Die Checkliste des Machine Studying Engineers: Finest Practices für zuverlässige Modelle
Bild vom Herausgeber
Einführung
Dank ausgereifter Frameworks und verfügbarer Rechenleistung ist der Aufbau neu trainierter Modelle für maschinelles Lernen, die funktionieren, ein relativ einfaches Unterfangen. Die eigentliche Herausforderung im Produktionslebenszyklus eines Modells beginnt jedoch nach dem ersten erfolgreichen Trainingslauf. Nach der Bereitstellung arbeitet ein Modell in einer dynamischen, unvorhersehbaren Umgebung, in der seine Leistung schnell nachlassen kann, was einen erfolgreichen Proof-of-Idea zu einer kostspieligen Belastung macht.
Praktizierende stoßen oft auf Probleme wie Datendriftwenn sich die Eigenschaften der Produktionsdaten im Laufe der Zeit ändern; Konzeptdriftwo sich die zugrunde liegende Beziehung zwischen Eingabe- und Ausgabevariablen entwickelt; oder subtil Rückkopplungsschleifen die zukünftige Trainingsdaten beeinflussen. Diese Fallstricke – die von katastrophalen Modellausfällen bis hin zu langsamen, schleichenden Leistungseinbußen reichen – sind oft das Ergebnis eines Mangels an der richtigen operativen Genauigkeit und den richtigen Überwachungssystemen.
Der Aufbau zuverlässiger Modelle, die auf lange Sicht eine gute Leistung erbringen, ist eine andere Geschichte, die Disziplin, eine robuste MLOps-Pipeline und natürlich Geschick erfordert. Dieser Artikel konzentriert sich genau darauf. Diese forschungsgestützte Checkliste bietet einen systematischen Ansatz zur Bewältigung dieser Herausforderungen und beschreibt