tl;dr. Die Leute machen sich über die Wahlprognose von Fivethirtyeight lustig, weil die Wahrscheinlichkeit 50/50 beträgt, aber das ist ungefähr die Prognose, die man abgeben sollte, wenn man nicht weiß, was passieren könnte.
Letzte Woche ich hat etwas gepostet„Die Wahl steht vor der Tür: Welchen Prognosen können wir vertrauen?“, Diskussion über die Anreize verschiedener Wahlprognostiker.
Politische Akteure und Journalisten haben schon lange Wahlprognosen erstellt. Der Wettanbieter und Fernsehstar Jimmy the Greek hat in seiner unterhaltsamen Autobiografie von 1975 einige gute Geschichten über Wahlprognosen erzählt. 1983 veröffentlichte der Politikwissenschaftler Steven Rosenstone ein hervorragendes Buch über die Prognose von Präsidentschaftswahlen; dies erschien etwa zur selben Zeit wie die Arbeiten von Douglas Hibbs, James Campbell und anderen. Gary King und ich nutzten diese Arbeit, als wir ein hierarchisches Modell zur Prognose der Wahlen von 1992 für unsere PapierWarum sind die Umfragen im amerikanischen Präsidentschaftswahlkampf so unterschiedlich, wenn die Stimmen doch so vorhersehbar sind?
Diese Vorhersagen basierten auf wirtschaftlichen und politischen Traits – was wir oft vage als „Fundamentaldaten“ bezeichnen – sowie auf einigen Modellen der Korrelation von Unsicherheit zwischen den Staaten. Ein Downside bei dieser Artwork von Prognosen ist, dass man manchmal Probleme schon vor der Wahl erkennen kann. Wir haben ein solches Beispiel in Kapitel 6 von Bayesian Information Evaluation besprochen: Unser Modell von 1992 gab Invoice Clinton eine unglaubwürdig hohe Probability, Texas und einige andere Südstaaten zu gewinnen. Wir konnten das auf einen Begriff in unserem Modell zurückführen, der Kandidaten aus dem Süden einen Heimatvorteil verschaffte, was in dem neu polarisierten politischen Umfeld, das mit Clintons Wahlkampf begann, nicht so intestine funktionierte. Der allgemeine Punkt hier ist, dass wir wussten, was in die Prognose einfloss. In die Worte von Ökonom Rajiv Sethi: „Statistische Modelle funktionieren nur dann intestine, wenn die Vergangenheit ein einigermaßen guter Indikator für die Zukunft ist. Modelle werden auf der Grundlage historischer Daten erstellt und kalibriert, unter der Annahme, dass sich der Datengenerierungsprozess nicht dramatisch verändert hat. Sie geraten in echte Schwierigkeiten, wenn wir uns auf unbekanntes Terrain begeben.“
Die Präsidentschaftswahlen von 1984, 1988, 1992 und 1996 waren nicht besonders knapp, und Wahlprognosen waren eher eine akademische als eine journalistische Angelegenheit. Nach der sehr knappen Wahl von 2000 (nur 30.000 mehr Floridianer haben für Gore als für Bush gestimmt und natürlich conflict das Ergebnis bei der Stimmenauszählung sogar noch knapper), wurden Wahlprognosen zu einem viel allgemeineren Thema und dieses Interesse hat sich seither auch bei den vielen knappen Wahlen fortgesetzt.
Außerdem ist es ziemlich klar, dass es sinnvoller ist, einen Blick auf die Umfragen zu werfen, wenn man ein Gefühl dafür bekommen möchte, wer die kommende Wahl im Einzelnen gewinnen wird, als die Faktoren zu verstehen, die den Wahlausgang bestimmen können.
Im ersten Jahrzehnt der 2000er Jahre erstellten Actual Clear Politics und einige andere Medienorganisationen Durchschnittsumfragestatistiken, dann stellte Nate Silver 2008 auf fivethirtyeight.com einen Umfragedurchschnitt für alle Staaten zusammen, und verschiedene andere Organisationen taten dasselbe.
