Entwirrende Merkmale im komplexen neuronalen Netzwerk mit Überlagerungen
Komplexe neuronale Netzwerkewie Großsprachmodelle (LLMs) leiden ziemlich oft unter Interpretierbarkeit Herausforderungen. Einer der wichtigsten Gründe für solche Schwierigkeiten ist Überlagerung – Ein Phänomen des neuronalen Netzwerks mit weniger Dimensionen als die Anzahl der Funktionen, die es darstellen muss. Beispielsweise muss ein Spielzeug -LLM mit 2 Neuronen 6 verschiedene Sprachmerkmale darstellen. Infolgedessen stellen wir häufig fest, dass ein einzelnes Neuron für mehrere Merkmale aktiviert werden muss. Eine detailliertere Erklärung und Definition der Überlagerung finden Sie in meinem vorherigen Weblog -Beitrag: „Überlagerung: Was es schwierig macht, neuronales Netzwerk zu erklären“.
In diesem Weblog -Beitrag gehen wir noch einen Schritt weiter: Versuchen wir, einige FSUperponiertenfunktionen zu entwirren. Ich werde eine Methodik vorstellen, die genannt wird Spärlicher Autoencoder Um das komplexe neuronale Netzwerk, insbesondere LLM, in interpretierbare Merkmale zu zersetzen, mit einem Spielzeugbeispiel für Sprachmerkmale.
A Spärlicher AutoencoderEs ist per Definition ein AutoCodierer mit Sparsity, der absichtlich in den Aktivierungen seiner verborgenen Schichten eingeführt wird. Mit einer ziemlich einfachen Struktur und einem leichten Trainingsprozess soll ein komplexes neuronales Netzwerk zerlegt und die Merkmale auf interpretierbare und verständliche und verständlicher für den Menschen aufdeckt.
Stellen wir uns vor, Sie haben ein geschultes neuronales Netzwerk. Der Autocoder ist nicht Teil des Trainingsprozesses des Modells selbst, sondern ein Put up-hoc-Analyse-Device. Das ursprüngliche Modell verfügt über eigene Aktivierungen, und diese Aktivierungen werden anschließend gesammelt und dann als Eingabedaten für den spärlichen Autoencoder verwendet.
Zum Beispiel nehmen wir an, dass Ihr ursprüngliches Modell ein neuronales Netzwerk mit einer versteckten Schicht von 5 Neuronen ist. Außerdem haben Sie einen Trainingsdatensatz mit 5000 Proben. Sie müssen alle Werte der 5-dimensionalen Aktivierung der versteckten Schicht für alle Ihre 5000 Trainingsproben sammeln, und sie sind nun die Eingabe für Ihren spärlichen Autocoder.

Der Autocoder lernt dann eine neue, spärliche Darstellung aus diesen Aktivierungen. Die Encoder -Aktivierung bildet die ursprünglichen MLP -Aktivierungen in einen neuen Vektorraum mit höheren Darstellungsdimensionen. Wenn wir auf mein vorheriges 5-Neuron-einfaches Beispiel zurückblicken, können wir es in Betracht ziehen, es mit 20 Funktionen in einen Vektorraum zuzuordnen. Hoffentlich erhalten wir einen spärlichen Autoencoder, der die ursprünglichen MLP -Aktivierungen effektiv in eine Darstellung zerlegen, die leichter zu interpretieren und zu analysieren zu werden.
Sparsity ist ein wichtiger im Autoencoder, da es für den Autocoder notwendig ist, Merkmale mit mehr „Freiheit“ als in einem dichten, überlappenden Raum zu entwirren. Ohne Existenz von Sparsity wird der Autocoder wahrscheinlich der Autocoder möglicherweise nur ein Trivial lernen Komprimierung ohne aussagekräftige Merkmalsbildung.
Sprachmodell
Lassen Sie uns jetzt unser Spielzeugmodell erstellen. Ich bitte die Leser zu bemerken, dass dieses Modell in der Praxis nicht realistisch und sogar ein bisschen albern ist, aber es reicht aus, um zu zeigen, wie wir spärliche Autoencoder aufbauen und einige Funktionen erfassen.
Angenommen, wir haben jetzt ein Sprachmodell erstellt, das eine bestimmte versteckte Schicht hat, deren Aktivierung drei Dimensionen hat. Nehmen wir auch an, wir haben die folgenden Token: „Katze“, „Pleased Cat“, „Canine“, „Energetic Canine“, „nicht Katze“, „nicht Hund“, „Roboter“ und „AI -Assistent“ in der Trainingsdatensatz und sie haben die folgenden Aktivierungswerte.
information = torch.tensor((
# Cat classes
(0.8, 0.3, 0.1, 0.05), # "cat"
(0.82, 0.32, 0.12, 0.06), # "pleased cat" (much like "cat")
# Canine classes
(0.7, 0.2, 0.05, 0.2), # "canine"
(0.75, 0.3, 0.1, 0.25), # "loyal canine" (much like "canine")# "Not animal" classes
(0.05, 0.9, 0.4, 0.4), # "not cat"
(0.15, 0.85, 0.35, 0.5), # "not canine"
# Robotic and AI assistant (extra distinct in 4D house)
(0.0, 0.7, 0.9, 0.8), # "robotic"
(0.1, 0.6, 0.85, 0.75) # "AI assistant"
), dtype=torch.float32)
Bau des AutoCoders
Wir erstellen jetzt den AutoCodierer mit dem folgenden Code:
class SparseAutoencoder(nn.Module):
def __init__(self, input_dim, hidden_dim):
tremendous(SparseAutoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(hidden_dim, input_dim)
)def ahead(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
Gemäß dem obigen Code sehen wir, dass der Encoder eine einzige vollständig verbundene lineare Schicht hat, wodurch die Eingabe zu einer versteckten Darstellung mit abgebildet ist hidden_dim und es geht dann zu einer Relu -Aktivierung. Der Decoder verwendet nur eine lineare Schicht, um die Eingabe zu rekonstruieren. Beachten Sie, dass das Fehlen einer Relu-Aktivierung im Decoder für unseren spezifischen Rekonstruktionsfall beabsichtigt ist, da die Rekonstruktion realbewertete und potenziell damaging Daten enthalten könnte. Ein Relu würde im Gegenteil die Ausgabe zwingen, nicht negativ zu bleiben, was für unseren Wiederaufbau nicht wünschenswert ist.
