
https://www.youtube.com/watch?v=gg-9zl59r30
Hallo! Ich bin Anna Strahl, Senior Course Developer bei DataQuest, und ich weiß, wie anspruchsvoll das Starten Ihres ersten Datenprojekts sich anfühlen kann. Fragen wie Welchen Datensatz soll ich verwenden? oder Welche Instruments sind am besten? sind ganz regular. Ich battle dort und bin hier, um zu helfen. In diesem Leitfaden werde ich Sie durch zwei anfängerfreundliche Projekte führen-eine in Python und eine in SQL. Bereit? Lass uns eintauchen!
Warum Datenprojekte für Lernende unerlässlich sind
Wenn Sie Python-, SQL- oder Datenvisualisierung lernen, sind Projekte, an denen die Magie stattfindet. Ich sage immer, Projekte sollten 70% Ihrer Lernzeit ausmachenAnwesend mit nur 30% für neue Konzepte. Hier ist der Grund:
- Wenden Sie an, was Sie wissen: Projekte verbinden die Punkte zwischen isolierten Fähigkeiten. Denken Sie an Schleifen, Funktionen und Dateibehandlungen – alle zusammenarbeiten.
- Vertrauen aufbauen: Das Abschluss eines Projekts beweist Ihre Fähigkeiten, was für Vorstellungsgespräche hervorragend ist.
- Erstellen Sie ein Portfolio: Projekte zeigen potenzielle Arbeitgeber Ihre Fähigkeiten zur Problemlösung in Aktion.
Als ich Karrieren überging, gab mir die Arbeit an Datenprojekten konkrete Beispiele, die ich in Vorstellungsgesprächen besprechen konnte, noch bevor ich eine formelle Berufserfahrung hatte.
Python Venture Walkthrough: App Retailer -Datenanalyse
Projektübersicht
In diesem Projekt geht es nur um Analyse von App Retailer -Daten Traits für worthwhile Apps erkennen. Wir werden das Python- und Jupyter -Notizbuch verwenden – perfekte Instruments für Anfänger.
Schritt 1: Beginnen Sie mit Jupyter Pocket book
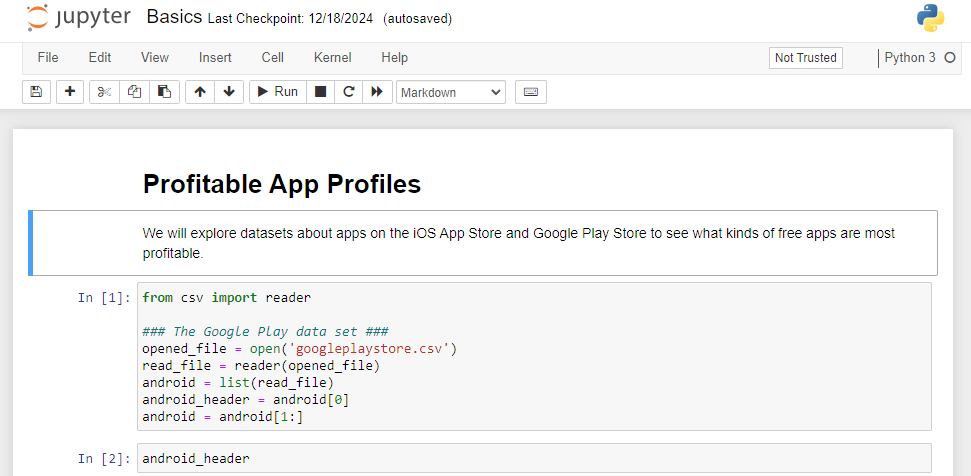
Wenn Sie neu im Jupyter -Notizbuch sind, scheint es einschüchternd zu sein. Folgendes müssen Sie wissen:
- Code vs. Markdown -Zellen: Codezellen führen Python aus, während Markdown -Zellen Ihnen helfen, Ihren Prozess zu dokumentieren.
- Ausführungsreihenfolge: Verfolgen Sie die Codemellnummern in Klammern (dh
In (1)) Um zu vermeiden, dass Code aus der Sequenz ausgeführt wird. - Starten von Kerneln: Wenn die Dinge schief gehen, starten Sie den Kernel neu und machen Sie Ihre Zellen für einen Neuanfang erneut aus.