Und wenn Sie erst einmal mit der Aggregation von Umfragen begonnen haben, stehen Sie vor Herausforderungen: Welche Umfragen sollen einbezogen werden, wie schnell soll der Durchschnitt geändert werden, wenn neue Umfragen erscheinen, wie sollen Meinungsverschiedenheiten zwischen Umfragen auf Bundesstaats- und Bundesebene beigelegt werden, wie sollen erwartete Artefakte wie der Parteitag-Bounce berücksichtigt werden, wie sollen Umfragen verschiedener Organisationen kombiniert werden, die unterschiedliche Erhebungsmethodenwie man berücksichtigt Nichtstichprobenfehler . . . all dies führt uns weg von einfachen Gewichten und gleitenden Durchschnitten hin zur Wahrscheinlichkeitsmodellierung von Unsicherheit. Anfang der 2010er Jahre gab es einige akademische Arbeiten zu diesem Thema von Drew Linzer und von Kari Lock und ich, und es kann noch viel mehr getan werden.
Dieses Jahr veröffentlichen die Web site Fivethirtyeight (jetzt Teil von ABC Information) und das Magazin The Economist Wahlprognosen, die Informationen aus Umfragen auf Bundesstaats- und Bundesebene, früheren Wahlmustern und allem, was die Prognostiker sonst noch einfließen lassen wollen, kombinieren. Ich conflict an der Erstellung dieser beiden Modelle beteiligt, aber sie unterscheiden sich in vielen Particulars, werden von unterschiedlichen Leuten betrieben und liefern unterschiedliche Ergebnisse.
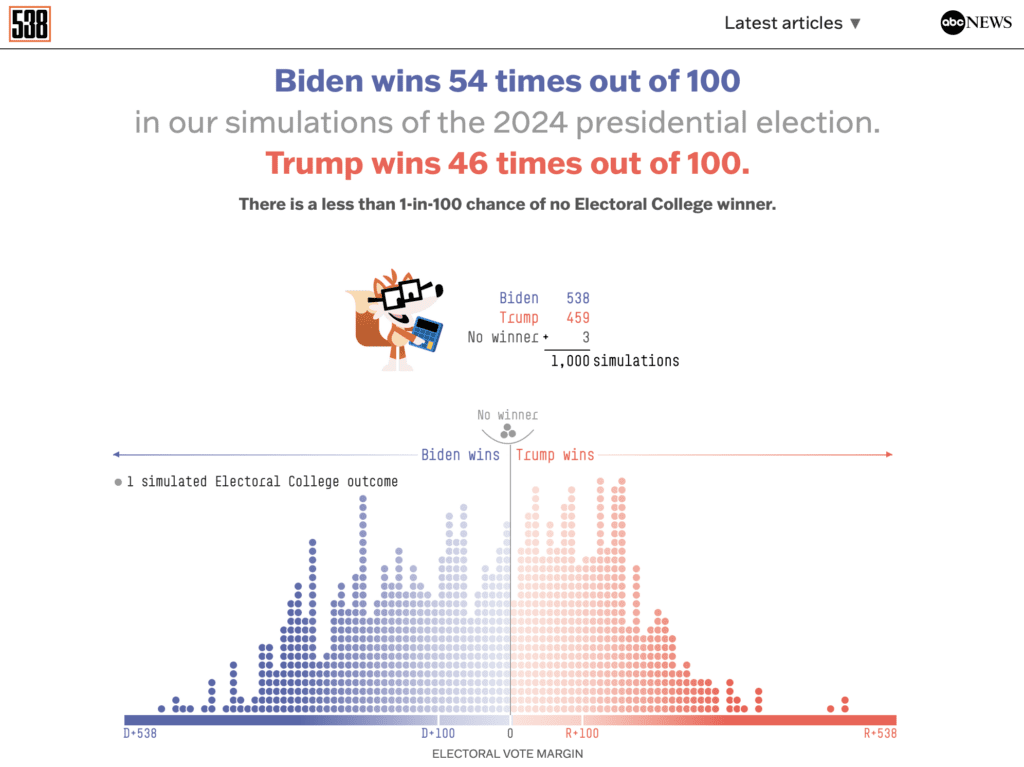
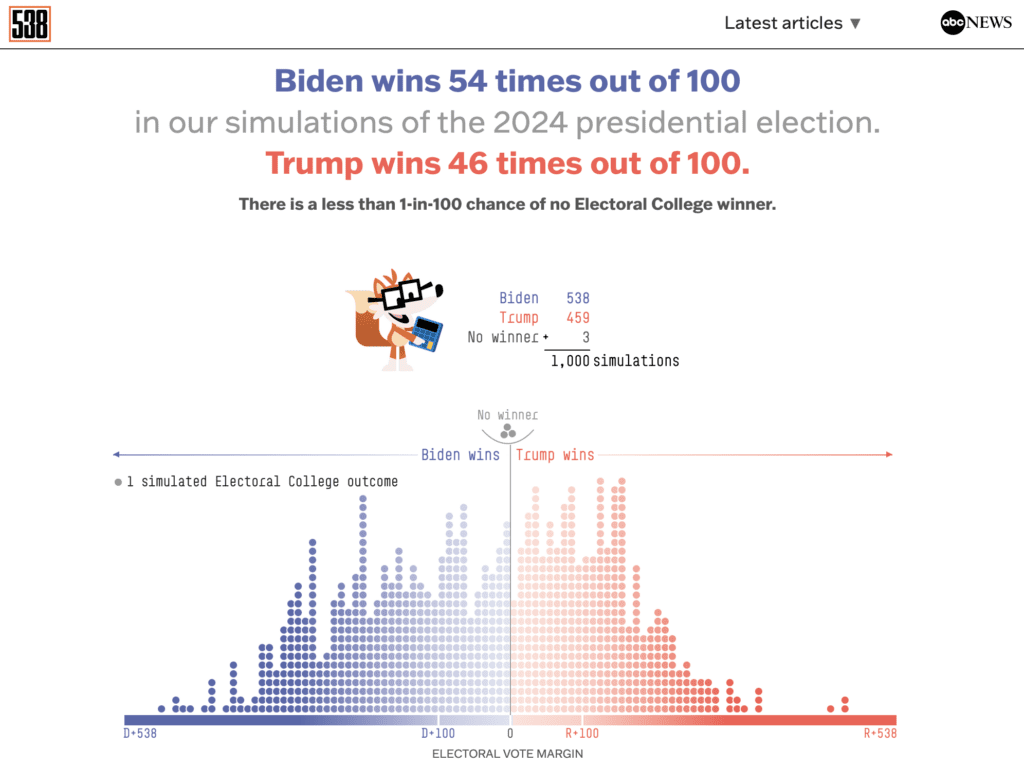
Hier ist Fivethirtyeight:
Und hier ist der Economist:

