
Im September 2024 veröffentlichte OpenAI sein O1-Modell, das auf groß angelegte Verstärkungslernen ausgebildet wurde und ihm „fortgeschrittene Argumentationsfunktionen“ verleiht. Leider wurden die Particulars darüber, wie sie das abgerufen haben, nie öffentlich geteilt. Heute hat Deepseek (ein AI -Forschungslabor) dieses Argumentationsverhalten wiederholt und die vollständigen technischen Particulars ihres Ansatzes veröffentlicht. In diesem Artikel werde ich die Schlüsselideen hinter dieser Innovation diskutieren und beschreiben, wie sie unter der Motorhaube arbeiten.
Das O1 -Modell von OpenAI markierte ein neues Paradigma für die Schulung von LLMs (Language Fashions). Es führte sogenannte ein „Denken“ Tokendie eine Artwork von Artwork von ermöglichen Kratzpad, mit dem das Modell nachdenken kann durch Probleme und Benutzeranfragen.
Der Haupteinblick von O1 battle die Leistung mit erhöhtem Anstieg verbessert TEST-Zeit-Berechnung. Dies ist nur eine ausgefallene Artwork, das zu sagen Je mehr Token ein Modell erzeugt, desto besser seine Reaktion. Die folgende Abbildung aus OpenAIs Weblog erfasst diesen Punkt intestine.
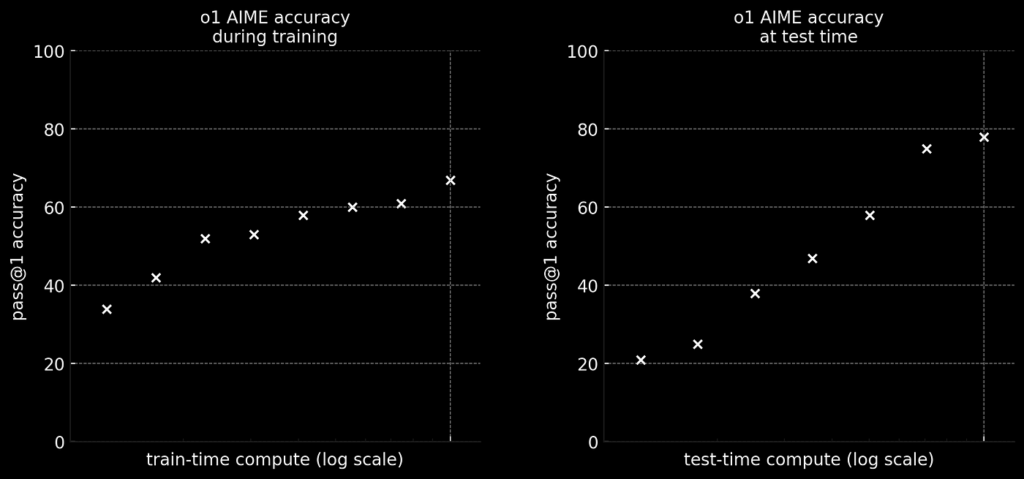
In den obigen Diagrammen sind die Y-Achsen die Modellleistung für Aime (Mathematikprobleme), während die X-Achsen verschiedene Berechnungszeiten sind. Die linke Verschwörung zeigt die bekannten Gesetze mit neuronaler Skalierung, die den LLM-Ansturm von 2023 abfielen. Mit anderen Worten, die länger ist ein Modell trainiert (dh Zug-Zeit-Laptop)Die Besser seine Leistung.
Auf der rechten Seite sehen wir jedoch eine neue Artwork von Skalierungsgesetz. Hier, desto mehr Token Ein Modell generiert (dh Check-Time-Laptop)Anwesend Je besser seine Leistung.
„Denken“ Token
Ein Schlüsselmerkmal von O1 ist sogenannt „Denken“ Token. Diese sind Spezielle Token, die während des Trainings eingeführt wurden, was die Denkkette des Modells (COT) abgrenzt Argumentation (dh das Drawback durchdenken). Diese speziellen Token sind aus zwei Gründen wichtig.
EinsSie haben eindeutig abgebaut, wo das „Denken“ des Modells beginnt und stoppt, sodass es beim Aufspinnen einer Benutzeroberfläche leicht analysiert werden kann. Und zweiEs erzeugt eine menschlich-interpretierbare Auslese darüber, wie das Modell durch das Drawback „denkt“.
