
Der Agent SDK von OpenAI hat mit der Veröffentlichung seiner Sprachagent-Funktion eine Stufe aufgenommen, mit der Sie intelligente, in Echtzeit-sprachgetriebene Anwendungen erstellen können. Egal, ob Sie einen Sprachlehrer, einen virtuellen Assistenten oder einen Assist-Bot erstellen, diese neue Fähigkeit bringt eine ganz neue Interaktionsebene mit sich-natürlich, dynamisch und menschlich. Lassen Sie es uns aufschlüsseln und durchgehen, was es ist, wie es funktioniert und wie Sie selbst einen mehrsprachigen Sprachagenten aufbauen können.
Was ist ein Sprachagent?
Ein Sprachagent ist ein System, das Ihre Stimme hört, versteht, was Sie sagen, denkt über eine Antwort und antwortet dann laut. Die Magie wird durch eine Kombination aus Sprach-Textual content, Sprachmodellen und Textual content-zu-Sprache-Technologien angetrieben.
Der Openai Agent SDK macht dies unglaublich zugänglich über etwas, das als Voicepipeline bezeichnet wird-ein strukturierter 3-Stufen-Prozess:
- Sprache zu Textual content (STT): Erfasst und konvertiert Ihre gesprochenen Wörter in Textual content.
- Agentenlogik: Dies ist Ihr Code (oder Ihr Agent), der die entsprechende Antwort ermittelt.
- Textual content-to-Speech (TTS): Umwandelt die Textantwort des Agenten in Audio zurück, das laut gesprochen wird.
Auswahl der richtigen Architektur
Abhängig von Ihrem Anwendungsfall möchten Sie eines von zwei von OpenAI unterstützten Kernarchitekturen auswählen:
1. Sprach-zu-Sprach (multimodal) Architektur
Dies ist der Echtzeit-All-Audio-Ansatz mit Modellen wie GPT-4O-RealTime-Präview. Anstatt in Textual content hinter den Kulissen zu übersetzen, verarbeitet und generiert das Modell direkt.
Warum das nutzen?
- Niedrige Latenz, Echtzeit-Interaktion
- Emotion und Vokal -Tonverständnis
- Glatter, natürlicher Gesprächsfluss
Perfekt für:
- Sprachunterricht
- Stay -Konversationsmittel
- Interaktive Storytelling- oder Lern -Apps
| Stärken | Am besten für |
|---|---|
| Geringe Latenz | Interaktiver, unstrukturierter Dialog |
| Multimodales Verständnis (Stimme, Ton, Pausen) | Echtzeit Engagement |
| Emotionsbewusste Antworten | Kundenbetreuung, virtuelle Begleiter |
Dieser Ansatz lässt Gespräche flüssig und menschlich anfühlen, benötigen jedoch möglicherweise mehr Aufmerksamkeit in Randfällen wie Protokollierung oder exakte Transkripte.
2. Kettenarchitektur
Die verkettete Methode ist traditioneller: Sprache wird in Textual content verwandelt, die LLM -Prozesse, die diesen Textual content verarbeitet, und dann wird die Antwort wieder in Sprache umgewandelt. Die empfohlenen Modelle hier sind:
- GPT-4O-Transcribe (für STT)
- GPT-4O (für Logik)
- GPT-4-MINI-TTS (für TTs)
Warum das nutzen?
- Benötigen Sie Transkripte für Audit/Protokollierung
- Haben strukturierte Workflows wie Kundendienst oder Leitqualifikation
- Wollen vorhersehbares, kontrollierbares Verhalten
Perfekt für:
- Bots unterstützen
- Vertriebsmitarbeiter
- Aufgabenspezifische Assistenten
| Stärken | Am besten für |
|---|---|
| Hohe Kontrolle und Transparenz | Strukturierte Workflows |
| Zuverlässige textbasierte Verarbeitung | Apps, die Transkripte benötigen |
| Vorhersehbare Ausgänge | Kundendebauende Skriptströme |
Dies ist einfacher zu debuggen und ein großartiger Ausgangspunkt, wenn Sie neu für Sprachagenten sind.
Wie funktioniert Sprachagent?
Wir richten a ein VoicePipeline mit einem benutzerdefinierten Workflow. Dieser Workflow führt einen Agenten aus, kann aber auch spezielle Antworten auslösen, wenn Sie ein geheimes Wort sagen.
Hier ist, was passiert, wenn Sie sprechen:
- Audio geht zur VoicePipeline, während Sie sprechen.
