

Hyperparameter bestimmen, wie intestine Ihr neuronales Netzwerk lernt und Informationen verarbeitet. Modellparameter werden während des Trainings gelernt. Im Gegensatz zu diesen Parametern müssen Hyperparameter vor Beginn des Trainings festgelegt werden. In diesem Artikel beschreiben wir die Techniken zur Optimierung der Hyperparameter in den Modellen.
Hyperparameter in neuronalen Netzwerken
Lernrate
Die Lernrate gibt dem Modell an, wie viel es aufgrund seiner Fehler ändern muss. Wenn die Lernrate hoch ist, lernt das Modell schnell, kann aber Fehler machen. Wenn die Lernrate niedrig ist, lernt das Modell langsam, aber sorgfältiger. Dies führt zu weniger Fehlern und höherer Genauigkeit.
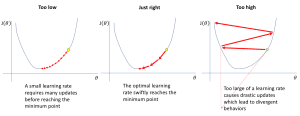 Quelle: https://www.jeremyjordan.me/nn-learning-rate/
Quelle: https://www.jeremyjordan.me/nn-learning-rate/Es gibt Möglichkeiten, die Lernrate anzupassen, um die bestmöglichen Ergebnisse zu erzielen. Dazu gehört, die Lernrate während des Trainings in vordefinierten Intervallen anzupassen. Darüber hinaus ermöglichen Optimierer wie Adam eine Selbstanpassung der Lernrate entsprechend der Durchführung des Trainings.
Batchgröße
Die Batchgröße ist die Anzahl der Trainingsbeispiele, die ein Modell zu einem bestimmten Zeitpunkt durchläuft. Eine große Batchgröße bedeutet im Grunde, dass das Modell mehr Beispiele durchläuft, bevor die Parameter aktualisiert werden. Dies kann zu einem stabileren Lernen führen, erfordert jedoch mehr Speicher. Eine kleinere Batchgröße hingegen aktualisiert das Modell häufiger. In diesem Fall kann das Lernen schneller erfolgen, es gibt jedoch mehr Variationen bei jeder Aktualisierung.
Der Wert der Batchgröße wirkt sich auf den Speicher und die Verarbeitungszeit für das Lernen aus.
Anzahl der Epochen
Epochen beziehen sich auf die Häufigkeit, mit der ein Modell während des Trainings den gesamten Datensatz durchläuft. Eine Epoche umfasst mehrere Zyklen, in denen dem Modell alle Datenstapel angezeigt werden, es daraus lernt und seine Parameter optimiert. Mehr Epochen sind besser für das Lernen des Modells, aber wenn sie nicht intestine beobachtet werden, können sie zu Überanpassung führen. Um eine gute Genauigkeit zu erreichen, ist es notwendig, die richtige Anzahl von Epochen festzulegen. Techniken wie das frühzeitige Stoppen werden häufig verwendet, um dieses Gleichgewicht zu finden.
Aktivierungsfunktion
Aktivierungsfunktionen entscheiden, ob ein Neuron aktiviert werden soll oder nicht. Dies führt zu Nichtlinearität im Modell. Diese Nichtlinearität ist insbesondere dann von Vorteil, wenn versucht wird, komplexe Interaktionen in den Daten zu modellieren.
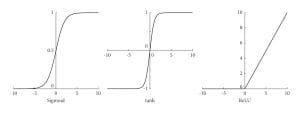 Quelle: https://www.researchgate.internet/publication/354971308/determine/fig1/AS:1080246367457377@1634562212739/Curves-of-the-Sigmoid-Tanh-and-ReLu-activation-functions.jpg
Quelle: https://www.researchgate.internet/publication/354971308/determine/fig1/AS:1080246367457377@1634562212739/Curves-of-the-Sigmoid-Tanh-and-ReLu-activation-functions.jpgZu den gängigen Aktivierungsfunktionen gehören ReLU, Sigmoid und Tanh. ReLU beschleunigt das Coaching neuronaler Netzwerke, da es nur constructive Aktivierungen in Neuronen zulässt. Sigmoid wird zum Zuweisen von Wahrscheinlichkeiten verwendet, da es einen Wert zwischen 0 und 1 ausgibt. Tanh ist insbesondere dann von Vorteil, wenn man nicht die gesamte Skala von 0 bis ± unendlich nutzen möchte. Die Auswahl der richtigen Aktivierungsfunktion muss sorgfältig überlegt werden, da sie bestimmt, ob das Netzwerk eine gute Vorhersage treffen kann oder nicht.
