
Vor einigen Jahren, als ich als Berater arbeitete, leitete ich einen relativ komplexen ML -Algorithmus ab und stand vor der Herausforderung, das Innenleben dieses Algorithmus für meine Stakeholder clear zu machen. Dann kam ich zum ersten Mal parallele Koordinaten – weil die Visualisierung der Beziehungen zwischen zwei, drei, vielleicht vier oder fünf Variablen einfach ist. Sobald Sie jedoch mit Vektoren mit höherer Dimension arbeiten (z. B. dreizehn), ist der menschliche Geist oft nicht in der Lage, diese Komplexität zu erfassen. Geben Sie parallele Koordinaten ein: ein Instrument, das so einfach und doch so effektiv ist, dass ich mich oft frage, warum es in der alltäglichen EDA so wenig verwendet wird (meine Groups sind eine Ausnahme). Daher werde ich in diesem Artikel Ihnen die Vorteile paralleler Koordinaten mit dem Weindatensatz mitteilen und hervorheben, wie diese Technik dazu beitragen kann, Korrelationen, Muster oder Cluster in den Daten aufzudecken, ohne die Semantik von Funktionen (z. B. in PCA) zu verlieren.
Was sind parallele Koordinaten
Parallele Koordinaten sind Eine gemeinsame Methode zur Visualisierung hochdimensionaler Datensätze. Und ja, das ist technisch korrekt, obwohl diese Definition die Effizienz und Eleganz der Methode nicht vollständig erfasst. Anders als in einem Standarddiagramm, in dem Sie zwei orthogonale Achsen (und damit zwei Dimensionen, die Sie zeichnen können), in parallelen Koordinaten so viele vertikale Achsen wie Abmessungen in Ihrem Datensatz haben. Dies bedeutet, dass eine Beobachtung als eine Linie angezeigt werden kann, die alle Achsen bei ihrem entsprechenden Wert überschreitet. Möchten Sie ein schickes Wort lernen, um beim nächsten Hackathon zu beeindrucken? „Polyline“, das ist der richtige Begriff dafür. Und Muster erscheinen dann als Bündel von Polylines mit ähnlichem Verhalten. Oder genauer gesagt: Cluster erscheinen als Bündel, während Korrelationen als Trajektorien mit konsistenten Hängen über benachbarte Achsen erscheinen.
Wundern Sie sich, warum nicht einfach tun PCA (Hauptkomponentenanalyse)? Parallele Koordinaten behalten wir alle Originalmerkmale bei, dh wir kondensieren die Informationen nicht und projizieren sie in einen niedrigeren Raum. Das erleichtert die Interpretation sowohl für Sie als auch für Ihre Stakeholder sehr! Aber (ja, über die ganze Aufregung muss es immer noch ein aber … aber …) Sie sollten sich intestine darauf achten, nicht in die überpassende Falle zu fallen. Wenn Sie die Daten nicht sorgfältig vorbereiten, werden Ihre parallele Koordinaten leicht unlesbar. Ich werde Ihnen in der Vorgehensweise mit Auswahl, Skalierung und Transparenzanpassungen von großer Hilfe zeigen.
Übrigens. Ich sollte Prof. Alfred Inselberg hier erwähnen. Ich hatte die Ehre, 2018 in Berlin mit ihm zu speisen. Er ist derjenige, der mich an parallele Koordinaten begeistert hat. Und er ist auch der Pate paralleler Koordinaten und beweist ihren Wert in einer Vielzahl von Anwendungsfällen in den 1980er Jahren.
Beweisen meinen Standpunkt mit dem Weindatensatz
Für diese Demo habe ich das gewählt Weindatensatz. Warum? Erstens magazine ich Wein. Zweitens fragte ich Chatgpt Für einen öffentlichen Datensatz, der in einer der Datensätze meines Unternehmens ähnlich ist, an denen ich derzeit arbeite (und ich wollte nicht den ganzen Aufwand für die Veröffentlichung/Anonymisierung/… Unternehmensdaten übernehmen). Drittens ist dieser Datensatz in vielen intestine recherchiert Ml und Analytics -Anwendungen. Es enthält Daten aus der Analyse von 178 Weinen, die von drei Traubensorten in derselben Area Italiens gezüchtet wurden. Jede Beobachtung hat dreizehn kontinuierliche Eigenschaften (denken Sie an Alkohol, Flavonoidkonzentration, Prolingehalt, Farbintensität,…). Und die Zielvariable ist die Klasse der Traube.
