Ein politikwissenschaftlicher Kollege fragte mich, was ich davon halte dieser aktuelle Artikel von Carlisle Rainey, das beginnt:
Einige Arbeiten zur politischen Methodik empfehlen angewandten Forschern, Punktschätzungen von interessierenden Größen zu erhalten, indem sie Modellkoeffizienten simulieren, diese simulierten Koeffizienten in simulierte interessierende Größen umwandeln und dann die simulierten interessierenden Größen mitteln. . . Andere Arbeiten empfehlen angewandten Forschern jedoch, Koeffizientenschätzungen direkt umzuwandeln, um interessierende Mengen abzuschätzen. Ich weise darauf hin, dass diese beiden Ansätze nicht austauschbar sind und untersuche ihre Eigenschaften. Ich zeige, dass der Simulationsansatz die transformationsbedingte Verzerrung verstärkt. . .
Mit den interessierenden Größen meint er Zusammenfassungen wie „vorhergesagte Wahrscheinlichkeiten, erwartete Anzahlen, marginale Effekte und erste Unterschiede“.
Die statistische Theorie konzentriert sich auf die Schätzung von Parametern in einem Modell und nicht so sehr auf Schlussfolgerungen für abgeleitete Größen, und es stellt sich heraus, dass diese Fragen subtil sind. Es gibt keine einfachen Antworten, wie Iain Pardoe und ich vor Jahren erkannten, als wir versuchten, allgemeine Regeln für die Schätzung durchschnittlicher Vorhersagevergleiche zu entwickeln.
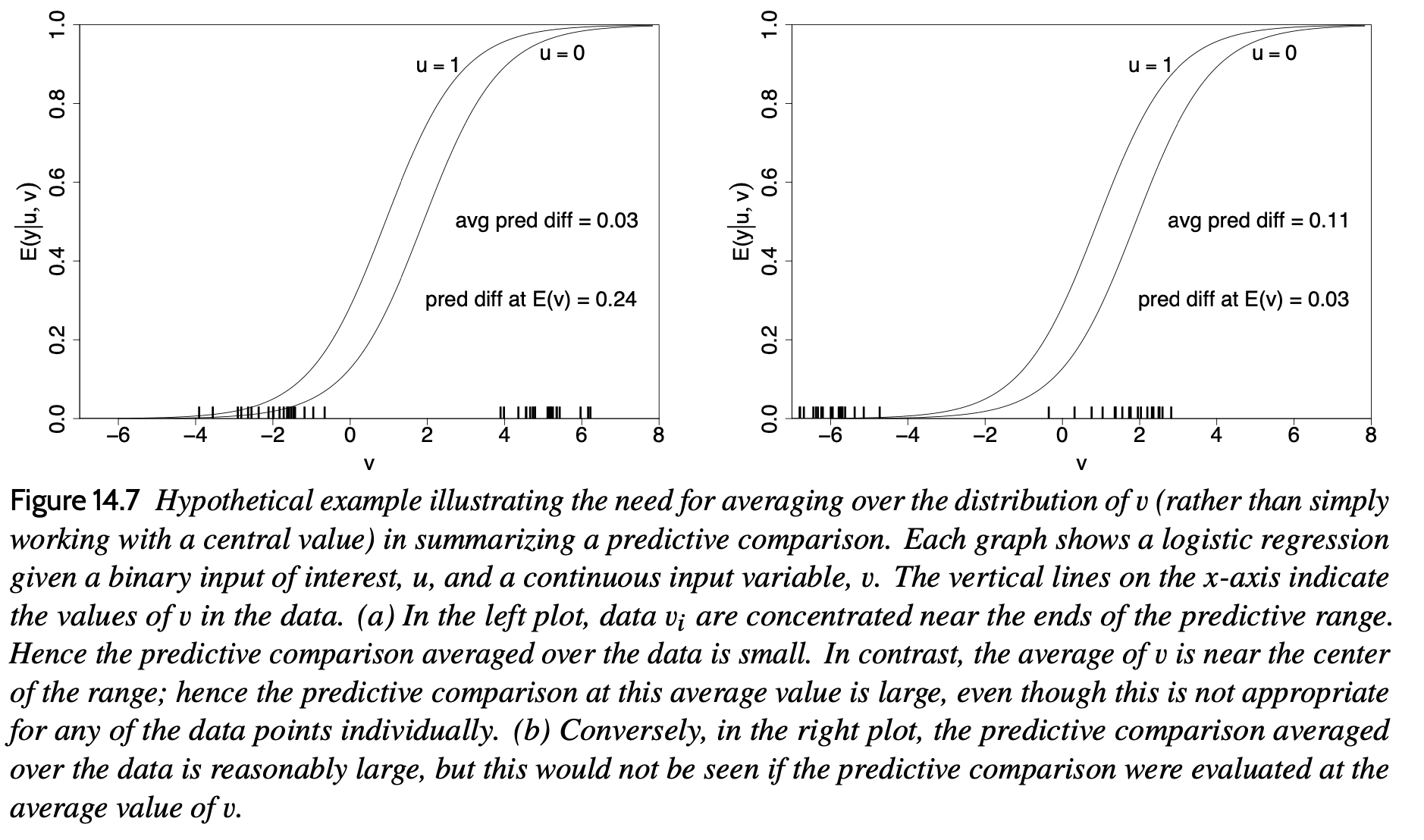
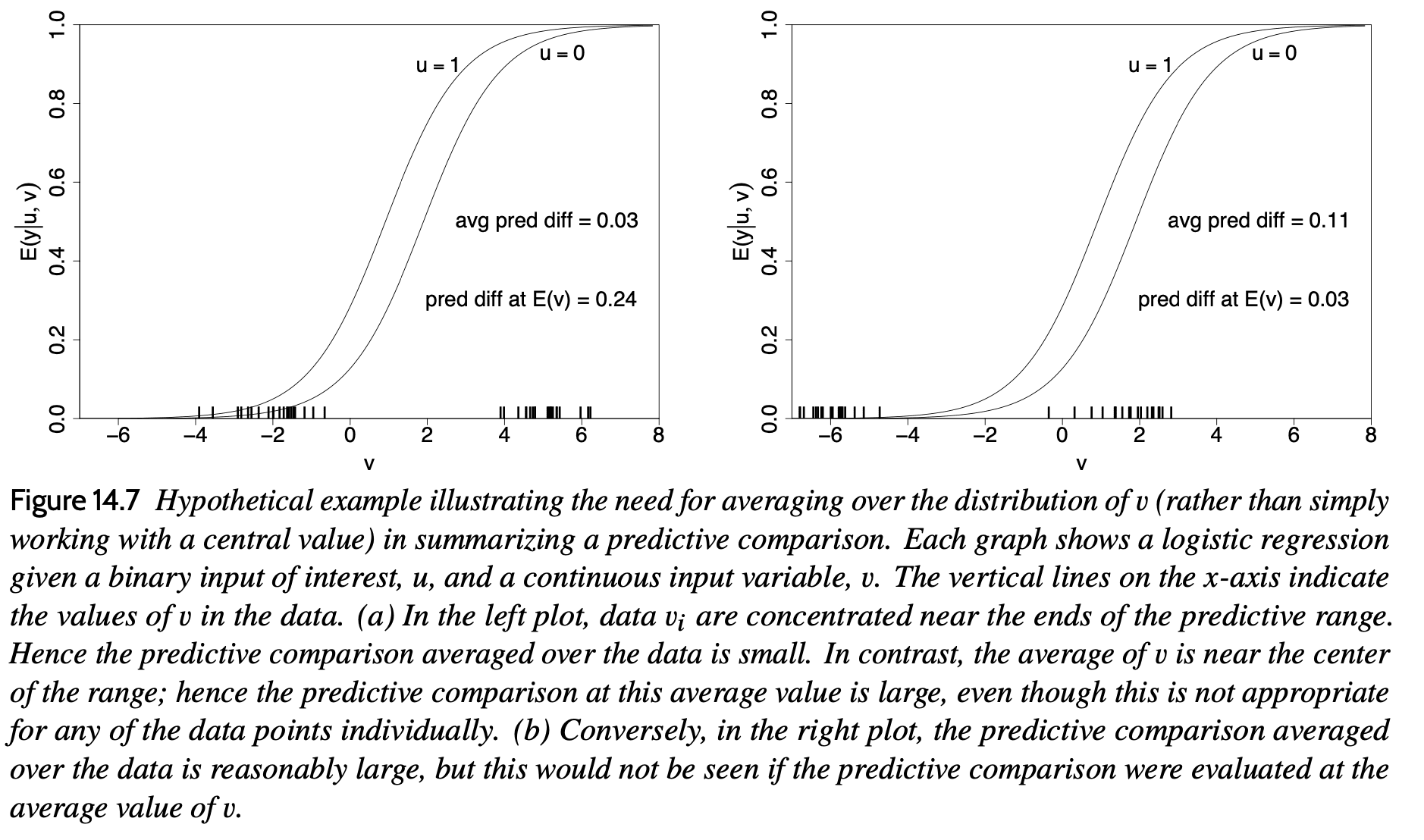
So stellen wir es in Abschnitt 14.4 dar Regression und andere Geschichten:

