Mein Wirtschaftskollege Rajiv Sethi aus Columbia schreibt:
Die erste (und möglicherweise letzte) Debatte zwischen den beiden Präsidentschaftskandidaten der großen Parteien der Vereinigten Staaten ist vorbei … Bewegungen auf den Prognosemärkten geben uns einen Einblick in das, was uns am Horizont erwarten könnte.
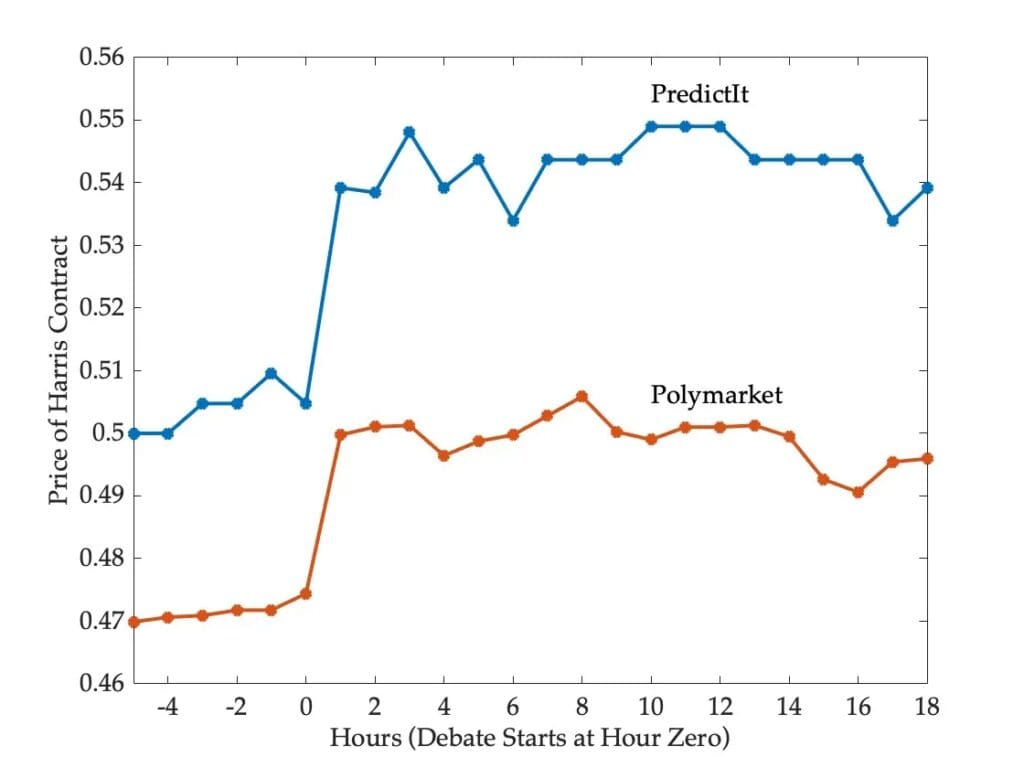
Die folgende Abbildung zeigt die Preise für den Harris-Vertrag auf PredictIt und Polymarket für einen 24-Stunden-Zeitraum, der die Debatte umfasst, angepasst, um ihre Interpretation als Wahrscheinlichkeiten zu ermöglichen und einen Vergleich mit statistischen Modellen zu erleichtern.
Die beiden Märkte reagierten auf die Debatte sehr ähnlich – sie bewegten sich in etwa gleichem Ausmaß in dieselbe Richtung. Eine Stunde nach Beginn der Debatte conflict die Wahrscheinlichkeit eines Harris-Sieges bei PredictIt von 50 auf 54 und bei Polymarket von 47 auf 50 gestiegen. Danach schwankten die Preise um diese höheren Werte.
Statistische Modelle, wie sie etwa von FiveThirtyEight, Silver Bulletin und dem Economist veröffentlicht werden, können auf derartige Ereignisse nicht sofort reagieren. Es wird mehrere Tage dauern, bis sich die Auswirkungen der Debatte (sofern überhaupt welche auftreten) in den Umfragen zum Pferderennen bemerkbar machen, und die Modelle werden reagieren, wenn die Umfragen dies tun.

Dies bezieht sich auf etwas, das wir bereits besprochenund so kann eine Prognose wie unsere im Economist verfügbare Informationen nutzen, die nicht im fundamentalen Modell enthalten sind und auch noch nicht in die Umfragen eingeflossen sind. Zu diesen Informationen gehören Debattenergebnisse, politische Empfehlungen und andere aktuelle Nachrichten sowie potenzielle tickende Zeitbomben wie unpopuläre Positionen, die ein Kandidat vertritt, von denen die Öffentlichkeit aber noch nicht vollständig Kenntnis hat.