Um diesen Prozess noch einfacher zu machen, können Sie dies folgen Schritt-für-Schritt-Anleitung zur Set up von Jupyter Pocket book lokal und Erstellen Sie Ihr erstes Projekt. Wenn Sie Anfänger sind, empfehlen wir Ihnen, unserem Break up-Display-Interaktiv zu folgen Lernen und installieren Sie Jupyter Pocket book Projekt, um die Grundlagen schnell zu lernen.
Schritt 2: Daten importieren und erkunden
Laden wir unseren Datensatz mit Python’s csv Modul:
from csv import reader
# Google Play dataset
opened_file = open('googleplaystore.csv')
read_file = reader(opened_file)
android = checklist(read_file)
android_header = android(0)
android = android(1:)Professional -Tipp: Fügen Sie Code -Kommentare hinzu, um Ihren Workflow zu dokumentieren, damit Ihr zukünftiges Selbst nicht vergisst, was eine bestimmte Codezeile tut.
Schritt 3: Fehlerbehebung bei üblichen Fehlern
Fehler sind Teil des Prozesses – scheuen Sie sich nicht vor ihnen! Ein häufiges ist ein Dateipfadfehler. Wenn Sie so etwas in der Ausgabe der Codezelle sehen:
FileNotFoundError: (Errno 2) No such file or listing: 'googleplay_store.csv'Es bedeutet, dass Python Ihre Datei nicht finden kann. Überprüfen Sie den Dateinamen und den Verzeichnis. Vergessen Sie nicht, Sie können sich immer an die wenden Dataquest -Group oder unser Chandra AI -Tutor um Hilfe.
Schritt 4: Bereiten Sie sich auf eine tiefere Analyse vor
Sie haben jetzt eine solide Grundlage mit Jupyter Pocket book – das Verständnis, wie Sie Ihren Code organisieren, Datensätze erkunden und häufig auftretende Probleme beheben. Zu diesem Zeitpunkt sind Sie intestine positioniert, um die Datenreinigung, -analyse und -visualisierung einzugehen.
Von hier aus können Sie sich auf die Datenreinigung konzentrieren, um die Genauigkeit zu gewährleisten, indem Sie Duplikate oder falsche Einträge beseitigen, sich zur Datenerforschung wenden, indem Sie zusammenfassende Statistiken in Bezug matplotlib oder seaborn Klare, überzeugende Diagramme zu erstellen.
SQL Venture Walkthrough: Erforschung einer relationalen Datenbank
Projektübersicht
Für SQL -Liebhaber werde ich Sie durchführen ein Projekt mit SQLite Erkundung einer Datenbank mit Kunden, Mitarbeitern und Produkten.
Schritt 1: SQLite einrichten
