
Datenvorverarbeitung bleibt für den Erfolg des maschinellen Lernens von entscheidender Bedeutung, aber reale Datensätze enthalten häufig Fehler. Die Datenvorverarbeitung mit CleanLab bietet eine effiziente Lösung und nutzt sein Python -Paket, um selbstbewusste Lernalgorithmen zu implementieren. Durch die Automatisierung der Erkennung und Korrektur von Etikettenfehlern vereinfacht CleanLab den Prozess der Datenvorverarbeitung im maschinellen Lernen. Durch die Verwendung statistischer Methoden zur Identifizierung problematischer Datenpunkte ermöglicht CleanLab die Vorbereitung mit CleanLab Python zur Verbesserung der Modellzuverlässigkeit. CleanLab optimiert beispielsweise Workflows und verbessert die Ergebnisse des maschinellen Lernens mit minimalem Aufwand.
Warum ist eine Datenvorverarbeitung wichtig?
Datenvorverarbeitung Wirkt sich direkt auf die Modellleistung aus. Schmutzige Daten mit falschen Beschriftungen, Ausreißern und Inkonsistenzen führen zu schlechten Vorhersagen und unzuverlässigen Erkenntnissen. Modelle, die auf fehlerhaften Daten ausgebildet sind, verewigen diese Fehler und erzeugen einen Kaskadeneffekt von Ungenauigkeiten in Ihrem System. Qualitätsvorverarbeitung beseitigt diese Probleme, bevor die Modellierung beginnt.
Eine effektive Vorverarbeitung spart auch Zeit und Ressourcen. Reinigere Daten bedeuten weniger Modell -Iterationen, schnelleres Coaching und reduzierte Rechenkosten. Es verhindert die Frustration, komplexe Modelle zu debuggen, wenn das eigentliche Downside in den Daten selbst liegt. Die Vorverarbeitung verwandelt Rohdaten in wertvolle Informationen, aus denen Algorithmen effektiv lernen können.
Wie kann ich Daten mit CleanLab vorbereiten?
CleanLab Hilft vor dem Coaching zu reinigen und zu validieren. Es findet schlechte Beschriftungen, Duplikate und minderwertige Stichproben verwendet ML -Modelle. Es eignet sich am besten für Etiketten- und Datenqualitätsprüfungen, nicht für die grundlegende Textreinigung.
Schlüsselmerkmale von CleanLab:
- Erkennt fehlgeschlagene Daten (laute Beschriftungen)
- Fahnen Duplikationen und Ausreißer
- Überprüfungen auf minderwertige oder inkonsistente Proben
- Bietet Etikettenverteilungserkenntnisse
- Arbeitet mit einem ML -Klassifikator zusammen, um die Datenqualität zu verbessern
Gehen wir nun durch, wie Sie CleanLab Schritt für Schritt verwenden können.
Schritt 1: Set up der Bibliotheken
Vor dem Begin müssen wir einige wesentliche Bibliotheken installieren. Diese helfen uns, die Daten zu laden und saubere Instruments reibungslos auszuführen.
!pip set up cleanlab
!pip set up pandas
!pip set up numpy- CleanLab: Zum Erkennen von Beschriftungs- und Datenqualitätsproblemen.
- Pandas: Lesen und Umgang mit den CSV -Daten.
- numpy: Unterstützt schnelle numerische Berechnungen von CleanLab.
Schritt 2: Laden des Datensatzes
Jetzt laden wir den Datensatz mithilfe Pandas mit der Vorverarbeitung beginnen.
import pandas as pd
# Load dataset
df = pd.read_csv("/content material/Tweets.csv")
df.head(5)- pd.read_csv ():
- df.head (5):

Jetzt, sobald wir die Daten geladen haben. Wir werden uns nur auf die Spalten konzentrieren, die wir benötigen, und nach fehlenden Werten prüfen.
# Concentrate on related columns
df_clean = df.drop(columns=('selected_text'), axis=1, errors="ignore")
df_clean.head(5)Entfernt die Spalte aus selected_text, wenn sie existiert; Vermeidet Fehler, wenn dies nicht der Fall ist. Hilft nur die erforderlichen Spalten für die Analyse.