- Wenn Sie aufhören zu sprechen, beginnt die Pipeline.
- Die Pipeline dann:
- Transkribiert Ihre Rede in Textual content.
- Sendet die Transkription an den Workflow, der die Agentenlogik ausführt.
- Streams die Antwort des Agenten auf ein TTS-Modell (Textual content-to-Speech).
- Spielt das generierte Audio zurück an Sie.
Es ist Echtzeit, interaktiv und klug genug, um anders zu reagieren, wenn Sie in einer versteckten Phrase ausrutschen.
Konfigurieren einer Pipeline
Beim Einrichten einer Sprachpipeline können Sie einige Schlüsselkomponenten anpassen:
- Workflow: Dies ist die Logik, die jedes Mal ausgeführt wird, wenn ein neues Audio transkribiert wird. Es definiert, wie der Agent verarbeitet und reagiert.
- STT- und TTS -Modelle: Wählen Sie aus, welche Sprach- und Textual content-zu-Sprach-Modelle Ihre Pipeline verwenden wird.
- Konfigurationseinstellungen: Hier verhalten Sie sich intestine, wie sich Ihre Pipeline verhält:
- Modellanbieter: Ein Zuordnungssystem, das Modellnamen mit tatsächlichen Modellinstanzen verknüpft.
- Tracing -Optionen: Steuern Sie, ob die Verfolgung aktiviert ist, ob Audiodateien hochladen, Workflow -Namen, Hint -IDs und mehr zuweisen.
- Modellspezifische Einstellungen: Passen Sie Eingabeaufforderungen, Sprachpräferenzen und unterstützte Datentypen für TTS- und STT -Modelle an.
Ausführen einer Sprachpipeline
Um eine Sprachpipeline zu starten, verwenden Sie die run() Verfahren. Es akzeptiert Audioeingaben in einer von zwei Formularen, je nachdem, wie Sie mit Sprache umgehen:
- Audioinput ist superb, wenn Sie bereits einen vollständigen Audioclip oder Transkript haben. Es ist perfekt für Fälle, in denen Sie wissen, wann der Lautsprecher fertig ist, wie bei vorgezeichneten Audio- oder Push-to-Speak-Setups. Keine Notwendigkeit für Stay -Aktivitätserkennung hier.
- Streamedaudioinput ist für Echtzeit, dynamische Eingabe. Sie füttern Audio -Stücke, sobald sie erfasst werden, und die Sprachpipeline ermittelt automatisch, wann die Agentenlogik mithilfe einer sogenannten Aktivitätserkennung ausgelöst werden soll. Dies ist tremendous praktisch, wenn Sie sich mit offenen Mikrofonen oder Freisprechinteraktion befassen, bei denen es nicht offensichtlich ist, wenn der Sprecher fertig ist.
Die Ergebnisse verstehen
Sobald Ihre Pipeline ausgeführt wird, gibt sie eine Streamedaudioresult zurück, mit der Sie Ereignisse in Echtzeit streamen können, wenn sich die Interaktion entfaltet. Diese Ereignisse kommen in einigen Geschmacksrichtungen:
- Voicestreameventaudio – Enthält Teile der Audioausgabe (dh, was der Agent sagt).
- VoicestreamEventlifecycle – Markiert wichtige Lebenszyklusereignisse wie der Beginn oder das Ende einer Gesprächswende.
- VoicestreameVentError – signalisiert, dass etwas schief gelaufen ist.
Praktischer Sprachagent mit OpenAI-Agent SDK
Hier ist eine sauberere, intestine strukturierte Model Ihres Leitfadens zum Einrichten eines praktischen Sprachagents mit OpenAI-Agent SDK mit detaillierten Schritten, Gruppierung und Klarheitsverbesserungen. Es ist alles immer noch lässig und praktisch, aber lesbarer und umsetzbarer:
1. Richten Sie Ihr Projektverzeichnis ein
mkdir my_project
cd my_project
2. Erstellen und aktivieren Sie eine virtuelle Umgebung
Erstellen Sie die Umgebung:
python -m venv .venvAktivieren Sie es:
supply .venv/bin/activate3. Installieren Sie OpenAI Agent SDK
pip set up openai-agent4. Stellen Sie eine OpenAI -API -Schlüssel ein
export OPENAI_API_KEY=sk-...5. Klonen Sie das Beispiel -Repository klonen
git clone https://github.com/openai/openai-agents-python.git6. Ändern Sie den Beispielcode für Hindi Agent und Audio -Speichern
Navigieren Sie zur Beispieldatei:
cd openai-agents-python/examples/voice/staticJetzt bearbeiten Sie Foremost.py:
Sie werden zwei wichtige Dinge tun:
- Fügen Sie einen Hindi -Agenten hinzu
- Aktivieren Sie Audiosparen nach der Wiedergabe
Ersetzen Sie den gesamten Inhalt in important.py. Dies ist der endgültige Code hier:
import asyncio
import random
from brokers import Agent, function_tool
from brokers.extensions.handoff_prompt import prompt_with_handoff_instructions
from brokers.voice import (
AudioInput,
SingleAgentVoiceWorkflow,
SingleAgentWorkflowCallbacks,
VoicePipeline,
)
from .util import AudioPlayer, record_audio
@function_tool
def get_weather(metropolis: str) -> str:
print(f"(debug) get_weather referred to as with metropolis: {metropolis}")
selections = ("sunny", "cloudy", "wet", "snowy")
return f"The climate in {metropolis} is {random.selection(selections)}."
