Dieser lange Beitrag behandelt vier Themen:
1. Die beeindruckende Siegesserie der Knicks, die nach einem Rückstand den NBA-Titel in fünf Spielen gewannen;
2. Die Martingaleigenschaft von Wahrscheinlichkeitsvorhersagen;
3. Ein Beispiel für das Lernen aus der Simulation;
4. Wie wir (manchmal) Wahrscheinlichkeits- und Statistikforschung betreiben.
Ich weiß nicht genug über die Zielgruppe dieses Blogs, um zu wissen, welches der vier Themen die meisten von Ihnen ansprechen wird. Für das Web insgesamt ist es die Nummer 1; Für die meisten von Ihnen dürfte es Nr. 3 sein.
Ich interessiere mich für alle vier, weshalb ich das jetzt alles aufschreibe. Es ist mir peinlich zu sagen, dass dies mehrere Stunden gedauert hat. Ursprünglich hatte ich geplant, diesen Sonntagmorgen nach dem Spiel zu posten, aber es hat einige Zeit gedauert, bis ich zur Aufgabe kam. Der größte Teil des Aufwands lag im Schreiben des Codes, nicht im Schreiben des Textes. Und es gibt tatsächlich nicht viel Code, wie Sie sehen können, wenn Sie zum Ende dieses Beitrags scrollen. Der Hauptaufwand bestand nicht darin, die Syntax herauszufinden oder gar zu debuggen (obwohl es einiges davon gab), sondern herauszufinden, was ich überhaupt codieren wollte.
Positiv zu vermerken ist, dass es sich hier um eine Recherche handelt, die ich schon seit einiger Zeit durchführen wollte. (a) Ich glaube additionally nicht, dass diese Mühe umsonst ist, auch nicht über den Bildungs- und Unterhaltungswert hinaus, den sie für Sie haben magazine, und (b) Ich habe daraus schon einiges gelernt. Ein Blick auf Daten ist immer intestine; Mit Simulationen zu experimentieren ist immer intestine.
Okay, los geht’s.
Das NBA-Finale
Hey, Denken Sie daranaus Spiel 4 der letzten NBA-Finals:

Oder der Verlauf des Spiels, das danach folgte:

Der Vollständigkeit halber finden Sie hier die Aufzeichnungen für die Spiele 3, 2 und 1, ebenfalls mit freundlicher Genehmigung von ESPN:

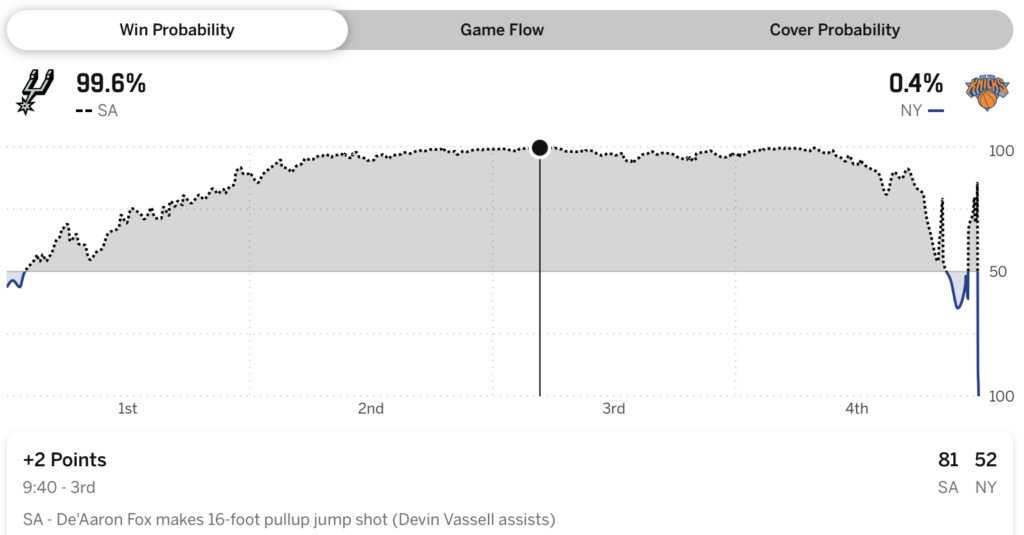
In Spiel 4 wurde geschätzt, dass die Spurs zu einem Zeitpunkt eine Siegchance von 99,6 % hatten. Aber wie Sie vielleicht gehört haben, haben sie verloren.
