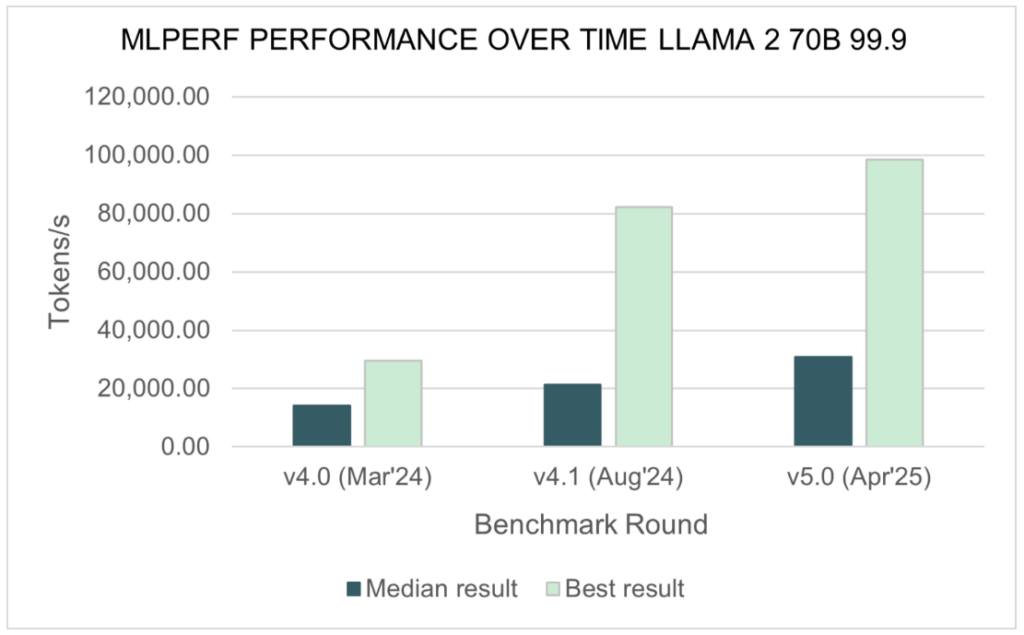
Quelle: Mlcommons
„Es ist jetzt klar, dass sich ein Großteil des Ökosystems genau auf die Bereitstellung generativer KI konzentriert und dass die Leistungsbenchmarking -Suggestions -Loop funktioniert“, sagte David Kanter, Leiter von MLPerf bei MLCommons. „Wir sehen eine beispiellose Flut neuer Generationen von Beschleunigern. Die {Hardware} ist mit neuen Softwaretechniken gepaart, einschließlich der ausgerichteten Unterstützung über {Hardware} und Software program für das FP4 -Datenformat. Mit diesen Fortschritten setzt die Neighborhood neue Datensätze für generative AI -Inferenzleistung.“
Die Benchmark-Ergebnisse für diese Runde umfassen Ergebnisse für sechs neu verfügbare oder bald angehende Prozessoren:
- AMD Intuition Mi325x
- Intel Xeon 6980p „Granite Rapids“
- Google TPU Trillium (TPU V6E)
- Nvidia B200
- Nvidia Jetson Agx Thor 128
- Nvidia GB200
Im Schritt mit Fortschritten in der AI -Neighborhood führt MLPerf Inference V5.0 einen neuen Benchmark ein, der das Lama 3.1 405b -Modell verwendet, das eine neue Bar für die Skala eines generativen AI -Inferenzmodells in einem Leistungsbenchmark markiert. LLAMA 3.1 405B enthält 405 Milliarden Parameter in sein Modell und unterstützt die Eingangs- und Ausgangslängen von bis zu 128.000 Token (im Vergleich zu nur 4.096 Token für LAMA 2 70B). Der Benchmark testet drei separate Aufgaben: Allgemeine Fragen zur Beantwortung, Mathematik und Codegenerierung.
„Dies ist unser ehrgeiziges Inferenz-Benchmark-To-Datum“, sagte Miro Hodak, Co-Vorsitzender der MLPerf-Inferenzarbeitsgruppe. „Es spiegelt den Branchentrend zu größeren Modellen wider, die die Genauigkeit erhöhen und einen breiteren Satz von Aufgaben unterstützen können. Es ist ein schwierigerer und zeitaufwändigerer Check, aber Unternehmen versuchen, reale Modelle dieser Größenordnung einzusetzen. Vertrauenswürdige, relevante Benchmarkergebnisse sind entscheidend, um ihnen zu helfen, bessere Entscheidungen zu treffen, um die besten Möglichkeiten zu erzielen.“
Die Inferenz V5.0 Suite verleiht dem vorhandenen Benchmark für Lama 2 70b auch einen neuen Check mit einem zusätzlichen Check, der Anforderungen an niedrige Latenz erhöht: LAMA 2 70B Interactive. Der Benchmark reflektiert die Branchentrends in Bezug auf interaktive Chatbots sowie Argumentation und Agentensysteme der nächsten Technology und erfordert, dass Systeme (SUTs), die anspruchsvollere Systemreaktionskennzahlen für Zeit bis zum ersten Token (TTFT) und Zeit professional Ausgabe-Token (TPOT) erfüllen.