Obwohl Openai bekannt gab, dass sie Verstärkungslernen verwendeten, um diese Fähigkeit zu erzeugen, die genauen Particulars von Wie Sie haben es nicht geteilt. Heute haben wir jedoch dank einer kürzlichen Veröffentlichung von Deepseek eine ziemlich gute Idee.
Deepseeks Papier
Im Januar 2025 veröffentlichte Deepseek “Deepseek-R1: Anreize der Argumentationsfähigkeit in LLMs durch Verstärkungslernen”(2). Während dieses Papier seinen angemessenen Anteil an Pandemonium verursachte, lag ihr zentraler Beitrag Enthüllung der Geheimnisse hinter O1.
Es führt zwei Modelle vor: Deepseek-R1-Null Und Deepseek-R1. Ersteres wurde ausschließlich auf Verstärkungslernen (RL) ausgebildet, und letzteres battle eine Mischung aus beaufsichtigter Feinabstimmung (SFT) und RL.
Obwohl es sich bei den Schlagzeilen (und dem Titel des Papiers) um Deepseek-R1 handelte, ist das erstere Modell wichtig, da es bei einem Trainingsdaten für R1 generierte, und zwei, es zeigt auffällige aufstrebende Argumente Fähigkeiten, die dem Modell nicht gelehrt wurden.
Mit anderen Worten, R1-Null entdeckt Cot und Check-Time-Berechnen Sie allein durch RL! Lassen Sie uns diskutieren, wie es funktioniert.
Deepseek-R1-Null (nur RL)
Verstärkungslernen (RL) ist a Maschinelles Lernen Ansatz, bei dem, anstatt Modelle zu expliziten Beispielen zu schulen Modelle lernen durch Versuch und Irrtum (3). Es funktioniert, indem es ein Belohnungssignal an ein Modell weitergibt, das keine explizite funktionale Beziehung zu den Parametern des Modells hat.
Dies ähnelt, wie wir in der realen Welt oft lernen. Wenn ich mich beispielsweise für einen Job bewerbe und keine Antwort bekomme, muss ich herausfinden, was ich falsch gemacht habe und wie ich mich verbessern kann. Dies steht im Gegensatz zum überwachten Lernen, was in dieser Analogie wie der Personalvermittler ein spezifisches Suggestions zu dem geben würde, was ich falsch gemacht habe und wie man sich verbessert.
Während ich RL zum Coaching von R1-Zero verwendet, besteht aus vielen technischen Particulars, ich möchte 3 Schlüssel hervorheben: die SchnellvorlageAnwesend BelohnungssignalUnd Grpo (Gruppenrelative Politikoptimierung).
1) Schablone Eingabeaufforderung
Der Vorlage für das Coaching verwendet wird unten angegeben, wo {immediate} wird durch eine Frage aus einem Datensatz mit (vermutlich) komplexen Mathematik-, Codierungs- und Logikproblemen ersetzt. Beachten Sie die Aufnahme von <reply> Und <suppose> Tags über einfache Aufforderung.
A dialog between Person and Assistant. The person asks a query, and the
Assistant solves it.The assistant first thinks in regards to the reasoning course of in
the thoughts after which offers the person with the reply. The reasoning course of and
reply are enclosed inside <suppose> </suppose> and <reply> </reply> tags,
respectively, i.e., <suppose> reasoning course of right here </suppose>
<reply> reply right here </reply>. Person: {immediate}. Assistant:Etwas, das hier auffällt, ist die minimale und entspannte Aufforderungstrategie. Dies battle eine absichtliche Wahl von Deepseek zu Vermeiden Sie Verzerrungsmodellantworten und zu Beobachten Sie seine natürliche Entwicklung während RL.
2) Belohnungssignal
Die rl belohnen hat zwei Komponenten: Genauigkeit und Formatbelohnungen. Da der Schulungsdatensatz aus Fragen mit klaren richtigen Antworten besteht, wird eine einfache regelbasierte Strategie zur Bewertung der Antwortgenauigkeit verwendet. In ähnlicher Weise wird eine regelbasierte Formatierungsbelohnung verwendet, um sicherzustellen, dass zwischen den Denketags Argumentationstoken generiert werden.