Excessive Gewinnwahrscheinlichkeiten
Waren die angegebenen Gewinnwahrscheinlichkeiten zu extrem?
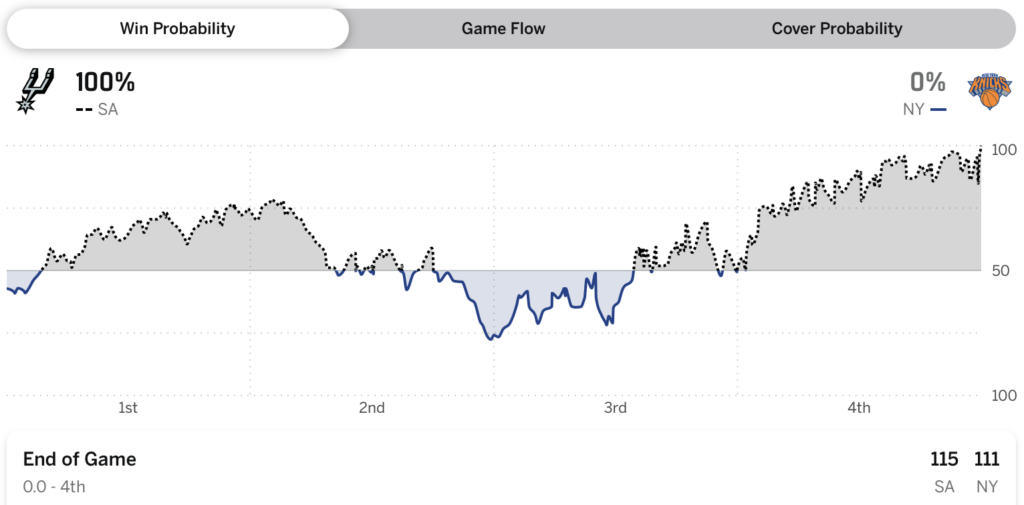
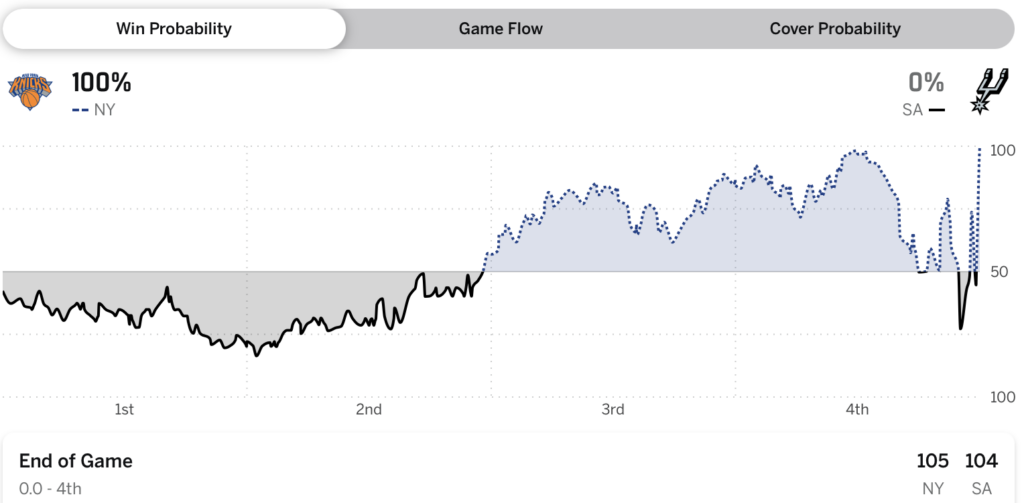
Einerseits passieren natürlich gelegentlich ungewöhnliche Ereignisse. Wenn die Wahrscheinlichkeit einer Niederlage bei 0,4 % liegt, sollte das in 1 von 250 Fällen passieren, und allein in der vergangenen Saison gab es viel mehr als 250 Basketballspiele. Andererseits sollen sehr ungewöhnliche Ereignisse nur sehr selten passieren, und es gab einen Punkt im dritten Viertel von Spiel 4, an dem der Algorithmus von ESPN den Spurs eine Siegchance von 97,1 % gab, ein Punkt in Spiel 1, an dem den Spurs eine Likelihood von 94,1 % gegeben wurde. Es gab einen Second in Spiel 2, in dem den Knicks eine Siegchance von 98,2 % zugeschrieben wurde, und natürlich haben sie dieses Spiel gewonnen, aber wenn man bedenkt, dass das Endergebnis 105-104 struggle, nach Unentschieden zwischen 97-97 und 104-104, scheint es im Nachhinein, dass diese 98,2 % etwas zu selbstbewusst waren.