Wir trainieren das Modell mit dem folgenden Code. Hier hat die Verlustfunktion zwei Teile: den Wiederaufbauverlust, die Genauigkeit der Rekonstruktion der Eingabedaten durch den AutoCodierer und einen Sparsity -Verlust (mit Gewicht), der die Sparsity -Formulierung im Encoder fördert.
# Coaching loop
for epoch in vary(num_epochs):
optimizer.zero_grad()# Ahead go
encoded, decoded = mannequin(information)
# Reconstruction loss
reconstruction_loss = criterion(decoded, information)
# Sparsity penalty (L1 regularization on the encoded options)
sparsity_loss = torch.imply(torch.abs(encoded))
# Complete loss
loss = reconstruction_loss + sparsity_weight * sparsity_loss
# Backward go and optimization
loss.backward()
optimizer.step()
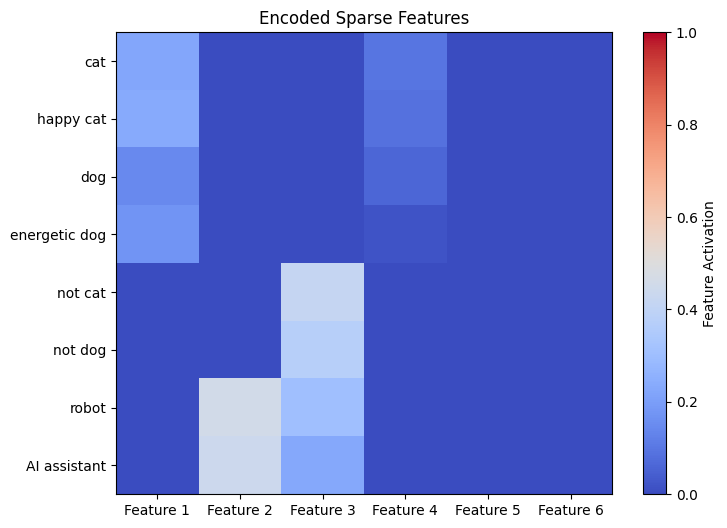
Jetzt können wir das Ergebnis sehen. Wir haben den Ausgangswert des Encoders jeder Aktivierung der ursprünglichen Modelle aufgetragen. Erinnern Sie sich daran, dass die Enter -Token „Katze“, „Pleased Cat“, „Canine“, „Energetic Canine“, „Not Cat“, „No Canine“, „Roboter“ und „AI Assistant“ sind.

Obwohl das Originalmodell mit einer sehr einfachen Architektur ohne tiefe Überlegungen entworfen wurde, hat der Autocoder immer noch sinnvolle Merkmale dieses trivialen Modells erfasst. Gemäß der obigen Handlung können wir mindestens vier Merkmale beobachten, die vom Encoder gelernt zu werden.
Geben Sie das erste Merkmal 1 an. Dieses Feautre hat große Aktivierungswerte auf den 4 folgenden Token: „Katze“, „Pleased Cat“, „Canine“ und „Energetic Canine“. Das Ergebnis deutet darauf hin, dass Function 1 etwas mit „Tieren“ oder „Haustieren“ bezogen kann. Function 2 ist auch ein interessantes Beispiel, das auf zwei Token „Roboter“ und „AI Assistant“ aktiviert wird. Wir vermuten, dass dieses Function etwas mit „künstlichem und Robotik“ zu tun hat, was auf das Verständnis des Modells zu technologischen Kontexten hinweist. Function 3 hat Aktivierung auf 4 Token: „Nicht Katze“, „nicht Hund“, „Roboter“ und „AI Assistant“ und dies ist möglicherweise ein Merkmal „kein Tier“.
Leider ist das Originalmodell kein echtes Modell, das auf realer Textual content ausgebildet ist, sondern künstlich mit der Annahme gestaltet wurde, dass ähnliche Token eine gewisse Ähnlichkeit im Aktivierungsvektorraum aufweisen. Die Ergebnisse liefern jedoch immer noch interessante Einblicke: Es gelang dem spärlichen Autocoder, einige bedeutungsvolle, menschlich-freundliche Merkmale oder reale Konzepte zu zeigen.
Das einfache Ergebnis in diesem Weblog-Beitrag deutet darauf hin: Ein spärlicher Autocoder kann effektiv dazu beitragen, hochrangige, interpretierbare Funktionen aus komplexen neuronalen Netzwerken wie LLM zu erhalten.
Für Leser, die sich für eine reale Implementierung von spärlichen Autoencodern interessieren, empfehle ich dies Artikelwo ein Autocoder geschult wurde, um ein echtes großes Sprachmodell mit 512 Neuronen zu interpretieren. Diese Studie bietet eine echte Anwendung spärlicher Autoencoder im Zusammenhang mit der Interpretierbarkeit von LLM.
Schließlich stelle ich hier diesen Google Colab zur Verfügung Notizbuch für meine in diesem Artikel erwähnte detaillierte Implementierung.