Es wird von den Autoren festgestellt, dass ein neuronales Belohnungsmodell nicht verwendet wird (dh Belohnungen werden nicht von einem neuronalen Netz berechnet), da diese möglicherweise anfällig für Anfälligkeiten sind Hacking belohnen. Mit anderen Worten, die LLM lernt, wie es geht Trick Das Belohnungsmodell zur Maximierung von Belohnungen während der nachgelagerte Leistung abnimmt.
Dies ist genau so, wie Menschen Wege finden, um eine Anreizstruktur auszunutzen, um ihre persönlichen Gewinne zu maximieren und gleichzeitig die ursprüngliche Absicht der Anreize zu geben. Dies unterstreicht die Schwierigkeit, gute Belohnungen zu erzeugen (ob für Menschen oder Laptop).
3) GRPO (Gruppenrelative Richtlinienoptimierung)
Das endgültige Element ist, wie Belohnungen in Modellparameter -Updates übersetzt werden. Dieser Abschnitt ist ziemlich technisch, sodass der erleuchtete Leser gerne voranschreitet.
Grpo ist ein RL -Ansatz, der eine Sammlung von Antworten auf Aktualisierungsmodellparameter kombiniert. Um ein stabiles Coaching zu fördern, integrieren die Autoren auch die Regularisierungsbegriffe für Klippungen und KL-Divergenz in die Verlustfunktion. Durch die Ausschnitte stellt die Optimierungsschritte nicht zu groß, und die Regularisierung sorgt dafür, dass sich die Modellvorhersagen nicht zu abrupt ändern.
Hier ist die vollständige Verlustfunktion mit einigen (hoffentlich) hilfreichen Anmerkungen.

Ergebnisse (aufstrebende Fähigkeiten)
Das auffälligste Ergebnis von R1-Null ist, dass es trotz seiner minimalen Anleitung wirksame Argumentationsstrategien entwickelt, die wir möglicherweise erkennen.
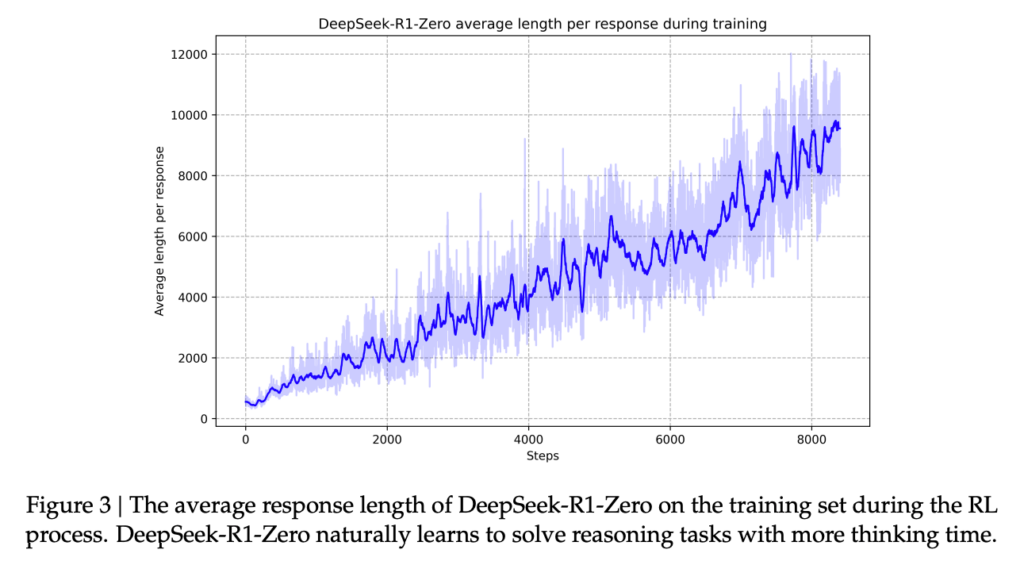
Zum Beispiel lernt es implizit durch die RL zur Verbesserung der Antworten durch Testzeitberechnung (Erinnern Sie sich an den früheren Einblick von O1). Dies wird über die unten stehende Handlung aus dem R1 -Papier (2) dargestellt.