Sollten wir diesen Wahrscheinlichkeiten gegenüber misstrauisch sein? Eine Möglichkeit, diese Frage zu stellen, besteht darin, die Kalibrierung zu überprüfen: Wenn wir alle Spielsituationen sammeln, in denen eine Mannschaft eine Siegesquote von 99,6 % hat, gewinnt sie dann in 99,6 % der Fälle?
Andererseits wähle ich die extremsten Werte dieser Gewinnwahrscheinlichkeiten. Sie sollten die Gewinnwahrscheinlichkeiten jederzeit kalibrieren lassen, und es ist in Ordnung, davon abhängig zu machen, aber nur davon, was zuvor kam.
Das heißt, wenn wir die Gewinnwahrscheinlichkeiten am Ende des ersten Viertels, am Ende der ersten Hälfte oder am Ende des dritten Viertels betrachten, sollten sie kalibriert werden. Und wenn Sie die Gewinnwahrscheinlichkeiten nur dann betrachten, wenn sie größer als 99 % sind, sollten sie kalibriert werden. Und wenn man sich nur die Gewinnwahrscheinlichkeiten anschaut, wenn sie bisher im Spiel maximal sind, sollten sie kalibriert werden. Mir ist jedoch nicht klar, dass Sie erwarten sollten, dass die Kalibrierung für die Gewinnwahrscheinlichkeiten so gewählt wird, dass sie für das gesamte Spiel maximal ist, denn wenn die Gewinnwahrscheinlichkeit zum Zeitpunkt t p
Die Martingaleigenschaft von Wahrscheinlichkeitsvorhersagen
Darüber haben wir in Abschnitt 1.6 unseres Artikels aus dem Jahr 2020 geschrieben: Informationen, Anreize und Ziele in Wahlprognosen:


Und es kam auch in einigen Blogbeiträgen vor:
ab 2024: „Ungewöhnliche Wettmuster bei mehreren Tempelspielen“: Es ist Martingal-Zeit, Child!
Ich gehe davon aus, dass die Gewinnwahrscheinlichkeiten von ESPN näher an der Kalibrierung liegen als die Quoten auf dem Prognosemarkt oder modellbasierte Wahlprognosen. Prognosemärkte hängen von den Wettenden ab und es gibt keinen Grund, eine Kalibrierung zu erwarten, zumindest nicht, bis der Markt in gewisser Weise vollständig ausgereift ist. Modellbasierte Wahlprognosen basieren auf Näherungsmodellen mit bekannten Pathologien (zum Beispiel hier), daher sind sie nicht universell kalibriert. Die Wahrscheinlichkeiten von ESPN werden ebenfalls nicht kalibriert – auch sie basieren auf einem unvollständigen Modell –, aber ich gehe davon aus, dass das Modell auf Tonnen von Daten trainiert wurde, additionally glaube ich nicht, dass es weit davon entfernt sein sollte.
Wenn mir jemand die von Second zu Second geschätzten Gewinnwahrscheinlichkeiten aus einer großen Datenbank mit Basketballspielen schicken könnte, könnten wir einen Blick darauf werfen.
In der Zwischenzeit können wir eine gewisse Instinct erlangen, indem wir anhand eines mathematischen Modells simulieren, mit dem wir Gewinnwahrscheinlichkeiten genau berechnen können.
Den Prozess simulieren
Nehmen Sie eine einfache Brownsche Bewegung mit Drift an, bei der die Bewertungsdifferenz y
Eine coole Sache an diesem Modell ist, dass die Gewinnwahrscheinlichkeit anhand der Punktedifferenz zu jedem Zeitpunkt im Spiel trivial berechnet werden kann.
Wie falsch kann man liegen?
