Benchmarking von Coding-Agenten in einer Welt aus Apps und Menschen
Stellen Sie sich eine Welt vor, in der KI-Agenten als Ihre persönlichen Assistenten fungieren und Aufgaben für Sie erledigen, wie z. B. eine Rücksendung bei Amazon zu veranlassen oder Conferences auf Grundlage Ihrer E-Mails abzusagen. Dies würde Agenten erfordern, die Ihre Anwendungen interaktiv in komplexen Workflows bedienen, und es gab bisher keine wirklich gute Möglichkeit, solche Agenten zu vergleichen. Bis jetzt.
KI-Assistenten (z. B. die auf unseren Mobiltelefonen) verbessern sich mit der Verbesserung der zugrunde liegenden KI-Modelle. Vor einigen Jahren hatten sie Schwierigkeiten, einfache Sachfragen richtig zu beantworten. Heute haben sie begonnen um an den Punkt zu gelangen, an dem sie Apps in unserem Namen betreiben können, um grundlegende Aufgaben zu erledigen. Ein Großteil der jüngsten GoogleIO Und Apple WWDC Bei den Veranstaltungen drehte es sich um die Imaginative and prescient von KI-Assistenten als autonomen Agenten, die in unserem Auftrag arbeiten.
In Zukunft werden sie in der Lage sein, komplexere Aufgaben in unseren Apps selbstständig zu erledigen. Sie könnten beispielsweise sagen: „Hey, einige meiner Kollegen haben Conferences per E-Mail abgesagt. Bitte löschen Sie meine entsprechenden Telefonerinnerungen.“ Der Agent würde selbstständig Ihren E-Mail-Posteingang überprüfen, herausfinden, welche Kollegen abgesagt haben, zur Kalender-App gehen, feststellen, welche Conferences mit diesen Kollegen anstehen, und sie absagen.

Eine Möglichkeit, wie KI-Modelle solche Aufgaben bewältigen können, ist durch interaktiv Schreiben Code und ruft APIs. APIs ermöglichen Agenten, elementare Aktionen auf Apps durchzuführen, Code ermöglicht es ihnen, sie in komplexen Logik- und Kontrollflüssen zu orchestrieren und Interaktion ermöglicht ihnen, Benutzerkonten zu untersuchen und basierend auf den Ergebnissen der Codeausführung Anpassungen vorzunehmen.
Betrachten Sie ein Beispiel in der folgenden Abbildung, in dem der Agent die Aufgabe hat, eine Wiedergabeliste mit genügend Songs zu starten, die die Trainingsdauer des Benutzers für heute abdecken. Dazu muss der Agent zunächst Code schreiben, der SimpleNote aufruft APIs (1. Codeblock), um die Notiz mit dem Trainingsplan zu finden und zu „lesen“ (drucken). Erst danach Interaktion um zu sehen, wie die Notiz strukturiert ist – da die Dauer nach Tagen aufgelistet ist – kann der Agent den erforderlichen Code schreiben (2. Codeblock), der das Finden des heutigen Wochentags und das Extrahieren der zugehörigen Dauer beinhaltet. Um eine Wiedergabeliste auszuwählen, muss er Wealthy Code mit For-Schleifen und anderen Kontrollflüssen, um über Wiedergabelisten zu iterieren, die Dauer der Wiedergabelisten zu berechnen und eine Wiedergabeliste abzuspielen, die die Dauer des Trainings abdeckt (3. Codeblock).

Nachdem wir nun wissen, wie ein Agent solche Aufgaben erledigen kann, stellt sich die Frage:
Wie können wir solche Kodieragenten für alltägliche digitale Aufgaben über verschiedene Apps hinweg entwickeln und vergleichen?
Dafür benötigen wir (i) eine umfangreiche, stabile und reproduzierbare Ausführungsumgebung, in der Agenten über Code und APIs mit vielen alltäglichen Apps interagieren können, (ii) komplexe Aufgaben, die API-Aufrufe und umfangreiche und interaktive Codierung erfordern, und (iii) ein zuverlässiges Evaluierungsframework.
