NED-SERIE
Wie man Wissen aus biomedizinischem Textual content destilliert, indem man vorab trainierte Sprachmodelle mit maschinellem Graphenlernen kombiniert
Dieser Artikel fasst einen vom IEEE akzeptierten Artikel zusammen Anwendung von Informations- und Kommunikationstechnologien (AICT2024) Konferenz. Zusätzlich zu den Unterzeichnern, Felice Paolo Colliani (Erstautor), Giovanni Garifo, Antonio VetròUnd Juan Carlos De Martin sind die Co-Autoren dieses Artikels.
Im biomedizinischen Bereich ist die Veröffentlichungsrate im Laufe der Jahre aufgrund des Wachstums der wissenschaftlichen Forschung, des technologischen Fortschritts und der globalen Betonung des Gesundheitswesens und der medizinischen Forschung stetig gestiegen.
Die Anwendung von Pure Language Processing (NLP)-Techniken im biomedizinischen Bereich stellt einen Wandel in der Analyse und Interpretation des umfangreichen biomedizinischen Wissensbestands dar und verbessert unsere Fähigkeit, aus Textdaten aussagekräftige Erkenntnisse abzuleiten.
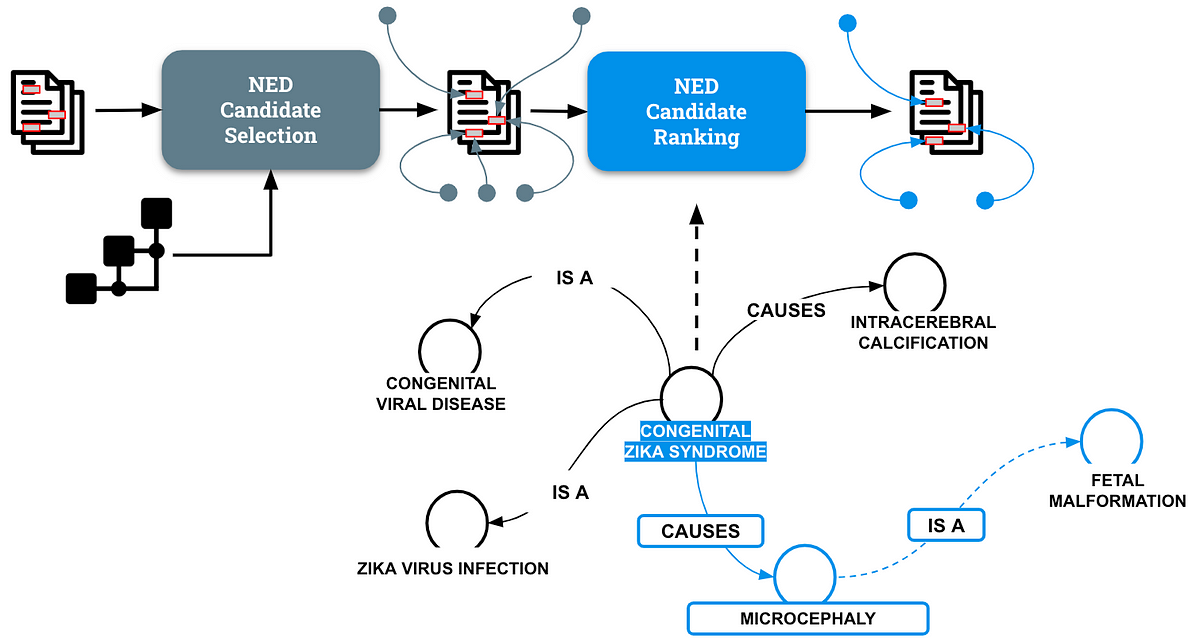
Die Benannte Entitätsdisambiguierung (NED) ist eine wichtige NLP-Aufgabe, bei der Mehrdeutigkeiten in Entitätserwähnungen gelöst werden, indem diese mit den richtigen Einträgen in einer Wissensdatenbank verknüpft werden. Um die Bedeutung und Komplexität einer solchen Aufgabe zu verstehen, betrachten Sie das folgende Beispiel:
Zika gehört zur Familie der Flaviviridae und wird durch Aedes-Mücken übertragen.
Betroffene Personen Zika Infektion oft…