Die künstliche Intelligenz (KI) dominiert die heutigen Schlagzeilen – eines Tages als Durchbruch und wartete als Bedrohung am nächsten. Ein Großteil dieser Debatte findet jedoch in einer Blase statt, die sich eher auf abstrakte Hoffnungen und Ängste als auf konkrete Lösungen konzentriert. In der Zwischenzeit ist eine dringende Herausforderung, die oft übersehen wird, der Aufstieg der psychischen Gesundheitsprobleme in On-line -Gemeinschaften, in denen voreingenommener oder feindlicher Austausch das Vertrauen und die psychische Sicherheit untergraben.
In diesem Artikel wird eine praktische Anwendung von KI eingeführt, die auf dieses Drawback abzielt: eine Pipeline für maschinelles Lernen, die zur Erkennung und Minderung der Verzerrungen im benutzergenerierten Inhalt erfasst und gemindert wird. Das System kombiniert Deep-Studying-Modelle für die Klassifizierung mit generativen Großsprachemodellen (LLMs) zum Erstellen von kontextsensitiven Antworten. Ausgebildet für mehr als zwei Millionen Reddit- und Twitter -Kommentare, erreichte es eine hohe Genauigkeit (F1 = 0,99) und erzeugte maßgeschneiderte Moderationsnachrichten über eine virtuelle Moderator -Particular person.
Im Gegensatz zu einem Großteil des Hype um KI zeigt diese Arbeit ein materielles, einsetzbares Software, das das digitale Wohlbefinden unterstützt. Es zeigt, wie KI nicht nur Geschäftseffizienz oder Gewinn, sondern auch die Schaffung von faireren, integrativeren Räumen, in denen sich Menschen on-line verbinden, dienen kann. Im Folgenden skizziere ich die Pipeline, ihre Leistung und ihre breiteren Auswirkungen auf On-line-Communities und digitales Wohlergehen. Für Leser, die an der Untersuchung der Forschungsergebnisse ausführlicher interessiert sind, einschließlich eines Poster-Präsentationsvideos, das die Codebereiche und den Forschungsbericht in voller Länge erläutert, sind Ressourcen auf GitHub verfügbar. (1)
Eine Pipeline für maschinelles Lernen, die generative künstliche Intelligenz einsetzt, um die Verzerrungen in sozialen Netzwerken anzugehen, hat den Wert für das geistige Wohlbefinden der Gesellschaft. Die menschliche Interaktion mit Computern vertraut immer mehr Antworten, die große Sprachmodelle im Argumentationsdialog bieten.
Verfahren
Das System wurde als dreiphasige Pipeline entwickelt: Sammeln, Erkennung und Minderung. Jede Part kombinierte die NLP -Techniken (natürliche Sprachverarbeitung) mit modernen Transformatormodellen, um sowohl die Skala als auch die Subtilität der voreingenommenen Sprache on-line zu erfassen.
Schritt 1. Datenerfassung und -vorbereitung
Ich habe 1 Million Twitter -Beiträge aus dem Sentiment140 -Datensatz (2) und 1 Million Reddit -Kommentaren eines kuratierten Pushshift -Corpus (2007–2014) (3) zusammengestellt. Die Kommentare wurden gereinigt, anonymisiert und engagiert. Die Vorverarbeitung umfasste Tokenisierung, Lemmatisierung, Stopword -Entfernung und Phrase -Matching unter Verwendung von NLTK und Spacy.
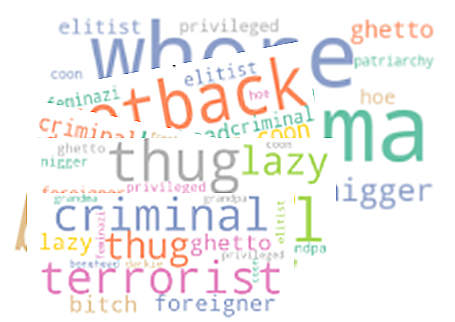
Um die Modelle effektiv zu trainieren, habe ich Metadatenfunktionen wie BIAS_TERMS, HAS_BIAS und BIAS_TYPE konstruiert, die die Schichtung über voreingenommene und neutrale Teilmengen über die Schichtung hinweg ermöglichten. Tabelle 1 fasst diese Merkmale zusammen, während Abbildung 1 die Häufigkeit von Vorspannungsbegriffen über die Datensätze hinweg zeigt.

