Der Datenbestand entwickelt sich weiter und das Datenqualitätsmanagement muss sich mit ihm mitentwickeln. Hier sind drei gängige Ansätze und die Richtung, in die sich das Feld im KI-Zeitalter bewegt.

Sind das unterschiedliche Wörter für dasselbe? Unterschiedliche Herangehensweisen an dasselbe Drawback? Etwas völlig anderes?
Und was noch wichtiger ist: Brauchen Sie wirklich alle drei?
Wie alles in der Datentechnik entwickelt sich auch das Datenqualitätsmanagement blitzschnell. Der kometenhafte Aufstieg von Daten und KI im Unternehmen hat die Datenqualität zu einem Zero-Day-Risiko für moderne Unternehmen gemacht – und zu DEM Drawback, das Datenteams lösen müssen. Bei so vielen sich überschneidenden Begriffen ist nicht immer klar, wie alles zusammenpasst – oder Wenn es passt zusammen.
Doch anders als manche vielleicht behaupten, sind Datenqualitätsüberwachung, Datentests und Datenbeobachtung keine widersprüchlichen oder gar alternativen Ansätze des Datenqualitätsmanagements, sondern ergänzende Elemente einer einzigen Lösung.
In diesem Artikel gehe ich näher auf die Besonderheiten dieser drei Methoden ein: wo sie am besten funktionieren, wo sie Schwächen haben und wie Sie Ihre Datenqualitätspraxis optimieren können, um im Jahr 2024 das Datenvertrauen zu stärken.
Bevor wir die aktuelle Lösung verstehen können, müssen wir das Drawback verstehen – und wie es sich im Laufe der Zeit verändert hat. Betrachten wir die folgende Analogie.
Stellen Sie sich vor, Sie sind Ingenieur und für die örtliche Wasserversorgung zuständig. Als Sie den Job annahmen, hatte die Stadt nur 1.000 Einwohner. Doch als unter der Stadt Gold entdeckt wird, verwandelt sich Ihre kleine 1.000-Einwohner-Gemeinde in eine echte Millionenstadt.
Wie könnte das Ihre Arbeitsweise verändern?
Zunächst einmal sind die Fehlerquellen in einer kleinen Umgebung relativ gering: Wenn ein Rohr kaputt geht, lässt sich die Grundursache auf einen von mehreren möglichen Übeltätern eingrenzen (eingefrorene Rohre, jemand hat in der Wasserleitung gegraben, das Übliche) und mit den Ressourcen von ein oder zwei Mitarbeitern genauso schnell beheben.
Angesichts der vielen Pläne und der Verwaltung von einer Million neuer Einwohner, des rasanten Tempos, das zur Deckung der Nachfrage erforderlich ist, und der begrenzten Möglichkeiten (und Sichtbarkeit) Ihres Groups sind Sie nicht mehr in der Lage, alle Probleme zu lokalisieren und zu lösen, mit deren Auftreten Sie rechnen – und schon gar nicht mehr, nach den Problemen Ausschau zu halten, mit denen Sie nicht rechnen.
In der modernen Datenumgebung verhält es sich genauso. Datenteams haben Gold gefunden und die Stakeholder wollen mitmischen. Je mehr Ihre Datenumgebung wächst, desto anspruchsvoller wird die Datenqualität – und desto weniger effektiv sind herkömmliche Datenqualitätsmethoden.
Sie sind nicht unbedingt falsch, aber sie reichen auch nicht aus.
Um es ganz klar zu sagen: Jede dieser Methoden versucht, DatenqualitätWenn das additionally das Drawback ist, müssen Sie bauen oder kaufen für, würde theoretisch jede dieser Lösungen dieses Kontrollkästchen aktivieren. Nur weil dies alles Datenqualitätslösungen sind, heißt das jedoch nicht, dass sie Ihr Datenqualitätsproblem tatsächlich lösen.
Wann und wie diese Lösungen verwendet werden sollten, ist etwas komplexer.
