase, Schultern, Ellenbogen, Knie und Knöchel, um die Haltung jeder Individual einzuschätzen.
- Oriented Bounding Field (OBB)-Erkennung: Prognostiziert gedrehte Begrenzungsrahmen mithilfe von fünf Parametern. xyw h und θ. Dies ist besonders nützlich für Luft- und Satellitenbilder, bei denen Objekte selten perfekt ausgerichtet erscheinen.
- Instanzsegmentierung: Erzeugt für jedes erkannte Objekt eine Maske auf Pixelebene. Dies hilft dabei, einzelne Objekte zu trennen, selbst wenn sie derselben Klasse angehören.
Diese Modelle weisen eine höhere Genauigkeit und bessere Effizienz auf als die vorherigen Modellgenerationen.
Architektur
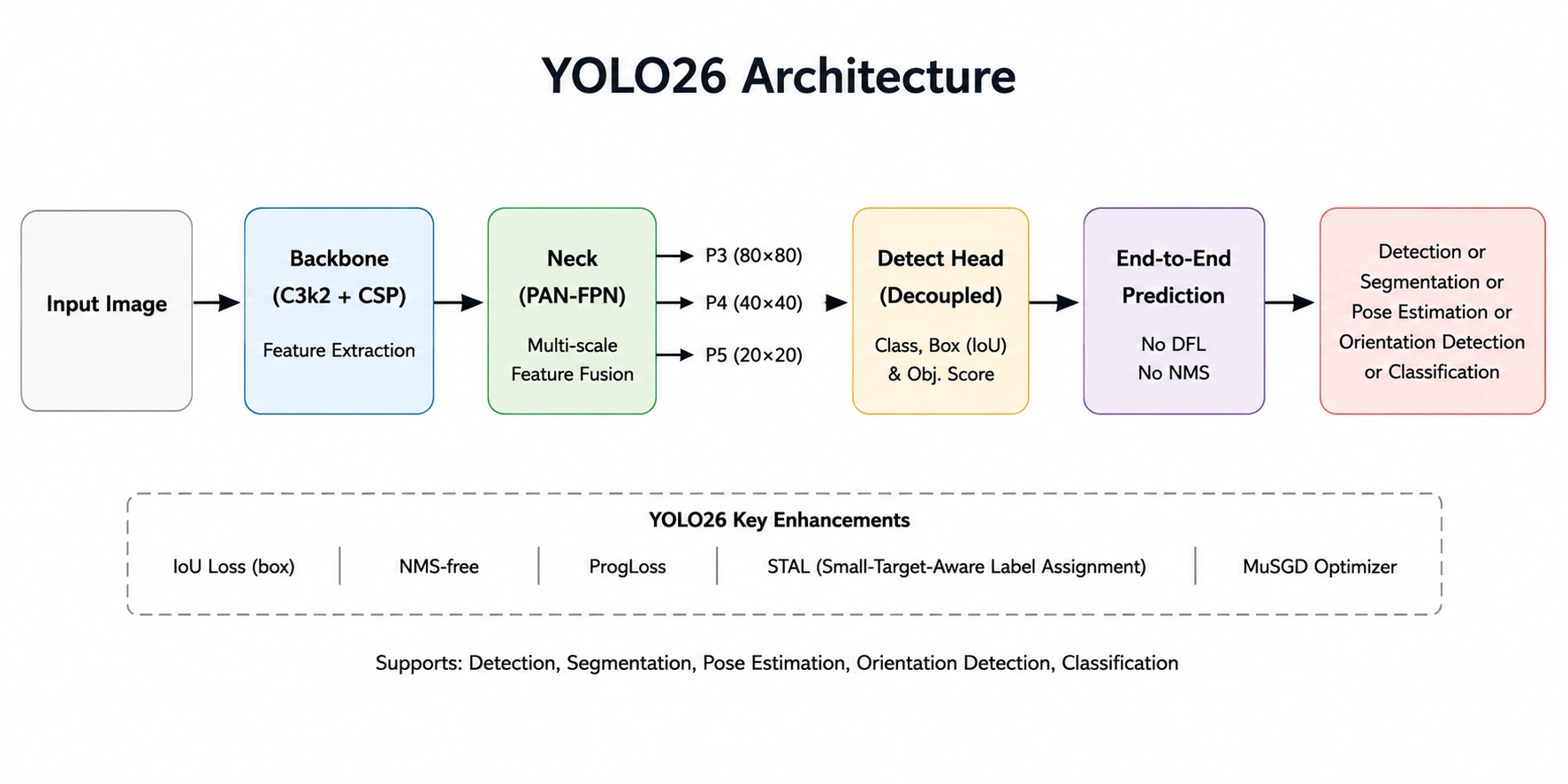
- Eingabebild: Die Größe des Eingabebilds wird geändert und normalisiert, bevor das Modell es verarbeitet.