spanish_agent = Agent(
identify="Spanish",
handoff_description="A spanish talking agent.",
directions=prompt_with_handoff_instructions(
"You are chatting with a human, so be well mannered and concise. Communicate in Spanish.",
),
mannequin="gpt-4o-mini",
)
hindi_agent = Agent(
identify="Hindi",
handoff_description="A hindi talking agent.",
directions=prompt_with_handoff_instructions(
"You are chatting with a human, so be well mannered and concise. Communicate in Hindi.",
),
mannequin="gpt-4o-mini",
)
agent = Agent(
identify="Assistant",
directions=prompt_with_handoff_instructions(
"You are chatting with a human, so be well mannered and concise. If the consumer speaks in Spanish, handoff to the spanish agent. If the consumer speaks in Hindi, handoff to the hindi agent.",
),
mannequin="gpt-4o-mini",
handoffs=(spanish_agent, hindi_agent),
instruments=(get_weather),
)
class WorkflowCallbacks(SingleAgentWorkflowCallbacks):
def on_run(self, workflow: SingleAgentVoiceWorkflow, transcription: str) -> None:
print(f"(debug) on_run referred to as with transcription: {transcription}")
async def important():
pipeline = VoicePipeline(
workflow=SingleAgentVoiceWorkflow(agent, callbacks=WorkflowCallbacks())
)
audio_input = AudioInput(buffer=record_audio())
outcome = await pipeline.run(audio_input)
# Create an inventory to retailer all audio chunks
all_audio_chunks = ()
with AudioPlayer() as participant:
async for occasion in outcome.stream():
if occasion.sort == "voice_stream_event_audio":
audio_data = occasion.information
participant.add_audio(audio_data)
all_audio_chunks.append(audio_data)
print("Acquired audio")
elif occasion.sort == "voice_stream_event_lifecycle":
print(f"Acquired lifecycle occasion: {occasion.occasion}")
# Save the mixed audio to a file
if all_audio_chunks:
import wave
import os
import time
os.makedirs("output", exist_ok=True)
filename = f"output/response_{int(time.time())}.wav"
with wave.open(filename, "wb") as wf:
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(16000)
wf.writeframes(b''.be part of(all_audio_chunks))
print(f"Audio saved to {filename}")
if __name__ == "__main__":
asyncio.run(important())
6. Führen Sie den Sprachagenten aus
Stellen Sie sicher, dass Sie im richtigen Verzeichnis sind:
cd openai-agents-pythonStarten Sie es dann:
python -m examples.voice.static.importantIch fragte den Agenten zwei Dinge, einen auf Englisch und einen in Hindi:
- Voice -Eingabeaufforderung: Hey, Voice Agent, was ist ein großes Sprachmodell?