Bestehende Benchmarks wie Gorilla, Werkzeugbank, API-Financial institution, WerkzeugTalk, Ruhebank erfüllen keine dieser drei Anforderungen. Abgesehen davon, dass ihnen die oben genannte Artwork von Umgebung fehlt, umfassen ihre Aufgaben nur eine lineare Abfolge von 1–4 API-Aufrufen, ohne dass umfangreiche und interaktive Codierung erforderlich ist, und sie bewerten, indem sie die Lösung des Agenten mit einer Referenzlösung vergleichen (mithilfe eines LLM oder eines Menschen), was bei komplexen Aufgaben, die viele verschiedene Lösungen zulassen, nicht intestine funktioniert.
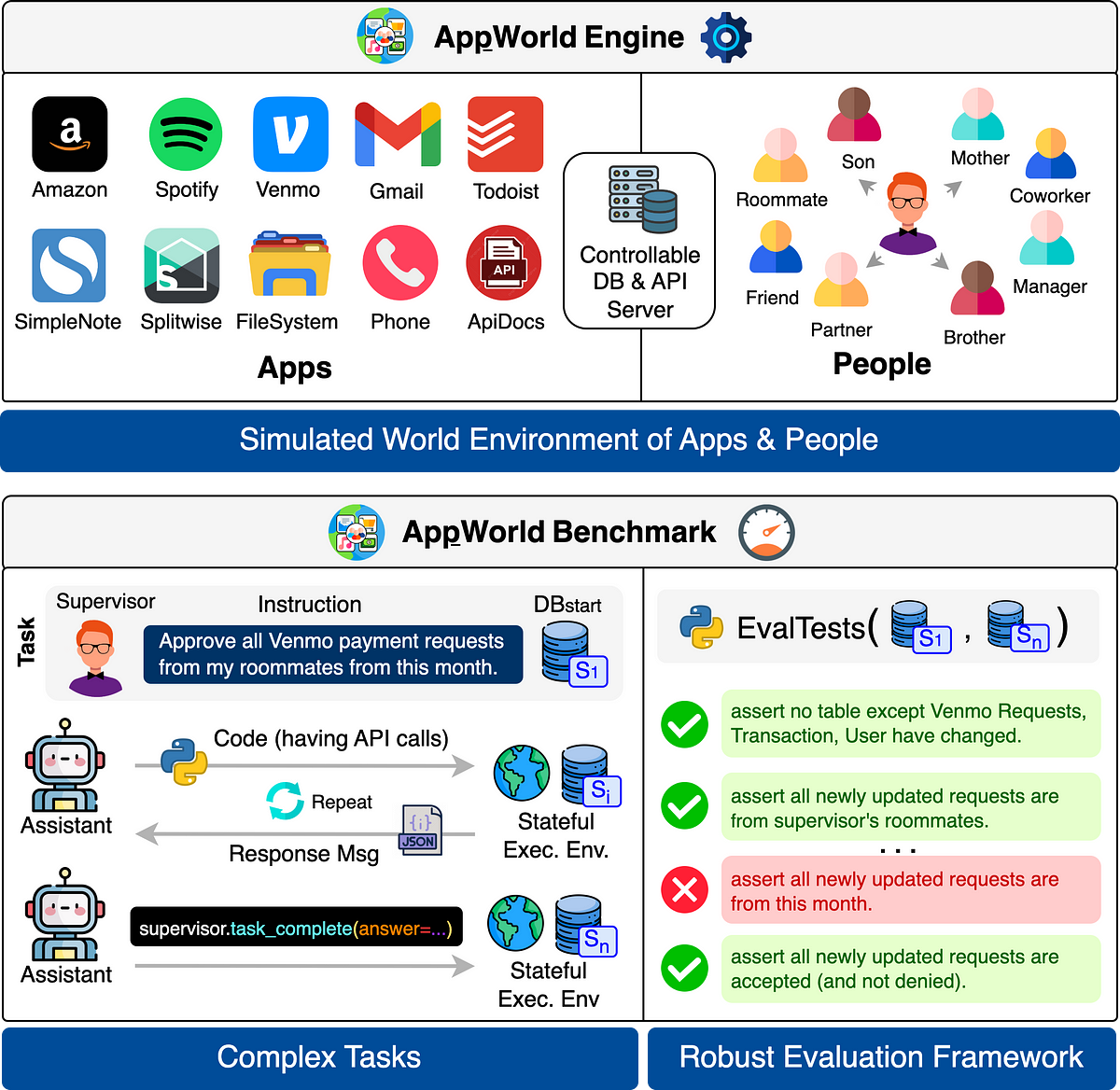
Um diese Lücke zu schließen, führen wir ein AppWorld, die (1) eine kontrollierbare und simulierte Weltumgebung darstellt (Motor), bei der Coding-Agenten über APIs verschiedene Apps im Auftrag von Menschen betreiben können, (2) eine Benchmark von komplexen Aufgaben, die auf dieser Umgebung definiert sind, und (3) eine robuste Auswertung Rahmen für die Beurteilung der Agentenleistung.