Eine andere bemerkenswerte Fähigkeit besteht darin, vergangene Antworten mit einem unheimlichen menschlichen inneren Monolog nachzudenken. Hier ist ein Beispiel von R1-Null. Beachten Sie die langes Kinderbett und zusätzlichen Überprüfungsschritt Vor der Erzeugung der endgültigen Antwort (ich habe einige Teile weggelassen, weil die Antwort sehr lang battle).
Person immediate: If it takes me 1.5 hours to write down a codebase and my intern 8
hours. How lengthy will it take us each to write down 3 codebases?
<suppose> To resolve for a way lengthy it can take each you and your intern to write down
three codebases collectively, we have to first learn the way many codebases every of
you'll be able to write per hour individually.
(lengthy CoT) ...
So, it can take roughly 3.7895 hours for you and your intern to write down
three codebases collectively.
To verify all the things is sensible, allow us to spherical the reply to an affordable
variety of decimal locations (e.g., spherical to 2 decimal locations):
t ≈ 3.79 hours
Nevertheless, in the event you want a extra "human-friendly" reply, you may convert the
decimal half into minutes. Since 0.7895 of an hour is:
0.7895 × 60 minutes ≈ 47.37 minutes
So, 3.7895 hours is roughly 3 hours and 47.37 minutes (or roughly 3
hours and 47 minutes if rounding to the closest minute).
## Verification (non-compulsory step for verification)
To confirm, allow us to test what number of codebases you'll be able to individually write in t =
72/19 hours:
Your work in 72/19 hours
= (2/3 codebases per hour) × (72/19 hours)
= (2 × 72) / (3 × 19)
= 144 / 57
= 48/19 codebases.
(verification course of) ...
Nevertheless, a extra "precise" reply ought to be saved in fractional type except
specified in any other case. Thus, the reply is: 72/19hours which is roughly
$3.7895$ hours or about $3.79$ hours when rounded to 2 decimal locations).
</suppose>
72/19 hours (or roughly 3.79 hours).Probleme mit R1-Zero
Obwohl die Considering-Token von R1-Null ein menschenlesbares Fenster in den „Gedankenprozess“ des Modells geben, berichten die Autoren einige Probleme. Nämlich das gelehrte Kinderbett leidet manchmal unter Lesbarkeitsprobleme und Sprachmischung. Vorschläge (vielleicht), dass seine Argumentation von etwas, das von Menschen leicht interpretierbar ist, wegweichen beginnt.
Deepseek-R1 (SFT + RL)
Um die Interpretierbarkeitsprobleme von R1-Null zu mildern, untersuchen die Autoren eine mehrstufige Trainingsstrategie, die Verwendet sowohl beaufsichtigte Feinabstimmung (SFT) als auch RL. Diese Strategie führt zu Deepseek-R1ein besseres Modell, das heute mehr Aufmerksamkeit erregt. Der gesamte Trainingsprozess kann in 4 Schritte unterteilt werden.
Schritt 1: SFT mit Argumentationsdaten
Um das Modell auf den richtigen Weg zu bringen, wenn es darum geht, wie man darstellt, beginnen die Autoren mit SFT. Das Nutzung von 1000s langen Cot -Beispielen Aus verschiedenen Quellen, darunter nur wenige Schüsse (dh Beispiele für die Überlegung durch Probleme), veranlasst das Modell direkt, Reflexion und Überprüfung zu verwenden, und die Synthetikdaten aus R1-Null (2) zu verfeinern.
Der zwei wichtige Vorteile davon sind, einsDas gewünschte Antwortformat kann dem Modell explizit gezeigt werden, und zweiund Sehen von kuratierten Argumentationsbeispielen ermöglicht eine bessere Leistung für das endgültige Modell.
Schritt 2: R1-Zero-Stil RL (+ Sprachkonsistenzbelohnung)
Als nächstes wird nach SFT ein RL -Trainingsschritt auf das Modell angewendet. Dies geschieht in einem identischer Weg wie R1-Null mit einer zusätzlichen Komponente zum Belohnungssignal, das die Sprache konsequent anreißt. Dies wurde zur Belohnung hinzugefügt, da R1-Null dazu tendierte, Sprachen zu mischen, was es schwierig machte, seine Generationen zu lesen.
