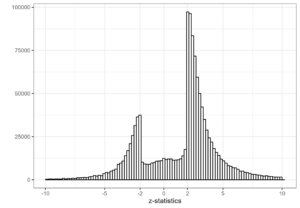
Das ist Erik. Vor fünf Jahren habe ich eine kurze Arbeit darüber geschrieben Der Signifikanzfilter, der Fluch des Gewinners und das Bedürfnis zu schrumpfen (mit Eric Cator). Der Hauptzweck bestand darin, einige mathematische Ergebnisse zur späteren Bezugnahme zu veröffentlichen. Um die Arbeit etwas interessanter zu gestalten, wollten wir ein motivierendes Beispiel hinzufügen. Ich bin auf einen Artikel von gestoßen Barnett und Wren (2019) der mehr als eine Million Konfidenzintervalle von Verhältnisschätzungen aus PubMed entnommen und öffentlich zugänglich gemacht hat. Ich habe die Konfidenzintervalle in Z-Statistiken umgewandelt, ein Histogramm erstellt und warfare überrascht, dass zwischen -2 und 2 keine Z-Statistiken vorhanden waren (dh nicht signifikante Ergebnisse).
load(url("https://github.com/agbarnett/intervals/uncooked/grasp/knowledge/Georgescu.Wren.RData"))
d=full(full$mistake==0,)
L=log(d$decrease) # take the log as a result of these are ratio estimates
U=log(d$higher)
estimate=(L+U)/2
stderror=(U-L)/(2*1.96)
z=estimate/stderror
hist(z(abs(z)<10),100)

Richard McElreath bemerkte die Figur, schnitt sie aus unserer Zeitung und habe es gepostet auf Twitter. Als nächstes wurde es von mehreren (relativ) großen Kunden übernommen; Harlan Krumholz, Neugieriger Vogel, Kareem Carr, John Holbein, Cremieux Und Nicolas Fabiano. Erst vor 2 Wochen John Holbein hat seinen früheren Beitrag noch einmal erhöht und weitere tausend Likes erhalten. Das Histogramm ist auch bei Bloggern sehr beliebt, siehe Hier, Hier, Hier, Hier, Hier, Hier, Hier, Hier, Hier, Hier, Hier Und Hier. Adrian Barnett und David Borg haben eine geschrieben Blogbeitrag mit ihrer eigenen Model des Histogramms. Es wurden auch mehrere Memes erstellt.
Zum fünfjährigen Jubiläum des Histogramms wollte ich auf ein paar typische Kommentare reagieren. Zum Beispiel, Adriano Aguzzi kommentierte:
Lassen Sie uns darüber nicht hyperventilieren. Es liegt in der Natur der Sache, dass detrimental Ergebnisse selten aussagekräftig sind und daher selten veröffentlicht werden. Und das ist völlig legitim.
Es ist gelinde gesagt enttäuschend, dass viele Menschen immer noch das Drawback der Verzerrung der wissenschaftlichen Aufzeichnungen durch die selektive Berichterstattung und Veröffentlichung von Ergebnissen mit p<0,05 nicht erkennen.
Ein weiterer typischer Kommentar (Simo110901):
Ich denke nicht, dass das grundsätzlich schlecht ist. Ein Teil dieser Voreingenommenheit ist sicherlich auf die Veröffentlichungsvoreingenommenheit zurückzuführen, aber ein erheblicher Teil (hoffentlich die Mehrheit) könnte darauf zurückzuführen sein, dass Forscher oft sehr intestine darin sind, fundierte Vermutungen zu formulieren, und daher in den meisten Fällen in der Lage sind, Nullergebnisse abzulehnen.
Viele andere Kommentatoren glauben auch, dass das Fehlen nicht signifikanter Ergebnisse auf die Fähigkeit der Forscher zurückzuführen ist, ihre Studien genau richtig zu dimensionieren, um statistische Signifikanz mit minimaler Unterschreitung zu erhalten. Das ist sehr unwahrscheinlich. In der folgenden Abbildung vergleiche ich die Z-Statistiken von Barnett und Wren (2019) mit einem Satz von mehr als 20.000 Z-Statistiken der primären Wirksamkeitsendpunkte klinischer Studien aus der Cochrane Database of Systematic Opinions (CDSR).