Das Ansprechen von Datenleckagen und Modellüberfütungsproblemen ist in frühen Datenvorbereitungsstadien wichtig.

Beaufsichtige Lerntechniken werden verwendet, um Vorspannungsbegriffe zu kennzeichnen und sie als implizite oder explizite Formen zu klassifizieren.
Schritt 2. Voreingenommener Annotation und Kennzeichnung
Die Verzerrung wurde an zwei Achsen kommentiert: Vorhandensein (vorgespannter vs. nicht voreingenommen) und Type (implizit, explizit oder keine). Die implizite Verzerrung wurde als subtile oder codierte Sprache (z. B. Stereotypen) definiert, während explizite Verzerrungen offenkundig waren oder Bedrohungen waren. Zum Beispiel wurde „Opa Biden die Treppe hinaufgefallen“ als AGEST codiert, während „Biden ein Opa ist, der seine Familie liebt“, warfare es nicht. Diese kontextbezogene Codierung reduzierte falsch constructive Ergebnisse.
Schritt 3. Stimmung und Klassifizierungsmodelle
Zwei Transformatormodelle haben die Erkennungsstufe betrieben:
-Roberta (4) warfare für die Klassifizierung der Stimmung intestine abgestimmt. Seine Ausgänge (positiv, impartial, negativ) haben dazu beigetragen, den Ton von voreingenommenen Kommentaren zu schließen.
– Distilbert (5) wurde auf dem angereicherten Datensatz mit impliziten/expliziten Etiketten geschult, wodurch eine präzise Klassifizierung subtiler Hinweise ermöglicht wurde.
Mit dem Erkennungsmodell, das mit der höchsten Genauigkeit geschult ist, werden Kommentare durch ein großes Sprachmodell bewertet und eine Antwort erzeugt.
Schritt 4. Minderungsstrategie
Nach der Erkennung der Vorspannung folgte Echtzeit-Minderung. Sobald ein voreingenommener Kommentar identifiziert wurde, erzeugte das System eine Antwort, die auf den Verzerrungstyp zugeschnitten warfare:
– Explizite Voreingenommenheit: direkte, durchsetzungsfähige Korrekturen.
– Implizite Voreingenommenheit: weichere Rephrasierungen oder Bildungsvorschläge.
Die Antworten wurden von ChatGPT (6) generiert und für seine Flexibilität und Kontextempfindlichkeit ausgewählt. Alle Antworten wurden durch eine fiktive Moderator-Particular person, Jenai-Moderator ™, gerahmt, die eine konsistente Stimme und einen konsistenten Ton beibehielt (Abbildung 3).

Schritt 5. Systemarchitektur
Die vollständige Pipeline ist in Abbildung 4 dargestellt. Sie integriert Vorverarbeitung, Verzerrungserkennung und generative Minderung. Daten- und Modellausgaben wurden in einem postgresql-relationalen Schema gespeichert, wobei Protokollierung, Auditing und zukünftige Integration in Systeme in den Schleifen in der Regel ermöglicht wurden.

Ergebnisse
Das System wurde auf einem Datensatz von über zwei Millionen Reddit- und Twitter-Kommentaren bewertet, wobei sich die Genauigkeit, Nuance und reale Anwendbarkeit konzentriert.
Function -Extraktion
Wie in Abbildung 1 gezeigt, schienen Begriffe im Zusammenhang mit Rasse, Geschlecht und Alter in den Benutzern Kommentaren unverhältnismäßig zu sein. Bei der ersten Datenuntersuchung wurden die gesamten Datensätze untersucht, und in den Kommentaren wurde eine Vorspannung von 4 Prozent aufgetaucht. Die Schichtung wurde verwendet, um das Ungleichgewicht der Nicht-Vorurteile von Vorspannungen zu beheben. Vorurteile wie Model und Mobbing schienen selten zu sein, während sich politische Vorurteile so distinguished wie andere voreingenommene Vorurteile auftraten.
Modellleistung
– Roberta erreichte durch die zweite Epoche eine Validierungsgenauigkeit von 98,6%. Seine Verlustkurven (Abbildung 5) konvergierten schnell, wobei eine Verwirrungsmatrix (Abbildung 6) eine starke Klassentrennung zeigte.
– Distilbert, ausgebildet auf impliziten/expliziten Etiketten, erreichte einen 99% igen F1 -Rating (Abbildung 7). Im Gegensatz zur Rohgenauigkeit spiegelt F1 besser das Gleichgewicht von Präzision und Rückruf in unausgeglichenen Datensätzen (7).