Es ist ein lustiges Downside, das typisch für viele mathematische Probleme ist, da es keine Möglichkeit gibt, über die richtige Antwort zu sprechen, bis Sie sich entschieden haben, was die Frage ist! Der prädiktive Vergleich – manchmal nennen wir ihn den durchschnittlichen prädiktiven Effekt von u auf y, manchmal vermeiden wir den Begriff „Effekt“ wegen seiner Implikation von Kausalität – hängt von den für u^lo und u^hello gewählten Werten ab die Werte der anderen Prädiktoren v und hängt vom Parametervektor Theta ab. Bei einem linearen Modell ohne Wechselwirkungen verschwinden alle diese Abhängigkeiten, aber im Allgemeinen hängt der durchschnittliche Vorhersagevergleich von all diesen Dingen ab.
Zusammen mit der Bewertung verschiedener Schätzer des durchschnittlichen Vorhersagevergleichs (oder anderer nichtlinearer Zusammenfassungen wie vorhergesagte Wahrscheinlichkeiten und erwartete Anzahlen) müssen wir additionally entscheiden, was wir schätzen möchten. Und das ist keine leichte Frage!
Für mehr zum Thema empfehle ich meine Arbeit von 2007 mit PardoeDurchschnittliche Vorhersagevergleiche für Modelle mit Nichtlinearität, Interaktionen und Varianzkomponenten.
Das Thema hat die Menschen schon früher verwirrt; sehen zum Beispiel hier.
Ich denke, das Downside entsteht durch die falsche Vorstellung, dass es auf diese Frage nur eine einzige richtige Antwort geben sollte. Die Probleme, die Rainey in seinem Artikel diskutiert, sind actual und entstehen in einem größeren Kontext des Versuchs, Methoden für Forscher bereitzustellen, die inferenzielle Zusammenfassungen erstellen, ohne immer eine klare Vorstellung davon zu haben, was sie schätzen wollen. Ich verurteile diese Forscher nicht – mir ist nicht immer klar, an welchen Zusammenfassungen ich interessiert bin.
Auch hier empfehle ich unser Papier von 2007. Es bleiben noch viele offene Fragen!