Vereinfacht ausgedrückt können Sie sich die Datenqualität als das Drawback vorstellen; Assessments und Überwachung als Methoden zur Erkennung von Qualitätsproblemen; und die Datenbeobachtung als einen anderen und umfassenden Ansatz, der beide Methoden kombiniert und um Funktionen für bessere Sichtbarkeit und Auflösung erweitert, um die Datenqualität im großen Maßstab zu verbessern.
Oder, um es noch einfacher auszudrücken: Durch Überwachung und Assessments werden Probleme identifiziert – durch die Datenbeobachtung werden Probleme identifiziert und Maßnahmen darauf abgestellt.
Hier ist eine kurze Illustration, die dabei helfen kann, zu visualisieren, wo die Datenbeobachtung in das passt Datenqualitäts-Reifekurve.

Lassen Sie uns nun die einzelnen Methoden etwas genauer betrachten.
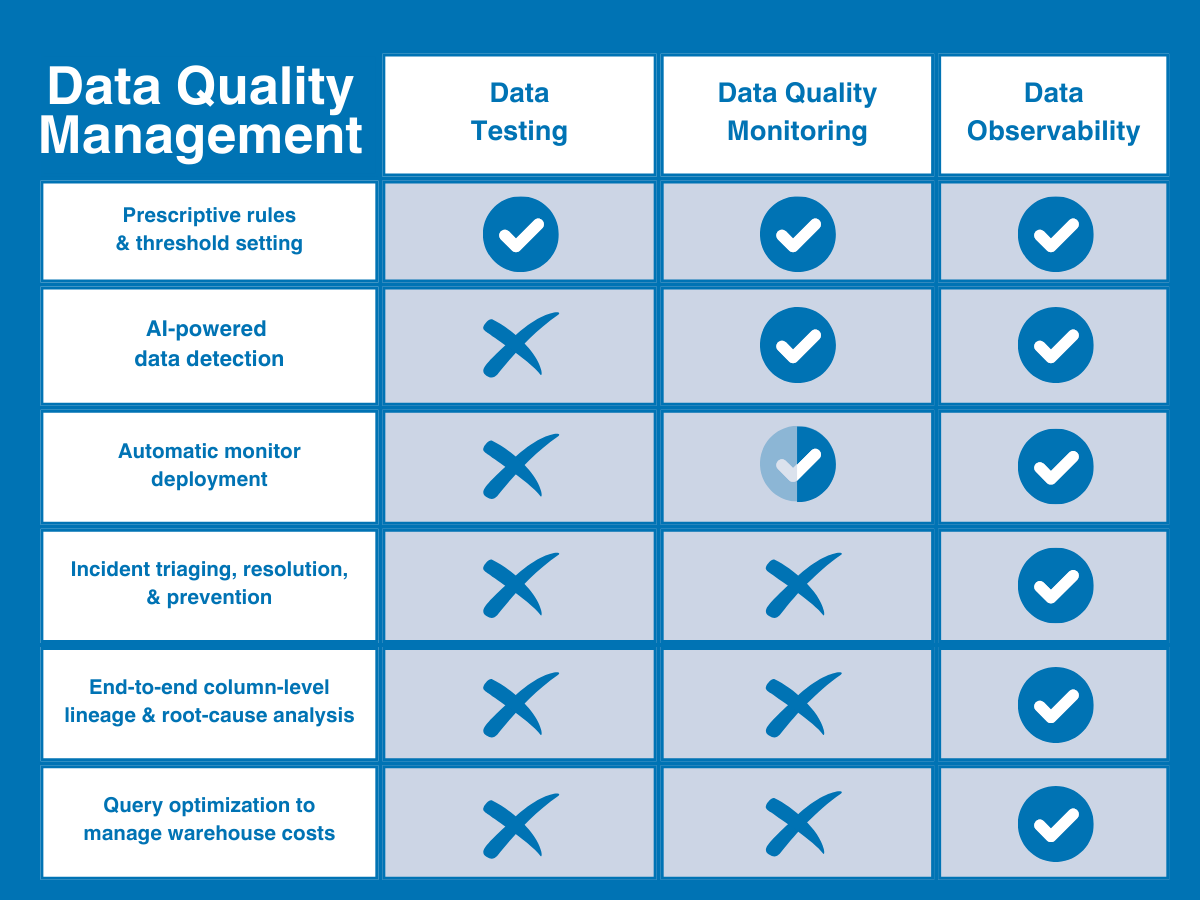
Der erste von zwei traditionellen Ansätzen zur Datenqualität ist der Datentest. Datenqualitätstests (oder einfach Datentest) ist eine Erkennungsmethode, die benutzerdefinierte Einschränkungen oder Regeln verwendet, um bestimmte bekannte Probleme innerhalb eines Datensatzes zu identifizieren und Überprüfen Sie die Datenintegrität und sorgen für spezifische Datenqualitätsstandards.