- Rückgrat (C3k2 + CSP): Extrahiert Merkmale aus dem Bild wie Kanten, Texturen, Formen und Objektmuster.
- Hals (PAN-FPN): Führt die Fusion von P3, P4 und P5 durch. Dies trägt dazu bei, die Erkennung kleiner, mittlerer und großer Objekte zu verbessern.
- Erkennungskopf: Prognostiziert die Objektklassen, Begrenzungsrahmen und Konfidenzwerte mithilfe der zusammengeführten Function-Maps.
- Finish-to-Finish-Inferenz: Beseitigt einige Dinge, die in den vorherigen Generationen vorhanden waren, insbesondere DFL und NMS. Vereinfachung der Pipeline bei gleichzeitiger Verbesserung der Inferenzlatenz.
- Ausgabe: Objekterkennung, Segmentierung, Posenschätzung, Orientierungserkennung oder Klassifizierung.
Für den Kontext
- C3k2: Ein Function-Extraktionsblock, der kürzlich in YOLO-Modellen eingeführt wurde. Es verbessert das Function-Lernen mit weniger Parametern.
- PAN (Path Aggregation Community): Passt Merkmale auf niedriger und hoher Ebene in beide Richtungen und hilft so bei der präzisen Objekterkennung von Objekten unterschiedlicher Größe.
- FPN (Function Pyramid Community): Kombiniert Function-Maps aus mehreren Tiefen und hilft bei der Erkennung von Objekten in mehreren Maßstäben.
- P3 -> Function-Map mit hoher Auflösung, P4 -> Function-Map mit mittlerer Auflösung und P5 -> Function-Map mit niedriger Auflösung. Sie helfen dem Modell, kleine, mittlere und große Objekte zu erkennen.
Praktisch
Probieren wir YOLO26 mithilfe von Google Colab aus. Wir werden in erster Linie dieses Bild während der Schlussfolgerung verwenden:

Notiz: YOLO-Modelle erfordern keine Excessive-Finish-{Hardware}, sie können auch lokal in Jupyter Pocket book ausgeführt werden.
Installationen
!pip set up -q "ultralytics>=8.4.0" Hier wird „-q“ verwendet, um die Bibliothek und Abhängigkeiten zu installieren, ohne etwas anzuzeigen.
Hilfsfunktion definieren
from PIL import Picture
# helper perform
def present(consequence):
show(Picture.fromarray(consequence.plot()(..., ::-1)))Dies wird zur Anzeige der Ergebnisse verwendet.
Objekterkennung
from ultralytics import YOLO
IMAGE = "https://ultralytics.com/photographs/bus.jpg"
mannequin = YOLO("yolo26n.pt")
consequence = mannequin(IMAGE)(0)
present(consequence)
Das Modell hat den Bus und die Personen erfolgreich erkannt.