Sethi verweist auf die obige Grafik, die die unterschiedlichen Preise auf den verschiedenen Märkten zeigt, und fährt fort:
Obwohl die Märkte auf die Debatte ähnlich reagierten, ist die Meinungsverschiedenheit zwischen ihnen hinsichtlich des Wahlergebnisses nicht geringer geworden. Dies wirft die Frage auf, wie eine solche Meinungsverschiedenheit angesichts finanzieller Anreize aufrechterhalten werden kann. Könnten Händler nicht auf Polymarket gegen Trump und auf PredictIt gegen Harris wetten und sich damit einen sicheren Gewinn von etwa vier Prozent über zwei Monate oder mehr als 26 Prozent auf Jahresbasis sichern? Und würde das Ausnutzen solcher Arbitragemöglichkeiten nicht die Preise auf allen Märkten angleichen?
Es gibt mehrere Hindernisse bei der Umsetzung einer solchen Strategie. PredictIt ist auf verifizierte Einwohner der USA beschränkt, die Konten mit Bargeld aufladen, während der Handel auf Polymarket kryptobasiert ist und die Börse keine Bareinzahlungen von US-Bürgern akzeptiert. Dies führt zu einer Marktsegmentierung und begrenzt die marktübergreifende Arbitrage. Darüber hinaus hat PredictIt ein Restrict von 850 USD für die Positionsgröße in jedem beliebigen Kontrakt sowie eine strafende Gebührenstruktur.
Das ist alles tremendous interessant. Viele der Diskussionen über Prognosemärkte, die ich mitbekommen habe, sind von einer pro- oder anti-marktwirtschaftlichen Ideologie geprägt, und es ist erfrischend, diese Gedanken von Sethi zu hören, einem Ökonomen, der Prognosemärkte untersucht und sowohl gute als auch schlechte Dinge an ihnen sieht, ohne sie blind zu fördern oder ideologisch abzulehnen.
Sethi diskutiert auch öffentliche Prognosen, die auf Fundamentaldaten und Umfragen basieren:
Während Arbitrage die Unterschiede zwischen den Märkten begrenzt, gibt es bei statistischen Modellen keine derartige Einschränkung. Hier sind die Unterschiede wesentlich größer – die Wahrscheinlichkeit eines Trump-Sieges reicht von 45 Prozent bei FiveThirtyEight bis zu 49 Prozent beim Economist und 62 Prozent beim Silver Bulletin.
Warum gibt es zwischen Modellen, die im Grunde dieselben Bestandteile verwenden, so große Unterschiede? Ein Grund dafür ist eine fragwürdige „Konventionsanpassung“ im Silver Bulletin-Modell, ohne die die Abweichung von FiveThirtyEight vernachlässigbar wäre.
Aber es gibt auch einige tiefgreifende Unterschiede in der zugrundeliegenden Korrelationsstruktur dieser Modelle, die ich äußerst rätselhaft finde. Laut dem Silver Bulletin-Modell ist es beispielsweise wahrscheinlicher, dass Trump New Hampshire gewinnt (30 Prozent), als dass Harris Arizona gewinnt (23 Prozent). Die anderen beiden Modelle bewerten diese beiden Staaten sehr unterschiedlich, wobei ein Sieg Harris‘ in Arizona deutlich wahrscheinlicher ist als ein Sieg Trumps in New Hampshire. Abgesehen von den Anpassungen der Parteitagsabstimmungen erscheint mir die Korrelationsstruktur zwischen den Staaten im Silver Bulletin-Modell einfach nicht plausibel.
Ich habe dazu ein paar Gedanken:
1. Eine Faustregel, die ich vor einigen Jahren in meinem Beitrag berechnet habe, Ist es sinnvoll, von einer Wahrscheinlichkeit von „65,7 %“ zu sprechen, dass Obama die Wahl gewinnen wird?ist, dass ein Anteil von 10 Prozentpunkten an der Gewinnwahrscheinlichkeit etwa einer Schwankung von vier Zehntelprozentpunkten beim erwarteten Stimmenanteil entspricht. Die Schwankungen von 5 Prozentpunkten in diesen Märkten entsprechen additionally etwa einer Schwankung von zwei Zehntelprozentpunkten bei der Meinung, was man sich grob als etwa gleichbedeutend mit einem impliziten Modell vorstellen kann, bei dem der endgültige Effekt der Debatte irgendwo zwischen null und einem halben Prozentpunkt liegt.