Sie sind sich nicht einig! Der eine sagt, die Chancen seien ausgeglichen, der andere gibt den Republikanern eine 3/4-Probability zu gewinnen. Beide Umfragen basieren auf denselben Informationen, aber sie nutzen diese Informationen auf unterschiedliche Weise.
Warum unterscheiden sie sich? Wenn Sie das Slate-Magazin lesen, werden Sie diese irreführende Schlagzeile sehen:

(nein, eine 54percentige Gewinnchance sollte nicht als „Biden wird gewinnen“ zusammengefasst werden), was Sie zu Das Nachrichtenartikel mit dem Untertitel „FiveThirtyEights Lifeless-Warmth-Prognose wird sich in etwa zwei Monaten selbst zerstören“, was ebenfalls irreführend ist, denn der ganze Sinn der Prognose besteht darin, dass wir nicht wissen, was in zwei Monaten passieren wird. Das ist der ganze Sinn einer 50:50-Prognose; sie drückt Unwissenheit aus!
Damit will ich nicht sagen, dass ich die Prognose von Fivethirtyeight für richtig halte. Die Prognose, mit der ich in jüngster Zeit gearbeitet habe, ist die des Economist, die Biden, wie oben erwähnt, nur eine Siegchance von 1/4 einräumt.
Die Umfragen selbst begünstigen derzeit die Republikaner. Hier ist die Zusammenfassung der Fivethirtyeight-Umfrage:

Und hier ist die Stellungnahme des Economist:

0,427/(0,427+0,401) = 0,516 und 0,463/(0,463+0,439) = 0,513, additionally ja, die Umfragedurchschnitte sind im Wesentlichen gleich. Es ist ein knapper Vorsprung der Republikaner, aber auf Grundlage der Ergebnisse früherer Wahlen in den einzelnen Bundesstaaten wird davon ausgegangen, dass die Demokraten etwas mehr als die Hälfte der nationalen Stimmen benötigen, um eine faire Probability auf den Sieg im Wahlkollegium zu haben, weshalb dies als solider Vorsprung für Trump gilt.