Ausfallen
Dropout ist eine Technik, die verwendet wird, um eine Überanpassung des Modells zu vermeiden. Dabei werden zufällig einige Neuronen deaktiviert oder „ausgeschlossen“, indem ihre Ausgaben während jeder Trainingsiteration auf Null gesetzt werden. Dieser Prozess verhindert, dass Neuronen sich zu stark auf bestimmte Eingaben, Merkmale oder andere Neuronen verlassen. Durch das Verwerfen der Ergebnisse bestimmter Neuronen hilft Dropout dem Netzwerk, sich im Trainingsprozess auf wesentliche Merkmale zu konzentrieren. Dropout wird meist während des Trainings implementiert, während es in der Inferenzphase deaktiviert wird.
Techniken zur Optimierung von Hyperparametern
Manuelle Suche
Bei dieser Methode werden Werte für Parameter ausprobiert, die bestimmen, wie der Lernprozess eines maschinellen Lernmodells abläuft. Diese Einstellungen werden einzeln angepasst, um zu beobachten, wie sie sich auf die Leistung des Modells auswirken. Versuchen wir, die Einstellungen manuell zu ändern, um eine höhere Genauigkeit zu erzielen.
learning_rate = 0.01
batch_size = 64
num_layers = 4
mannequin = Mannequin(learning_rate=learning_rate, batch_size=batch_size, num_layers=num_layers)
mannequin.match(X_train, y_train)
Die manuelle Suche ist einfach, da Sie keine komplizierten Algorithmen benötigen, um Parameter für Checks manuell festzulegen. Im Vergleich zu anderen Methoden hat sie jedoch mehrere Nachteile. Sie kann viel Zeit in Anspruch nehmen und findet möglicherweise nicht die besten Einstellungen effizienter als die automatisierten Methoden.
Rastersuche
Die Grid-Suche testet viele verschiedene Kombinationen von Hyperparametern, um die besten zu finden. Sie trainiert das Modell anhand eines Teils der Daten. Danach prüft sie, wie intestine sie mit einem anderen Teil funktioniert. Lassen Sie uns die Grid-Suche mit GridSearchCV implementieren, um das beste Modell zu finden.
from sklearn.model_selection import GridSearchCV
param_grid = {
'learning_rate': (0.001, 0.01, 0.1),
'batch_size': (32, 64, 128),
'num_layers': (2, 4, 8)
}
grid_search = GridSearchCV(mannequin, param_grid, cv=5)
grid_search.match(X_train, y_train)
Die Rastersuche ist viel schneller als die manuelle Suche. Allerdings ist sie rechenintensiv, da das Überprüfen aller möglichen Kombinationen Zeit in Anspruch nimmt.
Zufallssuche
Diese Technik wählt zufällig Kombinationen von Hyperparametern aus, um das effizienteste Modell zu finden. Für jede zufällige Kombination trainiert sie das Modell und prüft, wie intestine es funktioniert. Auf diese Weise können schnell gute Einstellungen erreicht werden, die zu einer besseren Leistung des Modells führen. Wir können eine zufällige Suche mit RandomizedSearchCV implementieren, um das beste Modell für die Trainingsdaten zu erhalten.
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform, randint
param_dist = {
'learning_rate': uniform(0.001, 0.1),
'batch_size': randint(32, 129),
'num_layers': randint(2, 9)
}
random_search = RandomizedSearchCV(mannequin, param_distributions=param_dist, n_iter=10, cv=5)
random_search.match(X_train, y_train)
Die Zufallssuche ist normalerweise besser als die Rastersuche, da nur wenige Hyperparameter überprüft werden, um geeignete Hyperparametereinstellungen zu erhalten. Dennoch wird möglicherweise nicht die richtige Kombination von Hyperparametern gesucht, insbesondere wenn der Arbeitsraum für Hyperparameter groß ist.
Einpacken
Wir haben einige der grundlegenden Techniken zur Hyperparameteroptimierung behandelt. Zu den fortgeschrittenen Techniken gehören Bayesianische Optimierung, genetische Algorithmen und Hyperband.
Jayita Gulati ist eine Enthusiastin für maschinelles Lernen und technische Autorin, die von ihrer Leidenschaft für die Erstellung von Modellen für maschinelles Lernen angetrieben wird. Sie hat einen Grasp-Abschluss in Informatik von der Universität Liverpool.