2. Die Faustregel gibt uns eine Möglichkeit, die Unterschiede in den Vorhersagen verschiedener Prognosen grob zu kalibrieren. Ein Unterschied zwischen einer Trump-Gewinnwahrscheinlichkeit von 50 % in einer Prognose und 62 % in einer anderen entspricht einem Unterschied von einem halben Prozentpunkt im prognostizierten nationalen Stimmenanteil. Angesichts aller Ermessensentscheidungen, die erforderlich sind, um zu entscheiden, welche Umfragen einbezogen werden, wie man sie an unterschiedliche Meinungsforschungsinstitute anpasst, wie man bundesstaatliche und nationale Umfragen kombiniert und wie man das vorherige oder fundamentalbasierte Modell einrichtet, erscheint es nicht unangemessen, dass verschiedene Prognosen beim Ergebnis um einen halben Prozentpunkt abweichen.
3. Bezüglich Korrelationen: Ich denke, dass Nate Silvers Ansatz sowohl die Stärken als auch die Schwächen eines stark empirischen, nicht modellbasierten Ansatzes hat. Ich habe noch nie ein Dokument gesehen, das beschreibt, was er getan hat (fairerweise muss man sagen, dass wir auch für das Economist-Modell kein solches Dokument haben!); mein Eindruck, basierend auf dem, was ich gelesen habe, ist, dass er mit der Aggregation von Umfragen begann, dann eine Artwork Gewichtung anwendet und dann ein Unsicherheitsmodell hat, das auf Unsicherheiten in staatlichen Prognosen und unsicheren demografischen Schwankungen basiert. Ich denke, dass einige der das kontraintuitive Verhalten in den Schwänzen kommt von den demografisch bedingten Unsicherheiten und auch, weil er, zumindest als er unter dem Banner von Fivethirtyeight arbeitete, große Unsicherheiten in den nationalen Wahlprognosen haben wollte, und mit der Methode, die er verwendete, conflict der direkteste Weg, dies zu erreichen, große Unsicherheiten für die einzelnen Staaten anzugeben. Das Ergebnis waren seltsame Dinge wie die Vorhersage, dass, wenn Trump New Jersey gewinnen würde, seine Wahrscheinlichkeit, Alaska zu gewinnen, runter. Das ergibt für niemanden außer Nate Sinn, denn wenn Trump in New Jersey gewonnen hätte, wäre das ein totaler Zusammenbruch der demokratischen Liste gewesen, und es ist schwer zu erkennen, wie sich das in einer besseren Likelihood für Biden in Alaska niedergeschlagen hätte. Es geht hier nicht darum, dass Nate eine Ermessensentscheidung in Bezug auf New Jersey und Alaska getroffen hat; vielmehr ist ein Vorhersagemodell für 50 Staaten eine komplizierte Sache. Man erstellt sein Modell und passt es an die verfügbaren Daten an, dann muss man seine Vorhersagen auf jede erdenkliche Weise überprüfen, und wenn man auf Ergebnisse stößt, die keinen Sinn ergeben, muss man eine Mischung aus Kalibrierung seiner Intuitionen vornehmen (vielleicht ist es Ist vernünftig anzunehmen, dass Trumps Sieg in New Jersey mit einem Sieg Bidens in Alaska einhergeht?) und herauszufinden, was mit dem Modell schiefgelaufen ist (ich vermute einige additive Fehlerterme mit hoher Varianz, die keine Probleme mit der nationalen Prognose verursachten, aber unerwünschte Eigenschaften im Ende hatten). Sie können einige dieser Dinge herausfinden, indem Sie nachverfolgen und andere Aspekte der Prognose betrachten, wie ich es in der verlinkter Beitrag.
Additionally, ja, ich würde die Korrelationen in Nates Prognose nicht so ernst nehmen. Das heißt, ich würde auch die Korrelationen in unserer Economist-Prognose nicht allzu ernst nehmen! Wir haben unser Bestes gegeben, aber es gibt viele bewegliche Teile und viele Möglichkeiten, etwas falsch zu machen. Was mir an Rajivs Beitrag gefällt, ist, dass er bereit ist, die gleiche kritische Arbeit an den marktbasierten Prognosen zu leisten und sie nicht einfach als Blackbox zu behandeln.