Warum gibt Fivethirtyeight den Demokraten eine 50:50-Probability, obwohl sie in den Umfragen zurückliegen und auf der falschen Seite der Wahlmännerkarte stehen? In dem Slate-Artikel heißt es: „Biden ist ein Amtsinhaber, der eine wachsende Wirtschaft überwacht, was bedeuten sollte, dass er problemlos zur Wiederwahl segeln würde. Aber das tut er nicht. Und andere (Wahlprognostiker) scheinen den Fundamentaldaten weniger Gewicht beizumessen, was bedeutet, dass sie den Umfragen, in denen Biden (eindeutig) verliert, mehr Bedeutung beimessen.“
Diese Beschreibung ist für das, was sie ist, in Ordnung. Ich denke, es kann uns auch nützen, das Downside aus der Perspektive der statistischen Modellierung zu betrachten.
Die Schlüsselfrage ist, wie man drei Dinge miteinander verbindet:
A. Der aktuelle Stand der Umfragen,
B. Der Stand der Umfragen kurz vor der Wahl,
C. Das Wahlergebnis.
Wenn Sie die Umfrageaggregation einfach als Prognose nehmen, gehen Sie implizit davon aus, dass A = B = C. Aber wir wissen, dass dies nicht der Fall ist. A ist nicht dasselbe wie B (Umfragen können sich während des Wahlkampfs ändern) und B ist nicht dasselbe wie C (Umfragen können falsch sein, sogar kurz vor der Wahl). Um A!=B und B!=C zu berücksichtigen, müssen Sie Ihre Prognose erweitern (und sie auch verschieben, wenn Sie eine Ahnung haben, wohin die Dinge gehen).
Schauen Sie sich jetzt noch einmal die oben genannten Prognosen von Fivethirtyeight und Economist an. Vergessen Sie die Wahrscheinlichkeiten und sehen Sie sich die breite Streuung der möglichen Ergebnisse im Wahlkollegium an. Es gibt eine Menge Unsicherheit!
Schon 2016 kritisierten manche Leute Fivethirtyeight für seine zu vorsichtige Prognose. Die Zeitung gab Clinton nur eine Siegchance von zwei Dritteln, obwohl sie in den Umfragen konstant vorne lag.—siehe hier für eine im Nachhinein peinliche Kritik an Fivethirtyeight am Vorabend der Wahl. Der Kritiker hat nicht verstanden, dass die Umfragen falsch sein könnten!
Um auf die Prognosen für 2024 zurückzukommen: In dem Slate-Artikel heißt es weiter: „Das Modell von FiveThirtyEight wird Biden gegenüber immer ungünstiger, je näher der Wahltag rückt, und es gewichtet Fundamentaldaten nach und nach immer weniger.“ Aber das ist nicht richtig! Wenn Wenn die Umfragen auf ihrem Stand bleiben, während der Wahltag näher rückt, wird die Prognose für Biden tatsächlich ungünstiger. Aber denken Sie daran: A!=B. Die Umfragen können sich bis dahin noch ändern.
Wie stark könnten sich die Umfragen ändern? Wie lässt sich dies modellieren?
Es hängt davon ab, was man als Vergleichsmaßstab verwendet. Die jüngsten Präsidentschaftswahlen verliefen in der öffentlichen Meinung sehr stabil, und umso mehr nach Berücksichtigung der unterschiedlichen Nichtbeantwortung. Aber ein paar Jahrzehnte zurück ist die Geschichte eine andere. Jimmy Carter lag 1976 in den Umfragen 30 Punkte vorn und konnte Gerald Ford am Wahltag nur knapp schlagen. 1988 lag Mike Dukakis deutlich vor George HW Bush, verlor aber am Ende deutlich.
Anders ausgedrückt: Versetzen Sie sich in die Zeit zurück, als Dukakis in Umfragen 52 % der Stimmen beider Parteien erhielt. Hätten Sie ihm eine Gewinnchance von 75 % zugestehen wollen? Ich glaube nicht. Wenn wir beim Economist Trump additionally eine Gewinnchance von 75 % zugestehen, ist dies zu einem großen Teil die implizite Annahme, dass die Umfragen jetzt nicht mehr so stark schwanken werden wie 1988.
Fivethirtyeight misst den Umfragen relativ wenig Gewicht bei. Anders ausgedrückt: Sie messen zukünftigen Umfrageschwankungen eine hohe Unsicherheit bei. Sie gehen davon aus, dass die Umfragen in diesem Jahr so ausfallen könnten wie 1988.