Zur Veranschaulichung zeige ich die Ergebnisse – den Punktestand und die Gewinnwahrscheinlichkeit während des Spiels – für 18 unabhängig simulierte Spiele. Der Einfachheit halber gehe ich davon aus, dass die Punkteverteilung 0 beträgt, sodass davon ausgegangen wird, dass die beiden Groups immer gleichwertig sind. Und ich werde das Spiel 10 Mal professional Minute durchlaufen, sodass das Spiel ungefähr aus einer Summe von 480 unabhängigen Schritten besteht.
Der Code ist unten; hier sind die Ergebnisse:

Ich weiß nicht genug über Basketball, um ein Gefühl dafür zu haben, wie plausibel diese als Spielergebnisse sind (abgesehen von der mangelnden Diskretion des Ergebnisses; wir haben ein kontinuierliches Modell verwendet, damit wir die relevanten Wahrscheinlichkeiten einfacher analytisch berechnen können). Sie ähneln dem Spiel Knicks-Spurs nicht allzu sehr, abgesehen von der einen Simulation unten hyperlinks im Diagramm, in der die „Spurs“ im dritten Viertel mit 10 Punkten Vorsprung führten und mit einer Siegwahrscheinlichkeit von 95,6 % das Most erreichten, bevor sie schließlich verloren.
Um ein umfassenderes Bild zu erhalten, habe ich 10.000 Spiele simuliert. (Nur als Anhaltspunkt: Es gibt 30 NBA-Groups, additionally gibt es jedes Jahr 82*30/2=1230 Spiele der regulären Saison.)
Für jedes Spiel habe ich „max_p_wrong“ berechnet: die höchste Gewinnwahrscheinlichkeit, die dem letztendlichen Verlierer des Spiels zugewiesen wird. In meiner Simulation beginnt jedes Spiel mit einer Wahrscheinlichkeit von 50/50 – denken Sie daran, der Einfachheit halber gehe ich immer von einer Punkteverteilung von 0 aus –, additionally muss max_p_wrong irgendwo zwischen 0,5 und 1 liegen. Folgendes kommt dabei heraus:
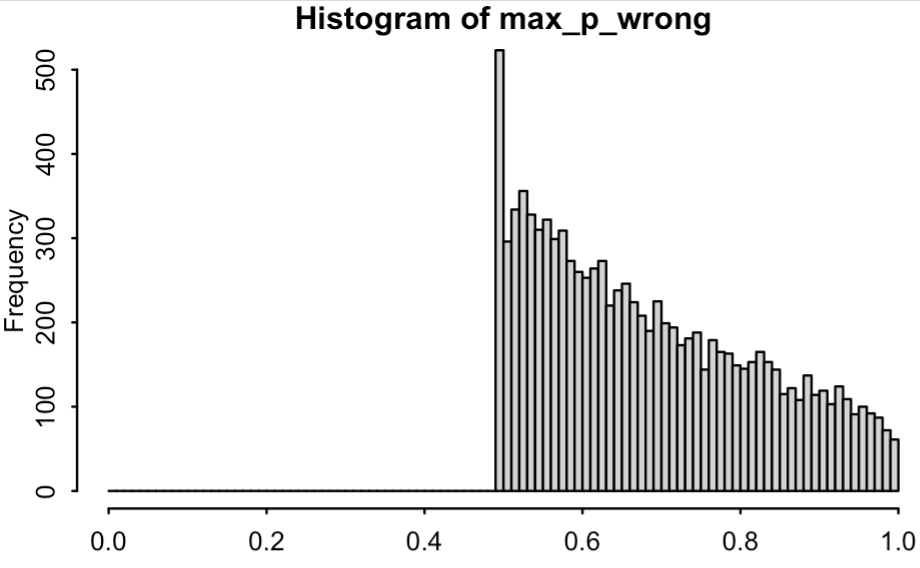
Extrem falsche Wahrscheinlichkeiten sind additionally keine Seltenheit. Wie häufig sind sie? Von diesen 10.000 Spielen hatten 61 einen max_p_wrong von mehr als 99 %. Das heißt, in 0,6 % der Spiele überschreitet die letztendlich verlierende Mannschaft irgendwann im Spiel die Schwelle von 99 % Siegwahrscheinlichkeit.
