Ein tiefer Einblick in die stochastische Dekodierung mit Temperatur, top_p, top_k und min_p
vor 11 Stunden

Wenn Sie einem Giant Language Mannequin (LLM) eine Frage stellen, gibt das Modell eine Wahrscheinlichkeit für jedes mögliche Token in seinem Vokabular aus.
Nachdem wir aus dieser Wahrscheinlichkeitsverteilung ein Token ausgewählt haben, können wir das ausgewählte Token an unsere Eingabeaufforderung anhängen, sodass das LLM die Wahrscheinlichkeiten für das nächste Token ausgeben kann.
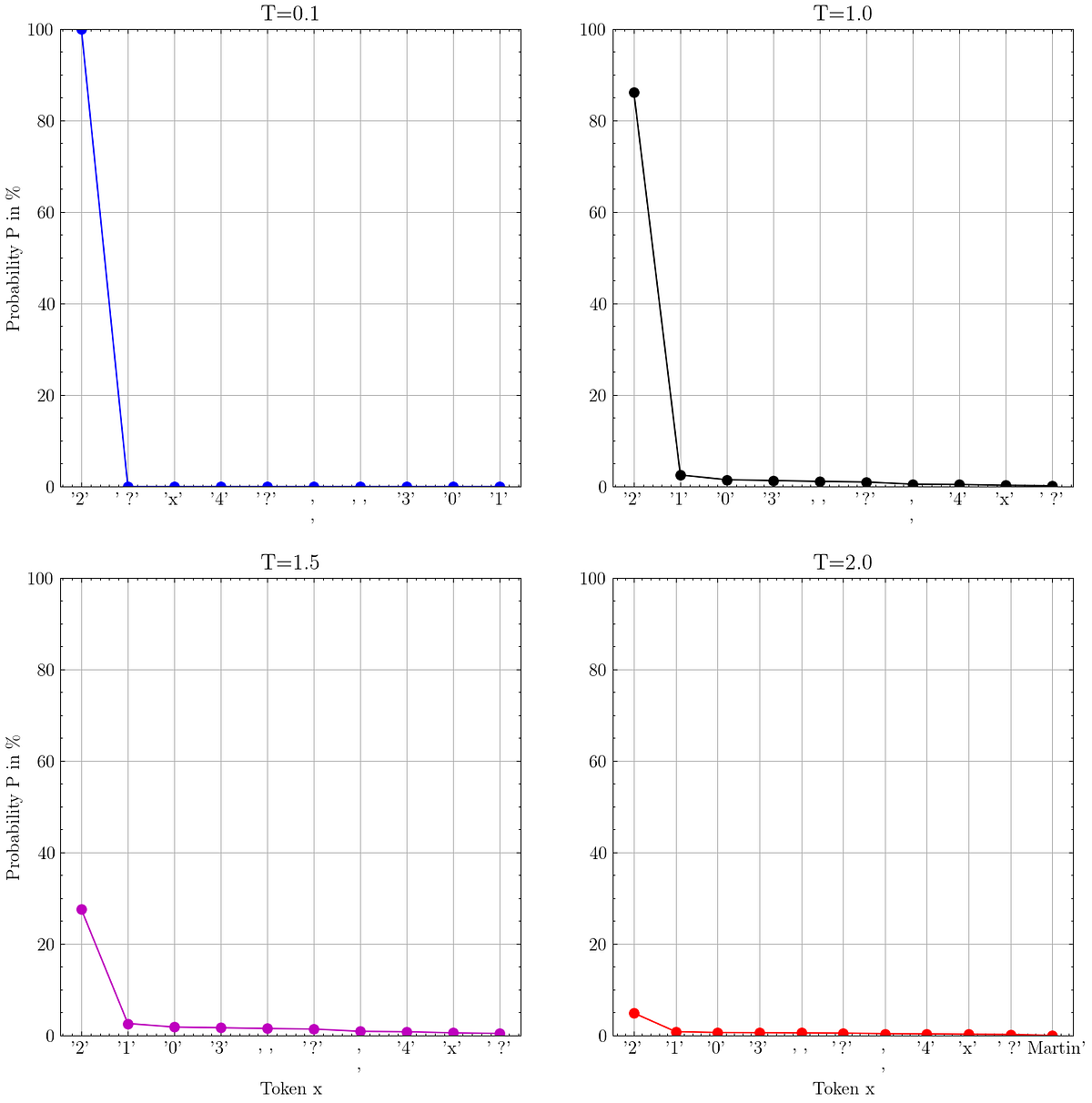
Dieser Sampling-Prozess kann durch Parameter wie die berühmte temperature Und top_p.
In diesem Artikel erkläre und visualisiere ich die Sampling-Strategien, die das Ausgabeverhalten von LLMs definieren. Indem wir verstehen, was diese Parameter bewirken, und sie entsprechend unserem Anwendungsfall einstellen, können wir die von LLMs generierte Ausgabe verbessern.
Für diesen Artikel verwende ich VLLM als Inferenzmaschine und Microsofts neue Phi-3.5-Mini-Anweisung Modell mit AWQ-Quantisierung. Um dieses Modell lokal auszuführen, verwende ich die NVIDIA GeForce RTX 2060 GPU meines Laptops.
Inhaltsverzeichnis
· Sampling mit Logprobs verstehen
∘ LLM Dekodierungstheorie
∘ Abrufen von Logprobs mit dem OpenAI Python SDK
· Grasping-Dekodierung
· Temperatur
· Prime-k-Stichproben
· Prime-p-Stichproben
· Kombinieren von Prime-p…