wesentliche Finest Practices, Kernkompetenzen und manchmal unverzichtbare Instruments, mit denen jeder Machine-Studying-Ingenieur vertraut sein sollte. Durch die Übernahme der in diesem Leitfaden dargelegten Prinzipien sind Sie in der Lage, Ihre ursprünglichen Modelle in wartbare, qualitativ hochwertige Produktionssysteme umzuwandeln und sicherzustellen, dass sie präzise, unvoreingenommen und widerstandsfähig gegenüber den unvermeidlichen Veränderungen und Herausforderungen der realen Welt bleiben.
Hier ist ohne weiteres die Liste der 10 Finest Practices für Machine-Studying-Ingenieure, die ich für Sie und Ihre kommenden Modelle zusammengestellt habe, damit sie im Hinblick auf langfristige Zuverlässigkeit von ihrer besten Seite glänzen.
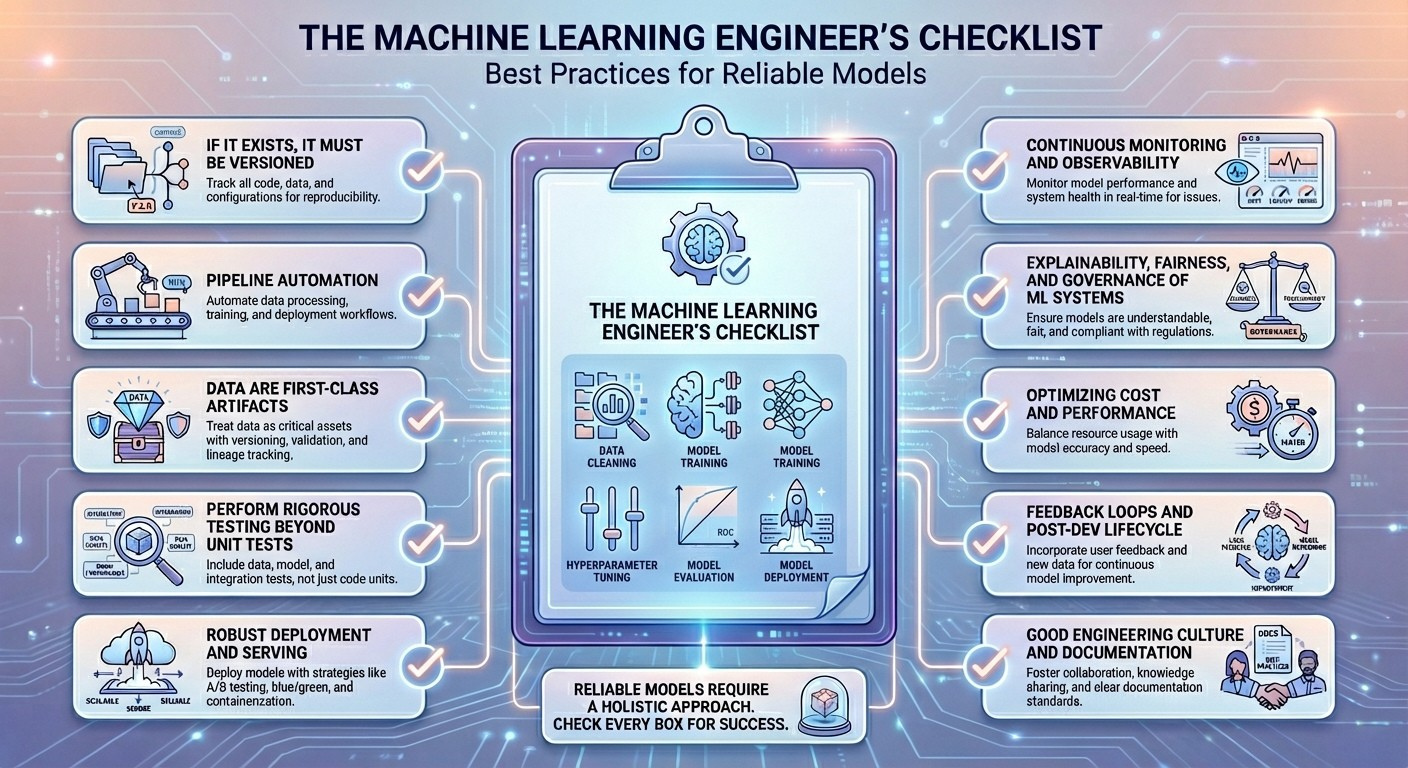
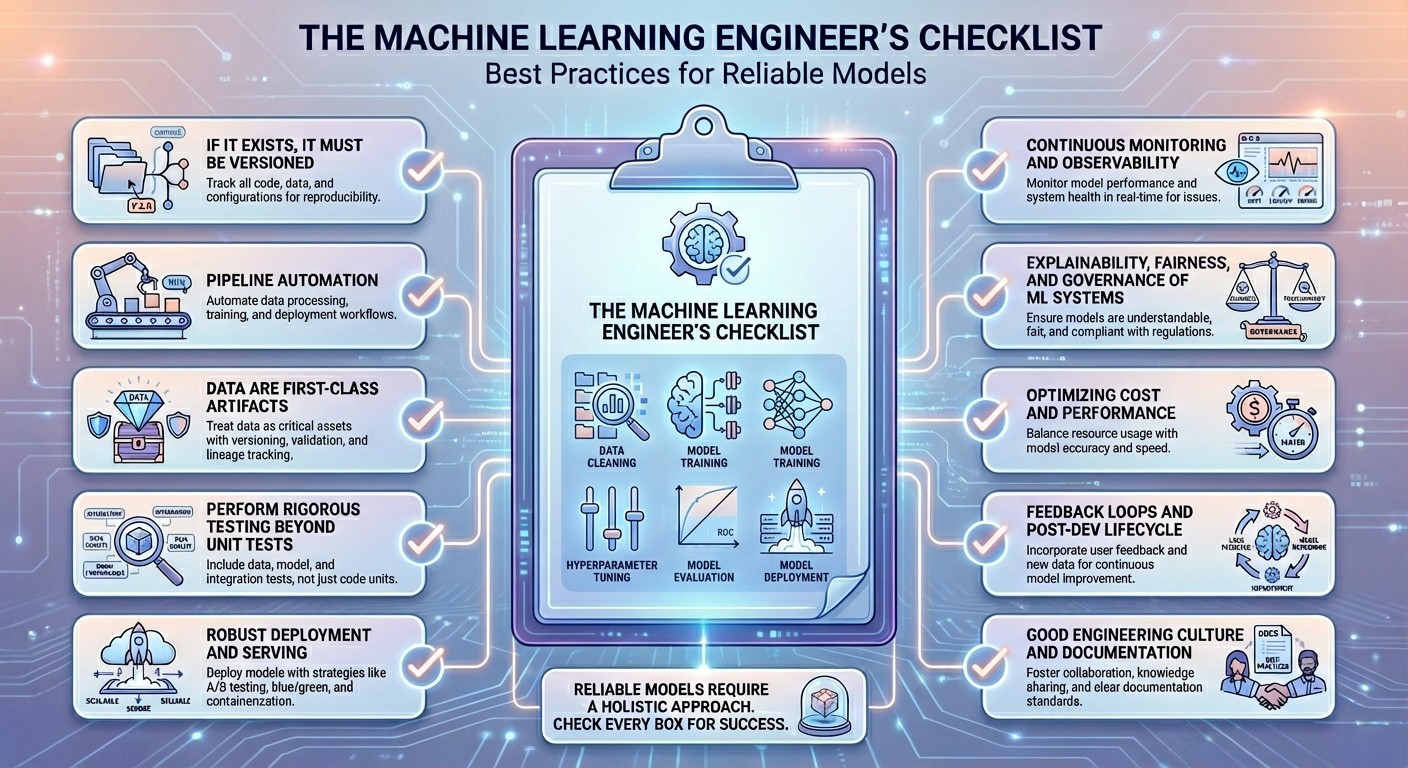
Die Checkliste
1. Wenn es existiert, muss es versioniert werden
Datenschnappschüsse, Code zum Trainieren von Modellen, verwendete Hyperparameter und Modellartefakte – alles ist wichtig und alles unterliegt Schwankungen im Laufe Ihres Modelllebenszyklus. Daher, Alles rund um ein Modell für maschinelles Lernen sollte ordnungsgemäß versioniert sein. Stellen Sie sich zum Beispiel vor, dass die Leistung Ihres Bildklassifizierungsmodells, die früher großartig conflict, nach einer konkreten Fehlerbehebung nachlässt. Mit der Versionierung können Sie die alten Modelleinstellungen reproduzieren und die Grundursache des Issues sicherer isolieren.