SQLite ist leicht und anfängerfreundlich. Laden Sie nach der Set up Ihre Datenbank- und Vorschau -Tabellenschemata, um die Struktur zu verstehen.
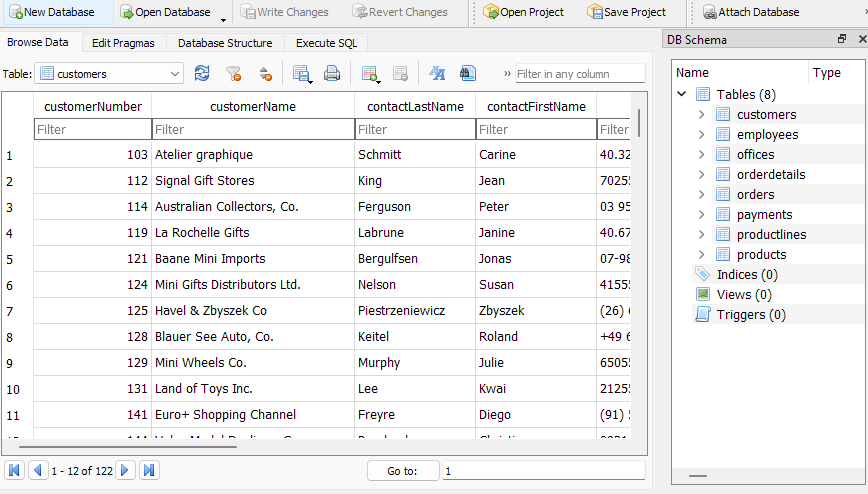
Schritt 2: Abfragen schreiben
Beginnen Sie einfach, indem Sie die Tische erkunden:
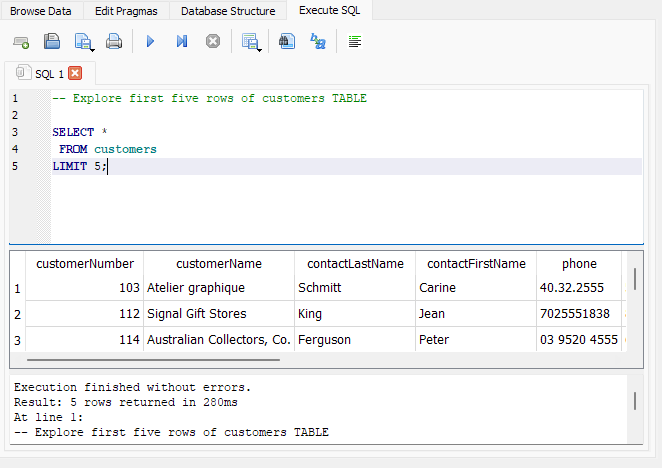
Diese Abfrage zeigt:
- So dokumentieren Sie Abfragen Kommentare in SQLite mit
-- - Wählen Sie alle aus (
*) Spalten - Von der
clientsTisch - Begrenzen Sie die angezeigte Ausgabe auf die ersten 5 Zeilen
Wenn Sie einfache Abfragen wie diese ausführen, können Sie sich an die SQLite -Schnittstelle gewöhnen, insbesondere wenn Sie hauptsächlich mit dem Ausführen von SQL -Abfragen innerhalb einer On-line -Plattform vertraut sind.
Schritt 3: Fortgeschrittene Abfragen und Herausforderungen
Fassen wir alle Tabellen in einer Abfrage mithilfe der Fassungsgruppe zusammen UNION ALL. Es ist eine leistungsstarke Möglichkeit, Ergebnisse über Tabellen hinweg zu kombinieren. Hier sehen wir die Abfrage und die Ausgabe für die ersten beiden Tabellen in der Datenbank (clients Und workers):
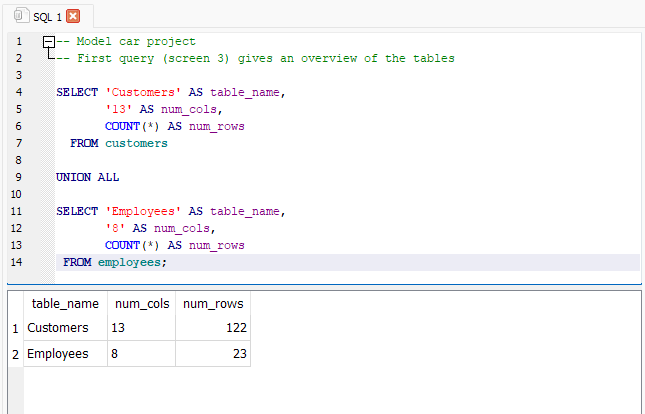
Beachten Sie, dass wir die verwendet haben, um Informationen aus mehreren Tabellen zu kombinieren UNION ALL Bediener und stellten sicher, dass unsere Spaltennamen über mehrere Tabellen konsistent waren (table_nameAnwesend num_cols,Und num_rows)
Schritt 4: Bereiten Sie sich auf eine tiefere Analyse vor
Sie haben jetzt eine solide Grundlage mit SQLite – das Verständnis der Set up, Erkundung von Tabellenschemata, führen Sie grundlegende Abfragen aus und verwenden Sie sogar Operatoren wie Operatoren UNION ALL Daten über Tabellen hinweg kombinieren. Zu diesem Zeitpunkt sind Sie intestine vorbereitet, um komplexere Analysen und Datenbankoperationen zu bekämpfen.
Von hier aus können Sie auf Ihren SQL -Fähigkeiten aufbauen, indem Sie ausgefeiltere Abfragen erstellen, z. B. die Verwendung von Verknüpfungen oder Unterabfragen, die Optimierung der Leistung mit Indizes und sogar die Integration Ihrer SQLite -Datenbank in größere Anwendungen oder Visualisierungstools, um tiefere Geschäftserkenntnisse abzuleiten.
Herausforderungen überwinden: Fehlerbehebung und Debuggen
- Für Python: Verwenden Sie Fehlermeldungen als Anleitungen. Instruments wie Chandra AI Tutor oder On-line -Communities können Probleme klären.