Vorspannungstypverteilung
Abbildung 8 zeigt Boxplots von Verzerrungstypen, die über vorhergesagte Stimmungsaufzeichnungen verteilt sind. Die Länge der Field -Diagramme für detrimental Kommentare, in denen etwa 20.000 Datensätze der geschichteten Datenbank, die sehr detrimental und detrimental Kommentare enthielten, kombiniert wurden. Für constructive Kommentare, das heißt, Kommentare, die eine liebevolle oder nicht-Bias-Stimmung widerspiegeln, umfassen die Field-Diagramme etwa 10.000 Aufzeichnungen. Neutrale Kommentare waren in etwa 10.000 Aufzeichnungen. Die Verzerrung und die vorhergesagte Sentiment-Aufschlüsselung bestätigen die klassifizierte Klassifizierungslogik.

Minderungswirksamkeit
Erzeugte Antworten von Jenai-Moderator, die in Abbildung 3 dargestellt wurden, wurden von menschlichen Rezensenten bewertet. Die Antworten wurden sprachlich genau und kontextuell angemessen beurteilt, insbesondere für implizite Verzerrungen. Tabelle 2 enthält Beispiele für Systemvorhersagen mit ursprünglichen Kommentaren, die die Empfindlichkeit gegenüber subtilen Fällen zeigen.