Lassen Sie mich Ihnen zeigen, wie Sie den Datensatz in den Datensatz laden können Python.
import pandas as pd
# Load Wine dataset from UCI
uci_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.knowledge"
# Outline column names based mostly on the wine.names file
col_names = (
"Class", "Alcohol", "Malic_Acid", "Ash", "Alcalinity_of_Ash", "Magnesium",
"Total_Phenols", "Flavanoids", "Nonflavanoid_Phenols", "Proanthocyanins",
"Color_Intensity", "Hue", "OD280/OD315", "Proline"
)
# Load the dataset
df = pd.read_csv(uci_url, header=None, names=col_names)
df.head()
Intestine. Lassen Sie uns nun eine naive Handlung als Grundlinie ableiten.
Erster Schritt: eingebaute Pandas
Lassen Sie uns den Einbau verwenden pandas Auftriebsfunktion:
from pandas.plotting import parallel_coordinates
import matplotlib.pyplot as plt
plt.determine(figsize=(12,6))
parallel_coordinates(df, 'Class', colormap='viridis')
plt.title("Parallel Coordinates Plot of Wine Dataset (Unscaled)")
plt.xticks(rotation=45)
plt.present()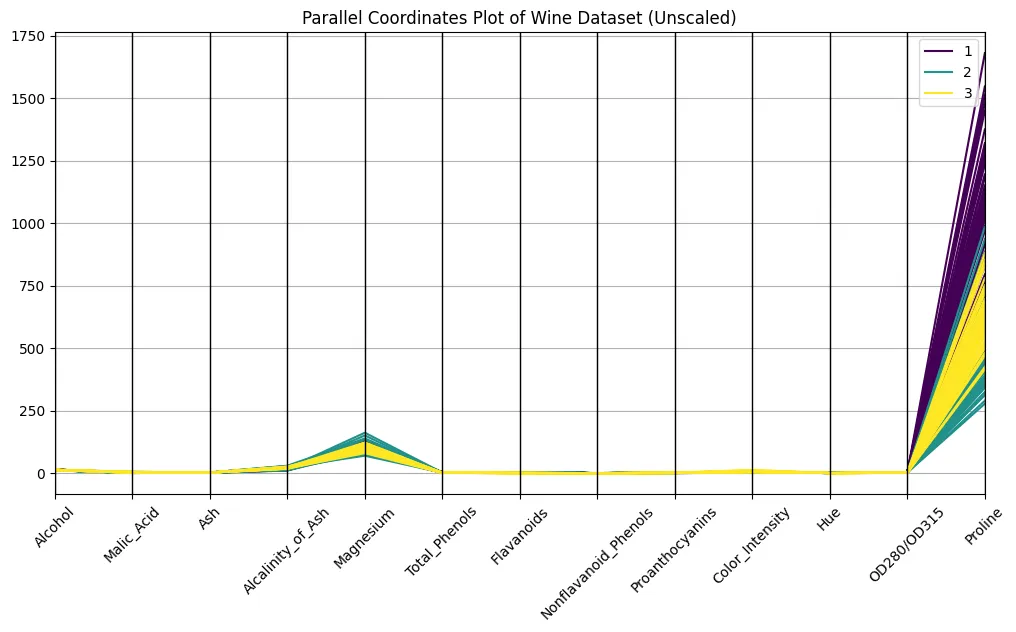
Sieht intestine aus, oder?
Nein, es tut es nicht. Sie können die Klassen auf der Handlung sicherlich erkennen, aber die Unterschiede in der Skalierung machen es schwierig, über Achsen hinweg zu vergleichen. Vergleichen Sie zum Beispiel die Größenordnungen von Prolin und Farbton: Prolin hat eine starke optische Dominanz, nur wegen der Skalierung. Eine unbekannte Handlung sieht quick bedeutungslos oder zumindest sehr schwer zu interpretieren. Trotzdem scheinen schwache Bündel über den Unterricht zu erscheinen.