Um einen Datentest zu erstellen, würde der Datenqualitätsverantwortliche eine Reihe manueller Skripte schreiben (im Allgemeinen in SQL oder mithilfe einer modularen Lösung wie dbt), um bestimmte Probleme wie übermäßige Nullraten oder falsche Zeichenfolgenmuster zu erkennen.
Wenn Ihr Datenbedarf – und damit auch Ihre Anforderungen an die Datenqualität – sehr gering sind, können viele Groups das, was sie brauchen, durch einfache Datentests erreichen. Wenn jedoch die Größe und Komplexität Ihrer Daten zunimmt, werden Sie schnell mit neuen Problemen bei der Datenqualität konfrontiert – und benötigen neue Funktionen, um diese zu lösen. Und dieser Zeitpunkt wird viel früher als später kommen.
Obwohl Datentests auch weiterhin ein notwendiger Bestandteil eines Datenqualitätsrahmens bleiben, sind sie in einigen wichtigen Bereichen unzureichend:
- Erfordert fundierte Datenkenntnisse – Datentests erfordern, dass Dateningenieure 1) über genügend Fachwissen verfügen, um die Qualität zu definieren, und 2) über genügend Wissen darüber, wie die Daten fehlerhaft sein können, um Assessments zu ihrer Validierung einzurichten.
- Kein Versicherungsschutz für unbekannte Probleme — Datentests können Ihnen nur Informationen über die Probleme geben, die Sie zu finden erwarten, nicht über die Vorfälle, die Sie nicht finden möchten. Wenn ein Check nicht darauf ausgelegt ist, ein bestimmtes Drawback abzudecken, wird er durch Assessments nicht gefunden.
- Nicht skalierbar — 10 Assessments für 30 Tabellen zu schreiben ist etwas ganz anderes, als 100 Assessments für 3.000 zu schreiben.
- Eingeschränkte Sichtbarkeit – Beim Datentesten werden nur die Daten selbst getestet. Daher können Sie daraus nicht ableiten, ob das Drawback tatsächlich bei den Daten, dem System oder dem zugrunde liegenden Code liegt.
- Keine Lösung – selbst wenn durch Datentests ein Drawback erkannt wird, kommen Sie seiner Lösung nicht näher und verstehen auch nicht, was und wen es betrifft.
Auf jeder Maßstabsebene werden Assessments zu einer Datenentsprechung, die dem Rufen von „Feuer!“ auf einer belebten Straße und anschließendem Weggehen entspricht, ohne jemandem zu sagen, wo man es gesehen hat.
Ein weiterer traditioneller – wenn auch etwas ausgefeilterer – Ansatz zur Datenqualität, Datenqualitätsüberwachung ist eine kontinuierliche Lösung, die Ihre Daten kontinuierlich überwacht und unbekannte Anomalien identifiziert, die entweder durch manuelle Schwellenwerteinstellung oder durch maschinelles Lernen in ihnen lauern.
Kommen Ihre Daten beispielsweise pünktlich an? Haben Sie die erwartete Zeilenanzahl erhalten?
Der Hauptvorteil der Datenqualitätsüberwachung besteht darin, dass sie eine breitere Abdeckung unbekannter Unbekannter bietet und Dateningenieure davon befreit, für jeden Datensatz Assessments zu schreiben oder zu klonen, um häufige Probleme manuell zu identifizieren.