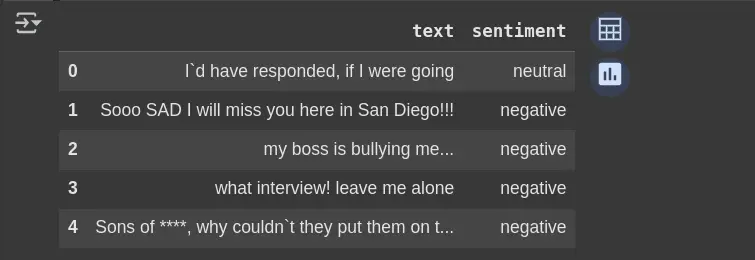
Schritt 3: Überprüfen Sie die Beschriftungsprobleme
from cleanlab.dataset import health_summary
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.textual content import TfidfVectorizer
from sklearn.model_selection import cross_val_predict
from sklearn.preprocessing import LabelEncoder
# Put together knowledge
df_clean = df.dropna()
y_clean = df_clean('sentiment') # Authentic string labels
# Convert string labels to integers
le = LabelEncoder()
y_encoded = le.fit_transform(y_clean)
# Create mannequin pipeline
mannequin = make_pipeline(
TfidfVectorizer(max_features=1000),
LogisticRegression(max_iter=1000)
)
# Get cross-validated predicted chances
pred_probs = cross_val_predict(
mannequin,
df_clean('textual content'),
y_encoded, # Use encoded labels
cv=3,
technique="predict_proba"
)
# Generate well being abstract
report = health_summary(
labels=y_encoded, # Use encoded labels
pred_probs=pred_probs,
verbose=True
)
print("Dataset Abstract:n", report)- df.dropna (): Entfernt Zeilen mit fehlenden Werten und stellt saubere Daten für das Coaching sicher.
- LabelCoder (): Konvertiert String -Etiketten (z. B. „positiv“, „negativ“) in Ganzzahl -Etiketten für die Modellkompatibilität.
- make_pipeline (): Erstellt eine Pipeline mit einem TF-IDF-Vectorizer (konvertiert Textual content in numerische Merkmale) und ein logistisches Regressionsmodell.
- cross_val_predict (): Führt eine 3-fache Kreuzvalidierung durch und rendite vorhergesagte Wahrscheinlichkeiten anstelle von Etiketten.
- Health_Summary (): Verwendet CleanLab, um die vorhergesagten Wahrscheinlichkeiten und Beschriftungen zu analysieren und potenzielle Label -Probleme wie Misklabel zu identifizieren.
- Druck (Bericht): Zeigt den Gesundheitsübersichtsbericht an, wodurch alle Label -Inkonsistenzen oder Fehler im Datensatz hervorgehoben werden.