⚙️ 2.1 Engine: simulierte digitale Welt
AppWorld Engine ist ein hochpräziser API-basierter Simulator (60.000 Zeilen Code), der ein Ökosystem aus 9 alltäglichen Apps aus verschiedenen Bereichen simuliert (Gmail für E-Mail, Amazon zum Einkaufen, Spotify für Musik usw.). Diese Engine wird von einem vollständig steuerbaren lokalen Backend mit 457 APIs und über 100 DB-Tabellen unterstützt, das die umfangreichen Funktionen der echten Apps genau nachahmt. Diese APIs verfügen über eine ausführliche Dokumentation (Interaktiv erkunden), die Agenten lesen können, um deren Verwendung zu verstehen.
Anschließend simulieren wir auf dieser Engine eine digitale Welt von Menschen und ihren digitalen Aktivitäten in diesen Apps. Insbesondere füllen wir die App-Datenbanken (DBs) mit 106 fiktiven Personen, die in dieser simulierten Welt leben. Sie sind über verschiedene Beziehungen miteinander verbunden, z. B. Mitbewohner, Freunde, Supervisor usw., um zwischenmenschliche Aufgaben zu ermöglichen, z. B. das Teilen von Rechnungen mit Mitbewohnern. Dann wird ihr Alltag simuliert, um verschiedene persönliche und zwischenmenschliche Aktivitäten auf ihren App-Konten auszuführen, z. B. T-Shirts bei Amazon zur Lieferung nach Hause zu bestellen, einen Mitbewohner telefonisch nach Autoschlüsseln zu fragen und so weiter. Die endgültigen DBs haben über 300.000 Zeilen, die sich über 726 Spalten erstrecken.
📊 2.2 Benchmark komplexer Aufgaben
AppWorld Benchmark erstellt 750 alltägliche Aufgaben auf dieser Engine (Beispiele oben gezeigt), die viele APIs erfordern (oft 15+), mehrere Apps umfassen (1–4) und eine umfangreiche und interaktive Codierung erfordern (oft 80+ Zeilen mit vielen Programmierkonstrukten). Siehe die Statistiken in der Abbildung unten und Aufgaben erkunden interaktiv auf unserem Spielplatz.
Jede Aufgabenanweisung wird mit einem Supervisor (Particular person in AppWorld) geliefert, in dessen Auftrag der Agent die Aufgabe ausführen soll. Der Agent hat Zugriff auf alle seine App-Konten. Der anfängliche Datenbankzustand jeder Aufgabe wird sorgfältig (programmgesteuert) entworfen, um sicherzustellen, dass die Aufgabe intestine definiert ist und realistische Ablenkungen und Hindernisse aufweist. Die Aufgaben werden auch mit Aufgabenvariationen geliefert, die ganzheitlich prüfen, ob ein Agent die Aufgabe unter verschiedenen Anfangsbedingungen und Anweisungsvariationen zuverlässig lösen kann.
Alle Aufgabenimplementierungen werden von uns entworfen und entwickelt (kein Crowdsourcing). Ihre Implementierungen umfassen über 40.000 Zeilen Code (ja, in die Aufgabenentwicklung fließt eine Menge ein; siehe das Dokument).

✔️ 2.3. Robuster Bewertungsrahmen
Die komplexen Aufgaben in AppWorld können auf viele Arten erledigt werden (z. B. kann ein Bestellbeleg über die Amazon-API oder die Bestätigungs-E-Mail heruntergeladen werden). Darüber hinaus kann ein Agent, der die Aufgabe löst, auf viele verschiedene Arten Kollateralschäden verursachen (z. B. indem er eine nicht angeforderte Rücksendung einleitet). Ein Verfahren-basierend Ein Ansatz, der agentengenerierten Code mit Referenzcode oder API-Aufrufen vergleicht, ist für die Bewertung der Aufgabenerledigung unzureichend.