Dieses Ergebnis sollte steigen, wenn wir zur kontinuierlichen Aktualisierung übergehen. Aber wir aktualisieren bereits 10 Mal professional Minute. Wenn Sie diesen Zeitplan auf 50 Mal professional Minute erhöhen, erhöht sich Pr(max_p_wrong > 0,99) auf 0,0075, und wenn Sie diesen Zeitplan auf 100 Mal professional Minute erhöhen, beträgt er 0,0076. Ich vermute additionally, dass dies ungefähr die kontinuierliche Grenze ist.
OK, nur zur Kontrolle, ich simuliere 100.000 Spiele, und jetzt beträgt Pr(max_p_wrong > 0,99) 0,0072 bei 10 Updates professional Minute oder 0,0084 bei 50 Updates professional Minute. Ich gehe additionally einen Schritt weiter und sage, wenn wir die genaue Wahrscheinlichkeit unter kontinuierlicher Aktualisierung berechnen würden, kämen wir auf 0,0085.
Das struggle eine Überraschung. Bevor ich diese Simulation durchführte, ging ich davon aus, dass die Wahrscheinlichkeit, dass p_win für den letztendlichen Verlierer 99 % übersteigt jederzeit im Spiel selektionsbedingt mehr als 1 % betragen würde. Ich schätze, meine Instinct struggle falsch. Vielleicht liegt es daran, dass ich darauf konditioniere, welches Crew gewinnt. (Natürlich, wenn Sie den anderen Weg gehen, liegt die Wahrscheinlichkeit, dass p_win letztendlich 99 % überschreitet Gewinner liegt bei 100 % im kontinuierlichen Restrict, da der Gewinner mit ziemlicher Sicherheit feststeht, wenn noch eine Epsilon-Sekunde im Spiel verbleibt.)
Additionally, ja, die obige Grafik ist irgendwie interessant. Nach unserem Modell werden die meisten Spiele nicht allzu weit von im Nachhinein peinlichen Wahrscheinlichkeitsschätzungen abweichen, aber das kann manchmal passieren.
Es wäre interessant, die obige Grafik mit dem zu vergleichen, was Sie aus einer Datenbank mit Spielquotendaten von ESPN oder was auch immer erhalten würden.
Um es klarzustellen: Es gibt keinen Grund zu der Annahme, dass die obige Grafik irgendeine universelle Eigenschaft von Martingalen darstellt. Es ist ein ganz besonderes Modell! Aber man muss irgendwo anfangen. Auch die Existenz verschiedener zentraler Grenzwertsätze lässt mich hoffen, dass dies ein allgemeines Ergebnis für eine entsprechend eingeschränkte Klasse stetiger Martingalprozesse sein könnte. Es ist eine Forschungsfrage!
Eine überraschend gleichmäßige Verteilung
Um den Prozess besser zu verstehen, habe ich die Gewinnwahrscheinlichkeiten nach dem Ende jedes der drei Viertel für die 10.000 simulierten Spiele gesammelt. Nachfolgend finden Sie Histogramme dieser Wahrscheinlichkeiten und Kalibrierungsdiagramme:

Es überrascht nicht, dass die Kalibrierung in Ordnung ist. Schließlich werden die Wahrscheinlichkeiten anhand desselben Modells berechnet, aus dem auch die Daten stammen. Tatsächlich ist selbst die scheinbare Anomalie im Diagramm unten hyperlinks nur ein Artefakt bei kleinen Stichproben, das verschwindet, wenn wir die Anzahl der Simulationen auf 100.000 erhöhen.
Interessanter sind die Histogramme. Es macht Sinn, dass die Verteilung der Gewinnwahrscheinlichkeiten im Laufe des Spiels bei 0,5 beginnt und dann allmählich bei 0 und 1 ansteigt. Tatsächlich liegen die Gewinnwahrscheinlichkeiten am Ende des vierten Viertels genau bei 0 und 1.
Aber es ist lustig, dass die Verteilung der Siegwahrscheinlichkeiten zur Halbzeit völlig gleichmäßig ist. Es muss ein direktes mathematisches Argument geben, das eine Instinct für dieses Ergebnis liefert; Es ist zu perfekt, um nur ein Zufall zu sein.
Hier muss noch viel recherchiert werden:
– Verallgemeinerung über das kontinuierliche Modell hinaus, um diskrete Bewertungsänderungen zu ermöglichen.
– Verallgemeinerung über den Random Stroll hinaus; Es gibt keinen Grund, warum das Modell Markovianisch sein muss.