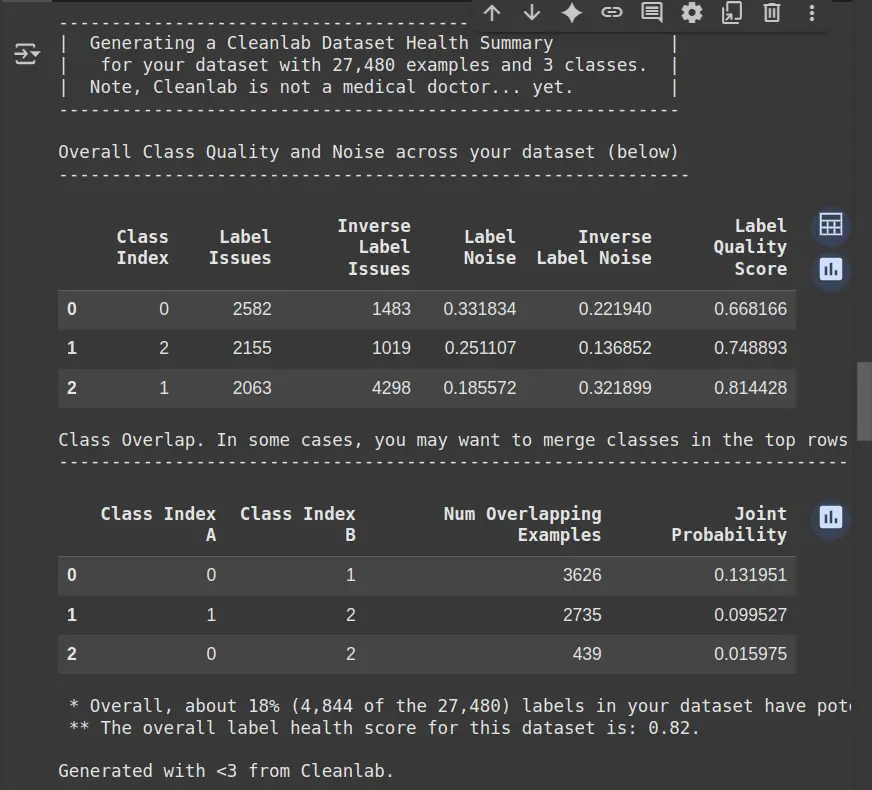
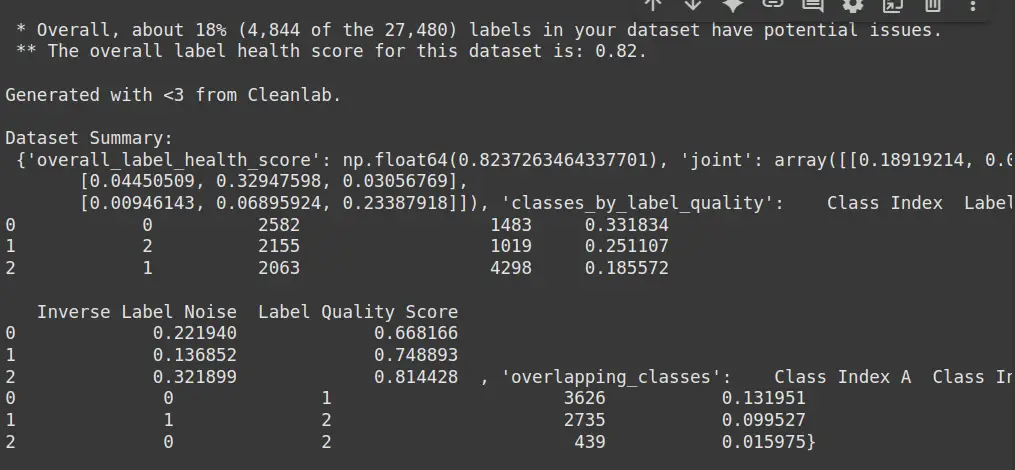
- Kennzeichnungsprobleme: Gibt an, wie viele Proben in einer Klasse potenziell falsche oder mehrdeutige Etiketten haben.
- Umgekehrte Etikettenprobleme: Zeigt die Anzahl der Fälle an, in denen die vorhergesagten Etiketten falsch sind (gegenüber echten Beschriftungen).
- Etikettenrauschen: Misst das Ausmaß des Rauschens (falsche Unsicherheit oder Unsicherheit) innerhalb jeder Klasse.
- Etikettenqualitätsbewertung: reflektiert die Gesamtqualität von Etiketten in einer Klasse (höhere Punktzahl bedeutet eine bessere Qualität).
- Klassenüberlappung: Identifiziert, wie viele Beispiele sich zwischen verschiedenen Klassen überlappen, und die Wahrscheinlichkeit solcher Überschneidungen.
- Gesamtlabel Gesundheitsbewertung: Bietet einen allgemeinen Hinweis auf die Etikettenqualität des Datensatzes (höhere Punktzahl bedeutet eine bessere Gesundheit).
Schritt 4: Erkennen Sie minderwertige Proben
Dieser Schritt beinhaltet das Erkennen und Isolieren der Proben im Datensatz, die möglicherweise kennzeichnende Probleme haben. CleanLab verwendet die vorhergesagten Wahrscheinlichkeiten und die wahren Beschriftungen, um minderwertige Stichproben zu identifizieren, die dann überprüft und gereinigt werden können.
# Get low-quality pattern indices
from cleanlab.filter import find_label_issues
issue_indices = find_label_issues(labels=y_encoded, pred_probs=pred_probs)
# Show problematic samples
low_quality_samples = df_clean.iloc(issue_indices)
print("Low-quality Samples:n", low_quality_samples)- find_label_issues (): Eine Funktion von CleanLab, die die Indizes von Stichproben mit Beschriftungsproblemen erkennt, basierend auf dem Vergleich der vorhergesagten Wahrscheinlichkeiten (Pred_PROBS) und echten Bezeichnungen (y_encoded).