Stattdessen verwendet AppWorld eine staatlich Ansatz. Insbesondere definieren wir für jede Aufgabe eine programmatische Reihe von Unit-Checks, die als Eingaben Snapshots von Datenbankzuständen erstellen: (1) Zustand vor dem Begin des Agenten und (2) nach dessen Ende. Anschließend prüfen wir, ob alle erwarteten und keine unerwarteten Datenbankänderungen vorgenommen wurden. Dies ermöglicht es uns, strong Überprüfen Sie, ob ein Agent die Aufgabe korrekt ausgeführt hat, ohne Kollateralschäden zu verursachen.
Um sicherzustellen, dass die Aufgaben lösbar sind, schreiben wir abschließend Validierungslösungscodes und überprüfen programmgesteuert, ob bei deren Ausführung alle Bewertungstests bestanden werden.
Wir haben viele LLMs mit mehreren Few-Shot-Prompting-Methoden wie ReAct, Planen und Ausführen, Generieren von vollständigem Code mit Reflektion und Funktionsaufrufen verglichen. Sogar das beste LLM, GPT-4o, zeigt eine recht schlechte Leistung. Beispielsweise erledigt es nur ca. 30 % der Aufgaben im Problem-Testsatz korrekt. GPT-4 Turbo und offene LLMs hinken noch viel weiter hinterher.
Darüber hinaus fallen die Werte für unsere strengere Robustheitsmetrik, die prüft, ob Agenten alle Aufgabenvariationen unter verschiedenen Startbedingungen und Anweisungsstörungen zuverlässig erledigen können, deutlich niedriger aus.

Darüber hinaus sinken die Punktzahlen mit zunehmendem Schwierigkeitsgrad erheblich, gemäß unseren handvergebenen Bezeichnungen und anderen Schwierigkeitsindikatoren, wie der Anzahl der APIs und Codezeilen basierend auf unseren schriftlichen Validierungslösungen.

AppWorld ist eine modulare und erweiterbare Grundlage, die viele spannende Möglichkeiten bei der Automatisierung digitaler Aufgaben eröffnet. Zukünftige Arbeiten können beispielsweise:
- Erweitern Sie die AppWorld-Engine, um die browser-/cellular UI-basierte Steuerung der vorhandenen Aufgaben zu unterstützen und einen einheitlichen Maßstab für Code-, API- und UI-basierte autonome Agenten bereitzustellen.
- Erweitern Sie den AppWorld-Benchmark um Aufgaben, die die Koordination und Zusammenarbeit mehrerer Agenten (und Menschen) erfordern (z. B. das Einrichten eines Kalendertreffens mit einem Freund, indem Sie sich per E-Mail mit seinem Agenten abstimmen).
- Überlagern Sie unsere digitale Weltmaschine mit einer physischen Weltmaschine, wie Simulacramit Rollenspielagenten, um soziale Dynamiken und Verhalten in einer kontrollierten Umgebung zu untersuchen.
- Verwenden Sie die Engine als Sandbox ohne Konsequenzen, um potenzielle Datenschutz- und Sicherheitsrisiken zu untersuchen, die entstehen können, wenn digitalen Assistenten die „Befugnis“ gegeben wird, in der realen Welt in unserem Namen zu handeln.
- Und natürlich können Sie AppWorld auf ein noch größeres Ökosystem aus Apps und Aufgaben ausweiten.
Wir freuen uns darauf, dass wir und andere diese Richtungen (und mehr!) auf AppWorld weiterverfolgen können. Melden Sie sich, wenn Sie Hilfe benötigen oder mitarbeiten möchten!
AppWorld ist einfach zu verwenden und schnell. Sie können das Open-Supply-Python-Paket mit pip installieren und mit dem Erstellen und Testen Ihres Agenten beginnen. Wenn Sie einen Agenten haben, benötigen Sie lediglich den folgenden Code, um ihn auf AppWorld auszuführen und auszuwerten.
Papier, Code, Bestenliste, Datenexplorer (Aufgaben, APIs, Agententrajektorien), interaktiver Spielplatz (direkte Interaktion mit AppWorld-Aufgaben), Videoerklärung und mehr finden Sie unter https://appworld.dev.
NEU: AppWorld gewann den Bestes Ressourcenpapier Auszeichnung bei ACL‘24. 🏆 🎉
Bildquelle: Alle Bilder wurden vom Autor erstellt.