---------------------------------------------------------------------------
FileNotFoundError Traceback (most up-to-date name final)
<ipython-input-1-2ed9ff83dc25> in <module>
2
3 ### The Google Play information set ###
----> 4 opened_file = open('googleplay_store.csv')
5 read_file = reader(opened_file)
6 android = checklist(read_file)
FileNotFoundError: (Errno 2) No such file or listing: 'googleplay_store.csv'- Dieser Fehler gibt an, dass die Datei nicht vorhanden ist (beachten Sie den Pfeil “ ->“, der auf die Zeile zeigt, in der der Fehler aufgetreten ist). Dies ist ein großer Hinweis darauf, dass etwas über den Dateinamen nicht wie erwartet funktioniert.
- Für SQL: Häufige Fehler wie nicht übereinstimmende Spaltennamen oder ungültige Syntax können durch Bezugnahme auf Datenbankschemas oder das Testen kleinerer Abfragekomponenten aufgelöst werden.
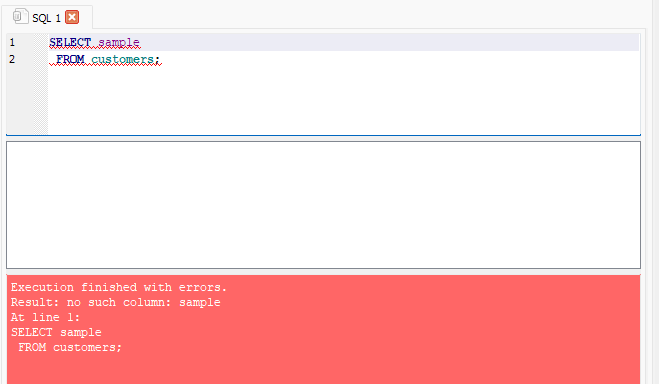
- Dieser Fehler gibt einen Fehler in an
line 1und gibt an, dass der Fehler auftritt, weil die aufgelistete Spalte nicht vorhanden ist.
Veröffentlichen Sie Ihr erstes Projekt
Sobald Ihr Projekt abgeschlossen ist, lassen Sie es nicht Staub sammeln. Teilt es! Das Veröffentlichen Ihrer Arbeit schafft Vertrauen und öffnet die Tür für Suggestions.
Empfohlene Werkzeuge
-
Github Gist: Perfekt für Anfänger. Sie können Python -Notizbücher oder SQL -Abfragen teilen, ohne sich über komplexe Repository -Strukturen zu sorgen.
-
Github -Repositories: Mit Repositories können Sie für fortgeschrittenere Benutzer Multi-File-Projekte organisieren und mit anderen zusammenarbeiten.
Nach der Veröffentlichung können andere Kommentare oder Vorschläge hinterlassen – eine großartige Möglichkeit, Ihre Fähigkeiten zu verfeinern.
Iterieren mit Suggestions
Suggestions ist Gold. Teilen Sie Ihre Arbeit in der Dataquest -Groupwo Lernende und Moderatoren konstruktive Ratschläge geben können. Ein Lerner verbesserte sein Star Wars -Projekt dramatisch, indem er nur ein Inhaltsverzeichnis und die auf Suggestions raffinierte Visualisierungen hinzufügte.
Nächste Schritte: Erstellen Sie Ihr erstes Datenprojekt
Bist du bereit, dein eigenes Projekt zu starten? So wie: wie:
- Wählen Sie ein geführtes Projekt: Beginnen Sie klein mit anfänglichen Projekten, die in der Datenquest-Bibliothek verfügbar sind.
- Üben Sie auf DataQuest oder lokal: Verwenden Sie Instruments wie Jupyter Pocket book, Jupyter Lab, Google Colab oder SQLite, um Vertrauen zu schaffen.
- Dokumentieren Sie Ihren Prozess: Fügen Sie Markdown -Zellen oder SQL -Kommentare ein, um Ihren Ansatz zu erklären.
- Veröffentlichen und teilen: Laden Sie Ihr Projekt in GitHub hoch oder teilen Sie es in der Dataquest -Group für Suggestions.
Das Erstellen Ihres ersten Datenprojekts ist ein Meilenstein. Es steigert Ihre Fähigkeiten, Ihr Vertrauen und Ihre Karriereaussichten. Denken Sie daran, dass jedes Projekt, das Sie abschließen, Ihr Selbstvertrauen baut und neue Türen für Lernen und Wachstum eröffnet. Additionally, wähle a Führungsprojekt Heute, und lass uns anfangen!