– Gibt es allgemeine Aussagen über diese Verteilungen der Gewinnwahrscheinlichkeiten unter beliebigen Martingalprozessen? Ich gehe davon aus, dass es einige Ergebnisse gibt. Zumindest sollte es einige Ungleichungen und Grenzwertsätze geben.
– Betrachtung realer Daten aus Basketball, anderen Sportarten und anderen Bereichen, einschließlich Wahlprognosen und Prognosemärkten.
Unser ultimatives Ziel besteht hier darin, ein allgemeines Maß für die Abweichung von der Martingaleigenschaft von Wahrscheinlichkeitsvorhersagen zu finden. Wir wollen etwas, das auf jeden Datensatz angewendet werden kann, natürlich mit größerer Präzision, wenn die Serien länger werden, zeitlich feiner verteilt sind und Replikationen verfügbar sind (wie bei den Tausenden von Basketballspielen).
PS Hier ist der R-Code zum Erstellen der obigen Simulationen und Grafiken:
set.seed(123)
blank_plot <- operate() {
plot(0,0,xlab="",ylab="",xaxt="n",yaxt="n",bty="n",sort="n")
}
winprob <- operate(y, t, T, delta, sigma) {
ifelse(t==T, (signal(y)+1)/2, pnorm((y + delta*(T-t))/(sigma*sqrt(T-t))))
}
N_games <- 10000
sigma <- 2
T <- 48
N_time_points <- T*10
t <- seq(0, T, size=N_time_points)
t_gap <- T / (N_time_points - 1)
y <- array(NA, c(N_time_points, N_games))
p_win <- array(NA, c(N_time_points, N_games))
y_final <- rep(NA, N_games)
p_wrong_halftime <- rep(NA, N_games)
max_p_wrong <- rep(NA, N_games)
for (j in 1:N_games){
unfold <- 0
delta <- unfold/T
increments <- rnorm(N_time_points - 1, t_gap*delta, sigma*sqrt(t_gap))
y(,j) <- c(0, cumsum(increments))
p_win(,j) <- winprob(y(,j), t, T, delta, sigma)
y_final(j) <- y(N_time_points,j)
p_wrong_halftime(j) 0, 1 - p_win(N_time_points/2,j), p_win(N_time_points/2,j))
max_p_wrong(j) 0, max(1 - p_win(,j)), max(p_win(,j)))
}
N_plots <- 18
par(mfrow=c(N_plots/3,6), mar=c(3,3,1,1), mgp=c(1.5,.5,0), tck=-.01)
t_range <- vary
y_range <- max(abs(y(,1:N_plots)))*c(-1,1)
p_range 0.99))
par(mfrow=c(3,3), mar=c(3,3,1,1), mgp=c(1.5,.5,0), tck=-.01)
hist(max_p_wrong, breaks=seq(0,1,0.01))
blank_plot()
blank_plot()
for (i in 1:3) {
hist(p_win(N_time_points*i/4,), xlab="ESPN's Pr(win)", most important=paste("Histogram of win prob from finish of quarter", i), cex.most important=.9)
}
for (i in 1:3){
in_quarter = T*(i-1)/4) & (t < T*i/4)
p_win_vector <- as.vector(p_win(in_quarter,))
y_final_vector <- as.vector(matrix(y_final, nrow=sum(in_quarter), ncol=N_games, byrow=TRUE))
N_bins <- 20
boundaries <- seq(0, 1, size=(N_bins+1))
lo <- boundaries(1:N_bins)
hello <- boundaries(2:(N_bins+1))
p_in_bin <- rep(NA, N_bins)
mean_in_bin <- rep(NA, N_bins)
freq_in_bin <- rep(NA, N_bins)
for (okay in 1:N_bins) {
in_bin lo(okay) & p_win_vector < hello(okay)
p_in_bin(okay) <- sum(in_bin)/size(in_bin)
mean_in_bin(okay) <- imply(p_win_vector(in_bin))
freq_in_bin(okay) 0)
}
plot(mean_in_bin, freq_in_bin, pch=20, xlim=c(0,1), ylim=c(0,1), xaxs="i", yaxs="i",
xlab="ESPN's Pr(win)", ylab="Empirical Pr(win)",
most important=paste("Calibration from quarter", i), cex.most important=.9)
}