Hier gibt es kein Hexenwerk – Versionierung ist in der gesamten Ingenieursgemeinschaft weithin bekannt und verfügt über Kernkompetenzen wie die Verwaltung von Git-Workflows, Datenherkunft und Experimentverfolgung; und spezifische Instruments wie DVC, Git/GitHub, MLflowUnd Deltasee.
2. Pipeline-Automatisierung
Im Rahmen Kontinuierliche Integration und kontinuierliche Lieferung (CI/CD) Prinzipien, wiederholbare Prozesse, die eine Datenvorverarbeitung durch Schulung, Validierung und Bereitstellung umfassen, sollten darin zusammengefasst werden Pipelines mit automatisiertem Betrieb und Assessments darunter. Angenommen, eine nächtliche Setup-Pipeline ruft neue Daten ab – z. B. von einem Sensor erfasste Bilder –, führt Validierungstests durch, trainiert das Modell bei Bedarf neu (z. B. aufgrund von Datendrift), bewertet geschäftliche Key Efficiency Indicators (KPIs) neu und schiebt die aktualisierten Modelle in die Bereitstellung. Dies ist ein häufiges Beispiel für Pipeline-Automatisierung und erfordert Fähigkeiten wie Workflow-Orchestrierung und Grundlagen von Technologien wie Docker Und Kubernetesund Kenntnisse in der Testautomatisierung.
Häufig nützliche Werkzeuge Dazu gehören: Luftstrom, GitLab CI, Kubeflow, FlyteUnd GitHub-Aktionen.
3. Daten sind erstklassige Artefakte
Die Strenge, mit der Softwaretests in jedem Softwareentwicklungsprojekt angewendet werden, muss vorhanden sein, um die Datenqualität und -beschränkungen durchzusetzen. Daten sind die wesentliche Nahrung von Machine-Studying-Modellen von der Entstehung bis zur Bereitstellung in der Produktion; Daher muss die Qualität der aufgenommenen Daten optimum sein.