„Ein kritisches Maß für die Leistung eines Abfragesystems oder eines Chatbots ist, ob es sich anfühlt, dass es sich an eine Particular person reagiert, die damit interagiert. Wie schnell antwortet es auf eine Eingabeaufforderung, und in welchem Tempo liefert es seine gesamte Antwort?“ sagte Mitchelle Rasquinha, MLPerf Inference Working Group Co-Vorsitzende. „Durch die Durchsetzung strengerer Anforderungen an die Reaktionsfähigkeit bietet diese interaktive Model des LLAMA 2 70B-Checks neue Einblicke in die Leistung von LLMs in realen Szenarien.“
Weitere Informationen zur Auswahl des Lama 3.1 405b und der neuen Lama 2 70b Interactive Benchmarks finden Sie in diesem ergänzenden Weblog.
Ebenfalls neu in Inferenz V5.0 ist ein Rechenzentrum -Benchmark, der ein GRAF -Modell für das Grafik Neural Community (GNN) implementiert. GNNs sind nützlich für die Modellierung von Hyperlinks und Beziehungen zwischen Knoten in einem Netzwerk und werden häufig in Empfehlungssystemen, Beantwortung von Wissensgraph, Betrugserkennung und anderen Arten von graphbasierten Anwendungen verwendet.
Das GNN Datacenter Benchmark implementiert das RGAT -Modell basierend auf dem Illinois Graph Benchmark Heterogen (IGBH) Datensatz mit 547.306.935 Knoten und 5.812.005.639 Kanten.
Weitere Informationen zum Bau des RGAT -Benchmarks finden Sie Hier.
Der Inferenz V5.0 Benchmark führt einen neuen Benchmark für Kfz -Pointpainting für Edge -Computing -Geräte, insbesondere Car, ein. Während die MLPerf Automotive Working Group zuerst den minimal lebensfähigen Produktbenchmark entwickelt angekündigt Im vergangenen Sommer bietet dieser Check einen Proxy für ein wichtiges Szenario mit Kantenkomputierungen: 3D-Objekterkennung in Kamera-Feeds für Anwendungen wie selbstfahrende Autos.
Weitere Informationen zum Automobil -Pointpainting -Benchmark finden Sie Hier.
„Wir stellen selten vier neue Checks in einem einzigen Replace in die Benchmark-Suite ein“, sagte Miro Hodak, „aber wir waren der Meinung, dass es notwendig struggle, der Neighborhood am besten zu dienen. Das schnelle Tempo des Fortschritts im maschinellen Lernen und die Breite der neuen Anwendungen sind sowohl erstaunlich als auch die Stakeholder benötigen relevante und aktuelle Daten, um ihre Entscheidung zu informieren.“
MLPerf Inference v5.0 contains 17,457 efficiency outcomes from 23 submitting organizations: AMD, ASUSTeK, Broadcom, Cisco, CoreWeave, CTuning, Dell, FlexAI, Fujitsu, GATEOverflow, Giga Computing, Google, HPE, Intel, Krai, Lambda, Lenovo, MangoBoost, NVIDIA, Oracle, Quanta Cloud Know-how, Supermicro, and Nachhaltige Metallwolke.
„Wir möchten die fünf Erstanlagen in der Inferenz-Benchmark: CoreWeave, Flexai, Gateoverflow, Lambda und Mangoboost begrüßen“, sagte David Kanter. „Das anhaltende Wachstum der Neighborhood of Subherers ist ein Beweis für die Bedeutung der genauen und vertrauenswürdigen Leistungsmetriken für die KI-Neighborhood. Ich möchte auch Fujitsus breites Satz von Rechenzentrumsleisten-Benchmark-Einsendungen hervorheben, und GateOverflows Edge-Leistungsunterlagen.
„Das Ökosystem für maschinelles Lernen bietet der Neighborhood weiterhin immer größere Fähigkeiten. Wir erhöhen das Ausmaß der ausgebildeten und eingesetztes KI -Modelle, erreichen neue Maßstäbe der interaktiven Reaktionsfähigkeit und sorgen für den Einsatz von KI -Berechnen als je zuvor“, sagte Kanter. „Wir freuen uns, dass neue Generationen von {Hardware} und Software program diese Funktionen liefern und Mlcommons ist stolz darauf, aufregende Ergebnisse für eine breite Palette von Systemen und mehreren neuartigen Prozessoren mit dieser Veröffentlichung des MLPERF -Inferenz -Benchmarks zu präsentieren. Unsere Arbeit, um die Benchmark Suite aktuell, umfassend und related in einer Zeit des schnellen Wandels zu halten, ist eine echte Leistung und stellt sicher, dass wir den Interessengruppen weiterhin wertvolle Leistungsdaten liefern werden.
MlCommons ist der weltweit führende Anführer für KI -Benchmarking. Ein offenes Engineering -Konsortium, das von über 125 Mitgliedern und verbundenen Unternehmen unterstützt wird, hat Mlcommons nachweislich nachweislich die Zusammenarbeit mit Wissenschaft, Industrie und Zivilgesellschaft, um die KI zu messen und zu verbessern. Die Stiftung für MLCommons begann 2018 mit den MLPERF -Benchmarks, die schnell als eine Reihe von Branchenmetriken skaliert wurden, um die Leistung des maschinellen Lernens zu messen und die Transparenz von Techniken des maschinellen Lernens zu fördern. Seitdem hat MLCommons das Kollektivtechnik weiter verwendet, um die Benchmarks und Metriken zu erstellen, die für eine bessere KI erforderlich sind, was letztendlich dazu beiträgt, die Genauigkeit, Sicherheit, Geschwindigkeit und Effizienz der KI -Technologien zu bewerten und zu verbessern.