Ist das eine vernünftige Annahme? Ich weiß es nicht. Wir leben heute in einer politisch viel stärker polarisierten Ära als 1976 oder 1988, daher ist der Spielraum für Meinungsumfragen wohl viel geringer. Andererseits spricht einiges dafür, bei einer Prognose die Möglichkeit unerwarteter Ereignisse einzubeziehen. Indem die Prognose von Fivethirtyeight potenziellen Meinungsumfragen eine hohe Varianz zuschreibt, hält sie die Wahrscheinlichkeit näher bei 50/50, was als sichere Wahl gelten könnte.
Der Slate-Artikel zitiert den Politikwissenschaftler David Broockman mit den Worten: „Historisch gesehen sind die frühen Umfragen nicht besonders aussagekräftig. Aber das liegt daran, dass die Leute die Kandidaten noch nicht kennen. Es ist schwer vorstellbar, dass die Leute nicht wissen, was sie von diesen beiden halten!“ Intestine, und tatsächlich berücksichtigt unsere Economist-Prognose weniger mögliche Umfrageschwankungen zwischen jetzt und der Wahl. Das ist ein grundlegender Kompromiss bei Prognosen: Wir können eine stärkere Aussage treffen (indem wir den Republikanern eine Gewinnchance von 75 % statt 50 % geben), aber auf Kosten der Anfälligkeit für große Umfrageschwankungen.
Jede Annahme, die wir treffen, ist vom Glück abhängig, aber es gibt keine Möglichkeit, Prognosen zu erstellen, ohne Annahmen zu treffen. Und darum geht es in dem obigen Beitrag. Eine einfache Umfrageaggregation in eine Prognose umzuwandeln, ist ein sauberes Verfahren, aber wenn Sie das so interpretieren wollen, dass es etwas über die bevorstehende Wahl aussagt, entspricht das implizit der starken Annahme, dass A=B=C oben ist.
Damit will ich wiederum nicht sagen, dass entweder die Fivethirtyeight-Prognose mit einer Gewinnwahrscheinlichkeit von 50 % oder die Economist-Prognose von 75 % „korrekt“ ist. Sie machen lediglich unterschiedliche Annahmen über mögliche Meinungsumfragen und es stellt sich heraus, dass Fivethirtyeight sich dieses Jahr in einer ähnlichen Lage befindet wie 2016 und den Umfragen im Vergleich zu den Prognosen vieler Experten weniger vertraut.
PS Ich empfehle auch dieser Beitrag (Hyperlink auch oben) von Rajiv Sethi, in dem die Preisschwankungen auf einem Markt zur Wahlprognose erörtert werden.
Im Zusammenhang mit Sethis Argumentation steht, dass jede statistische Prognose zwei verschiedene Dinge tut: Sie ist eine Datenzusammenfassung und eine Prognose eines zukünftigen Ergebnisses. In ihrer Rolle als Datenzusammenfassung soll die Prognose clear sein, damit wir die Beziehung zwischen den eingehenden Daten und den daraus resultierenden Vorhersagen verstehen können. Die Kehrseite davon ist jedoch, dass es immer Informationen geben wird, die nicht im Modell enthalten sind. Dies conflict auch 2016 und 2020 der Fall. Wie soll man über die erste weibliche Kandidatin denken, wie soll man über Drittparteien denken, wie soll man über eine große Zahl von Briefwahlstimmen denken, wie soll man über vergangene Umfragefehler denken, wie soll man über überraschende Ergebnisse bei Sonderwahlen denken, wie soll man über einen Kandidaten denken, der ein verurteilter Schwerverbrecher ist, wie soll man über einen Kandidaten denken, der offensichtlich Schwierigkeiten hat, seiner Arbeit nachzugehen, usw. usw.
Eine verlockende Lösung besteht darin, die datenbasierten Prognosen einfach zu ignorieren und sich auf den Prognosemarkt zu verlassen. Doch das ist eine Artwork Zirkelschluss: Die Prognosemärkte basieren auf der wirtschaftlichen Lage und den neuesten Umfragen. Die neuesten Umfragen sind jedoch ungenau, was eine gewisse Aggregation der Umfragen erforderlich macht. Dies wirft wiederum die Frage auf, wie genau diese Aggregation erfolgen soll, was wiederum die Grundlage für Prognosemodelle bildet – und da sind wir! Es gibt additionally keine einfachen Antworten.