Es geht nur um Skala
Viele von Ihnen (alle?) Kennt man mit der min-max-Skalierung von ML-Vorverarbeitungspipelines. Lassen Sie uns das nicht verwenden. Ich werde eine Standardisierung der Daten durchführen, dh hier machen wir Z-Scaling (jede Funktion hat einen Mittelwert von Null- und Einheitsvarianz), um allen Achsen das gleiche Gewicht zu geben.
from sklearn.preprocessing import StandardScaler
# Separate options and goal
options = df.drop("Class", axis=1)
scaler = StandardScaler()
scaled = scaler.fit_transform(options)
# Reconstruct a DataFrame with scaled options
scaled_df = pd.DataFrame(scaled, columns=options.columns)
scaled_df("Class") = df("Class")
plt.determine(figsize=(12,6))
parallel_coordinates(scaled_df, 'Class', colormap='plasma', alpha=0.5)
plt.title("Parallel Coordinates Plot of Wine Dataset (Scaled)")
plt.xticks(rotation=45)
plt.present()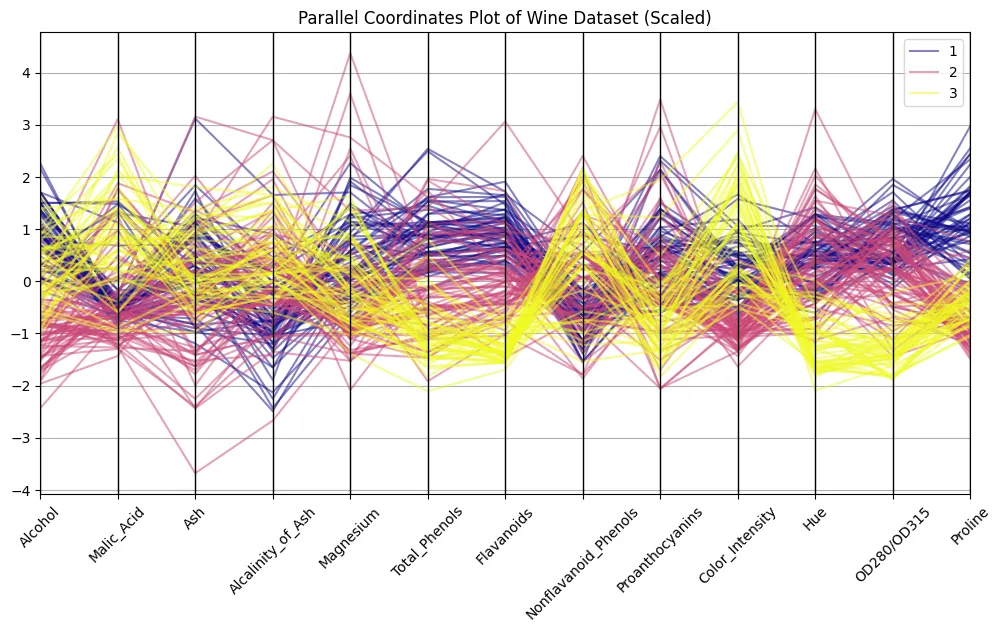
Erinnerst du dich an das Bild von oben? Der Unterschied ist auffällig, was? Jetzt können wir Muster erkennen. Versuchen Sie, Cluster von Linien zu unterscheiden, die mit jeder Weinklasse verbunden sind, um herauszufinden, welche Funktionen am unterschiedlichsten sind.
Characteristic -Auswahl
Hast du etwas entdeckt? Richtig! Ich hatte den Eindruck, dass Alkohol, Flavonoide, Farbintensität und Prolin quick ein Lehrbuchmustern zeigen. Lassen Sie uns diese filtern und versuchen zu sehen, ob eine Kuration von Merkmalen dazu beiträgt, dass unsere Beobachtungen noch auffälliger werden.