d=learn.csv("https://osf.io/xq4b2/?motion=obtain")
d=d %>% filter(RCT=="sure",consequence.group=="efficacy", consequence.nr==1, abs(z)<20 )
d=group_by(d,examine.id.sha1) %>% sample_n(measurement=1) # one consequence per examine
hist(d$z(abs(d$z)<10),50)
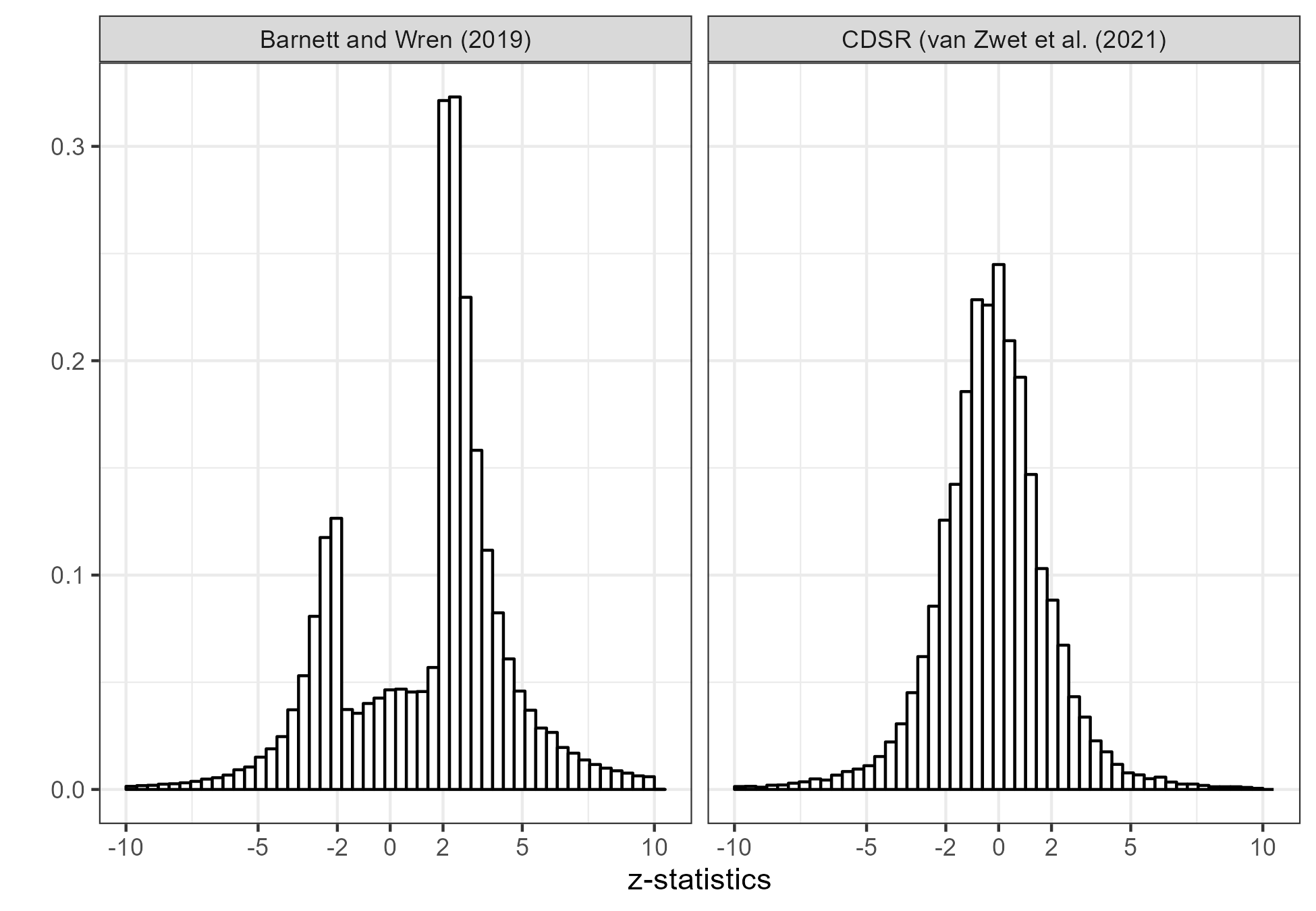
Das Histogramm des CDSR (rechts) zeigt keine nennenswerte Lücke. Ich weiß nicht genau, warum das so ist, vermute aber, dass es daran liegt, dass es sich bei klinischen Studien um seriöse Forschung handelt. Sie sind in der Regel in dem Sinne vorregistriert, dass sie über ein Protokoll verfügen, das von einem institutionellen Prüfungsausschuss genehmigt wurde. Sie sind teuer und zeitaufwändig. Selbst wenn sie nicht von Bedeutung sind, wäre es eine Schande, sie nicht zu veröffentlichen. Schließlich wäre es für die Teilnehmer unethisch, keine Veröffentlichungen vorzunehmen.
Ein weiterer typischer Kommentar (Daniel Lakens):
Dies ist kein genaues Bild davon, wie voreingenommen die Literatur ist. Die Autoren analysieren p-Werte nur in Abstracts.
Barnett und Wren (2019) sammelten Z-Statistiken aus beiden Abstracts Und Volltextquellen. Die Volltextdaten sind für Artikel verfügbar, die auf PubMed Central verfügbar sind. Es gibt 961.862 Abstracts und 348.809 Volltextquellen. Unten zeige ich die Z-Statistiken separat. Die Verteilungen sind bemerkenswert ähnlich, obwohl der Anteil nichtsignifikanter Ergebnisse aus den Volltexten etwas höher ist

Bei jedem automatisierten Scraping-Algorithmus werden zwangsläufig einige Dinge übersehen. Es ist durchaus möglich, dass nicht signifikante Ergebnisse, die nicht im Summary oder Haupttext enthalten sind, dennoch in separaten Tabellen, Anhängen und Ergänzungen aufgeführt werden. Es wird jedoch bezweifelt, dass dies der Grund für die große Lücke ist. Ich bin ziemlich überzeugt, dass die Z-Statistiken von PubMed tatsächlich starke Beweise für eine Publikationsverzerrung gegenüber nicht signifikanten Ergebnissen in der medizinischen Fachliteratur liefern. Es sollte jedoch beachtet werden, dass die Unterrepräsentation der Z-Statistiken zwischen -2 und 2 wahrscheinlich nicht nur auf einen Publikationsbias zurückzuführen ist, sondern auch darauf, dass Autoren keine Konfidenzintervalle für nicht signifikante Ergebnisse angegeben haben. Das ist natürlich immer noch keine gute Sache.