- Stimme Eingabeaufforderung: „मुझे दिल्ली के बाे में बताओ
Hier ist das Terminal:
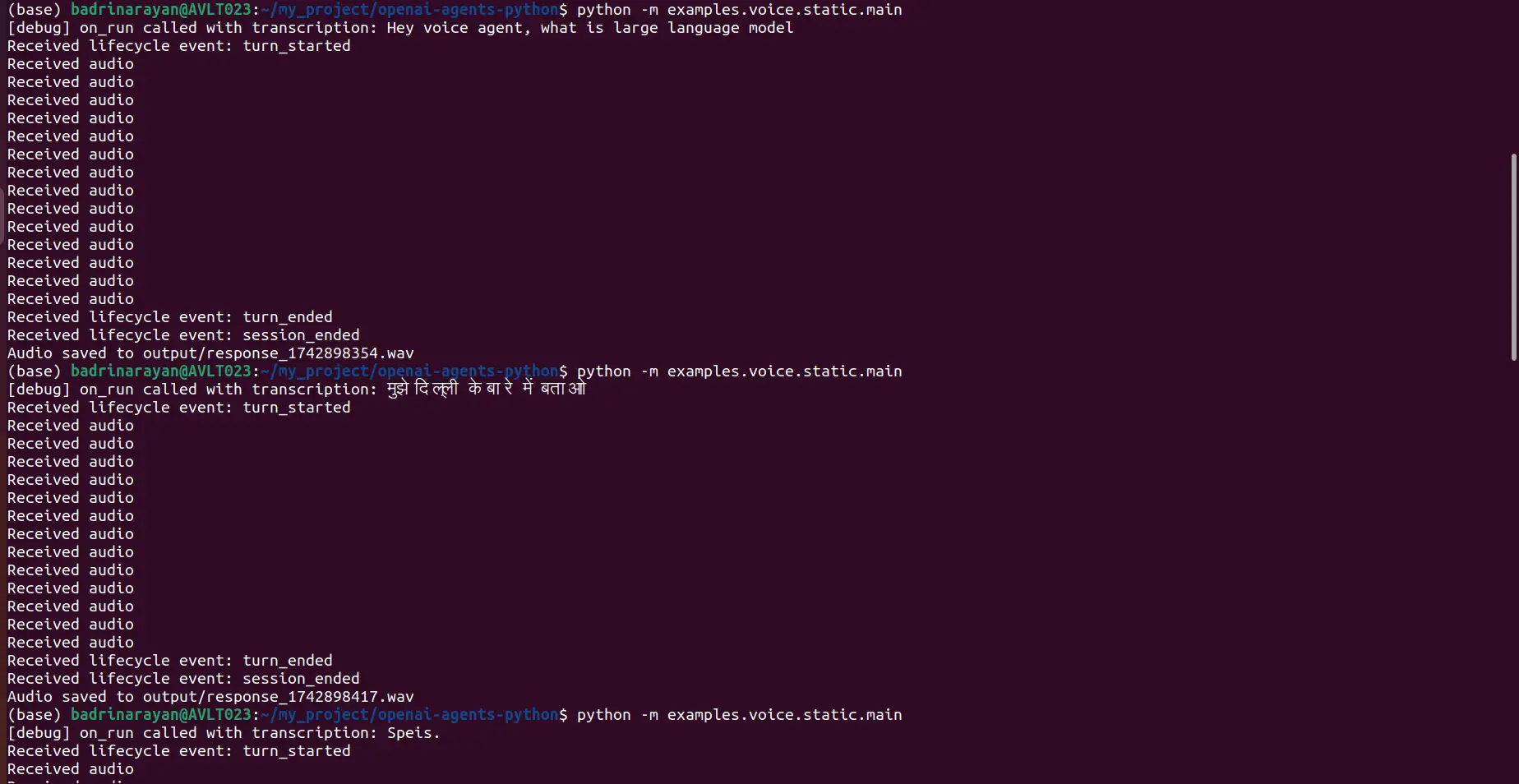
Ausgabe
Englische Antwort:
Hindi -Antwort:
Zusätzliche Ressourcen
Willst du tiefer graben? Überprüfen Sie diese:
Lesen Sie auch: Die Audiomodelle von OpenAI: Zugriff, Funktionen, Anwendungen und mehr
Abschluss
Der Aufbau eines Sprachagents mit dem OpenAI -Agenten SDK ist jetzt viel zugänglicher – Sie müssen nicht mehr eine Menge Werkzeuge zusammenfügen. Wählen Sie einfach die richtige Architektur aus, richten Sie Ihre VoicePipeline ein und lassen Sie den SDK das schwere Heben durchführen.
Wenn Sie einen qualitativ hochwertigen Konversationsfluss haben, gehen Sie multimodal. Wenn Sie Struktur und Kontrolle wünschen, gehen Sie gekettet. In jedem Fall ist diese Technologie mächtig und es wird nur besser. Wenn Sie einen erstellen, teilen Sie mir im Kommentarbereich unten wissen.
Hallo, ich bin Pankaj Singh Negi – Senior Content material Editor | Leidenschaftlich über das Geschichtenerzählen und das Erstellen überzeugender Erzählungen, die Ideen in einen wirkungsvollen Inhalt verwandeln. Ich liebe es, über die Technologie zu lesen, die unseren Lebensstil revolutioniert.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.