chosen = ("Alcohol", "Flavanoids", "Color_Intensity", "Proline", "Class")
plt.determine(figsize=(10,6))
parallel_coordinates(scaled_df(chosen), 'Class', colormap='coolwarm', alpha=0.6)
plt.title("Parallel Coordinates Plot of Chosen Options")
plt.xticks(rotation=45)
plt.present()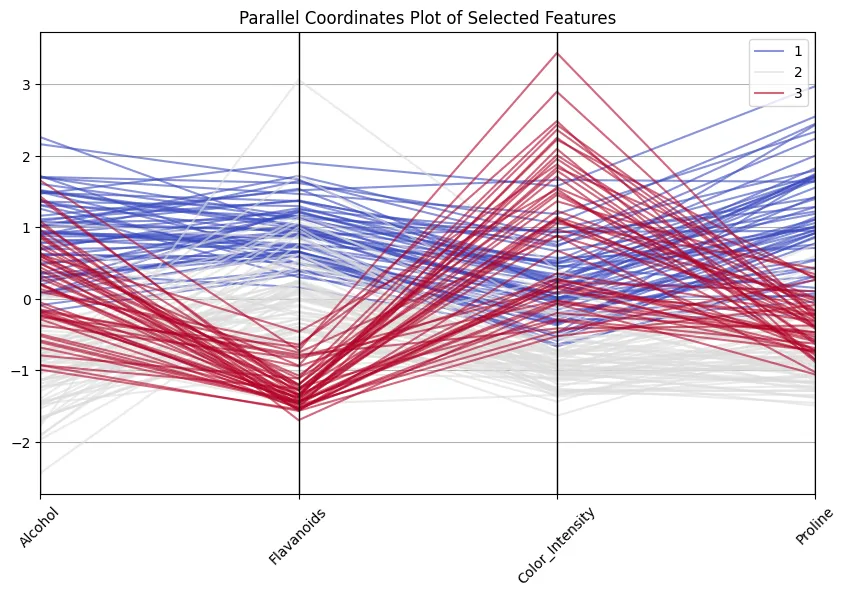
Schön zu sehen, wie Weine der Klasse 1 bei Flavonoiden und Prolin immer hoch punkten, während die Weine der Klasse 3 bei diesen, aber eine hohe Farbintensität niedriger sind! Und denken Sie nicht, dass dies eine vergebliche Übung ist … 13 Dimensionen sind immer noch in Ordnung, um zu handhaben und zu inspizieren, aber ich habe Fälle mit mehr als 100 Dimensionen begegnet, was die Reduzierung von Dimensionen imperativ macht.
Hinzufügen von Interaktion
Ich gebe zu: Die obigen Beispiele sind ziemlich mechanistisch. Beim Schreiben des Artikels platzierte ich auch Farbton neben Alkohol, wodurch meine intestine gezeigten Klassen zusammengebrochen waren. Additionally bewegte ich die Farbintensität neben Flavonoiden, und das half. Aber mein Ziel hier conflict es nicht, Ihnen das perfekte Codekopie zu geben. Es ging eher um die Verwendung paralleler Koordinaten auf der Grundlage einiger einfacher Beispiele. Im wirklichen Leben würde ich ein explorativeres Frontend einrichten. Parallele Koordinaten plotte zum Beispiel mit einer „Bürsten“ -Funktion: Dort können Sie einen Unterabschnitt einer Achse auswählen und alle Polylines, die in diese Teilmenge fallen, werden hervorgehoben.
Sie können Achsen auch durch einfache Luftwiderstandsanschluss neu ordnen, was häufig dazu beiträgt, Korrelationen zu enthüllen, die in der Standardreihenfolge versteckt waren. Hinweis: Versuchen Sie benachbarte Achsen, die Sie vermuten, die Co-Varia zu machen.
Und noch besser: Skalierung ist für die Prüfung der Daten mit Plotly nicht erforderlich: Die Achsen werden automatisch auf die Min- und Max-Werte jeder Dimension skaliert.
Hier ist ein Code, den Sie in Ihrem Colab reproduzieren können:
import plotly.specific as px
# Preserve class as a separate column; Plotly's parcoords expects numeric color for 'shade'
df("Class") = df("Class").astype(int)
fig_all = px.parallel_coordinates(
df,
shade="Class", # numeric color mapping (1..3)
dimensions=options.columns,
labels={c: c.substitute("_", " ") for c in scaled_df.columns},
)
fig_all.update_layout(
title="Interactive Parallel Coordinates — All 13 Options"
)
# The file under may be opened in any browser or embedded through <iframe>.
fig_all.write_html("parallel_coordinates_all_features.html",
include_plotlyjs="cdn", full_html=True)
print("Saved:")
print(" - parallel_coordinates_all_features.html")
# present figures inline
fig_all.present()
Welche Schlussfolgerungen ziehen wir mit diesem endgültigen Component?