In gewissem Sinne könnte man die Überwachung der Datenqualität als ganzheitlicher als das Testen betrachten, da dabei Kennzahlen über einen längeren Zeitraum verglichen werden und die Groups Muster erkennen können, die ihnen bei einem einzelnen Unit-Check der Daten für ein bekanntes Drawback entgehen würden.
Leider lässt auch die Überwachung der Datenqualität in einigen wichtigen Bereichen zu wünschen übrig.
- Erhöhte Rechenkosten — Die Überwachung der Datenqualität ist teuer. Wie beim Datentesten werden die Daten bei der Datenqualitätsüberwachung direkt abgefragt. Da sie jedoch unbekannte Unbekannte identifizieren soll, muss sie breit angelegt sein, um effektiv zu sein. Das bedeutet hohe Rechenkosten.
- Langsame Wertschöpfung — Überwachungsschwellenwerte können mit maschinellem Lernen automatisiert werden, aber Sie müssen trotzdem zuerst jeden Monitor selbst erstellen. Das bedeutet, dass Sie für jedes Drawback am Frontend viel Code schreiben und diese Monitore dann manuell skalieren müssen, wenn Ihre Datenumgebung mit der Zeit wächst.
- Eingeschränkte Sichtbarkeit — Daten können aus allen möglichen Gründen kaputt gehen. Genau wie beim Testen werden beim Monitoring nur die Daten selbst betrachtet, sodass es Ihnen nur sagen kann, dass eine Anomalie aufgetreten ist – nicht, warum sie aufgetreten ist.
- Keine Lösung – obwohl durch die Überwachung sicherlich mehr Anomalien erkannt werden können als durch Assessments, können Sie auch hier nicht feststellen, welche Auswirkungen dies hatte, wer davon erfahren muss oder ob dies überhaupt von Bedeutung ist.
Und weil die Überwachung der Datenqualität nur dann effektiver ist, Bereitstellung Warnungen – und nicht deren Verwaltung – ist Ihr Datenteam viel eher gefährdet Alarmmüdigkeit in größerem Maßstab, als die Zuverlässigkeit der Daten im Laufe der Zeit tatsächlich zu verbessern.
Bleibt noch die Datenbeobachtung. Im Gegensatz zu den oben genannten Methoden bezieht sich die Datenbeobachtung auf eine umfassend anbieterneutrale Lösung, die eine vollständige Datenqualitätsabdeckung bietet, die sowohl skalierbar als auch umsetzbar ist.
Inspiriert von bewährten Vorgehensweisen im Software program-Engineering, Datenbeobachtung ist ein durchgängiger KI-gestützter Ansatz für das Datenqualitätsmanagement, der das Was, Wer, Warum und Wie von Datenqualitätsproblemen auf einer einzigen Plattform beantworten soll. Es gleicht die Einschränkungen herkömmlicher Datenqualitätsmethoden aus, indem es sowohl Assessments als auch eine vollautomatische Datenqualitätsüberwachung in einem einzigen System vereint und diese Abdeckung dann auf die Daten-, System- und Codeebene Ihrer Datenumgebung ausdehnt.
In Kombination mit Funktionen zur Verwaltung und Lösung kritischer Vorfälle (wie etwa automatisierter Herkunft auf Spaltenebene und Warnprotokollen) unterstützt die Datenbeobachtung Datenteams bei der Erkennung, Priorisierung und Lösung von Datenqualitätsproblemen von der Aufnahme bis zur Nutzung.
Darüber hinaus ist die Datenbeobachtung darauf ausgelegt, funktionsübergreifend einen Mehrwert zu schaffen, indem sie die Zusammenarbeit zwischen Groups, darunter Dateningenieure, Analysten, Dateneigentümer und Stakeholder, fördert.