- Issue_indices: Speichert die Indizes der Proben, die CleanLab als potenzielle Kennzeichnungsprobleme (dh minderwertige Proben) identifiziert hat.
- DF_CLEAN.ILOC (Issue_indices): Extrahiert die problematischen Zeilen aus dem sauberen Datensatz (df_clean) mit den Indizes der minderwertigen Proben.
- low_quality_samples: Hält die als Kennzeichnungsprobleme identifizierten Stichproben, die für potenzielle Korrekturen weiter überprüft werden können.
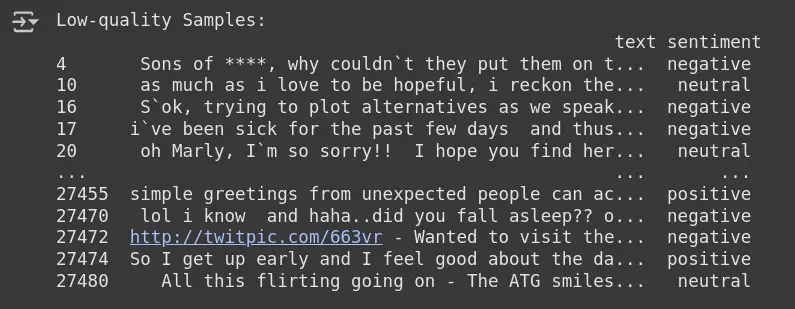
Schritt 5: Erkennende laute Beschriftungen über Modellvorhersage erkennen
Dieser Schritt beinhaltet die Verwendung von CleanLearning, a CleanLab -Methode, Um laute Beschriftungen im Datensatz zu erkennen, indem ein Modell trainiert und seine Vorhersagen verwendet werden, um Stichproben mit inkonsistenten oder lauten Beschriftungen zu identifizieren.
from cleanlab.classification import CleanLearning
from cleanlab.filter import find_label_issues
from sklearn.feature_extraction.textual content import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
# Encode labels numerically
le = LabelEncoder()
df_clean('encoded_label') = le.fit_transform(df_clean('sentiment'))
# Vectorize textual content knowledge
vectorizer = TfidfVectorizer(max_features=3000)
X = vectorizer.fit_transform(df_clean('textual content')).toarray()
y = df_clean('encoded_label').values
# Practice classifier with CleanLearning
clf = LogisticRegression(max_iter=1000)
clean_model = CleanLearning(clf)
clean_model.match(X, y)
# Get prediction chances
pred_probs = clean_model.predict_proba(X)
# Discover noisy labels
noisy_label_indices = find_label_issues(labels=y, pred_probs=pred_probs)
# Present noisy label samples
noisy_label_samples = df_clean.iloc(noisy_label_indices)
print("Noisy Labels Detected:n", noisy_label_samples.head())
- Label -Codierung (labelCoder ()): Konvertiert String -Etiketten (z. B. „positiv“, „negativ“) in numerische Werte, wodurch sie für maschinelle Lernmodelle geeignet sind.
- Vektorisation (tfidfVectorizer ()): Konvertiert Textdaten mithilfe von TF-IDF in numerische Merkmale und konzentriert sich auf die 3.000 wichtigsten Merkmale aus der Spalte „Textual content“.
- Zugklassifizierer (logisticRegression ()): Verwendet die logistische Regression als Klassifikator für das Coaching des Modells mit den codierten Beschriftungen und vektorisierten Textdaten.
- CleanLearning (CleanLearning ()): Wendet CleanLearning auf das logistische Regressionsmodell an. Diese Methode verfeinert die Fähigkeit des Modells, laute Beschriftungen zu bewältigen, indem sie sie während des Trainings berücksichtigen.
- Vorhersagewahrscheinlichkeiten (predict_proba ()): Nach dem Coaching prognostiziert das Modell die Klassenwahrscheinlichkeiten für jede Stichprobe, mit der potenzielle, verrückte Beschriftungen identifiziert werden.
- find_label_issues (): Verwendet die vorhergesagten Wahrscheinlichkeiten und die wahren Bezeichnungen, um festzustellen, welche Proben verrückte Beschriftungen (dh wahrscheinlich Misklabel) aufweisen.