Abschluss
Parallele Koordinaten beziehen sich nicht so sehr um die harten Zahlen, sondern vielmehr um die Muster, die aus diesen Zahlen hervorgehen. Im Weindatensatz können Sie mehrere solche Muster beobachten – ohne Korrelationen auszuführen, PCA oder Streumatrizen auszuführen. Flavonoide helfen stark, die Klasse 1 von den anderen zu unterscheiden. Farbintensität und Farbton getrennt die Klassen 2 und 3. Prolin verstärken dies weiter. Was aus dort folgt, ist nicht nur, dass Sie diese Klassen visuell trennen können, sondern auch ein intuitives Verständnis dafür, was Sorten in der Praxis trennt.
Und dies ist genau die Stärke über T-SNE, PCA usw., diese Techniken projizieren Daten in Komponenten, die hervorragend bei der Unterscheidung der Klassen sind… aber viel Glück mit dem Versuch, einem Chemiker zu erklären, was „Komponenten eins“ ihm bedeutet.
Versteh mich nicht falsch: Parallele Koordinaten sind nicht das Schweizer Armeemesser von Eda. Sie benötigen Stakeholder mit einem sehr guten Verständnis für Daten, um parallele Koordinaten zu verwenden, um mit ihnen zu kommunizieren (sonst verwenden Sie weiterhin Boxplots und Balkendiagramme!). Aber für Sie (und mich) als Datenwissenschaftler sind parallele Koordinaten das Mikroskop, nach dem Sie sich schon immer gesehnt haben.
Häufig gestellte Fragen
A. Parallele Koordinaten werden hauptsächlich für die explorative Analyse hochdimensionaler Datensätze verwendet. Sie ermöglichen es Ihnen, Cluster, Korrelationen und Ausreißer zu erkennen und gleichzeitig die ursprünglichen Variablen interpretierbar zu halten.
A. Ohne Skalierung dominieren Merkmale mit großen numerischen Bereichen das Diagramm. Die Standardisierung jeder Merkmal auf Null- und Einheitsvarianz stellt sicher, dass jede Achse gleichermaßen zum visuellen Muster beiträgt.
A. PCA und T-SNE reduzieren die Dimensionalität, aber die Achsen verlieren ihre ursprüngliche Bedeutung. Parallele Koordinaten halten die semantische Verbindung zu den Variablen auf Kosten einer gewissen Unordnung und potenziellen Überlagern.
Als CDAO bei Fischer bin ich ein erfahrener Fachmann mit über 15 Jahren Erfahrung im Bereich Information Science. Mit einem Ph.D. In Wirtschaft und fünf Jahren Erfahrung als Assistenzprofessor für Wirtschaftstheorie habe ich ein tiefes Verständnis der Einhaltung sozialer Norm und deren Auswirkungen auf die Entscheidungsfindung entwickelt.
Ich bin auch ein renommierter Konferenzredner und Podcast -Teilnehmer, der mein Fachwissen über eine breite Palette von Themen im Zusammenhang mit Datenwissenschaft und Geschäftsstrategie teilt. Mein Hintergrund beinhaltet die Arbeit als AI-Evangelist für die Zusammenarbeit mit der Sternenzusammenarbeit sowie in der Strategie- und Managementberatung mit Schwerpunkt auf der Preisgestaltung nach dem Verkauf. Diese Erfahrung hat es mir ermöglicht, ein breites Qualifikationssatz zu entwickeln, das Datenwissenschaft, Produktmanagement und Strategieentwicklung umfasst.
Vor meiner aktuellen Aufgabe conflict ich für die Verwaltung eines großen Information Science Heart of Excellence bei E. Breuninger verantwortlich, wo ich ein Workforce von Datenwissenschaftlern und Produktmanagern leitete. Ich bin begeistert davon, Daten zu nutzen, um geschäftliche Entscheidungen voranzutreiben und greifbare Ergebnisse zu erzielen, und habe eine nachgewiesene Erfolgsbilanz des Erfolgs in diesem Bereich.
Mit einem tiefen Wissen über Wirtschaft, Psychologie und Datenwissenschaft freue ich mich auf einen professionellen Austausch mit jeder Organisation, die das Wachstum und die Innovation durch datengesteuerte Erkenntnisse vorantreiben möchte.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.