Die Datenbeobachtung behebt die Mängel der herkömmlichen DQ-Praxis auf vier wesentliche Arten:
- Robuste Vorfall-Priorisierung und -Lösung – und das Wichtigste: Die Datenbeobachtung stellt die Ressourcen bereit, um Vorfälle schneller zu lösen. Neben dem Markieren und Warnen beschleunigt die Datenbeobachtung den Ursachenprozess durch eine automatisierte Herkunft auf Spaltenebene, sodass Groups auf einen Blick sehen können, was betroffen ist, wer Bescheid wissen muss und wo sie das Drawback beheben können.
- Vollständige Transparenz — Die Datenbeobachtung geht über die Datenquellen hinaus und erstreckt sich auf die Infrastruktur, Pipelines und Submit-Ingestion-Systeme, in denen Ihre Daten verschoben und transformiert werden, um Datenprobleme für Domänenteams im gesamten Unternehmen zu lösen.
- Schnellere Wertschöpfung – Die Datenbeobachtung automatisiert den Einrichtungsprozess vollständig mit ML-basierten Monitoren, die sofort einsatzbereite Abdeckung ohne Codierung oder Schwellenwerteinstellung bieten, sodass Sie schneller eine Abdeckung erhalten, die sich im Laufe der Zeit automatisch an Ihre Umgebung anpasst (zusammen mit benutzerdefinierten Einblicken und vereinfachten Codierungstools, um auch benutzerdefinierte Assessments zu erleichtern).
- Überwachung der Produktintegrität – Die Datenbeobachtung erweitert außerdem die Überwachung und Integritätsverfolgung über das herkömmliche Tabellenformat hinaus, um die Integrität bestimmter Datenprodukte oder kritischer Property zu überwachen, zu messen und zu visualisieren.
Wir alle kennen den Satz „Rubbish in, Rubbish out“. Nun, dieser Grundsatz gilt doppelt für KI-Anwendungen. KI braucht jedoch nicht nur ein besseres Datenqualitätsmanagement, um ihre Ergebnisse zu liefern; Ihr Datenqualitätsmanagement sollte auch von der KI selbst angetrieben werden, um die Skalierbarkeit für sich entwickelnde Datenbestände zu maximieren.
Datenbeobachtung ist die de facto – und wohl einzige – Datenqualitätsmanagementlösung, die es Unternehmensdatenteams ermöglicht, zuverlässige Daten für KI effektiv bereitzustellen. Und ein Teil der Artwork und Weise, wie sie dieses Kunststück erreicht, besteht darin, dass sie auch eine KI-gestützte Lösung ist.
Durch die Nutzung von KI zur Monitorerstellung, Anomalieerkennung und Ursachenanalyse ermöglicht die Datenbeobachtung ein hyperskalierbares Datenqualitätsmanagement für Echtzeit-Datenstreaming, RAG-Architekturen und andere KI-Anwendungsfälle.
Da sich der Datenbestand in Unternehmen und darüber hinaus ständig weiterentwickelt, können herkömmliche Datenqualitätsmethoden nicht alle Fehlerquellen Ihrer Datenplattform überwachen – oder Ihnen bei der Behebung solcher Fehler helfen.
Insbesondere im Zeitalter der KI ist die Datenqualität nicht nur ein Geschäftsrisiko, sondern auch ein existenzielles. Wenn Sie nicht der Gesamtheit der Daten vertrauen können, die in Ihre Modelle eingespeist werden, können Sie auch der Ausgabe der KI nicht vertrauen. Angesichts des schwindelerregenden Ausmaßes der KI reichen herkömmliche Datenqualitätsmethoden einfach nicht aus, um den Wert oder die Zuverlässigkeit dieser Datenbestände zu schützen.
Um effektiv zu sein, müssen sowohl Assessments als auch Überwachung in eine einzige plattformunabhängige Lösung integriert werden, die die gesamte Datenumgebung (Daten, Systeme und Code) objektiv und durchgängig überwachen kann und die Datenteams dann mit den Ressourcen ausstattet, um Probleme schneller zu priorisieren und zu lösen.
Mit anderen Worten: Damit das Datenqualitätsmanagement sinnvoll ist, benötigen moderne Datenteams eine Datenbeobachtung.
Erster Schritt. Erkennen. Zweiter Schritt. Lösen. Dritter Schritt. Gedeihen.