Ein solides Verständnis von Datentypen, Schemadesigns und Datenqualitätsproblemen wie Anomalien, Ausreißern, Duplikaten und Rauschen ist von entscheidender Bedeutung, um Daten als erstklassige Vermögenswerte zu behandeln. Werkzeuge wie Offensichtlich, DBT-AssessmentsUnd Deequ sollen dabei helfen.
4. Führen Sie strenge Assessments durch, die über Unit-Assessments hinausgehen
Das Testen maschineller Lernsysteme umfasst Spezifische Assessments für Aspekte wie Pipeline-Integration, Funktionslogik und statistische Konsistenz von Ein- und Ausgaben. Wenn ein überarbeitetes Characteristic-Engineering-Skript eine geringfügige Änderung in der ursprünglichen Verteilung einer Funktion vornimmt, besteht Ihr System möglicherweise grundlegende Komponententests, aber durch Verteilungstests kann das Drawback möglicherweise rechtzeitig erkannt werden.
Testgetriebene Entwicklung (TDD) und Kenntnisse über statistische Hypothesentests sind starke Verbündete, um „diese Finest Observe in die Praxis umzusetzen“, wobei zwingend erforderliche Instruments wie das unter dem Radar bleiben pytest Bibliothek, benutzerdefinierte Datendrifttests und Mocking in Unit-Assessments.
5. Robuste Bereitstellung und Bereitstellung
Dazu gehört die Bereitstellung und Bereitstellung eines robusten Modells für maschinelles Lernen in der Produktion Das Modell sollte verpackt, reproduzierbar und auf große Umgebungen skalierbar sein und bei Bedarf sicher zurückgesetzt werden können.
Die sogenannte Blau-Grün-Strategie, die auf der Bereitstellung in zwei „identischen“ Produktionsumgebungen basiert, ist eine Möglichkeit, sicherzustellen, dass der eingehende Datenverkehr bei Latenzspitzen schnell zurückverlagert werden kann. Dabei helfen Cloud-Architekturen und Containerisierung mit spezifischen Instruments wie Docker, Kubernetes, FastAPIUnd BentoML.
6. Kontinuierliche Überwachung und Beobachtbarkeit
Dies steht wahrscheinlich bereits in Ihrer Checkliste der Finest Practices, aber als wesentlicher Bestandteil der maschinellen Lerntechnik lohnt es sich, darauf hinzuweisen. Die kontinuierliche Überwachung und Beobachtbarkeit des bereitgestellten Modells umfasst eine Überwachung DatendriftModellverfall, Latenz, Kosten und andere domänenspezifische Geschäftsmetriken, die über Genauigkeit oder Fehler hinausgehen.
Wenn beispielsweise die Rückrufmetrik eines Betrugserkennungsmodells bei der Entstehung neuer Betrugsmuster sinkt, können richtig eingestellte Abweichungswarnungen dazu führen, dass das Modell mit neuen Transaktionsdaten neu trainiert werden muss. Prometheus und Enterprise-Intelligence-Instruments wie Grafana kann hier sehr helfen.
7. Erklärbarkeit, Equity und Governance von ML-Systemen
Ein weiteres wesentliches Ziel für Ingenieure des maschinellen Lernens, auf das diese Finest Observe abzielt Sicherstellung der Bereitstellung von Modellen mit transparentem, konformem und verantwortungsvollem Verhalten sowie Verständnis und Einhaltung bestehender nationaler oder regionaler Vorschriften – zum Beispiel die KI-Gesetz der Europäischen Union. Ein Beispiel für die Anwendung dieser Grundsätze könnte ein Kreditklassifizierungsmodell sein, das vor dem Einsatz Fairnessprüfungen auslöst, um sicherzustellen, dass geschützte Gruppen nicht unangemessen abgelehnt werden. Für Interpretierbarkeit und Governance stehen Instruments wie zur Verfügung Gestalten, KALKModellregister und Fairlearn sind sehr zu empfehlen.