Schritt 3: SFT mit gemischten Daten
Zu diesem Zeitpunkt hat das Modell wahrscheinlich eine NA (oder bessere) Leistung als R1-Null bei Argumentationsaufgaben. Dieses Zwischenmodell wäre jedoch nicht sehr praktisch, da es über alle Eingaben (z. B. „Hallo es“) nachgehen möchte, was für sachliche Fragen und Antworten, Übersetzung und kreatives Schreiben nicht erforderlich ist. Deshalb wird eine weitere SFT -Runde mit beiden durchgeführt Argumentation (600k Beispiele) Und Nicht-Bewertung (200K-Beispiele) Daten.
Der Deningdaten Hier wird aus dem resultierenden Modell aus Schritt 2 generiert. Zusätzlich werden Beispiele enthalten, bei denen ein LLM -Richter verwendet wird, um Modellvorhersagen mit Grundwahrheitsantworten zu vergleichen.
Der Daten nicht erschwinglich kommt von zwei Orten. Zunächst trainierte der SFT-Datensatz, der Deepseek-V3 (das Basismodell) trainiert. Zweitens synthetische Daten, die von Deepseek-V3 erzeugt wurden. Beachten Sie, dass Beispiele enthalten sind, die COT nicht verwenden, damit das Modell für jede Antwort nicht den Denk -Token verwendet.
Schritt 4: RL + RLHF
Schließlich wird eine weitere RL-Runde durchgeführt, die (wieder) R1-Null-Argumentationstraining und RL zum menschlichen Suggestions umfasst. Diese letztere Komponente hilft Verbessern Sie die Hilfsbereitschaft und Harmlosigkeit des Modells.
Das Ergebnis dieser gesamten Pipeline ist Deepseek-R1, das sich bei den Argumentationsaufgaben auszeichnet und ein KI-Assistent ist, mit dem Sie regular chatten können.
Zugriff auf R1-Zero und R1
Ein weiterer wichtiger Beitrag von Deepseek besteht darin, dass die Gewichte der beiden oben beschriebenen Modelle (und viele andere destillierte Versionen von R1) öffentlich verfügbar gemacht wurden. Dies bedeutet, dass es viele Möglichkeiten gibt, auf diese Modelle zuzugreifen, sei es Inferenzanbieter oder sie lokal ausführen.
Hier sind einige Orte, an denen ich diese Modelle gesehen habe.
- Deepseek (Deepseek-V3 und Deepseek-R1)
- Zusammen (Deepseek-V3, Deepseek-R1 und Destillationen)
- Hyperbolisch (Deepseek-V3, Deepseek-R1-Zero und Deekseek-R1)
- Ollama (lokal) (Deepseek-V3, Deepseek-R1 und Destillationen)
- Umarmtes Gesicht (lokal) (alle oben genannten)
Schlussfolgerungen
Die Veröffentlichung von O1 führte eine neue Dimension ein, durch die LLMs verbessert werden können: TEST-Zeit-Berechnung. Obwohl OpenAI seine geheime Sauce dafür nicht veröffentlichte, konnte Deepseek dieses Argumentationsverhalten nachbilden und die technischen Particulars seines Ansatzes veröffentlichen.
Während aktuelle Argumentationsmodelle Einschränkungen aufweisen, ist dies eine vielversprechende Forschungsrichtung, da sie gezeigt hat, dass Verstärkungslernen (ohne Menschen) können Erstellen Sie Modelle, die unabhängig lernen. Dies (möglicherweise) bricht die impliziten Einschränkungen der aktuellen Modelle aus, die nur können abrufen Und Remix Informationen, die zuvor im Web (dh bestehende menschliche Wissen) gesehen wurden.
Das Versprechen dieses neuen RL -Ansatzes besteht darin, dass Modelle das menschliche Verständnis (allein) übertreffen können, was zu neuen wissenschaftlichen und technologischen Durchbrüchen führt, die uns Jahrzehnte dauern könnten (allein).
🗞️ Erhalten Sie einen exklusiven Zugang zu KI -Ressourcen und Projektideen: https://the-ta-entrepreneurs.equipment.com/shaw
🧑🎓 Lernen Sie in 6 Wochen KI, indem Sie es bauen: https://maven.com/shaw-talebi/ai-builders-bootcamp
Referenzen
(2) ARXIV: 2501.12948 (cs.cl)