- Laute Beschriftungen anzeigen: Ruft die Proben mit lauten Beschriftungen anhand ihrer Indizes ab und zeigt sie an, sodass Sie sie überprüfen und potenziell reinigen können.
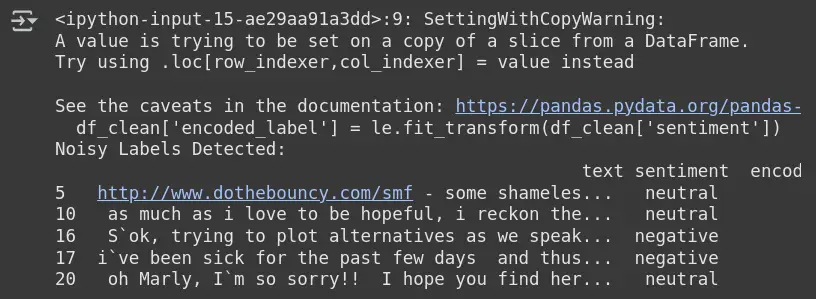
Beobachtung
Ausgang: Laute Beschriftungen erkannt
- CleanLab -Flaggen Muster, bei denen das vorhergesagte Gefühl (aus dem Modell) nicht mit dem bereitgestellten Etikett übereinstimmt.
- Beispiel: Zeile 5 ist impartial bezeichnet, aber das Modell glaubt, dass dies nicht der Fall ist.
- Diese Stichproben sind aufgrund des Modellverhaltens wahrscheinlich falsch oder mehrdeutig.
- Es hilft, problematische Proben für eine bessere Modellleistung zu identifizieren, neu zu identifizieren oder zu entfernen.
Abschluss
Die Vorverarbeitung ist der Schlüssel zum Aufbau zuverlässig Modelle für maschinelles Lernen. Es beseitigt Inkonsistenzen, standardisiert Eingaben und verbessert die Datenqualität. Aber die meisten Workflows verpassen eine Sache, die lautes Labels sind. CleanLab füllt diese Lücke. Es erkennt automatisch fehlzündliche Daten, Ausreißer und minderwertige Stichproben. Keine manuellen Überprüfungen erforderlich. Dies macht Ihren Datensatz sauberer und Ihre Modelle intelligenter.
Das Vorverarbeitung von CleanLab steigert nicht nur die Genauigkeit, sondern spart Zeit. Durch frühes Entfernen von schlechten Etiketten reduzieren Sie die Trainingsbelastung. Weniger Fehler bedeuten eine schnellere Konvergenz. Mehr Sign, weniger Rauschen. Bessere Modelle, weniger Aufwand.
Häufig gestellte Fragen
Ans. CleanLab hilft bei der Erkennung und Behebung fehlzündlicher, lauter oder minderwertiger Daten in gekennzeichneten Datensätzen. Es ist nützlich für Domänen wie Textual content, Bild und tabellarische Daten.
Ans. Nr. CleanLab arbeitet mit der Ausgabe vorhandener Modelle. Es muss keine Umschulung erforderlich sind, um Label -Probleme zu erkennen.
Ans. Nicht unbedingt. CleanLab kann sowohl mit herkömmlichen ML -Modellen als auch mit Deep -Studying -Modellen verwendet werden, solange Sie vorhergesagte Wahrscheinlichkeiten bieten.
Ans. Ja, CleanLab ist für eine einfache Integration ausgelegt. Sie können es schnell mit nur wenigen Codezeilen verwenden, ohne dass sich Ihr Workflow wesentlich ändert.
Ans. CleanLab kann verschiedene Arten von Etikettenrauschen verarbeiten, einschließlich Fehlvermittlung, Ausreißer und unsicherer Etiketten, wodurch Ihr Datensatz sauberer und für Trainingsmodelle zuverlässiger wird.
Hallo, ich bin Vipin. Ich bin begeistert von Datenwissenschaft und maschinellem Lernen. Ich habe Erfahrung mit der Analyse von Daten, dem Aufbau von Modellen und der Lösung realer Probleme. Ich möchte Daten verwenden, um praktische Lösungen zu erstellen und in den Bereichen Datenwissenschaft, maschinelles Lernen und NLP zu lernen.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.