8. Optimierung von Kosten und Leistung
Diese Finest Observe beinhaltet Optimierung des Modelltrainings und des Inferenzdurchsatzes sowie der Latenz und des Hardwareverbrauchs. Eine mögliche Möglichkeit, dies zu nutzen, besteht darin, von herkömmlichen Modellen auf solche umzusteigen, die Techniken wie gemischte Präzision und Quantisierung verwenden, wodurch die GPU-Kosten erheblich gesenkt werden und gleichzeitig die Genauigkeit erhalten bleibt. Zu den Bibliotheken und Frameworks, die diese Techniken bereits unterstützen, gehören: PyTorch AMP, TensorRTUnd vLLMum nur einige zu nennen.
9. Feedbackschleifen und Submit-Dev-Lebenszyklus
Zu den spezifischen Finest Practices in diesem Bereich gehören: Sammeln von „Floor Reality“-Datenbezeichnungen, Umschulen von Modellen im Rahmen eines etablierten Arbeitsablaufs und Überbrücken der Lücke zwischen realen Ergebnissen und Modellvorhersagen. Ein Empfehlungsmodell ist ein gutes Beispiel dafür: Es muss regelmäßig neu trainiert werden und dabei aktuelle Benutzerinteraktionen einbeziehen, um zu verhindern, dass es veraltet. Schließlich ändern und entwickeln sich die Vorlieben der Benutzer im Laufe der Zeit!
Zu den hilfreichen Fähigkeiten zum Definieren solider Feedbackschleifen und eines Lebenszyklus nach der Entwicklung gehören das Definieren geeigneter Datenkennzeichnungsstrategien, das Entwerfen von Modellumschulungsschemata und die Verwendung von Vorfall-Runbooks (ein Vorfall-Runbook ist eine Schritt-für-Schritt-Anleitung zum schnellen Identifizieren, Analysieren und Bewältigen von Problemen in Produktionssystemen für maschinelles Lernen). Ebenso Characteristic-Retailer-Instruments wie Tecton Und Fest sind auch praktisch für die Ausübung dieser Praktiken.
10. Gute Ingenieurkultur und Dokumentation
Zum Abschluss dieser Checkliste ist eine gute Ingenieurskultur in Kombination mit allen anderen neun Finest Practices unerlässlich Reduzieren Sie nicht so offensichtliche technische Schulden und erhöhen Sie die Wartbarkeit des Methods. Vereinfacht ausgedrückt verhindert eine klar dokumentierte Modellabsicht, dass zukünftige Ingenieure es beispielsweise für unbeabsichtigte Aufgaben verwenden. Kommunikation, funktionsübergreifende Zusammenarbeit und effektives Wissensmanagement sind hierfür drei Grundpfeiler. In Unternehmen weit verbreitete Instruments wie Zusammenfluss Und Vorstellung kann helfen.
Zusammenfassung
Obwohl die Landschaft des maschinellen Lernens von komplexen Herausforderungen durchzogen ist – von der Bewältigung technischer Schulden und Datendrift bis hin zur Aufrechterhaltung von Equity und hoher Leistung – sind diese Probleme nicht unüberwindbar. Die erfolgreichsten MLOps-Groups betrachten diese Hindernisse nicht als Hindernisse, sondern als notwendige Ziele für Prozessverbesserungen. Durch die Anwendung der in dieser Checkliste beschriebenen systematischen, strengen Praktiken können Ingenieure über fragmentierte Advert-hoc-Lösungen hinausgehen und eine dauerhafte Qualitätskultur etablieren. Die Befolgung dieser Prinzipien, von der Versionierung aller Daten bis hin zum rigorosen Testen von Daten und der Automatisierung der Bereitstellung, verwandelt die schwierige Aufgabe der langfristigen Modellzuverlässigkeit in einen überschaubaren, reproduzierbaren Engineering-Aufwand. Dieses Bekenntnis zu Finest Practices ist es, was letztendlich erfolgreiche Forschungsprojekte von nachhaltigen, wirkungsvollen Produktionssystemen unterscheidet.
Dieser Artikel enthält eine Checkliste mit 10 wesentlichen Finest Practices für Machine-Studying-Ingenieure, um eine zuverlässige Modellentwicklung und -bereitstellung auf lange Sicht sicherzustellen, sowie spezifische Strategien, Beispielszenarien und nützliche Instruments auf dem Markt, um diese Finest Practices zu befolgen.