Instanzsegmentierung
seg_model = YOLO("yolo26n-seg.pt")
consequence = seg_model(IMAGE)(0)
present(consequence)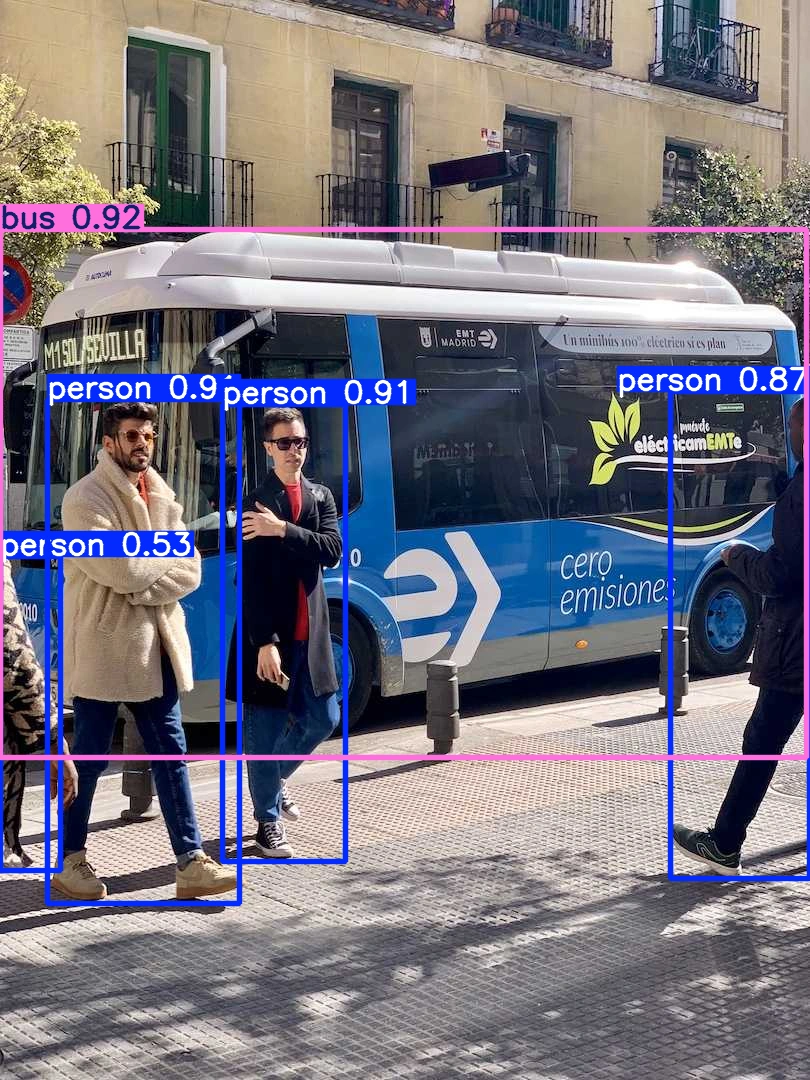
Hier hat das Modell die Segmentierung durchgeführt, es hat die erkannten Objekte maskiert. Auch die Kantenerkennung sieht intestine aus.
Posen-/Schlüsselpunktschätzung
pose_model = YOLO("yolo26n-pose.pt")
consequence = pose_model(IMAGE)(0)
present(consequence)
Das Modell hat die Schlüsselpunkte des menschlichen Körpers für die Posenerkennung erfolgreich vorhergesagt.
Orientierte Begrenzungsrahmen
obb_model = YOLO("yolo26n-obb.pt")
consequence = obb_model("https://ultralytics.com/photographs/boats.jpg")(0)
present(consequence)
Dieses Modell kann gezielt Objekte in Luft-, High-Down- oder Satellitenbildern erkennen. Wie Sie sehen können, wurden die Schiffe im Bild sehr intestine erkannt.
Bildklassifizierung
cls_model = YOLO("yolo26n-cls.pt")
consequence = cls_model(IMAGE)(0)
for i in consequence.probs.top5:
print(f"{consequence.names(i):<25} {consequence.probs.information(i):.2%}")Ausgabe:

Das Modell gibt die Wahrscheinlichkeiten von 1000 Klassen aus, hier hat der Klassifikator die Klasse als Kleinbus genau vorhergesagt.
Abschluss
Zusammenfassend haben Sie die Grundlagen von YOLO und YOLO26 kennengelernt, deren Architektur erkundet und in Google Colab Inferenzen zur Objekterkennung, Instanzsegmentierung, Posenschätzung, orientierten Begrenzungsrahmen und Bildklassifizierung durchgeführt. Mit seiner verbesserten Genauigkeit, Effizienz und Echtzeitleistung ist YOLO26 eine gute Wahl für eine Vielzahl von Laptop-Imaginative and prescient-Anwendungen.
Häufig gestellte Fragen
A. In Google Colab können Sie ein Bild mit der Funktion recordsdata.add() hochladen und den hochgeladenen Pfad zur Inferenz an das Modell übergeben.
A. Ja. Sie können das Video als Bilder (Frames) lesen, das Modell für jedes Body ausführen und dann die verarbeiteten Frames als Video kombinieren.
A. Nein. YOLO26-Modelle können auf einer CPU laufen, obwohl eine GPU für Inferenzen bei größeren Aufgaben viel schneller wäre.
Leidenschaftlich für Technologie und Innovation, Absolvent des Vellore Institute of Expertise. Derzeit arbeite ich als Knowledge Science Trainee mit Schwerpunkt auf Knowledge Science. Großes Interesse an Deep Studying und generativer KI, begierig darauf, modernste Techniken zu erforschen, um komplexe Probleme zu lösen und wirkungsvolle Lösungen zu schaffen.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.