Diskussion
Die Moderation wird häufig als technisches Filterproblem eingerahmt: Erkennen eines verbotenen Wortes, löschen Sie den Kommentar und fahren Sie fort. Moderation ist aber auch eine Interaktion zwischen Benutzern und Systemen. In der HCI -Forschung ist Equity nicht nur technisch, sondern experimentell (8). Dieses System umfasst diese Perspektive und fordert die Minderung als Dialog durch einen personenorientierten Moderator: Jenai-Moderator.
Mäßigung als Interaktion
Eine explizite Verzerrung erfordert häufig eine feste Korrektur, während implizite Verzerrungen von konstruktivem Suggestions profitieren. Durch das Auffrischen und nicht das Löschen fördert das System die Reflexion und das Lernen (9).
Equity, Ton und Design
Ton ist wichtig. Übermäßig harte Korrekturen riskieren Risiko, Benutzer zu entfremden; Übermäßig höfliche Warnungen riskieren, ignoriert zu werden. Dieses System variiert den Ton: Durchsetzungsfähig für explizite Verzerrungen, Bildung für implizite Verzerrungen (Abbildung 4, Tabelle 2). Dies entspricht der Forschung, die Equity zeigt, abhängig vom Kontext (10).
Skalierbarkeit und Integration
Das modulare Design unterstützt die API-basierte Integration mit Plattformen. Die integrierte Protokollierung ermöglicht Transparenz und Überprüfung, während die Optionen für Menschen in der Regel Sicherheitsvorkehrungen vor Überschreitungen gewährleisten.
Ethische und soziotechnische Überlegungen
Die Erkennung von Vorspannungen Risiken falsch positiv oder überpoliert marginalisierte Gruppen. Unser Ansatz mildert dies, indem wir persönliche Informationsdaten entfernen, demografische Etiketten vermeiden und überprüfbare Protokolle gespeichert werden. Dennoch ist die Aufsicht unerlässlich. Wie Mehrabi et al. (7) argumentieren, dass die Verzerrung niemals vollständig beseitigt wird, sondern ständig verwaltet werden muss.
Abschluss
Dieses Projekt zeigt, dass KI konstruktiv in On-line-Communities eingesetzt werden kann-nicht nur um Verzerrungen zu erkennen, sondern es auf eine Weise zu mildern, die die Dignität der Benutzer beibehält und das digitale Wohlbefinden fördert.
Schlüsselbeiträge:
-Architektur Twin-Pipeline (Roberta + Distilbert).
-Toneadaptive Minderungsmotor (CHATGPT).
-Persona-basierte Moderation (Jenai-Moderator).
Die Modelle erreichten nahezu perfekte F1-Werte (0,99). Noch wichtiger ist, dass die Reaktionen der Minderung genau und kontextempfindlich waren, was sie für den Einsatz praktisch machte.
Zukünftige Anweisungen:
– Benutzerstudien zur Bewertung des Empfangs.
– Pilotbereitstellungen zum Testen von Vertrauen und Engagement.
– Stärkung der Robustheit gegen Ausweichen (z. B. codierte Sprache).
– Erweiterung auf mehrsprachige Datensätze für die globale Equity.
In einer Zeit, in der KI oft als Hype oder Gefahr gegossen wird, zeigt dieses Projekt, wie es sozial vorteilhaft sein kann. Durch die Einbettung von Equity und Transparenz fördert es gesündere On-line -Räume, in denen sich die Menschen sicherer und respektiert fühlen.
Bilder, Tabellen und Abbildungen, die in diesem Bericht dargestellt wurden, wurden ausschließlich vom Autor erstellt.
Anerkennung
Dieses Projekt erfüllte die Anforderungen an Meilenstein II und Capstone für das Programm Grasp of Utilized Knowledge Science (MADS) an der College of Michigan Faculty of Data (UMSI). Das Poster des Projekts erhielt einen MADS -Preis bei der UMSI Exposition 2025 Poster Session. Dr. Laura Stagnaro diente als Mentor für Capstone Challenge, und Dr. Jinseok Kim diente als Meilenstein II -Projekt Mentor.
Über den Autor
Celia B. Banks ist ein Sozial- und Datenwissenschaftler, dessen Arbeit menschliche Systeme und angewandte Datenwissenschaft überbrückt. Ihre Doktorarbeit in Menschen- und Organisationssystemen untersuchte, wie sich Organisationen in virtuelle Umgebungen entwickeln und ihr breiteres Interesse an der Schnittstelle von Menschen, Technologie und Strukturen widerspiegeln. Dr. Banks lernt lebenslange Lernende und ihr aktueller Fokus baut auf dieser Stiftung durch angewandte Forschung in Datenwissenschaft und Analyse auf.
Referenzen
(1) C. Banks, Celia Banks Portfolio Repository: College of Michigan Faculty of Data Poster (2025) (on-line). Verfügbar: https://celiabbanks.github.io/ (Zugriff am 10. Mai 2025)
(2) A. Go, Twitter Sentiment Evaluation (2009), Entropie, P. 252
(3) Watchful1, 1 Milliarde Reddit-Kommentare von 2005-2019 (Datensatz) (2019), Drücken Sie durch das Auge. Verfügbar: https://github.com/watchful1/pushShiftdumps (Zugriff am 1. September 2024)
(4) Y. Liu, Roberta: Ein strong optimierter Bert -Vorab -Ansatz (2019), Arxiv Preprint Arxiv, P. 1907.116892
(5) V. Sanh, Distilbert, eine destillierte Model von Bert: kleiner, schneller, billiger und leichter (2019), Arxiv Preprint Arxiv, P. 1910.01108
(6) B. Zhang, mildern unerwünschte Verzerrungen mit kontroversem Lernen (2018), in AAAI/ACM -Konferenz über KI, Ethik und Gesellschaft, S. 335-340
(7) A. Mehrabi, eine Umfrage zu Voreingenommenheit und Equity im maschinellen Lernen (2021), in ACM Computing -Umfragen, vol. 54, nein. 6, S. 1-35
(8) R. Binns, Equity im maschinellen Lernen: Lehren aus der politischen Philosophie (2018), in PMLR -Konferenz über Equity, Rechenschaftspflicht und Transparenz, S. 149-159
. ACM-Transaktionen zur Pc-Human-Interaktion (TOCHI), vol. 26, nein. 5, S. 1-35, 2019
(10) N. Lee, P. Resnick und G. Barton, Algorithmische Verzerrungserkennung und -minderung: Greatest Practices und Richtlinien zur Reduzierung von Verbraucherschaden (2019) in Brookings InstituteWashington, DC